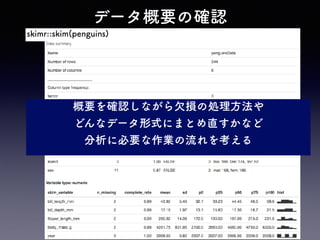
データの結合
関数 動作
left_join(x, y,by = z ) xを基準に結合
right_join(x, y, by = z ) yを基準に結合
inner_join(x, y, by = z ) x,y両方に存在する行のみ結合
full_join(x, y, by = z ) x,y両方の行を結合
anti_join(x, y, by = z ) yと紐づかないxを返す
*複数列をkeyにjoinする場合
by = c( z , zz )
*keyにする列名が異なる場合
by = c( z = zz )































![[データマイニング+WEB勉強会][R勉強会] はじめてでもわかる 統計解析・データマイニング R言語入門](https://cdn.slidesharecdn.com/ss_thumbnails/rlecturehamada100213-100216161757-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
























