Spark+Cassandra Data pipeline optimazation at recommend system for recommend system
1.
Spark + Cassandra기반 Big Data를 활용한
추천시스템 서빙 파이프라인 최적화
2020.11.26
SSG.COM
박수성
2.
CONTENTS
1. E-commerce DataUse case
2. Data Pipeline with Spark + Cassandra
3. Trouble Shooting & Optimization
4. Q&A
3.
1. E-commerce DataUse case
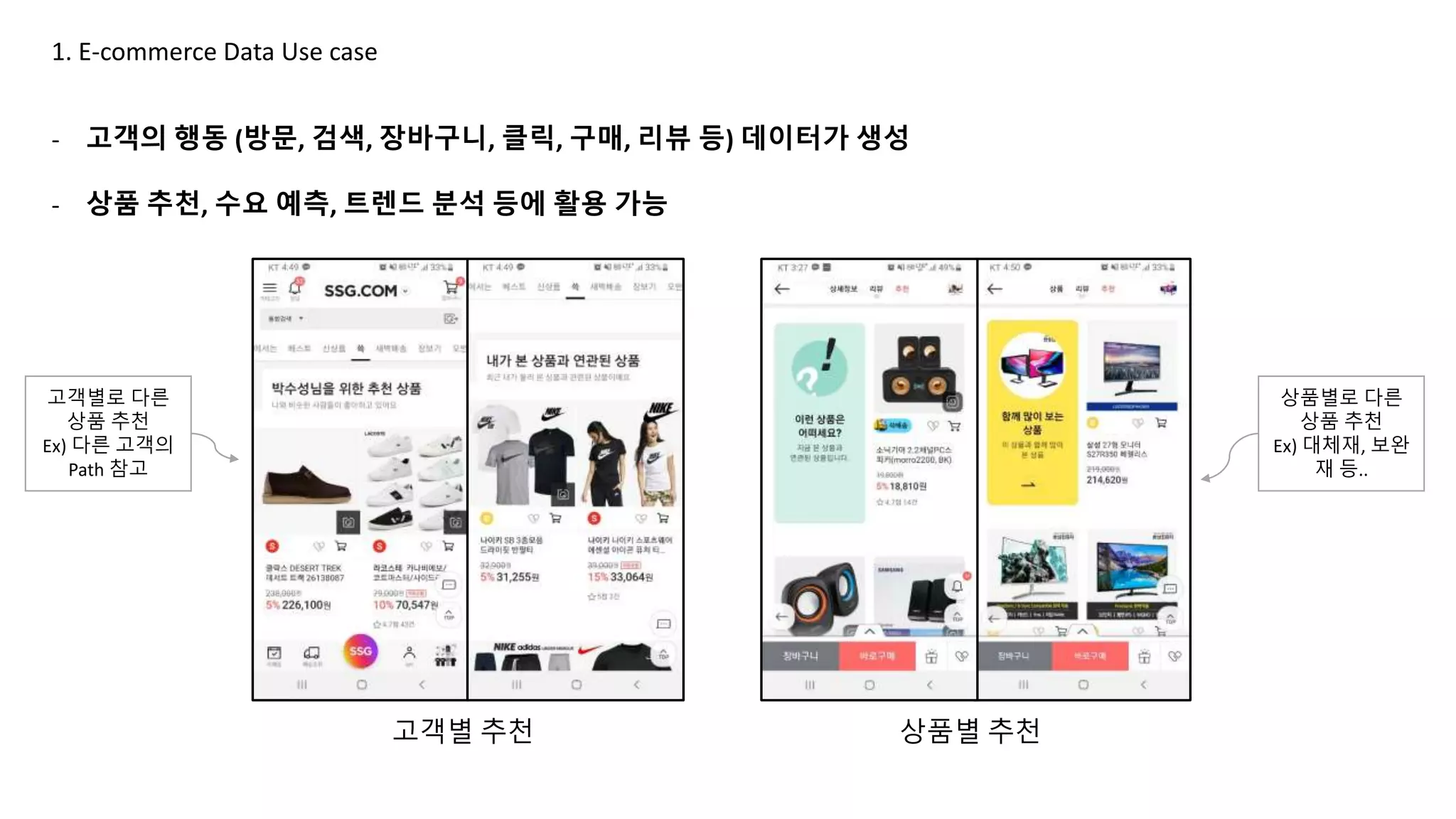
- 고객의 행동 (방문, 검색, 장바구니, 클릭, 구매, 리뷰 등) 데이터가 생성
- 상품 추천, 수요 예측, 트렌드 분석 등에 활용 가능
고객별 추천 상품별 추천
고객별로 다른
상품 추천
Ex) 다른 고객의
Path 참고
상품별로 다른
상품 추천
Ex) 대체재, 보완
재 등..
4.
1. E-commerce DataUse case
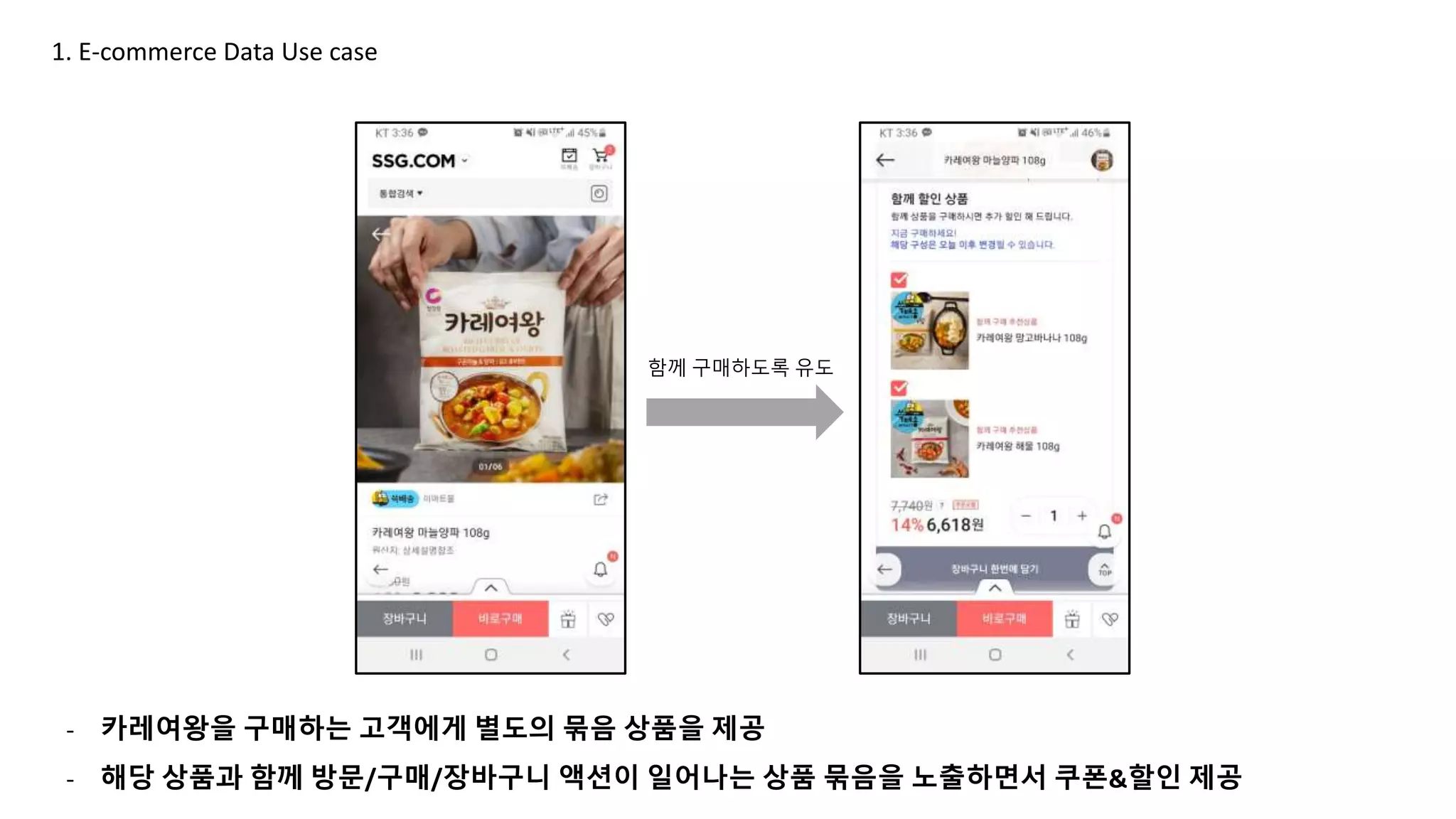
- 카레여왕을 구매하는 고객에게 별도의 묶음 상품을 제공
- 해당 상품과 함께 방문/구매/장바구니 액션이 일어나는 상품 묶음을 노출하면서 쿠폰&할인 제공
함께 구매하도록 유도
5.
1. E-commerce DataUse case
- 수 많은 프레임워크에서는 쉽게 접근이 가능한 알고리즘이 존재
- 전처리, 후처리, 파라미터 조절 만으로도 쉽게 추천 데이터 Set을 만들어낼 수 있음.
Ex) MLlib: Main Guide
- Basic statistics
