Download to read offline










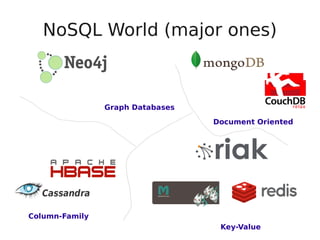



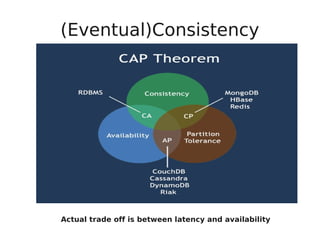





This document provides an overview and introduction to NoSQL databases. It discusses key characteristics of NoSQL such as being non-relational and schemaless. Common data models for NoSQL including document, key-value, and column-family databases are presented. The document also covers distribution models, consistency models, and the NWR consistency framework for NoSQL databases.

















































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)















