Download to read offline



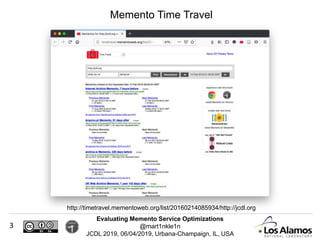
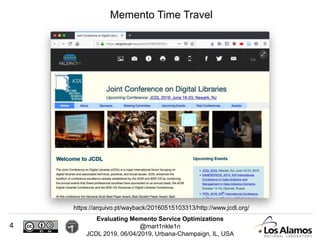
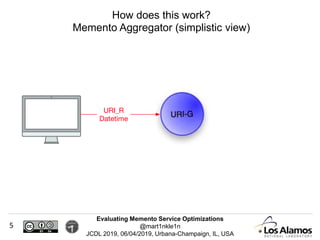
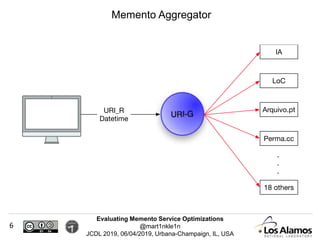
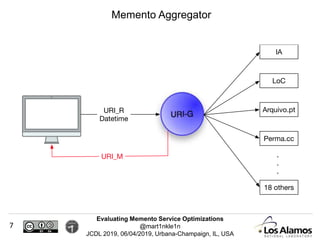



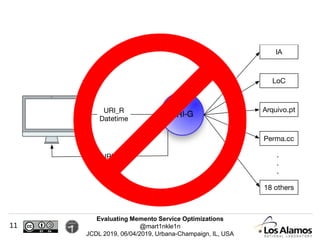

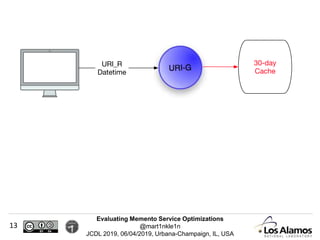
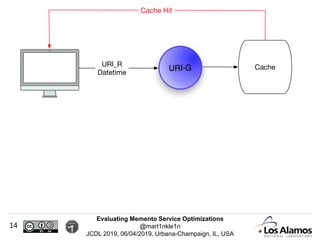
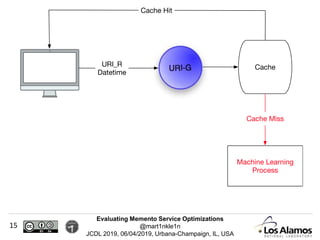
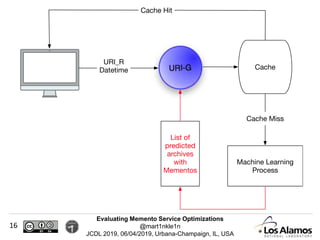
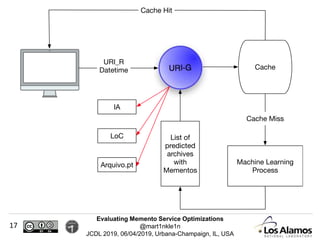
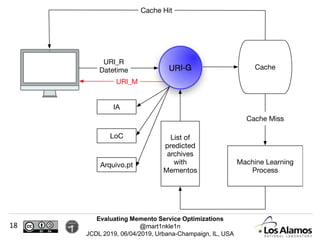


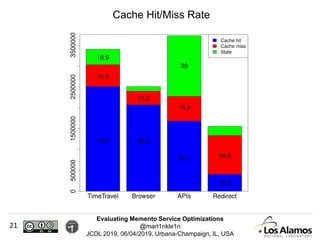
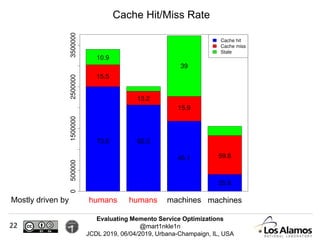


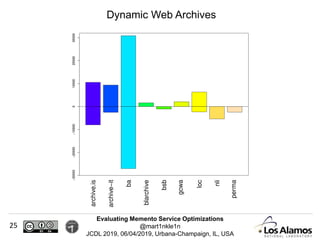


The document discusses optimizations made to Memento services to improve efficiency. It describes using a cache that achieved a hit rate of around 60% and machine learning models to predict whether archives would have versions of requested URIs. The machine learning reduced the number of requests by around 40% while maintaining over 70% recall. The optimizations saved significant time and resources while maintaining an acceptable level of effectiveness.












