- Pipelines
- Extracting, transforming and selecting
features
- Classification and Regression
- Clustering
- Collaborative filtering
- Frequent Pattern Mining
- Model selection and tuning
Spark MLlib의 FP-Growth 예제 코드
6.
- 과거에 비해개발자들도 ML에 대한 접근이 쉬워지고 있음.
- 분명 여러 프레임워크에서 제공하는 알고리즘에 부족한 부분이 존재.
- But 꾸준히 발전 중이고 새로운 것이 계속해서 등장.
1. E-commerce Data Use case
7.
- 좋은 알고리즘으로제품을 만들어내는 것도 중요
- 하지만 고객에게 데이터를 서빙할 수 있어야 의미가 있음
- 서빙 파이프라인 구축은 경험과 노하우가 필요
1. E-commerce Data Use case
8.
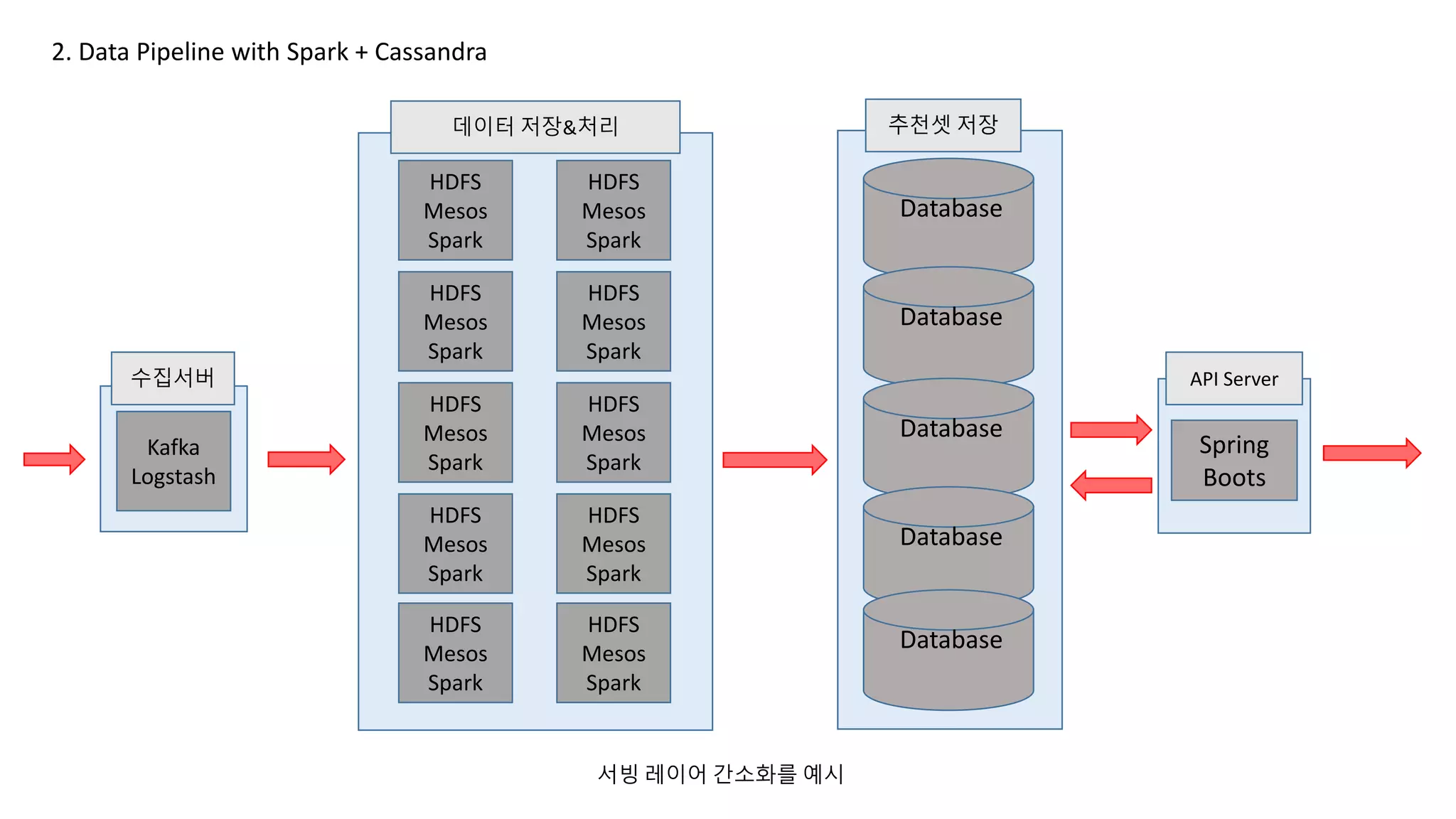
2. Data Pipelinewith Spark + Cassandra
HDFS
Mesos
Spark
HDFS
Mesos
Spark
HDFS
Mesos
Spark
HDFS
Mesos
Spark
HDFS
Mesos
Spark
HDFS
Mesos
Spark
HDFS
Mesos
Spark
HDFS
Mesos
Spark
HDFS
Mesos
Spark
HDFS
Mesos
Spark
Kafka
Logstash
데이터 저장&처리 추천셋 저장
API Server
Database
Database
Database
Database
Database
Spring
Boots
수집서버
서빙 레이어 간소화를 예시
9.
