Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Masahiko Hashimoto
1,756 views
OSSかな漢字変換『Egoistic Lily』の紹介&今後の展望
IM飲み会2019で紹介したスライドです。 KOFのスライドよりやや高度な内容…?
Technology
◦
Read more
2
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 24
2
/ 24
3
/ 24
4
/ 24
5
/ 24
6
/ 24
7
/ 24
8
/ 24
9
/ 24
10
/ 24
11
/ 24
12
/ 24
13
/ 24
14
/ 24
15
/ 24
16
/ 24
17
/ 24
18
/ 24
19
/ 24
20
/ 24
21
/ 24
22
/ 24
23
/ 24
24
/ 24
More Related Content
PDF
DNNを使用した新しいかな漢字変換『EgoisticLily』 その仕組みとは?
by
Masahiko Hashimoto
PDF
自作かな漢字変換「Genji」をつくったよ
by
Masahiko Hashimoto
PDF
Advanced Microeconomics - Lecture Slides
by
Yosuke YASUDA
PPTX
名のあるフラクタルたち
by
Yu(u)ki IWABUCHI
PDF
BERT入門
by
Ken'ichi Matsui
PDF
最小カットを使って「燃やす埋める問題」を解く
by
shindannin
PDF
研究室における研究・実装ノウハウの共有
by
Naoaki Okazaki
PDF
データでみる機械学習と制御理論の類似点と相違点
by
Ichiro Maruta
DNNを使用した新しいかな漢字変換『EgoisticLily』 その仕組みとは?
by
Masahiko Hashimoto
自作かな漢字変換「Genji」をつくったよ
by
Masahiko Hashimoto
Advanced Microeconomics - Lecture Slides
by
Yosuke YASUDA
名のあるフラクタルたち
by
Yu(u)ki IWABUCHI
BERT入門
by
Ken'ichi Matsui
最小カットを使って「燃やす埋める問題」を解く
by
shindannin
研究室における研究・実装ノウハウの共有
by
Naoaki Okazaki
データでみる機械学習と制御理論の類似点と相違点
by
Ichiro Maruta
What's hot
PPTX
全脳アーキテクチャ若手の会 機械学習勉強会 ベイジアンネットワーク
by
Erika_Fujita
PPTX
組合せ最適化を体系的に知ってPythonで実行してみよう PyCon 2015
by
SaitoTsutomu
PDF
形態素解析の過去・現在・未来
by
Preferred Networks
PDF
[DL輪読会]Attention is not Explanation (NAACL2019)
by
Deep Learning JP
PDF
マッチングの仕組み
by
Yosuke YASUDA
PPTX
メッセージとストーリーのない発表はカスだ アカデミック・プレゼンテーションのコツ
by
Kei Gomi
PDF
国際会議運営記
by
Takayuki Itoh
PDF
「世界モデル」と関連研究について
by
Masahiro Suzuki
PDF
暗号文のままで計算しよう - 準同型暗号入門 -
by
MITSUNARI Shigeo
PDF
異常検知と変化検知 第4章 近傍法による異常検知
by
Ken'ichi Matsui
PDF
ICPC国内予選F解説
by
tmaehara
PPTX
論文の図表レイアウト例
by
Sunao Hara
PDF
学振特別研究員になるために~知っておくべき10のTips~
by
Masahito Ohue
PPTX
強化学習アルゴリズムPPOの解説と実験
by
克海 納谷
PDF
何となく勉強した気分になれるパーサ入門
by
masayoshi takahashi
PDF
学振特別研究員になるために~2023年度申請版
by
Masahito Ohue
PDF
双対性
by
Yoichi Iwata
PDF
工学系大学4年生のための論文の読み方
by
ychtanaka
PDF
Convex Hull Trick
by
HCPC: 北海道大学競技プログラミングサークル
PDF
【DL輪読会】Mastering Diverse Domains through World Models
by
Deep Learning JP
全脳アーキテクチャ若手の会 機械学習勉強会 ベイジアンネットワーク
by
Erika_Fujita
組合せ最適化を体系的に知ってPythonで実行してみよう PyCon 2015
by
SaitoTsutomu
形態素解析の過去・現在・未来
by
Preferred Networks
[DL輪読会]Attention is not Explanation (NAACL2019)
by
Deep Learning JP
マッチングの仕組み
by
Yosuke YASUDA
メッセージとストーリーのない発表はカスだ アカデミック・プレゼンテーションのコツ
by
Kei Gomi
国際会議運営記
by
Takayuki Itoh
「世界モデル」と関連研究について
