Downloaded 10 times








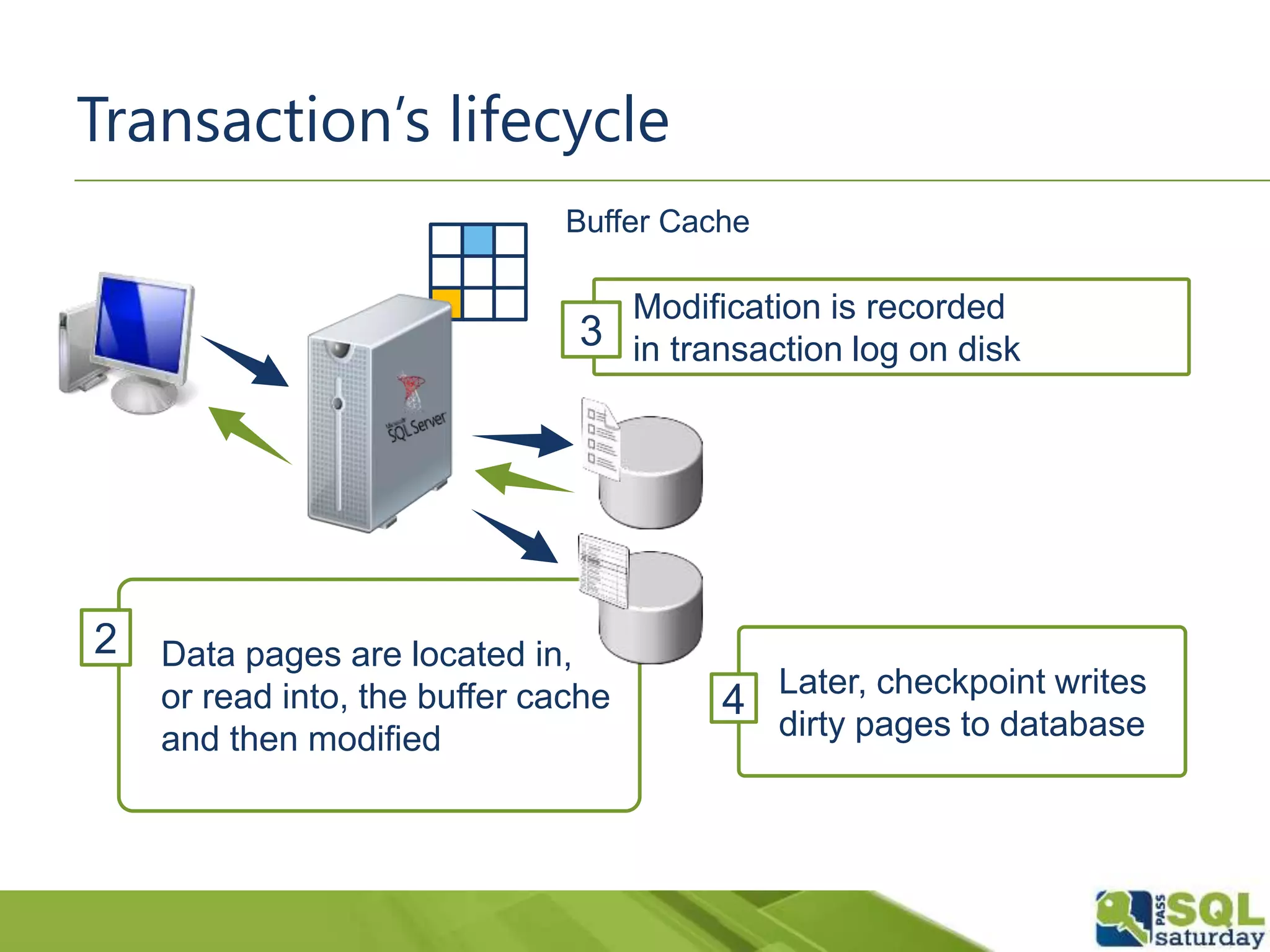
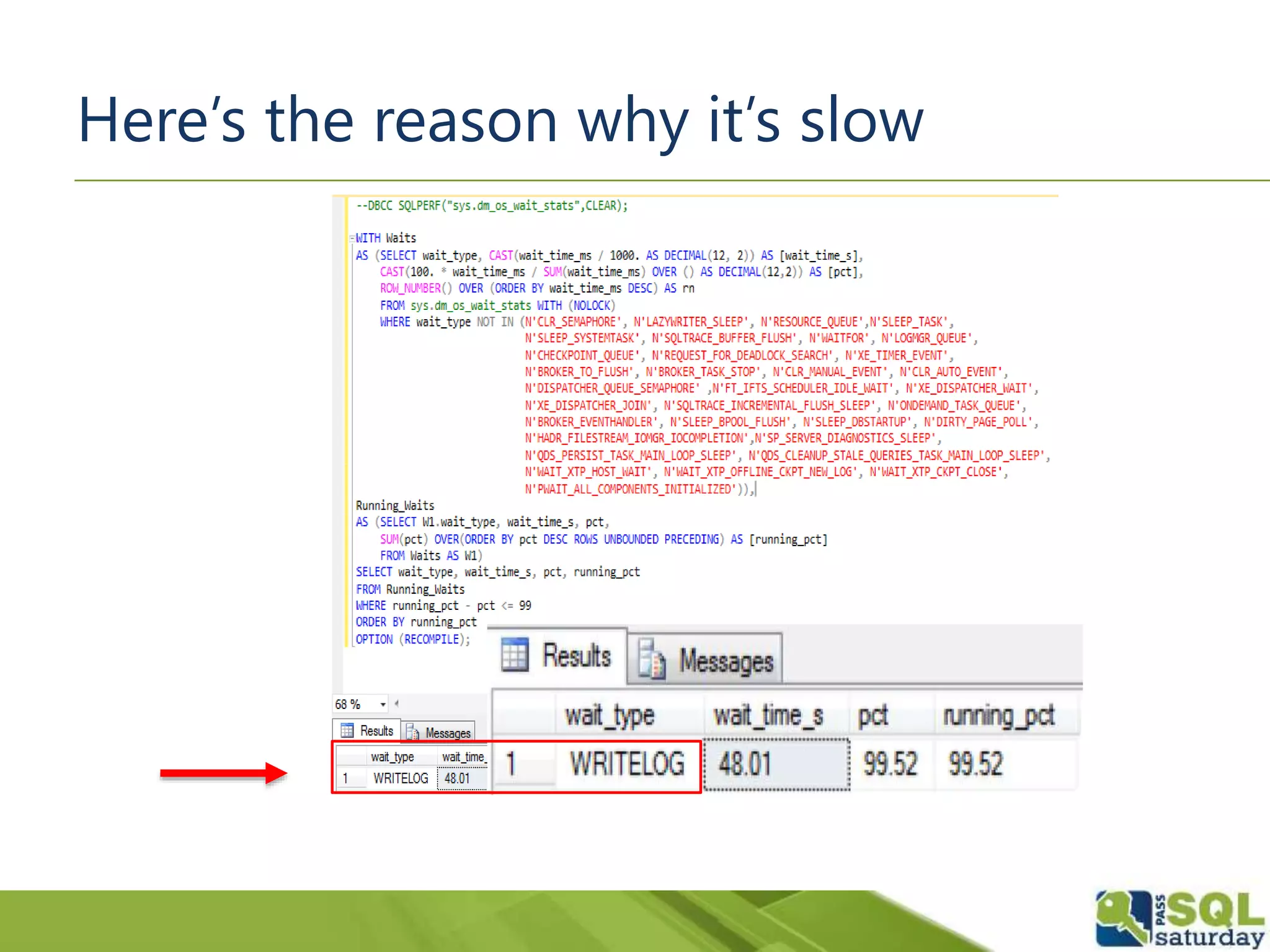
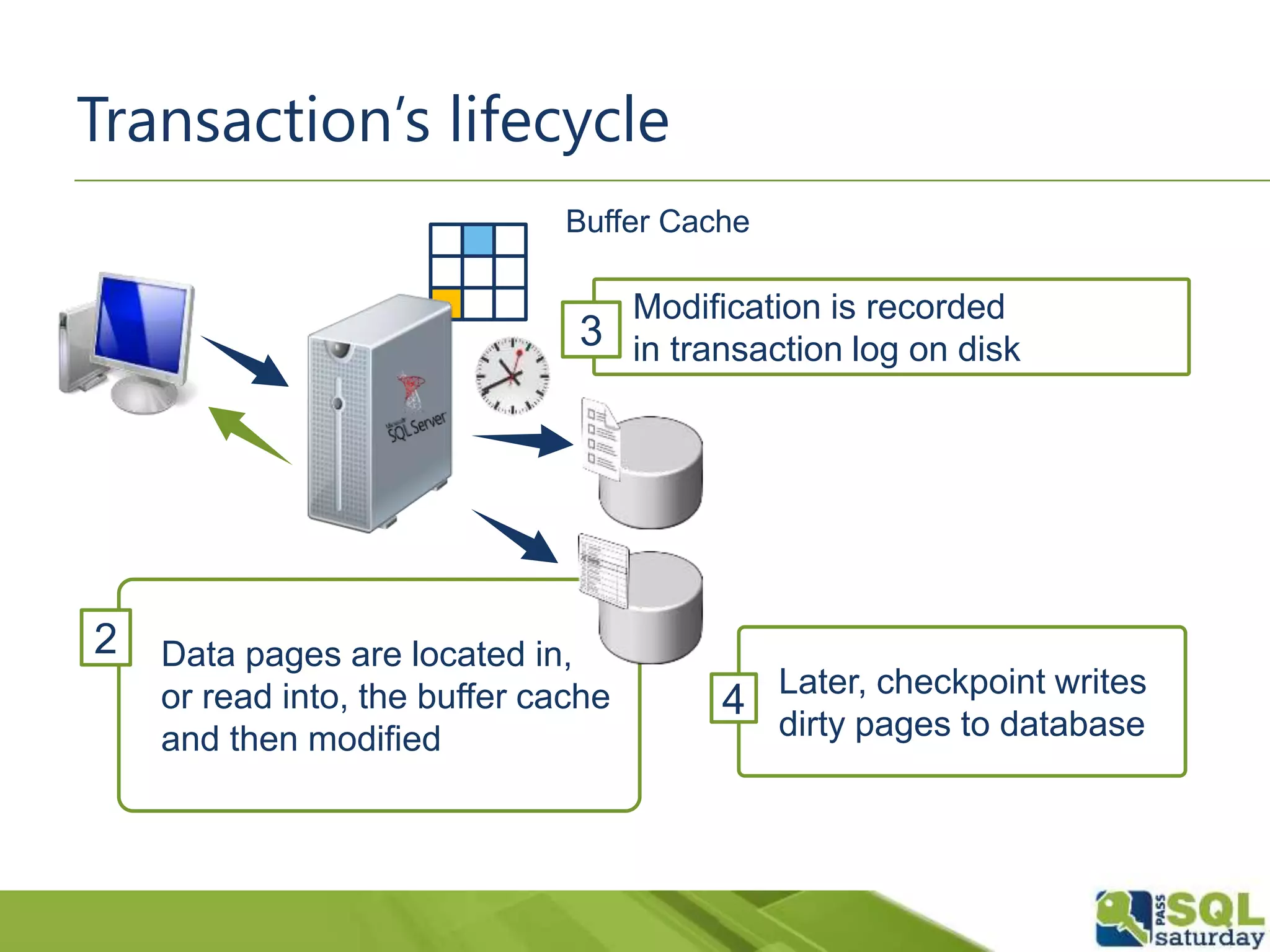







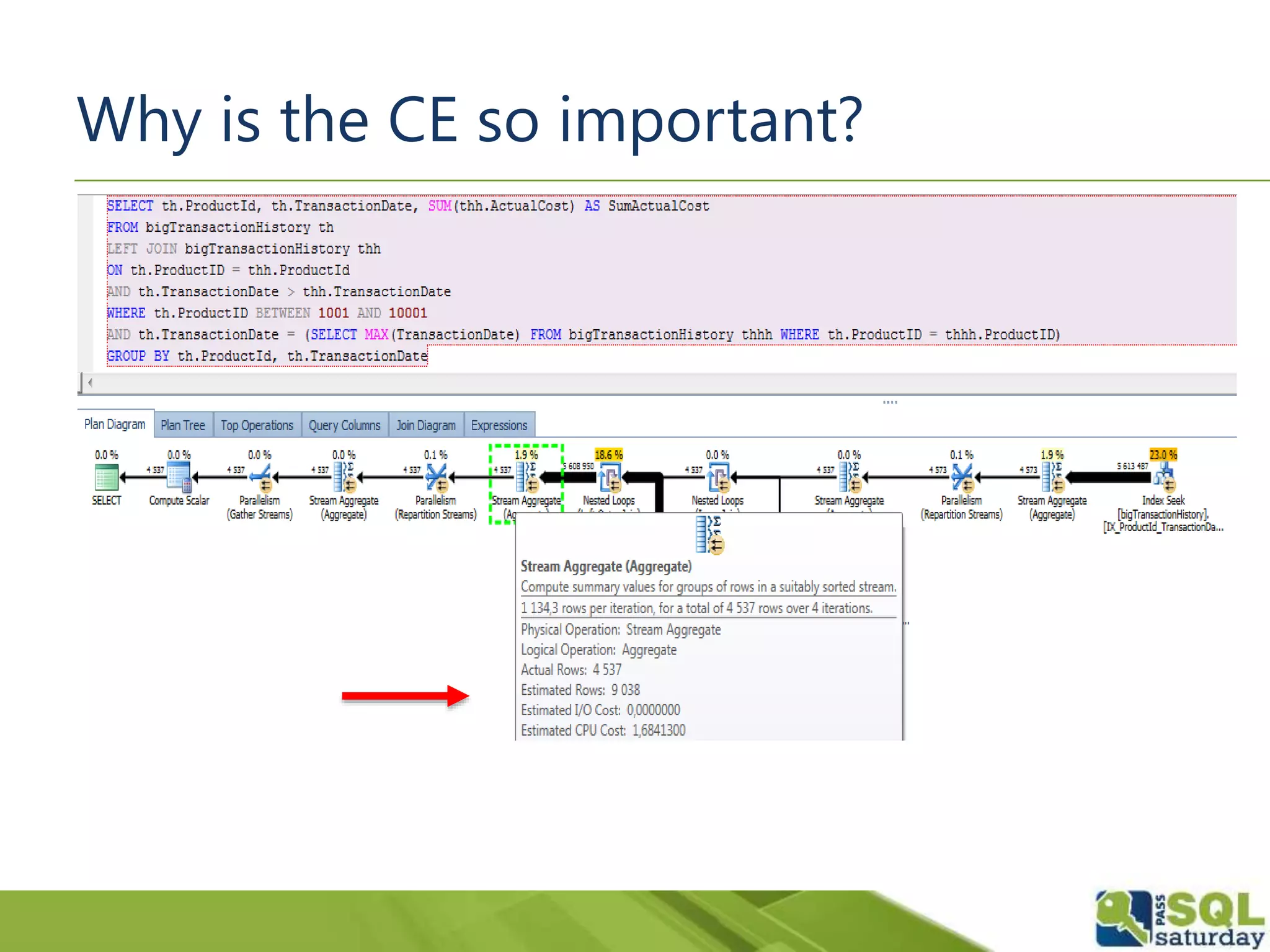














The document discusses five significant T-SQL improvements introduced in SQL Server 2014, including delayed durability, parallel execution plans, an updated cardinality estimator, inline index definitions, and enhanced partitioning features. It emphasizes the importance of proper database design for performance and encourages thorough testing of queries due to changes in estimations. Additional resources for further learning are also provided.

























![[JSS2015] In memory and operational analytics](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-inmemoryandoperationalanalytics-151211084342-thumbnail.jpg?width=640&height=640&fit=bounds)









































