Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Daisuke Shimada
PDF, PPTX
4,955 views
ITエンジニアのための機械学習理論入門8.1ベイズ推定
ITエンジニアのための機械学習理論入門の読書会で発表した、 8章の前半ベイズ推定についてに関するスライドです。
Technology
◦
Read more
4
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 64
2
/ 64
3
/ 64
4
/ 64
5
/ 64
6
/ 64
7
/ 64
8
/ 64
9
/ 64
10
/ 64
11
/ 64
12
/ 64
13
/ 64
14
/ 64
15
/ 64
16
/ 64
17
/ 64
18
/ 64
19
/ 64
20
/ 64
21
/ 64
22
/ 64
23
/ 64
24
/ 64
25
/ 64
26
/ 64
27
/ 64
28
/ 64
29
/ 64
30
/ 64
31
/ 64
32
/ 64
33
/ 64
34
/ 64
35
/ 64
36
/ 64
37
/ 64
38
/ 64
39
/ 64
40
/ 64
41
/ 64
42
/ 64
43
/ 64
44
/ 64
45
/ 64
46
/ 64
47
/ 64
48
/ 64
49
/ 64
50
/ 64
51
/ 64
52
/ 64
53
/ 64
54
/ 64
55
/ 64
56
/ 64
57
/ 64
58
/ 64
59
/ 64
60
/ 64
61
/ 64
62
/ 64
63
/ 64
64
/ 64
More Related Content
PDF
Dockerことはじめ
by
Daisuke Shimada
PDF
PyMC mcmc
by
Xiangze
PDF
ベイズ推定とDeep Learningを使用したレコメンドエンジン開発
by
LINE Corporation
PDF
機械学習のためのベイズ最適化入門
by
hoxo_m
PDF
機械学習チュートリアル@Jubatus Casual Talks
by
Yuya Unno
PPTX
機械学習基礎(2)(パラメータ推定)
by
mikan ehime
PDF
PRML第3章_3.3-3.4
by
Takashi Tamura
PDF
いいからベイズ推定してみる
by
Makoto Hirakawa
Dockerことはじめ
by
Daisuke Shimada
PyMC mcmc
by
Xiangze
ベイズ推定とDeep Learningを使用したレコメンドエンジン開発
by
LINE Corporation
機械学習のためのベイズ最適化入門
by
hoxo_m
機械学習チュートリアル@Jubatus Casual Talks
by
Yuya Unno
機械学習基礎(2)(パラメータ推定)
by
mikan ehime
PRML第3章_3.3-3.4
by
Takashi Tamura
いいからベイズ推定してみる
by
Makoto Hirakawa
Similar to ITエンジニアのための機械学習理論入門8.1ベイズ推定
PDF
20190512 bayes hands-on
by
Yoichi Tokita
PDF
ベイズ入門
by
Zansa
PDF
Casual learning machine learning with_excel_no3
by
KazuhiroSato8
PDF
bayesian inference
by
Asako Yanuki
PDF
0726
by
RIKEN Center for Integrative Medical Science Center (IMS-RCAI)
PDF
3.4
by
show you
PPTX
PRML 1.2.3 ベイズ確率
by
KokiTakamiya
PDF
単純ベイズ法による異常検知 #ml-professional
by
Ai Makabi
PDF
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
PDF
A09 穴田研究室1 木村優斗,小笠原琉佳,坂本慶多,高橋昂大
by
aomorisix
PDF
Introduction to statistics
by
Kohta Ishikawa
PDF
Prml3 4
by
K5_sem
PDF
Prml3 4
by
K5_sem
PPTX
変分ベイズ法の説明
by
Haruka Ozaki
PDF
20130716 はじパタ3章前半 ベイズの識別規則
by
koba cky
PPTX
