Download to read offline




![4
Existing tools do not include Linked Data-specific metrics:
Linked data-specific metrics, but no platform [Moller et al, WebScience 2010]
Filling a Gap in Prior Art](https://image.slidesharecdn.com/analytics-eswc2017-20170601-170601143958/85/Traffic-Analytics-for-Linked-Data-Publishers-4-320.jpg)







![14
Visitor Session Detection
Session: sequence of requests issued with no significant
interruptions by a uniquely identified visitor. Expires after a
period of inactivity.
We use the HAC variant by [Murray et al. 2006, Mehrzadi et al. 2012]
Unsupervised, gap-based session boundary detection
Traditional web logs analysis
Benefit: visitor-specific temporal cut-off
Two-step procedure:
Set visitor-specific session cut-off as time interval that significantly
increases the variance.
Group HTTP/SPARQL requests into sessions according to the cut-off](https://image.slidesharecdn.com/analytics-eswc2017-20170601-170601143958/85/Traffic-Analytics-for-Linked-Data-Publishers-14-320.jpg)









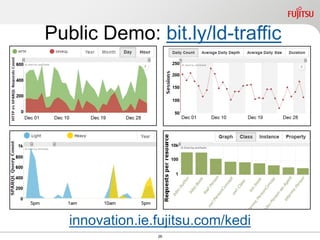

The document discusses a traffic analytics platform designed for linked data publishers, addressing the lack of tools for measuring access to RDF datasets. It outlines challenges such as client session detection, traffic metrics extraction, and noise filtering while providing insights into heavy and light SPARQL queries. The project aims to automate access log mining, support linked data-specific metrics, and enhance understanding of user interactions with linked data infrastructure.






















