by
Masahiro Suzuki
暗号文のままで計算しよう - 準同型暗号入門 -
by
MITSUNARI Shigeo
異常検知と変化検知 第4章 近傍法による異常検知
by
Ken'ichi Matsui
ICPC国内予選F解説
by
tmaehara
論文の図表レイアウト例
by
Sunao Hara
学振特別研究員になるために~知っておくべき10のTips~
by
Masahito Ohue
強化学習アルゴリズムPPOの解説と実験
by
克海 納谷
何となく勉強した気分になれるパーサ入門
by
masayoshi takahashi
学振特別研究員になるために~2023年度申請版
by
Masahito Ohue
双対性
by
Yoichi Iwata
工学系大学4年生のための論文の読み方
by
ychtanaka
Convex Hull Trick
by
HCPC: 北海道大学競技プログラミングサークル
【DL輪読会】Mastering Diverse Domains through World Models
by
Deep Learning JP
More from Masahiko Hashimoto
PDF
Dockerいろいろ使って思うこと
by
Masahiko Hashimoto
PDF
BrowserMob-Proxyのお話
by
Masahiko Hashimoto
PDF
DeepLearning入門以前
by
Masahiko Hashimoto
PDF
かな漢字変換ソフト「Genji」をつくってみた
by
Masahiko Hashimoto
PDF
あひるに焼かれた話と今後のおーぷん万葉について
by
Masahiko Hashimoto
PDF
ホットな日本語入力技術のお勉強。〜 OSC 2016 Hamanako 編 〜
by
Masahiko Hashimoto
PDF
おーぷん万葉プロジェクトとは
by
Masahiko Hashimoto
PDF
C++アプリをCmakeとEclipseで開発するお話
by
Masahiko Hashimoto
PDF
おーぷん万葉プロジェクトの進捗とIzumoのその後
by
Masahiko Hashimoto
PDF
ホットな日本語技術の(ちょっとした)お勉強。
by
Masahiko Hashimoto
PDF
京都発祥日本語入力「FreeWnn」は(今度こそ)どこまで賢くなれるか?
by
Masahiko Hashimoto
PDF
TrieとLOUDS??
by
Masahiko Hashimoto
PDF
C言語なWebSocketの遊び方。
by
Masahiko Hashimoto
PDF
アヒルヤキを変換してみよう
by
Masahiko Hashimoto
PDF
Nginxで日本語入力を遊んでみよう!
by
Masahiko Hashimoto
PDF
続・Cannaをフォークしてみた
by
Masahiko Hashimoto
PDF
Cannaをフォークしてみた
by
Masahiko Hashimoto
PDF
秘伝:クラウドに開発環境をえいっ!と構築する方法
by
Masahiko Hashimoto
PDF
AzureとSUSE Studioのあつ~い関係
by
Masahiko Hashimoto
PDF
X window managerで遊んでみた
by
Masahiko Hashimoto
Dockerいろいろ使って思うこと
by
Masahiko Hashimoto
BrowserMob-Proxyのお話
by
Masahiko Hashimoto
DeepLearning入門以前
by
Masahiko Hashimoto
かな漢字変換ソフト「Genji」をつくってみた
by
Masahiko Hashimoto
あひるに焼かれた話と今後のおーぷん万葉について
by
Masahiko Hashimoto
ホットな日本語入力技術のお勉強。〜 OSC 2016 Hamanako 編 〜
by
Masahiko Hashimoto
おーぷん万葉プロジェクトとは
by
Masahiko Hashimoto
C++アプリをCmakeとEclipseで開発するお話
by
Masahiko Hashimoto
おーぷん万葉プロジェクトの進捗とIzumoのその後
by
Masahiko Hashimoto
ホットな日本語技術の(ちょっとした)お勉強。
by
Masahiko Hashimoto
京都発祥日本語入力「FreeWnn」は(今度こそ)どこまで賢くなれるか?
by
Masahiko Hashimoto
TrieとLOUDS??
by
Masahiko Hashimoto
C言語なWebSocketの遊び方。
by
Masahiko Hashimoto
アヒルヤキを変換してみよう
by
Masahiko Hashimoto
Nginxで日本語入力を遊んでみよう!
by
Masahiko Hashimoto
続・Cannaをフォークしてみた
by
Masahiko Hashimoto
Cannaをフォークしてみた
by
Masahiko Hashimoto
秘伝:クラウドに開発環境をえいっ!と構築する方法
by
Masahiko Hashimoto
AzureとSUSE Studioのあつ~い関係
by
Masahiko Hashimoto
X window managerで遊んでみた
by
Masahiko Hashimoto
OSSかな漢字変換『Egoistic Lily』の紹介&今後の展望
1.
