MongoDB
목차
• MongoDB 기본
•데이터모델링
– References
– Embedding
• Index
– 인덱스 배경
– 인덱스 생성
– 인덱스 전략
• Aggregation Pipieline
• 고급기능활용
3.
MongoDB
MongoDB 기본
• 쉘명령어
– 서버실행 mongod --dbpath d:mongo
– 몽고쉘 mongo
– DB선택 use blog
– 현재DB명 db
– 기타
• show dbs
• show collections
• show users
• ..
http://docs.mongodb.org/v3.0/core/data-modeling-introduction/
4.
MongoDB
MongoDB 기본
• CRUD
–Create
• db:blog.insert(삽입정보)
– Read
• db.blog.findOne()
• db.blog.find().limit(3) 앞에서 3개 문서반환
• db.blog.find().skip(3) offset, 3개 이후부터..
• db.blog.find().skip(Math.floor(Math.random()*db.blog.count())).limit(1) 랜덤찾
기
• db.blog.find().limit(3).sort({“key1”:-1}) key1부터(-1:내림차순)
• db.blog.find({"$query":{"key1":"value1"}}) modifier 이용
• db.blog.find({"$query":{"key1":"value1"},"$orderby":{"x":1}}) modifier 이용한
orderby
– Update
• db.blog.update(조건,업데이트정보)
– Delete
• db.blog.remove(조건)
MongoDB
데이터 모델링
• Embeddeddata
– single document에 sub-document를 포함하는 구조로 모델링을 함
– 문서(BSON)는 16MB를 넘을수 없다는 점을 유의할 필요가 있음
• http://docs.mongodb.org/master/reference/limits/
7.
MongoDB
Index 배경
• Index를사용하는 이유
• 거대한 컬렉션에 대해 Read Operation이 느릴때
– Read operation시 Table scan(정보전체에 대한 읽기)이 일어남
– 거대한 컬렉션에서 Table scan이 일어난다면서버는 Table scan이
일어나지 않도록 해야함
8.
MongoDB
Index 배경
• Index의효과
– 인덱스는 DB 테이블에 대한 동작속도를 높여주는 자료구조로, 저장된
자료에대한 빠른조회를 위해 생성 (Index ↔ Full Table Scan)
– 인덱스는 키-필드 형태를 가지며, Scan을 거치지 않고, 원하는 문서 위
치주소로 바로 이동함
9.
MongoDB
Index 배경
• 몽고DBIndex에 대한 특징
– MongoDB automatically creates a unique index on the _idfield.
• Index 생성시 알아둘점
– 각 Index는 8KB의 데이터 공간을 필요로함
– Index생성시 write 및 update operation 성능을 떨어뜨림
– Index는 system.indexes 컬렉션에 저장됨
• db.system.indexes.find() 로 색인된키 확인가능
10.
MongoDB
Index 생성
• 오름차순/내림차순에대한 색인
– 키가 하나 일때는 키 방향이 무의미, 키가 하나 이상일 경우 고려함
• 단일키에서 특정M키는 방향과 관계없이 명확함
– 최적화시 정렬방향을 고려함
• {“username”:1,”age”:-1} 내림차순 최적화
• {“username”:1,“age”:1} 오름차순 최적화
• {“comments.date”:1} 내장문서 comments에 있는 date키에 대한 색인
– 예
• 수백만 사용자에 대한 상태메시지
– {date:-1, user:1}
11.
MongoDB
Index 생성
• 인덱스생성
– db.people.find({“username”:”david”})에 대한 인덱스 생성은
db.people.ensureIndex({“username”:1})
db.people.ensuerIndex({“date”:1,“username:”:1}) 1은 오름차순 방향
– 고유 인덱스 생성
• db.user.ensureIndex({"userid":1},{"unique":true})
• db.system.indexes.find()
• 고유 인덱스는 삭제불가.. (_id 로 생성됨)
12.
MongoDB
Index 생성
– 중복제거(dropDups) 옵션
• db.user.insert({"userid":"hello1"})
• db.user.insert({"userid":"hello1"})
• db.user.insert({"userid":"hello2"})
• db.user.insert({"userid":"hello2"})
• db.user.ensuerIndex({"userid":1},{"unique":true,"dropDups":true})
unique 하지 않아서 발생되는 에러
13.
MongoDB
Index 생성
• 인덱스생성과 삭제(특정문서)
– db.hello.insert({"name":"wook"})
– db.hello.ensureIndex({"name":1})
– db.hello.ensureIndex({"name":2})
– db.system.indexes.find()
– db.hello.dropIndex({"name":1}) 특정 문서만 삭제
– db.hello.dropIndex({"name":2})
– db.system.indexes.find()
_id는 인덱스가 자동으로 생성되었음에 유의
14.
MongoDB
Index 생성
• 인덱스삭제 (인덱스이름 이용)
– index 이름을 이용한 삭제
– db.hello.dropIndex("name_1")
– db.hello.dropIndex("name_2")
– db.system.indexes.find()
MongoDB
Index 생성
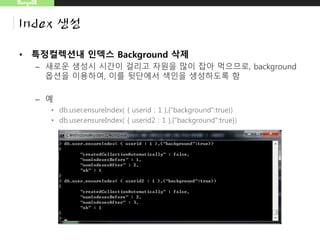
• 특정컬렉션내인덱스 Background 삭제
– 새로운 생성시 시간이 걸리고 자원을 많이 잡아 먹으므로, background
옵션을 이용하여, 이를 뒷단에서 색인을 생성하도록 함
– 예