2. Data Pipelinewith Spark + Cassandra
- 매일 새벽 시간대에 수백 GB의 데이터셋들을 DB에 Insert
- 특정 실시간 로그들 단건 Insert
- 병렬 수행을 위한 Spark와의 궁합
- 단순 Select가 주요 쿼리
- 특정 회원/상품 Skew
- DB Downtime이 발생하더라도 지속가능한 운영
- 추후 쉽게 확장 가능해야 함.
- 모니터링 프로세스 필요
10.
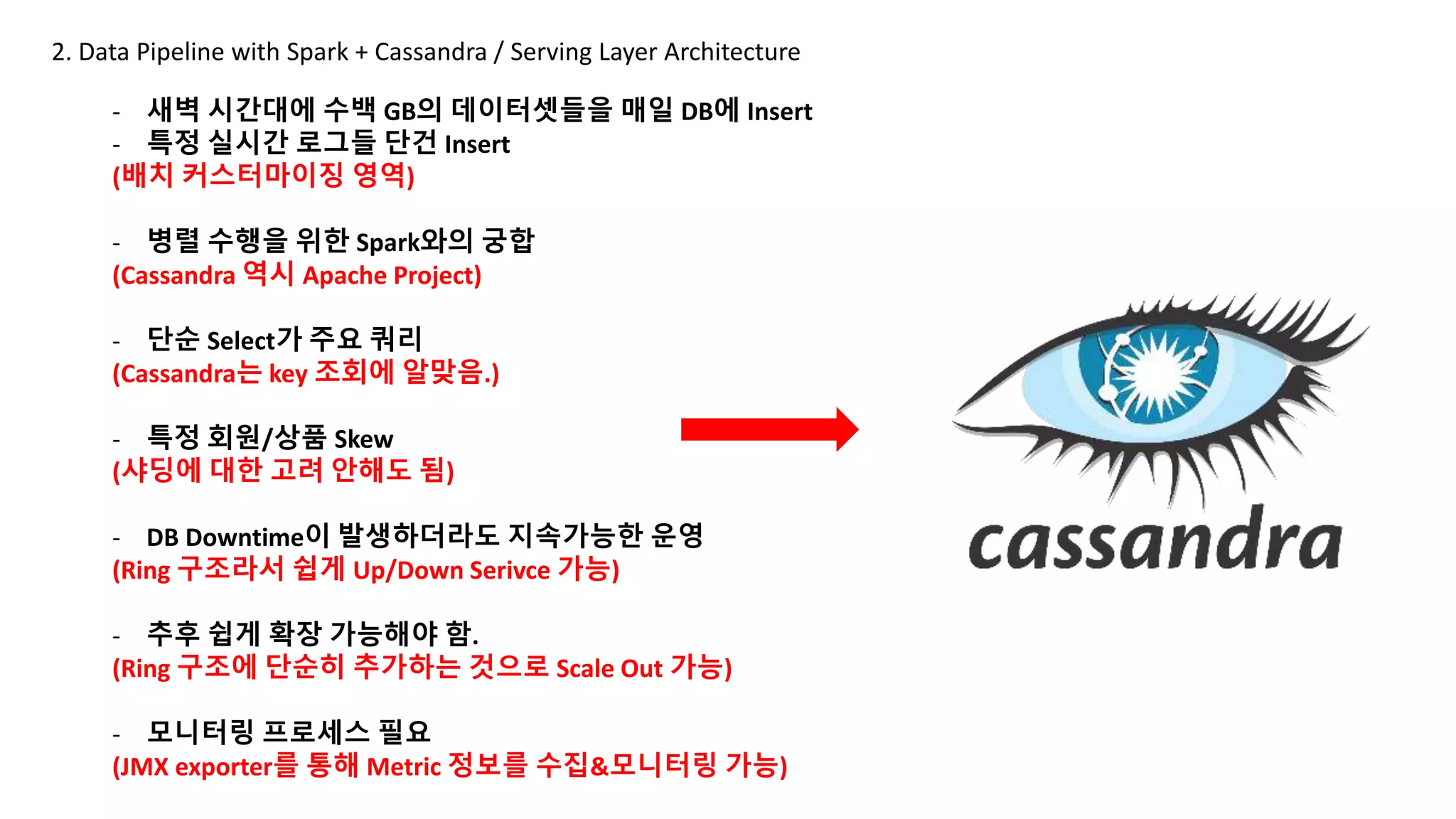
2. Data Pipelinewith Spark + Cassandra / Serving Layer Architecture
- 새벽 시간대에 수백 GB의 데이터셋들을 매일 DB에 Insert
- 특정 실시간 로그들 단건 Insert
(배치 커스터마이징 영역)
- 병렬 수행을 위한 Spark와의 궁합
(Cassandra 역시 Apache Project)
- 단순 Select가 주요 쿼리
(Cassandra는 key 조회에 알맞음.)
- 특정 회원/상품 Skew
(샤딩에 대한 고려 안해도 됨)
- DB Downtime이 발생하더라도 지속가능한 운영
(Ring 구조라서 쉽게 Up/Down Serivce 가능)
- 추후 쉽게 확장 가능해야 함.
(Ring 구조에 단순히 추가하는 것으로 Scale Out 가능)
- 모니터링 프로세스 필요
(JMX exporter를 통해 Metric 정보를 수집&모니터링 가능)
11.
