Download to read offline










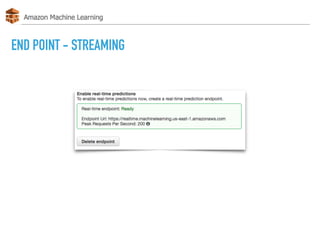
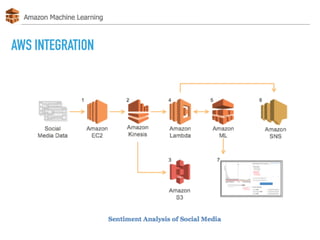





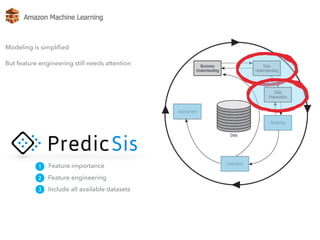
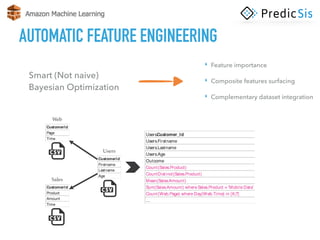

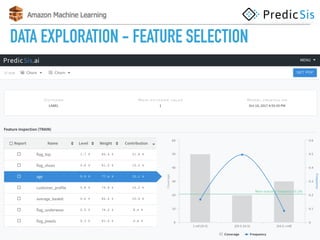
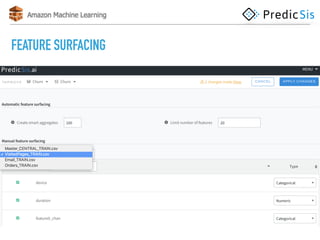
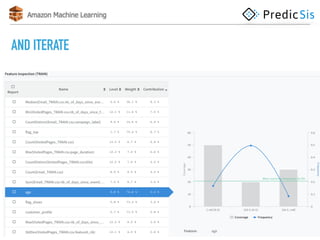
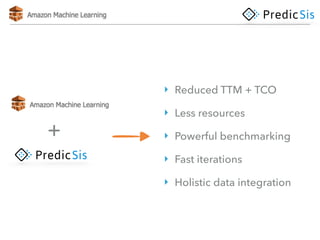
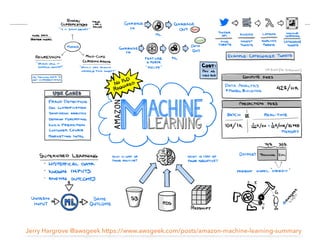


The document discusses AWS Machine Learning, highlighting its predictive analytics capabilities and limitations, including the focus on supervised learning and the absence of deep learning support. It also covers the AWS ML project workflow, data transformation techniques, and potential improvements such as the lack of cross-validation and limited feature engineering. Overall, it emphasizes the need for domain expertise while noting the time-saving benefits of using AWS for machine learning tasks.







![[판교에서 만나는 아마존웹서비스] Obama for America를 통해서 본 AWS에서의 데이터 분석](https://cdn.slidesharecdn.com/ss_thumbnails/ofa-and-redshift-pangyo-131203232750-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)







































