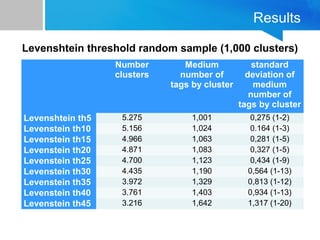
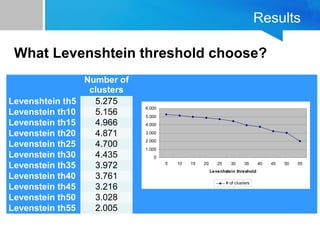
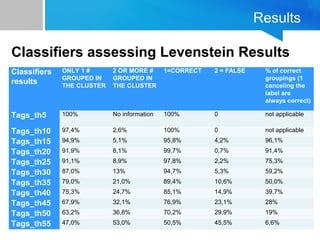
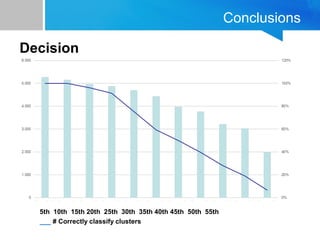
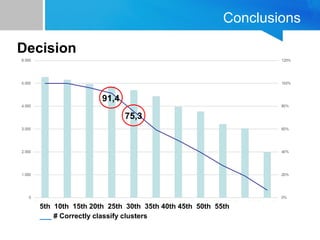
The document discusses the process of filtering and coding big data from Twitter, specifically related to the theme of evictions in Spain. It outlines the challenges of dealing with big data, especially regarding efficiency and effectiveness in information retrieval, as well as the methodology for automatic processing of tweets. The findings suggest the importance of balancing data reduction and classification accuracy when analyzing social media data.