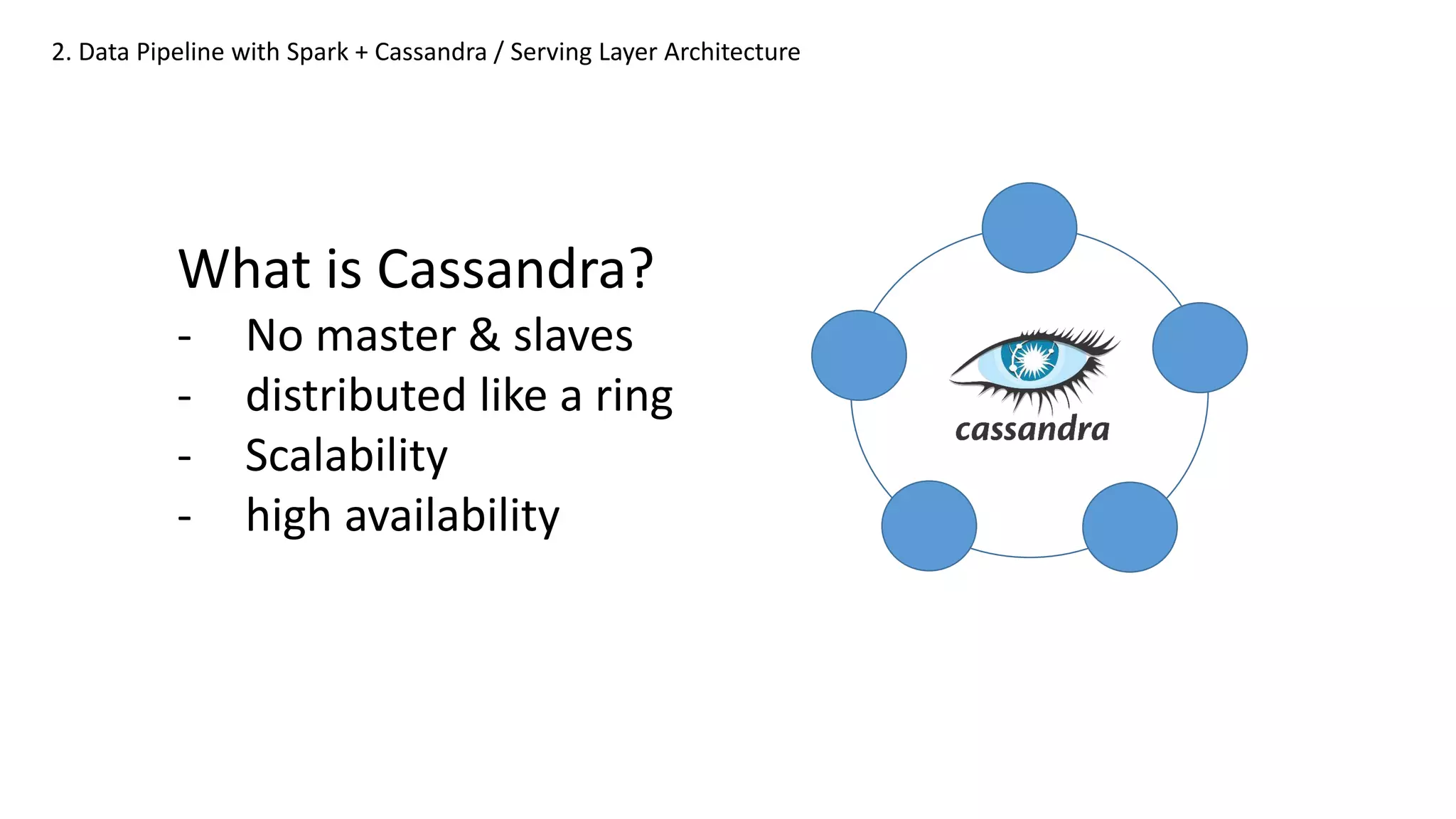
What is Cassandra?
-No master & slaves
- distributed like a ring
- Scalability
- high availability
2. Data Pipeline with Spark + Cassandra / Serving Layer Architecture
12.
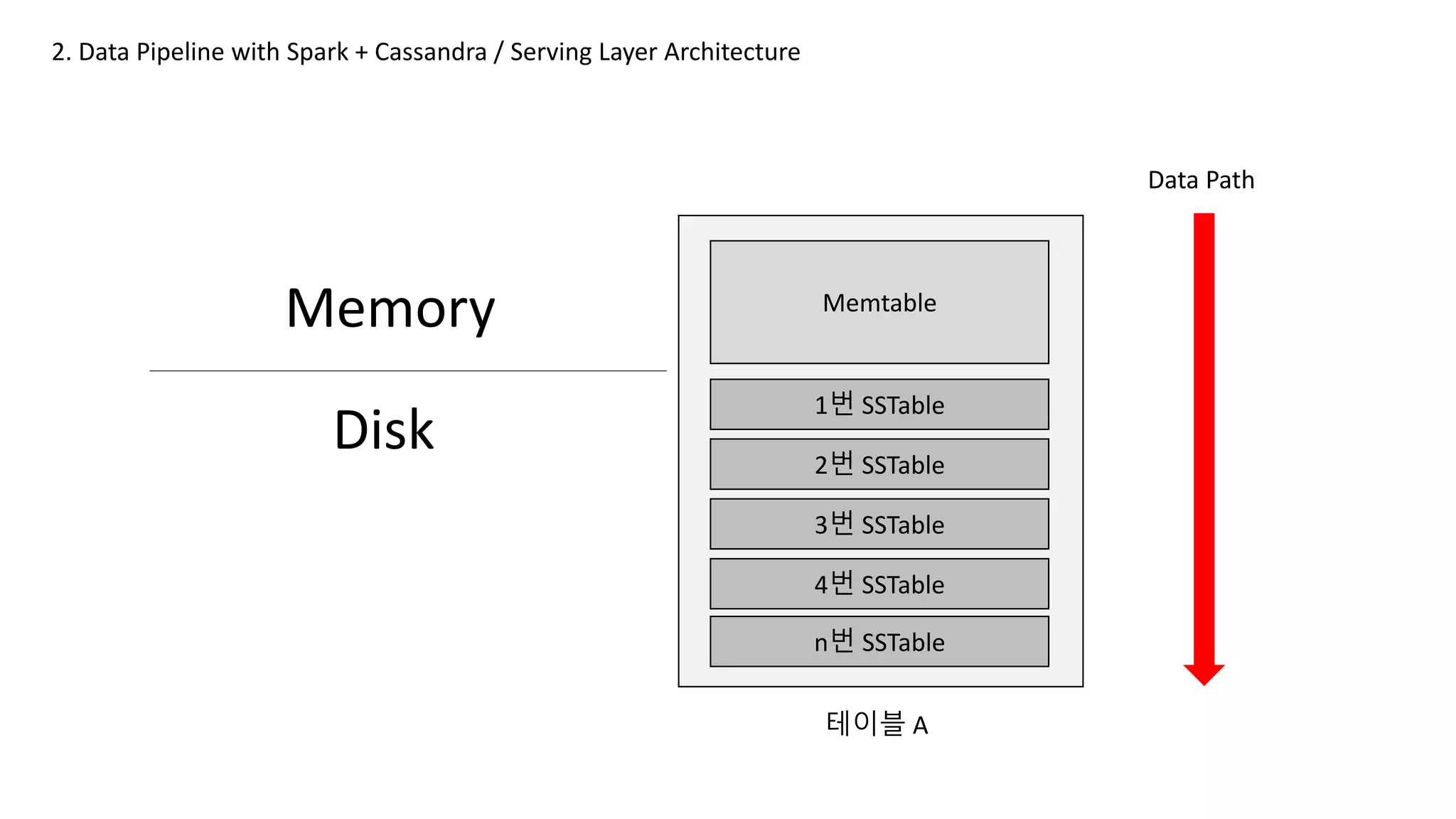
Memory
2. Data Pipelinewith Spark + Cassandra / Serving Layer Architecture
Memtable
