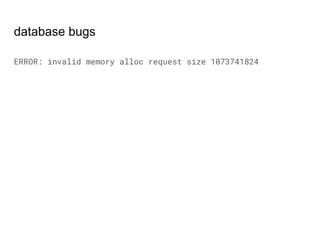
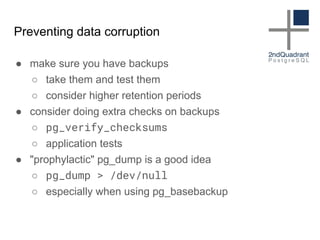
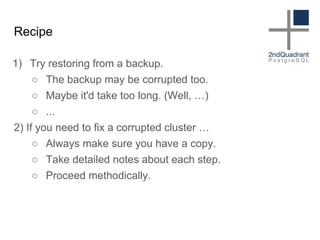
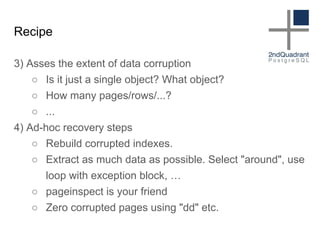
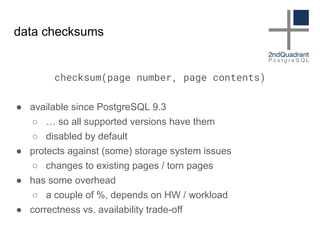
The document discusses data corruption in databases, its causes, and preventive measures. It outlines hardware, software, and administrative mistakes as potential sources of corruption and emphasizes the importance of using good hardware, regular updates, and thorough testing. Additionally, the document highlights the need for backups and explains strategies for fixing corrupted data, while noting the limitations of data checksums in detecting certain corruption types.










































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)