OSSかな漢字変換 『Egoistic Lily』 の紹介 &
今後の展望 はしもとまさひこ@おーぷん万葉 feat.XDDC IM飲み会 2019 2019/12/28
2.
2019/12/28OSSかな漢字変換『Egoistic Lily』 2/24 自己紹介 Name: はしもとまさ(または鹿) Twitter: @shikanotsukimi ● 東海道らぐ
(Tokaido Liuxn Uesr Gruop) ● おーぷん万葉プロジェクト オープンデータを使用したかな漢字変換の自作など ● ちびぎーこ保護者会(別名:日本openSUSEユーザ会) ● 仕事は自然言語処理界隈では(たぶん)ない人
3.
2019/12/28OSSかな漢字変換『Egoistic Lily』 3/24 『XDDC』とは 正式名称: 『Cross
Distribution Developers Camp』 Linuxディストリビューションの枠を超えて 各個撃破…じゃなかった、課題解決しよう!という集まり 参加Linuxディストリビューション – Debian – openSUSE – Ubuntu
4.
2019/12/28OSSかな漢字変換『Egoistic Lily』 4/24 今日のお話 DNNを使用したOSS新かな漢字変換 『Egoistic
Lily』のお話です ※XDDCの課題のひとつ = かな漢字変換
5.
2019/12/28OSSかな漢字変換『Egoistic Lily』 5/24 ※おさらい
Mozc 〜 Since 2010 〜 Google日本語入力のオープンソース版 現在のLinuxデフォルトといえばほぼこれ! – Ubuntu、Debian、openSUSE… – 例外: RedHat系(Fedora、CentOS) Mecab と似たアルゴリズム…?
6.
2019/12/28OSSかな漢字変換『Egoistic Lily』 6/24 Mozcの問題点 ● 現在開発が停止してしまっている… –
例えば『令和』 この単語を追加するのに 各ディストリビューション毎に対応する必要が 発生してしまっている状況 (Debian, Ubuntu, openSUSE...) – 連接コストについては『平成』からの丸パクリ対応 – 但し、単語生起コストについては適当な値を入れるしかない ※コーパスを使用しているわけではない
7.
2019/12/28OSSかな漢字変換『Egoistic Lily』 7/24 そしたらよく言われるの…… AIでなんとか ごにょごにょすればいいじゃん!! これ仕事してるとよく言われるやつ…
8.
2019/12/28OSSかな漢字変換『Egoistic Lily』 8/24 が。 『Egoistic
Lily』は 本当にDNNでどうにかしてしまいました 注:RNNではありません
9.
2019/12/28OSSかな漢字変換『Egoistic Lily』 9/24 使用しているモデル
= AutoEncoder 入力をエンコードして、特徴抽出した後 デコードしてデータを復元し、入力値と比較する ⇛きちんと復元できればそれって異常なし! 異常検知などでわりとどこでも使われてる一般的なモデルですね 入力 出力 特徴抽出 二乗誤差を算出して 誤差が大きい 異常度が高い⇛
10.
2019/12/28OSSかな漢字変換『Egoistic Lily』 10/24 異常度が高い日本語って? 「私の名前は中野です」=正常 「私が名前は中野です」=異常 何故これが異常と言えるのか?
11.
2019/12/28OSSかな漢字変換『Egoistic Lily』 11/24 係り受けの関係に着目 ● 「私
/ の / 名前」 ⇛「私」が「名前」に係っている 「私」と「名前」という単語を「の」が結んでいる ● 「私 / が / 名前」 ⇛「私」が「名前」に係っていない 上記の3単語は関連性がない つまり、3単語をペアにして、正常か否かを学習させてみる
12.
2019/12/28OSSかな漢字変換『Egoistic Lily』 12/24 とりあえずの実装(1) 1.係り受けで紐づく3単語をセットにして抽出 ⇛それぞれの単語に16bitの乱数を設定 ⇛16列のベクトル(0
or 1)に変換して 3単語 × 16bit = 48列をひとつの学習データとする 1 0 0 1 …… 1 0 1 1 1 …… 0 1 1 1 0 …… 0 私 の 名前 合計48bitの 0 or 1 をAutoEncoderの入力へ 単語ごとに テキトーな乱数を 16bit化
13.