1번 SSTable
2번 SSTable
3번 SSTable
4번 SSTable
n번 SSTable
테이블 A
Disk
Data Path
3. Trouble Shooting& Optimization
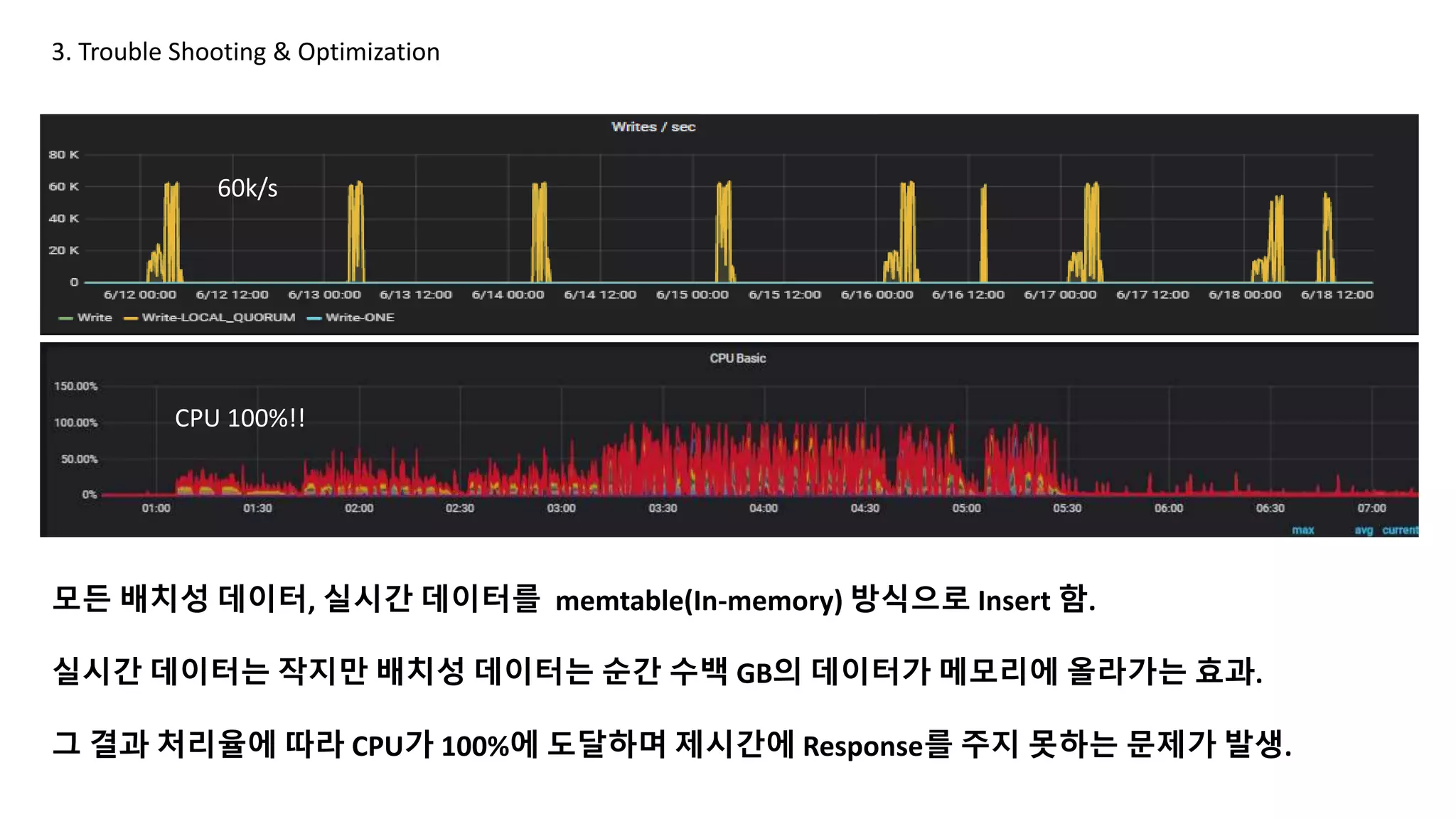
모든 배치성 데이터, 실시간 데이터를 memtable(In-memory) 방식으로 Insert 함.
실시간 데이터는 작지만 배치성 데이터는 순간 수백 GB의 데이터가 메모리에 올라가는 효과.
그 결과 처리율에 따라 CPU가 100%에 도달하며 제시간에 Response를 주지 못하는 문제가 발생.
CPU 100%!!
60k/s
15.