PRML読み会第一章
by
Takushi Miki
PDF
Prml1.2.3
by
Tomoyuki Hioki
PDF
20191117_choco_bayes_pub
by
Yoichi Tokita
PDF
PRML 上 1.2.4 ~ 1.2.6
by
禎晃 山崎
PDF
第4章 確率的学習---単純ベイズを使った分類
by
Wataru Shito
20190512 bayes hands-on
by
Yoichi Tokita
ベイズ入門
by
Zansa
Casual learning machine learning with_excel_no3
by
KazuhiroSato8
bayesian inference
by
Asako Yanuki
0726
by
RIKEN Center for Integrative Medical Science Center (IMS-RCAI)
3.4
by
show you
PRML 1.2.3 ベイズ確率
by
KokiTakamiya
単純ベイズ法による異常検知 #ml-professional
by
Ai Makabi
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
A09 穴田研究室1 木村優斗,小笠原琉佳,坂本慶多,高橋昂大
by
aomorisix
Introduction to statistics
by
Kohta Ishikawa
Prml3 4
by
K5_sem
Prml3 4
by
K5_sem
変分ベイズ法の説明
by
Haruka Ozaki
20130716 はじパタ3章前半 ベイズの識別規則
by
koba cky
PRML読み会第一章
by
Takushi Miki
Prml1.2.3
by
Tomoyuki Hioki
20191117_choco_bayes_pub
by
Yoichi Tokita
PRML 上 1.2.4 ~ 1.2.6
by
禎晃 山崎
第4章 確率的学習---単純ベイズを使った分類
by
Wataru Shito
More from Daisuke Shimada
PDF
ブロックチェーンの基礎を学び、未来に活かす。
by
Daisuke Shimada
PDF
既存システムに対するブロックチェーン適用の検証と考察
by
Daisuke Shimada
PDF
Ml4se 2 2_slideshare
by
Daisuke Shimada
PDF
ネタ募集箱を支える技術 開発環境編
by
Daisuke Shimada
ZIP
悩めるWindowsインストーラ制作者の道しるべ
by
Daisuke Shimada
PPTX
悩めるWindowsユーザーの為のコマンドライン入門
by
Daisuke Shimada
ブロックチェーンの基礎を学び、未来に活かす。
by
Daisuke Shimada
既存システムに対するブロックチェーン適用の検証と考察
by
Daisuke Shimada
Ml4se 2 2_slideshare
by
Daisuke Shimada
ネタ募集箱を支える技術 開発環境編
by
Daisuke Shimada
悩めるWindowsインストーラ制作者の道しるべ
by
Daisuke Shimada
悩めるWindowsユーザーの為のコマンドライン入門
by
Daisuke Shimada
ITエンジニアのための機械学習理論入門8.1ベイズ推定
1.
8.1 ベイズ推定モデルとベイズの定理 第8章 ベイズ推定: データを元に「確信」 を高める方法 注意:今回かなり割愛してますがそれでも数式多いです。。
2.
パラメトリックモデルおさらい パラメーターを含むモデル(数式) を設定する パラメーターを評価する基準を定める 最良の評価を与えるパラメーターを 決定する
3.
パラメーターを評価する方法 最小二乗法 誤差を定義して誤差を最小にするよう にする方法 最尤推定法
トレーニングセットが得られる確率で ある尤度関数を定め、これを最大にす るようにする方法
4.
ベイズ推定は? 最小二乗法とも最尤推定法とも違う。 パラメーターそのものについても 「それぞれの値をとる確率」を定義 する、という新しい方法。
5.
最尤推定法と ベイズ推定法を 比較してみる
6.
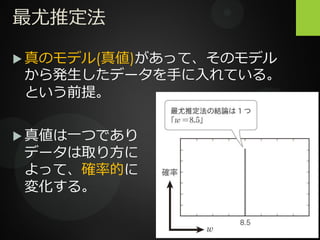
最尤推定法 真のモデル(真値)があって、そのモデル から発生したデータを手に入れている。 という前提。
7.
最尤推定法 真のモデル(真値)があって、そのモデル から発生したデータを手に入れている。 という前提。 真値は一つであり データは取り方に よって、確率的に 変化する。
8.