• db.user.ensureIndex( { userid : 1 },{"background":true})
• db.user.ensureIndex( { userid2 : 1 },{"background":true})
17.
MongoDB
Index 생성
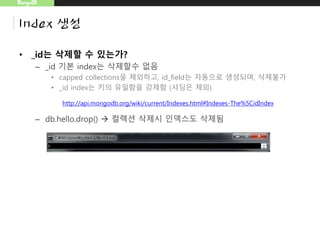
• _id는삭제할 수 있는가?
– _id 기본 index는 삭제할수 없음
• capped collections을 제외하고, id_field는 자동으로 생성되며, 삭제불가
• _id index는 키의 유일함을 강제함 (샤딩은 제외)
– db.hello.drop() 컬렉션 삭제시 인덱스도 삭제됨
http://api.mongodb.org/wiki/current/Indexes.html#Indexes-The%5CidIndex
18.
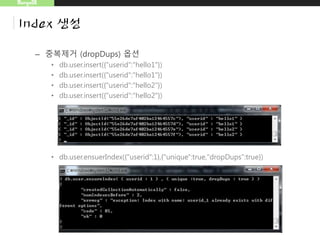
MongoDB
Index 생성
• 공간정보색인
–위도,경도에 가까운 영화관을 찾을때 공간색인을 이용함
– 공간정보 색인
• 1 or -1대신, 2d를 넣음
• db.map.ensureIndex({"gps":"2d"})
– 유효키 예
• {"gps":[0,100]}
• {"gps":{"x":-30,"y":30}}
• {"gps":{"lat":-180,"long":180}}
19.
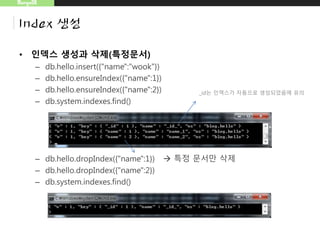
MongoDB
Index 생성
– 2d지정예
• db.map.ensureIndex({"gps":"2d"})
• db.map.insert({"gps":[0,100]})
• db.map.insert({"gps":{"x":-30,"y":30}})
• db.map.insert({"gps":{"lat":-180,"long":180}})
20.
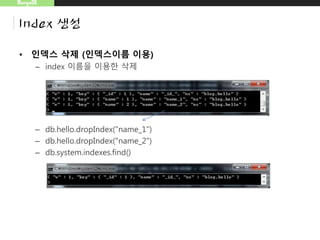
MongoDB
Index 생성
– 범위지정예
• db.map.ensureIndex({"gps2":"2d"},{"min":-1000,"max":1000})
• db.map.insert({"gps2":[-1001,0]})
범위 벗어났을때 오류
21.
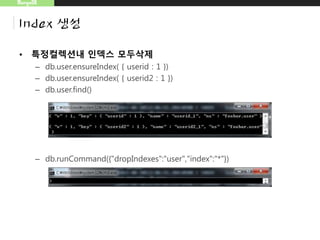
MongoDB
Index 생성
– 복합공간정보색인 질의
• db.map.ensureIndex({"gps3":"2d"},{"min":-1000,"max":1000},{"desc":1})
• db.map.insert({"gps3":[50,70],"desc":"coffe"})
• db.map.insert({"gps3":[60,70],"desc":"coffe"})
• db.map.find({"gps3":{"$near":[56,70]},"desc":"coffe"})
22.
MongoDB
Index 전략
• 주의사항
–모든 Key에 대해 색인하지 않는다.
• 공간이 늘어날 수 있으며, 모든 Key에 인덱싱을 걸었다고 하여도, 쿼리속도
가 크게 빨라지지 않는다.
• 색인생성시 입력, 갱신, 삭제에 대한 Cost가 발생함
– DB연산 수행뿐 아니라, 컬렉션 내 모든 색인에도 반영이 필요하므로
– 컬렉션의 절반이상을 반환하는 경우는 사용하지 않음
• 모든 문서에 대해 키를 찾아 살피는것보다, 그냥 테이블 스캔을 하는 것이
훨씬 효율적
23.
MongoDB
Index 전략
• MongoDB에서 지원하는 Index 목록
– Single Field indexes
• 문서에 대해 single field에 대한 인덱스
• db.friends.createIndex( { "name" : 1 } )
– Compound Indexes
• 1개 필드 이상에 대한 인덱스..
• db.products.createIndex( { "item": 1, "stock": 1 } )
– Multikey Indexes
• array field에 대한 인덱스..
• db.survey.createIndex( { ratings: 1 } )
– Geospatial Indexes and Queries
• location-based 검색에 이용되며, 데이터는 GeoJSON object 형태로 저장
– Text Indexs
• string 컨텐츠에 대한 인덱스를 지원
– Hashed Index
• hash function 기반 인덱스, multi-key(arrays)에 대해 지원안함
• db.active.createIndex( { a: "hashed" } )
http://docs.mongodb.org/master/core/indexes/
24.
MongoDB
Index 전략
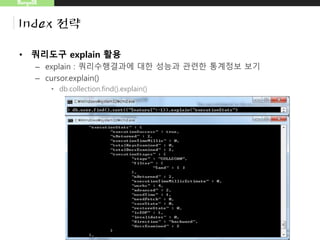
• 쿼리도구explain 활용
– explain : 쿼리수행결과 통계정보를 통한 성능개선점 찾기
– cursor.explain()
• db.collection.find().explain()
MongoDB
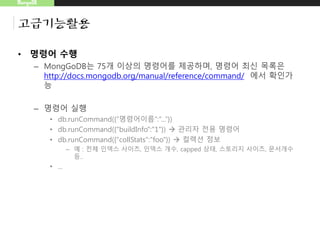
고급기능활용
• 명령어 수행
–MongGoDB는 75개 이상의 명령어를 제공하며, 명령어 최신 목록은
http://docs.mongodb.org/manual/reference/command/ 에서 확인가
능
– 명령어 실행
• db.runCommand({“명령어이름”:”...”})
• db.runCommand({"buildInfo":"1"}) 관리자 전용 명령어
• db.runCommand({"collStats":"foo"}) 컬렉션 정보
– 예 : 전체 인덱스 사이즈, 인덱스 개수, capped 상태, 스토리지 사이즈, 문서개수
등..
• ...
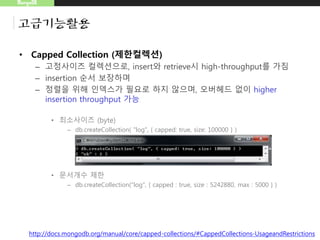
MongoDB
고급기능활용
• Tailable Cursor
–capped collection의 문서를 모두 꺼내었어도, 원형큐의 특성처럼 종료
되지 않고 문서를 꺼냄
$cursor = $collection->find()->tailable();
while (true) {
if (!$cursor->hasNext()) {
if ($cursor->dead()) {
break;
}
sleep(1);
}
else {
while ($cursor->hasNext()) {
do_stuff($cursor->getNext());
}
}
}