3. Trouble Shooting& Optimization
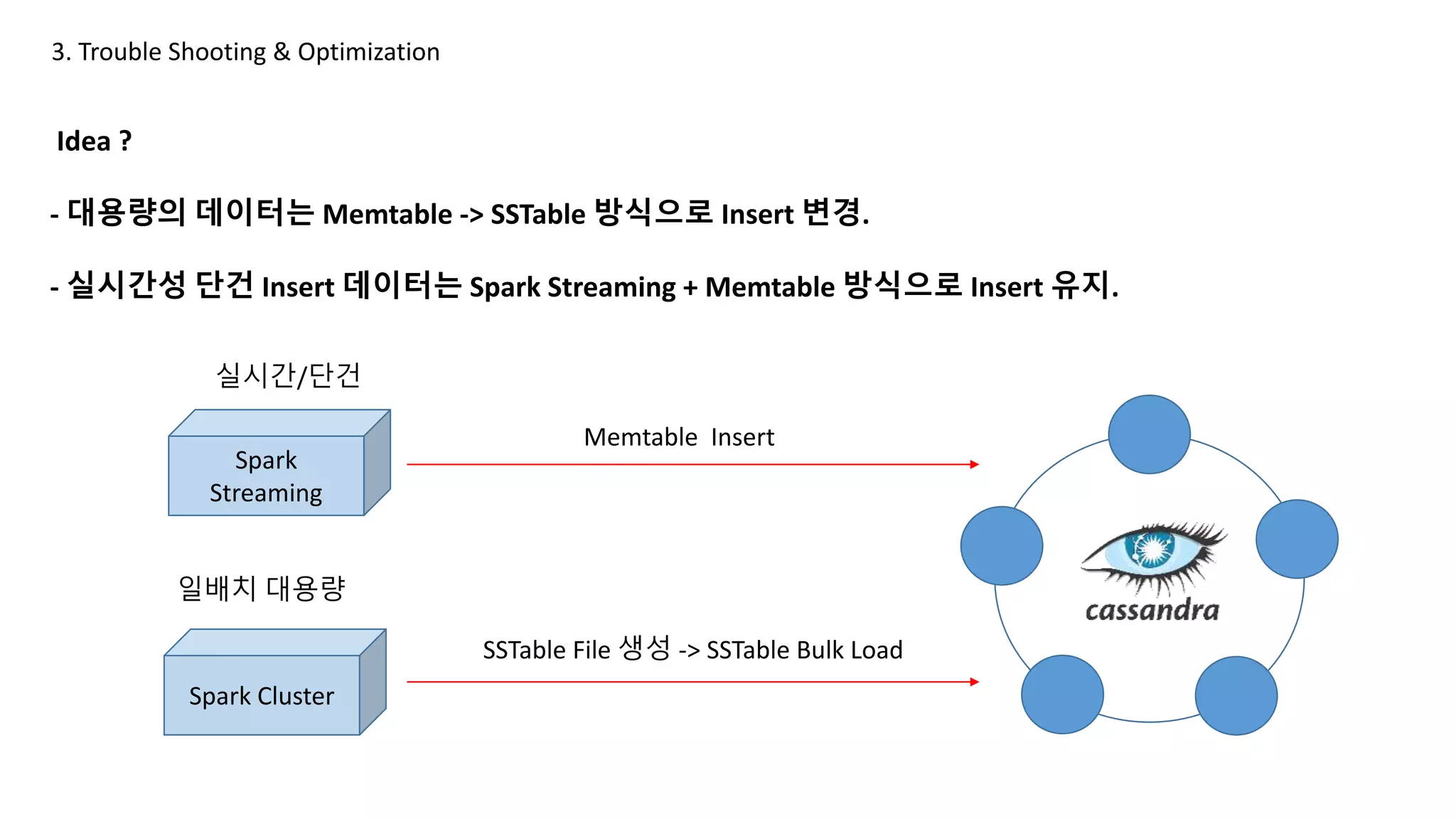
해당 데이터가 너무 클 경우 Memtable(In-memory) -> SSTable(Disk)로 내리는 과정인 Flush가 존재함.
Service Downtime을 고려하여 Replica를 3으로 잡음.
따라서 Flush 및 Copy로 인한 Batch 시간은 길어지고 이 모든 시간대는 장애상황으로 간주.
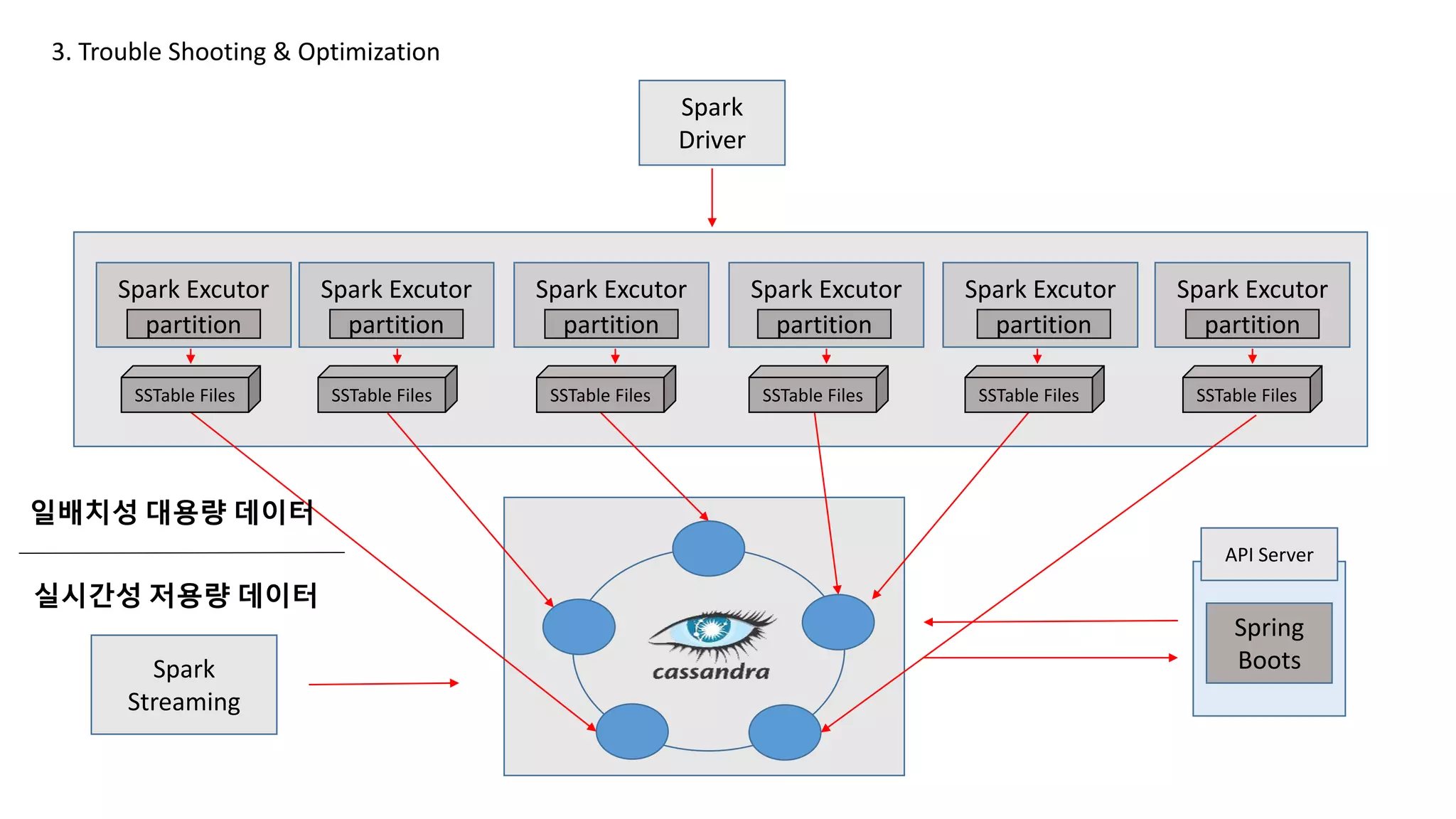
Connection Timeouts / Pending threads
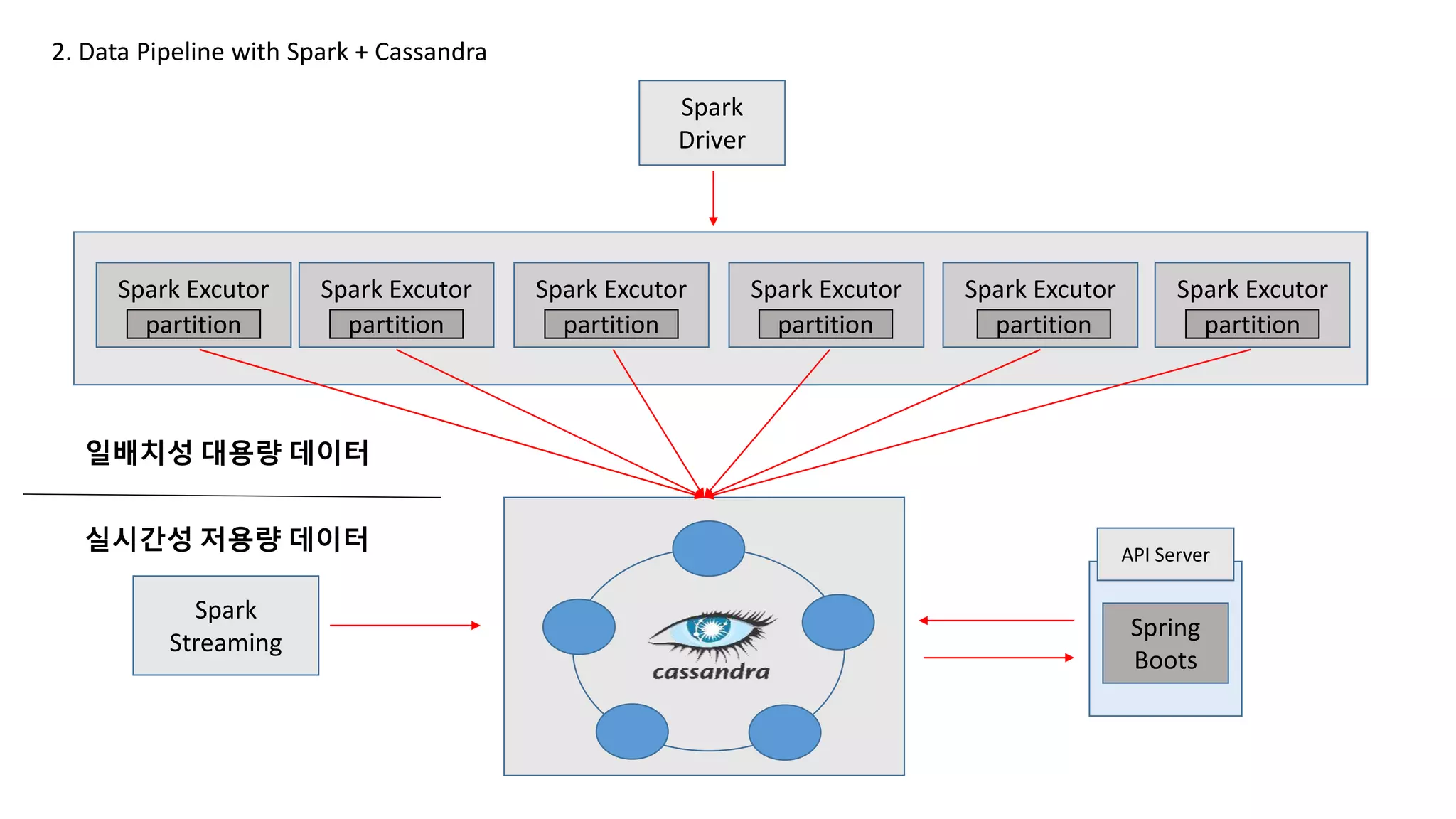
Spark
Driver
Spark Excutor
partition
Spark Excutor
partition
SparkExcutor
partition
Spark Excutor
partition
Spark Excutor
partition
Spark Excutor
