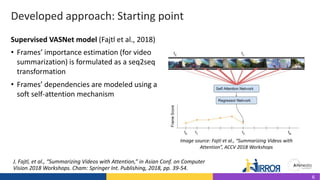
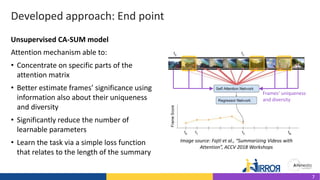
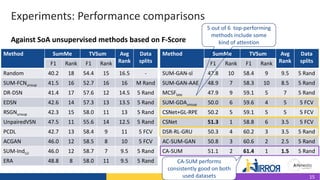
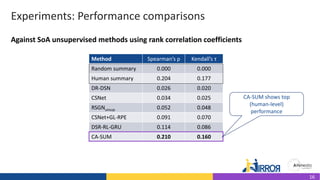
The document discusses the development and evaluation of a new video summarization model called ca-sum, which uses concentrated attention to improve frame significance estimation. It highlights the limitations of existing video summarization techniques and presents experiments demonstrating ca-sum's competitive performance against state-of-the-art methods on benchmark datasets. Overall, the ca-sum model effectively addresses the challenges of unstable training and long-range frame dependencies while producing summaries that align with human expectations.


















![Experiments: Implementation details
• Videos were down-sampled to 2 fps
• Feature extraction: pool5 layer of GoogleNet trained on ImageNet (D = 1024)
• Block size M = 60
• Learning rate and L2 regularization factor: 5 x 10-4 and 10-5 respectively
• Network initialization approach: Xavier uniform (gain = 2; biases = 0.1)
• Training: in a full-batch mode using the Adam optimizer and stops after 400 epochs
• Length regularization factor = [0.5; 0.1; 0.9]
• Model selection is based on a two-step process:
• Keep one model per length regularization factor based on the minimization of the training loss
• Choose the best-performing one via transductive inference and comparison with a fully-untrained model
of the network architecture
13](https://image.slidesharecdn.com/2022-icmr-ca-sum-slideshare-220718135703-eb25c4a9/85/CA-SUM-Video-Summarization-21-320.jpg)
























![[NS][Lab_Seminar_250106]SAM-Aware Graph Prompt Reasoning Network for Cross-Do...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar250106gprn-250106075150-b64c5cde-thumbnail.jpg?width=640&height=640&fit=bounds)

















