![MongoDB
Index 생성
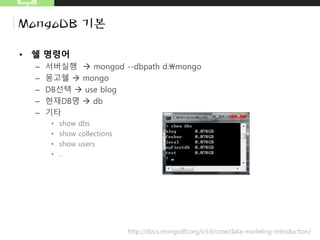
• 공간정보색인
– 위도,경도에 가까운 영화관을 찾을때 공간색인을 이용함
– 공간정보 색인
• 1 or -1대신, 2d를 넣음
• db.map.ensureIndex({"gps":"2d"})
– 유효키 예
• {"gps":[0,100]}
• {"gps":{"x":-30,"y":30}}
• {"gps":{"lat":-180,"long":180}}](https://image.slidesharecdn.com/20150830mongodb-150830101018-lva1-app6892/85/Mongo-DB-18-320.jpg)
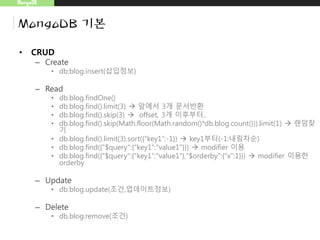
![MongoDB
Index 생성
– 2d지정 예
• db.map.ensureIndex({"gps":"2d"})
• db.map.insert({"gps":[0,100]})
• db.map.insert({"gps":{"x":-30,"y":30}})
• db.map.insert({"gps":{"lat":-180,"long":180}})](https://image.slidesharecdn.com/20150830mongodb-150830101018-lva1-app6892/85/Mongo-DB-19-320.jpg)
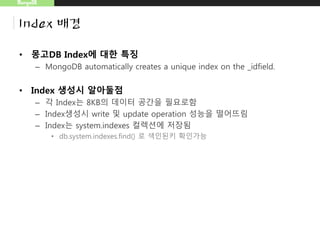
![MongoDB
Index 생성
– 범위지정 예
• db.map.ensureIndex({"gps2":"2d"},{"min":-1000,"max":1000})
• db.map.insert({"gps2":[-1001,0]})
범위 벗어났을때 오류](https://image.slidesharecdn.com/20150830mongodb-150830101018-lva1-app6892/85/Mongo-DB-20-320.jpg)
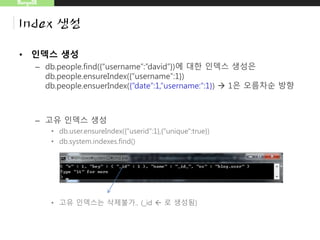
![MongoDB
Index 생성
– 복합공간 정보색인 질의
• db.map.ensureIndex({"gps3":"2d"},{"min":-1000,"max":1000},{"desc":1})
• db.map.insert({"gps3":[50,70],"desc":"coffe"})
• db.map.insert({"gps3":[60,70],"desc":"coffe"})
• db.map.find({"gps3":{"$near":[56,70]},"desc":"coffe"})](https://image.slidesharecdn.com/20150830mongodb-150830101018-lva1-app6892/85/Mongo-DB-21-320.jpg)