partition
API Server
Spring
Boots
SSTable Files SSTable Files SSTable Files SSTable Files SSTable FilesSSTable Files
3. Trouble Shooting & Optimization
Spark
Streaming
일배치성 대용량 데이터
실시간성 저용량 데이터
18.
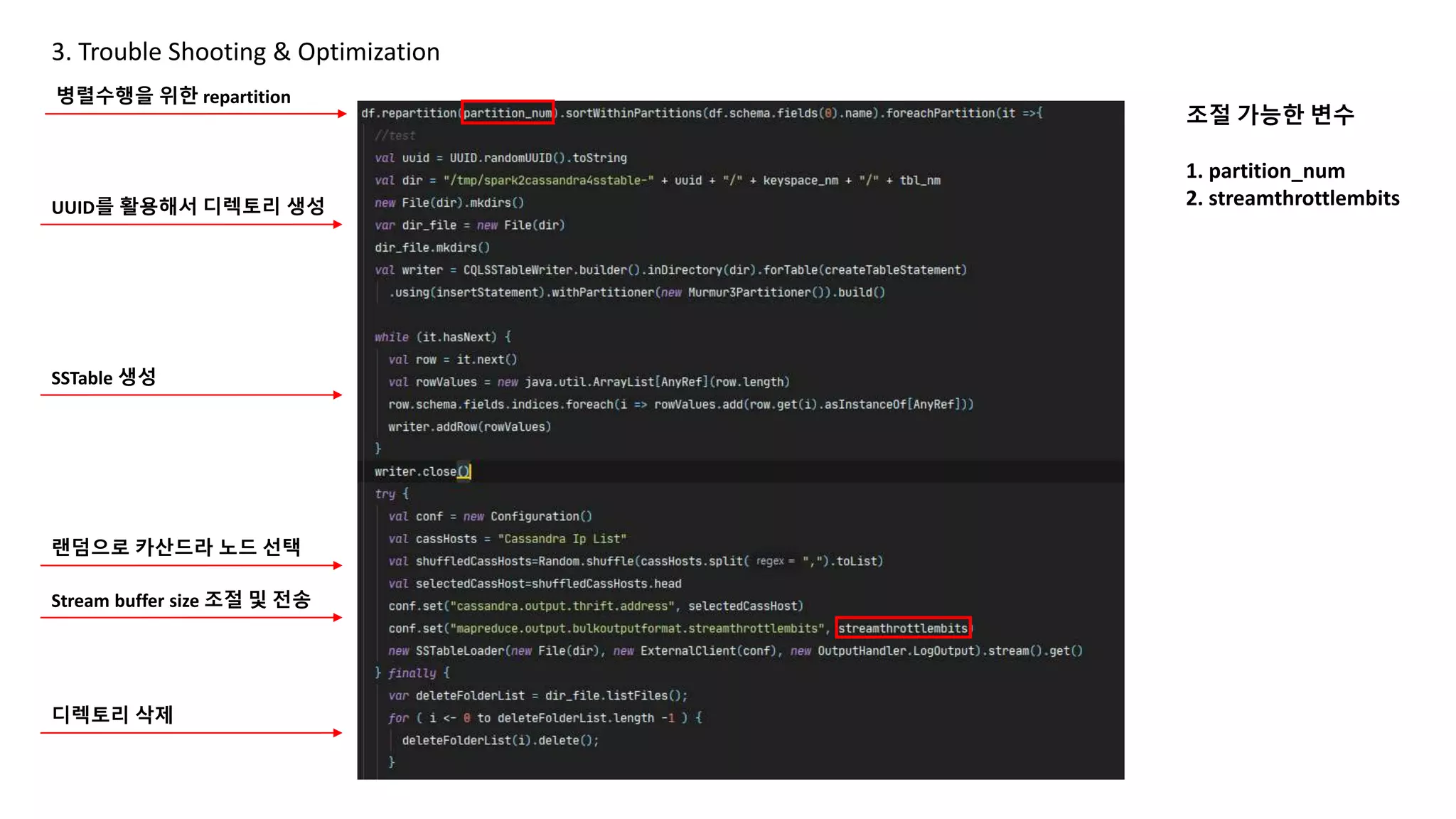
* 작업 순서
1.UUID를 활용하여 SSTable Directory 생성
2. Directory에 SSTable 생성
3. SSTable Bulk Load To Cassandra
4. Delete Directory
3. Trouble Shooting & Optimization
* 기대효과
- 각 카산드라 노드는 SSD이기 때문에 효율 증가
- CPU 사용이 미미할 것이기 때문에 운영 상에 영향 미미
- Network/Disk 성능이 충분히 받쳐준다면 더 많은 배치를 동시수행 가능
19.