最尤推定法 例えばコイントス 真値は0.5だけど、たまには0.3 だったり0.7だったりする。
何度もサンプルをとって平均すれ ば0.5に近づいていくはず。 データは確率的だけど、真のモデ ルからは手元のデータが最も得ら れやすいはず、と考える。
9.
最尤推定法 コインを100回投げたら50回表、 50回裏だった。 このデータが最もありえるモデル はなんだろうか?と考える。
このモデルの尤もらしさが尤度で、 尤度を最大にするのが最尤推定法 という。
10.
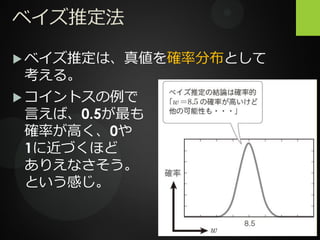
ベイズ推定法 ベイズ推定は、真値を確率分布として 考える。
11.
ベイズ推定法 ベイズ推定は、真値を確率分布として 考える。 コイントスの例で 言えば、0.5が最も 確率が高く、0や 1に近づくほど ありえなさそう。 という感じ。
12.
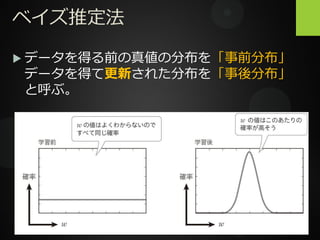
ベイズ推定法 データを得る前の真値の分布を「事前分布」 データを得て更新された分布を「事後分布」 と呼ぶ。
13.
ベイズ推定法 少しずつデータを得て、事後分布をどんど ん更新していくことができる。 この更新をするのに使用するのが、 「ベイズの定理」 トーマス・ベイズ
14.
ベイズの定理入門
15.
簡単な問題を考えてみる 箱の中に「黒」「白」「大」「小」の ボールが入っていて、その中からランダム にボールが出てくるおもちゃがある。
16.
簡単な問題を考えてみる Q1. 出たボールが「黒」の確率。
Q2. 出たボールが「大」と分かっている 場合、それが「黒」の確率。 Q3. 出たボールが「大きな黒」の確率。
17.
Q1. 出たボールが「黒」の確率。 全部で12個、そのうち黒は7個なので
18.
Q2. 出たボールが「大」と分かっている 場合、それが「黒」の確率。 大きいボールは全部で4個、 その中で黒いボールは1個なので
19.
Q3. 出たボールが「大きな黒」の確率。 全部で12個、そのうち大きい黒は1個 なので
20.
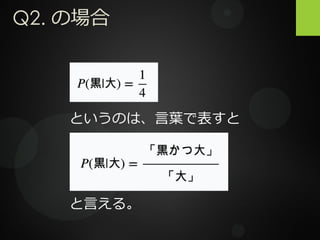
Q2. の場合 というのは、言葉で表すと と言える。
21.
Q3. の場合 というのは、言葉で表すと と言える。
22.
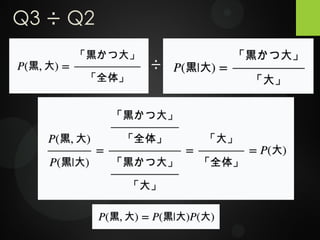
Q3 ÷ Q2 ÷
23.
Q3の黒と大を入替 ÷ Q2
24.
ということは
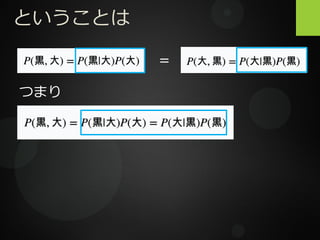
25.
ということは =
26.
ということは = つまり
27.
ということは = つまり 一般化すると となる。
28.
さらにこれは
29.
さらにこれは こうなる
30.
さらにこれは こうなる ベイズの定理
31.
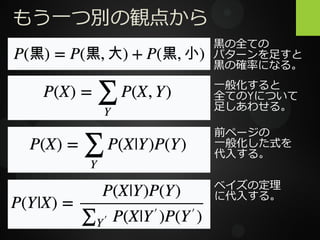
もう一つ別の観点から 黒の全ての パターンを足すと 黒の確率になる。 一般化すると 全てのYについて 足しあわせる。 前ページの 一般化した式を 代入する。 ベイズの定理 に代入する。
32.