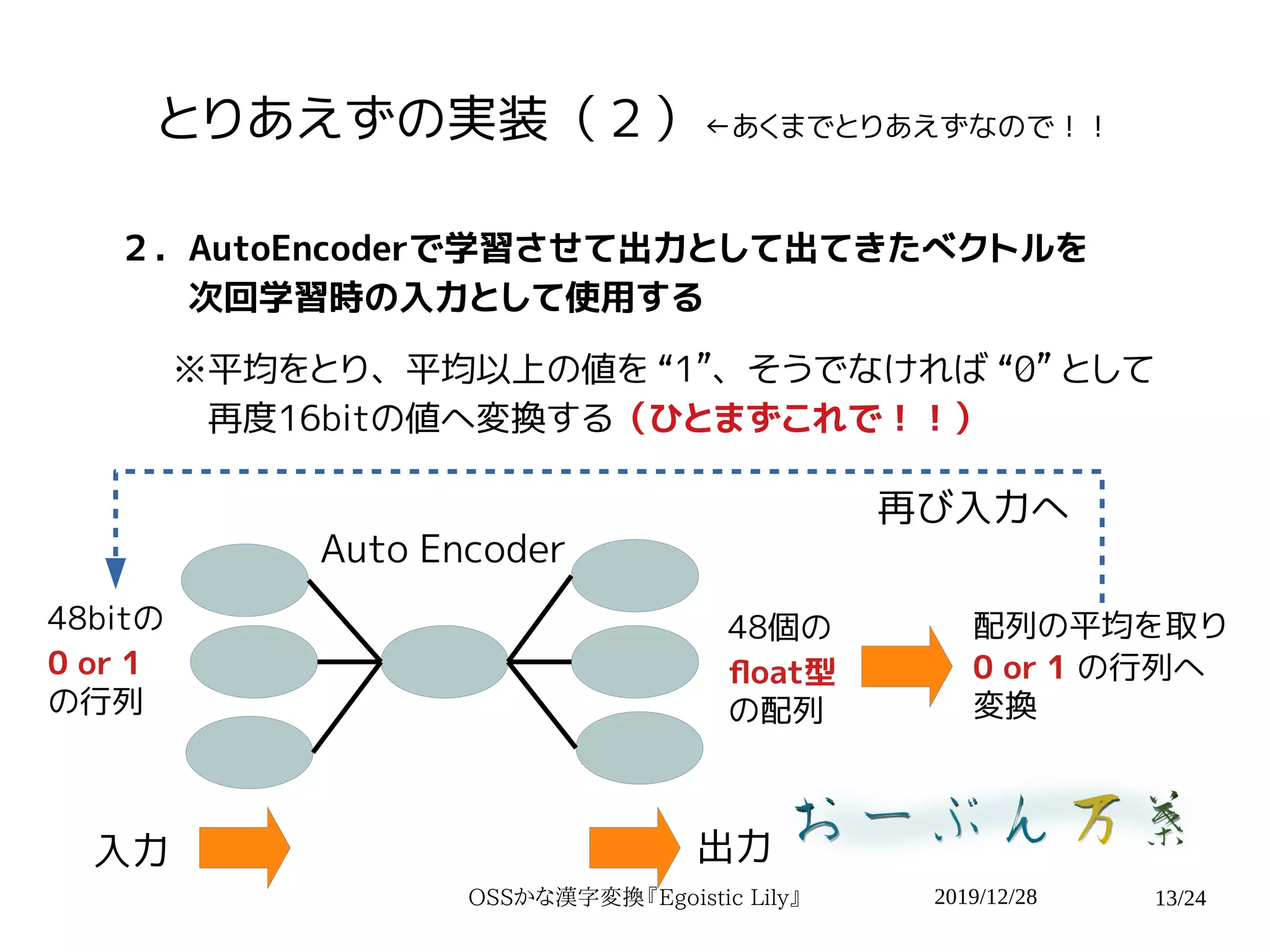
2019/12/28OSSかな漢字変換『Egoistic Lily』 13/24 とりあえずの実装(2)←あくまでとりあえずなので!! 2.AutoEncoderで学習させて出力として出てきたベクトルを 次回学習時の入力として使用する ※平均をとり、平均以上の値を
“1”、そうでなければ “0” として 再度16bitの値へ変換する(ひとまずこれで!!) 入力 出力 48bitの 0 or 1 の行列 48個の float型 の配列 Auto Encoder 配列の平均を取り 0 or 1 の行列へ 変換 再び入力へ
14.
