Download as PDF, PPTX




























![7 Key Recipes For Data Eng
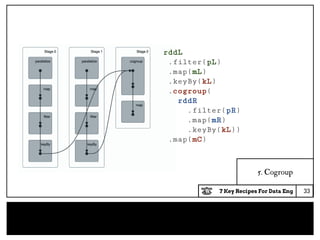
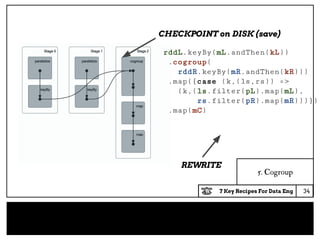
Cogroup API
from (left:RDD[(K,A)],right:RDD[(K,B)])
○ join : RDD[(K,( A , B ))]
○ outerJoin : RDD[(K,(Option[A],Option[B]))]
○ cogroup : RDD[(K,( Seq[A], Seq[B]))]
from (rdd:RDD[(K,A)])
○ groupBy : RDD[(K,Seq[A])]
On cogroup and groupBy, for a given key:K, there is only
one unique row with that key in the output dataset.
5. Cogroup
32
cogroup と groupBy は任意のキーに対して単一の行を返す](https://image.slidesharecdn.com/jpscalamatsuri-7keyrecipesfordataengineering2-170326145607/85/7-key-recipes-for-data-engineering-32-320.jpg)
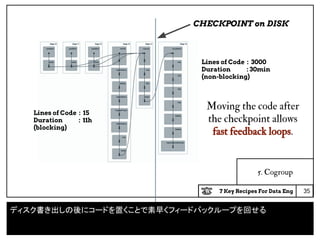





case class Annotation(path:String,
typeName:String,
msg:String,
discardedData:Seq[String],
entityIdType:Option[String],
entityId:Option[String],
level:Int,
stage:String)
6. Inline data quality
40](https://image.slidesharecdn.com/jpscalamatsuri-7keyrecipesfordataengineering2-170326145607/85/7-key-recipes-for-data-engineering-40-320.jpg)

Result is either:
● Containing a value, with a list of warnings,
● Empty, with a list containing the error and
warnings.
(Serialization and Big Data don’t like Sum types, so it’s pre-projected
onto a product type)
6. Inline data quality
41
値を持つか、Empty の二値
それぞれ警告やエラーを表す注釈も持つ](https://image.slidesharecdn.com/jpscalamatsuri-7keyrecipesfordataengineering2-170326145607/85/7-key-recipes-for-data-engineering-41-320.jpg)

Then we can use applicatives to combine results.
case class Person(name:String,age:Int)
def build(name:Result[String],
age:Result[Int]):Result[Person] =
...
6. Inline data quality
42
アプリカティブを使って結果を組み合わせる](https://image.slidesharecdn.com/jpscalamatsuri-7keyrecipesfordataengineering2-170326145607/85/7-key-recipes-for-data-engineering-42-320.jpg)

The annotations are accumulated at the top of
the hierarchy, and saved with the data:
6. Inline data quality
43
注釈は蓄積されて、データと一緒に保存される](https://image.slidesharecdn.com/jpscalamatsuri-7keyrecipesfordataengineering2-170326145607/85/7-key-recipes-for-data-engineering-43-320.jpg)

![7 Key Recipes For Data Eng
6. Inline data quality
If you are interested by the approach, you can take a look at
this repository:
Macros based on Shapeless to build Result[T] from case classes.
https://github.com/ahoy-jon/autoBuild (~october 2015)
45
気になった人はレポジトリをみてください](https://image.slidesharecdn.com/jpscalamatsuri-7keyrecipesfordataengineering2-170326145607/85/7-key-recipes-for-data-engineering-45-320.jpg)









This document provides an overview of 7 key recipes for data engineering: 1. Focus on organizational contexts as the most difficult problems and durable solutions come from organizational contexts. 2. Optimize work by considering lead time, impact, and failure management when making decisions. 3. Stage data persistently using solutions like Kafka and HDFS to retain data for long periods of time. 4. Use RDDs for ETL workloads and dataframes for exploration, lightweight jobs, and dynamic jobs. 5. Leverage cogroups to efficiently link different data sources together. 6. Integrate data quality checks directly into jobs to improve resilience to bad data. 7. Design real programs using stateless computations













































![[DSC Europe 25] Ekaterina Bubenko - Behind the Curtain: How Data Roles Collab...](https://cdn.slidesharecdn.com/ss_thumbnails/anmv6x8dstqbbzchoklr-ekaterina-bubenko-behind-the-curtain-how-data-roles-collaborate-in-the-ai-era-a-260123083019-4b252ec7-thumbnail.jpg?width=640&height=640&fit=bounds)