ベイズの定理の特徴 左辺は「Xである時のYの確率」 右辺は逆に「Yである時のXの確率」
このように「条件と結果」を入れ替えた 関係を計算するのが特徴となる。
33.
別の問題を考えてみる ピロリ菌感染問題。 太郎さんの年代の感染率は1%
ピロリ菌検査の精度は95% 太郎さんは陽性だった。 この時感染している 確率は何%か?
34.
分かっていること P(感染) =
0.01 P(非感染) = 0.99 P(陽性|感染) = 0.95 P(陰性|感染) = 0.05 P(陽性|非感染)= 0.05 P(陰性|非感染)= 0.95 P(感染|陽性) = ???? (問われている事)
35.
ベイズの定理を適用すると P(感染|陽性) =
???? (問われている事)
36.
図で見てみる 偽陰性 真陽性 真陰性 偽陽性 感染 非感染
37.
陽性全体 真陽性 偽陽性 感染 非感染
38.
問われている、陽性の時の感染 真陽性 感染 非感染
39.
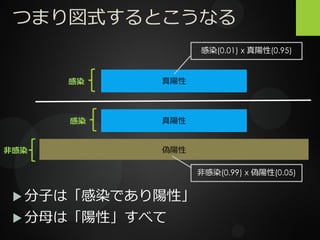
つまり図式するとこうなる 偽陽性 感染 真陽性 真陽性 感染 非感染
40.
つまり図式するとこうなる 偽陽性 感染 真陽性 真陽性 感染 非感染 非感染(0.99) x 偽陽性(0.05) 感染(0.01)
x 真陽性(0.95) 分子は「感染であり陽性」 分母は「陽性」すべて
41.
ベイズ推定による 正規分布の決定 〜パラメーター推定〜
42.
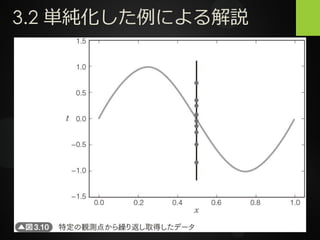
3.2 単純化した例による解説
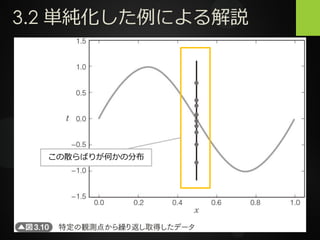
43.
3.2 単純化した例による解説 この散らばりが何かの分布
44.
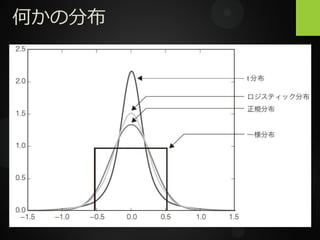
何かの分布
45.
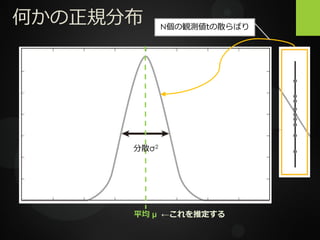
何かの正規分布 平均 μ ←これを推定する 分散σ2 N個の観測値tの散らばり
46.
3.2 単純化した例による解説より 平均μ、標準偏差σの正規分布の場合 ある特定のデータtnが得られる確率は となり、トレーニングセット全体が観測 される確率は全ての掛けあわせなので となる。
47.
あれ?この記号… これは先ほどの例と同じく、 「μであるときのtの確率」を表している。 であれば、ベイズの定理(8.15)に当てはめて みる。
48.
μを求めたいのでP(μ|t)とする 分母は「あらゆるYについて足し合わせる」 という意味のΣがあった。 いま求めるμは正規分布として連続する数 なので、和の代わりに積分を用いる。
49.