2019/12/28OSSかな漢字変換『Egoistic Lily』 14/24 とりあえずの実装(3)
※補足編 実際はこれを一つの正常データとして学習してます 01…000…010…0 1 0 0 1 …… 1 0010000 係り受け解析から得た 単語ベクトル 単語の品詞情報 ※one-hot 名前のの私 直前の単語係り元文節 の付属部 係り元文節 の自立部 これを正常データとして学習 ⇛学習&変換に使用します Mozcでいうところの連接コストをDNNで求めるイメージ ⇛最終的にはコスト最小法で変換を行います
15.
2019/12/28OSSかな漢字変換『Egoistic Lily』 15/24 とりあえずの実装(4)
※補足編 実際の変換の肝となる部分 01…000…010…0 1 0 0 1 …… 1 0010000 係り受け解析から得た 単語ベクトル 単語の品詞情報 ※one-hot 名前のの私 直前の単語係り元文節 の付属部 係り元文節 の自立部 この部分だけを見れば 従来の単語N-gramの変換をDNNで求めてるとも 言えますね
16.
2019/12/28OSSかな漢字変換『Egoistic Lily』 16/24 『Egoistic
Lily』…その実態は? Mozcのコスト最小法 + 単語bi-gramによるかな漢字変換 をAutoEncoderを用いて実装した形
17.
2019/12/28OSSかな漢字変換『Egoistic Lily』 17/24 その特徴は? ● RNNよりは学習速度が速い……と思う ● 新単語は品詞情報さえあればそこそこ変換可能 ● 現状、単語生起コストというものが存在しない –
『大阪』と『大坂』の区別不可! ● 事前アノテーションがめっちゃしんどい!! – 現在はKNPを使用(←係り受けを行っているため)
18.
2019/12/28OSSかな漢字変換『Egoistic Lily』 18/24 ところで…… ここにいる皆さんならツッコミたいところが 少なからずあったはず!! その中で一番ツッコみたい箇所といえば?
19.
2019/12/28OSSかな漢字変換『Egoistic Lily』 19/24 きっとココだ!!! 1.係り受けで紐づく3単語をセットにして抽出 ⇛それぞれの単語に16bitの乱数を設定 ⇛16列のベクトル(0
or 1)に変換して 3単語 × 16bit = 48列をひとつの学習データとする 1 0 0 1 …… 1 0 1 1 1 …… 0 1 1 1 0 …… 0 私 の 名前 合計48bitの 0 or 1 をAutoEncoderの入力へ きっとココ!
20.
2019/12/28OSSかな漢字変換『Egoistic Lily』 20/24 ここってそれこそ純粋に… それこそ Word2Vec
とか BERT とかを 使えばいいんじゃないの!?
21.
2019/12/28OSSかな漢字変換『Egoistic Lily』 21/24 悩ましいところ… そのモデル、OSSとして配布しやすい形か? ※主にファイルサイズ的に 正直AutoEncoder程度ならまぁ〜……
22.
2019/12/28OSSかな漢字変換『Egoistic Lily』 22/24 ただし、、、 試してみる価値はありそうなので やってみよう! とは思います。(来年)
23.
2019/12/28OSSかな漢字変換『Egoistic Lily』 23/24 今後のToDo ● TensorFlowからPyTorchへ移植 –
TensorFlow2.0になってから pipのバージョンを上げる必要があるため 『u』で始まるディストリビューション関係者からクレームがw ● 辞書にNEologdを使用したい!! – ただし、現在使用しているのはKNP……orz ● 単語生起コストも実装しないと – FineTuningでなんとかなる……かな? – 『自分でコーパスからモデルを作りたい』という人も…本当にいる? ● 深層学習っぽいことをしたい!←ぉ
24.
2019/12/28OSSかな漢字変換『Egoistic Lily』 24/24 ご清聴、ありがとうございましたm(_
_)m
Download



































![[DL輪読会]Attention is not Explanation (NAACL2019)](https://cdn.slidesharecdn.com/ss_thumbnails/20190412dlhacks-190422080919-thumbnail.jpg?width=640&height=640&fit=bounds)



