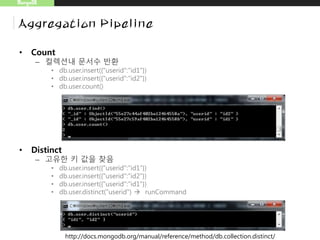

![• Group으로 집계
MongoDB
Aggregation Pipeline
db.sales.aggregate(
[
{
$group : {
_id : { month: { $month: "$date" }, day: { $dayOfMonth: "$date" }, year: { $year:
"$date" } },
totalPrice: { $sum: { $multiply: [ "$price", "$quantity" ] } },
averageQuantity: { $avg: "$quantity" },
count: { $sum: 1 }
}
}
]
)
_id(생략시 fail)를 date필드를
이용하여 구성함](https://image.slidesharecdn.com/20150830mongodb-150830101018-lva1-app6892/85/Mongo-DB-27-320.jpg)



![Naver속도의, 속도에 의한, 속도를 위한 몽고DB (네이버 컨텐츠검색과 몽고DB) [Naver]](https://cdn.slidesharecdn.com/ss_thumbnails/naver-190916181334-thumbnail.jpg?width=640&height=640&fit=bounds)




![[215]네이버콘텐츠통계서비스소개 김기영](https://cdn.slidesharecdn.com/ss_thumbnails/215-161025030904-thumbnail.jpg?width=640&height=640&fit=bounds)





![[pgday.Seoul 2022] PostgreSQL구조 - 윤성재](https://cdn.slidesharecdn.com/ss_thumbnails/pgday2022-postgresql-20221112-221114014106-bbfb1955-thumbnail.jpg?width=640&height=640&fit=bounds)









![[212]검색엔진dot의내부 강희구최규식](https://cdn.slidesharecdn.com/ss_thumbnails/212dot-161025011124-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[124]네이버에서 사용되는 여러가지 Data Platform, 그리고 MongoDB](https://cdn.slidesharecdn.com/ss_thumbnails/124mongodb-181011042943-thumbnail.jpg?width=640&height=640&fit=bounds)

![[스마트스터디]MongoDB 의 역습](https://cdn.slidesharecdn.com/ss_thumbnails/mongodb-171107063223-thumbnail.jpg?width=640&height=640&fit=bounds)
![[스마트스터디]모바일 애플리케이션 서비스에서의 로그 수집과 분석](https://cdn.slidesharecdn.com/ss_thumbnails/redismongodbmysql-171107063045-thumbnail.jpg?width=640&height=640&fit=bounds)