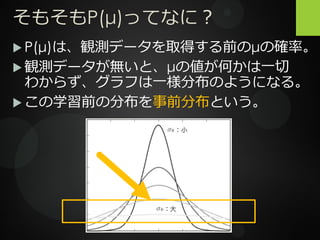
そもそもP(μ)ってなに? P(μ)は、観測データを取得する前のμの確率。 観測データが無いと、μの値が何かは一切 わからず、グラフは一様分布のようになる。
この学習前の分布を事前分布という。
50.
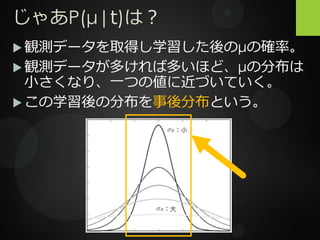
じゃあP(μ|t)は? 観測データを取得し学習した後のμの確率。 観測データが多ければ多いほど、μの分布は 小さくなり、一つの値に近づいていく。
この学習後の分布を事後分布という。
51.
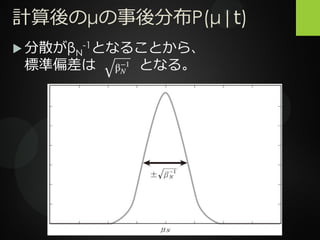
P(μ|t)って結局何なの? 数学徒の小部屋の計算をすると、P(μ|t)は 平均μN、分散βN -1となる。
52.
計算後のμの事後分布P(μ|t) 分散がβN -1となることから、 標準偏差は となる。
53.
分散の値を紐とく 分散βN -1を計算すると、 となる。
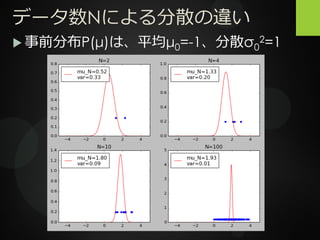
これは、トレーニングセットのデータ数Nが 大きくなるほど分散が小さくなり、分布の 幅が狭くなるということ。 N→∞の極限では、分散は0になり、μの値は 一つに定まる。 =最尤推定法と同じ結果になる。
54.
データ数Nによる分散の違い 事前分布P(μ)は、平均μ0=-1、分散σ0 2=1
55.
ベイズ推定による 正規分布の決定 〜観測値の分布の推定〜
56.
次の値は何か?が知りたい。 いままで見てきたP(μ|t)は、観測データtの 値が得られた時の平均μの確率。 でも本当に知りたいのは次に得られるで あろう観測データtの値。
観測データは、平均μ、分散σ2の正規分布 から得られるという前提だった。
57.
平均μは1つに決まっていない いまベイズ推定では平均μは事後分布として P(μ|t)で与えられている。 この場合「さまざまなμに対する正規分布 N(t
| μ, σ2)をそれぞれの確率P(μ | t)の 重みで足し合わせる」という事をする。
58.
具体的には さまざまなμの確率
59.
具体的には そのμの時のtの正規分布
60.
具体的には 計算するとこうなる 分散σ2 ちょっと大きくなる
61.
分散の増分βN -1 本来β-1が分散としてこのデータの真のモデ ルで定義されている。 ただしβN -1
の分だけ増えている。 これはデータ数Nが少ない時に確信が持てな いので分散を大きくし、Nが増えると確信が 持てるようになって分散が小さくなる。
62.
βN -1はデータ数が多くなれば消える
63.
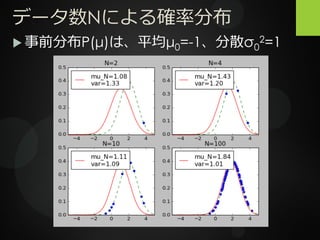
データ数Nによる確率分布 事前分布P(μ)は、平均μ0=-1、分散σ0 2=1
64.
まとめ ベイズ推定はパラメーター自体にその値をと る確率という概念を入れたもの。 最尤推定法と異なり、真値は分布で考える。
十分にデータが多い場合は最尤推定法の結果 と同じになる。 データセットから平均の分散を求め、その 平均の分布から改めて観測データが得られる 確率を求めるという事をする。
Download