3. Trouble Shooting& Optimization
병렬수행을 위한 repartition
UUID를 활용해서 디렉토리 생성
SSTable 생성
랜덤으로 카산드라 노드 선택
Stream buffer size 조절 및 전송
디렉토리 삭제
조절 가능한 변수
1. partition_num
2. streamthrottlembits
20.
3. Trouble Shooting& Optimization
Ex) 수신 측이 Network Traffic은 최대 1Gbps를 받을 수 있고 SSD는 2GBs. (Network Traffic만 고려)
Base Line을 Max 35%인 350Mbps만 사용하도록 가정.
만약 HDFS Size 1G당 파티션 1개로 고정한다면 10GB를 전송할 경우 10대가 병렬로 수행.
Streamthrottlembits * partition_num = 350 (mbps)
350Mbps로 제한하는 예제 코드
21.
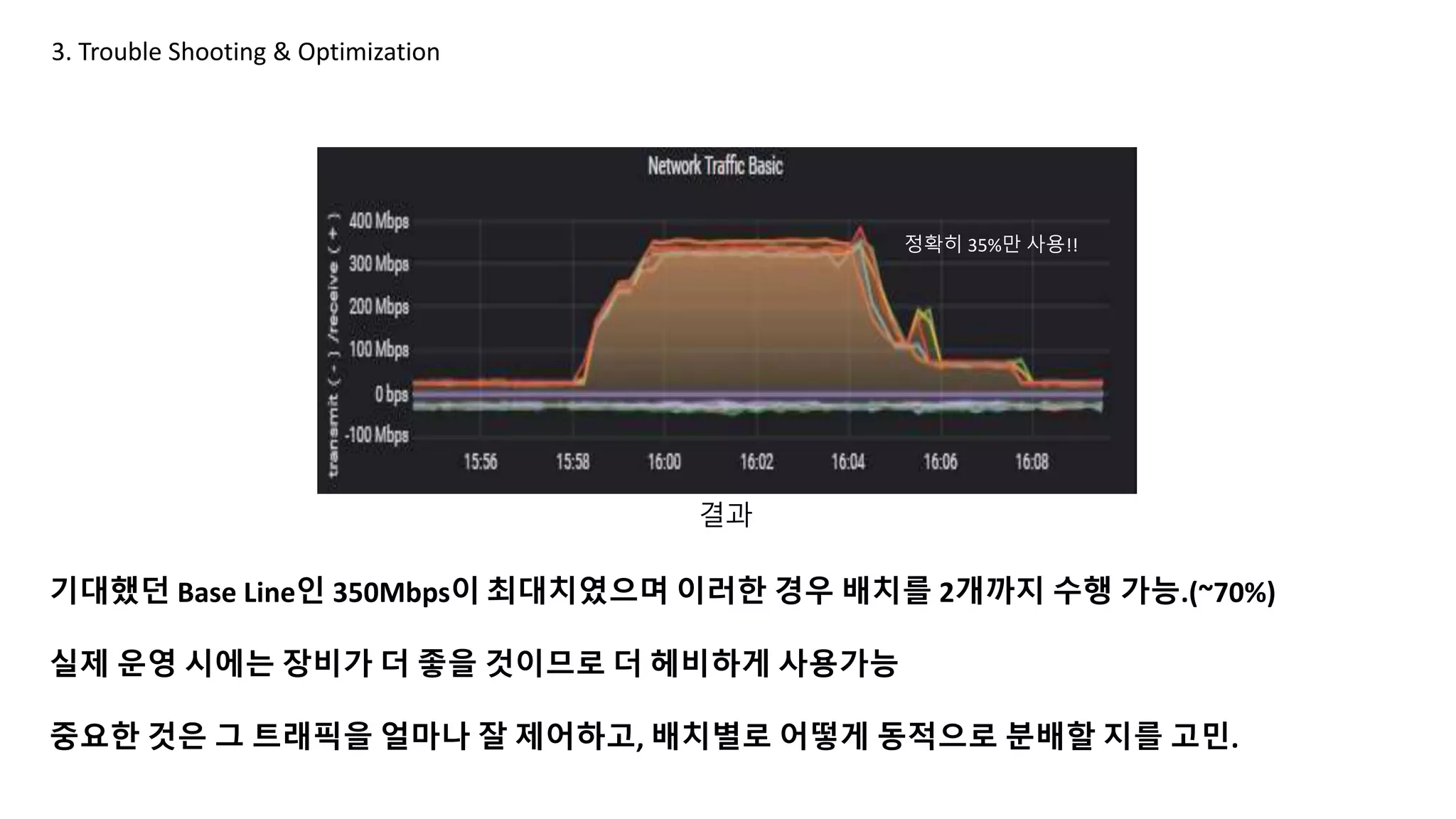
3. Trouble Shooting& Optimization
기대했던 Base Line인 350Mbps이 최대치였으며 이러한 경우 배치를 2개까지 수행 가능.(~70%)
실제 운영 시에는 장비가 더 좋을 것이므로 더 헤비하게 사용가능
중요한 것은 그 트래픽을 얼마나 잘 제어하고, 배치별로 어떻게 동적으로 분배할 지를 고민.
결과
정확히 35%만 사용!!
22.
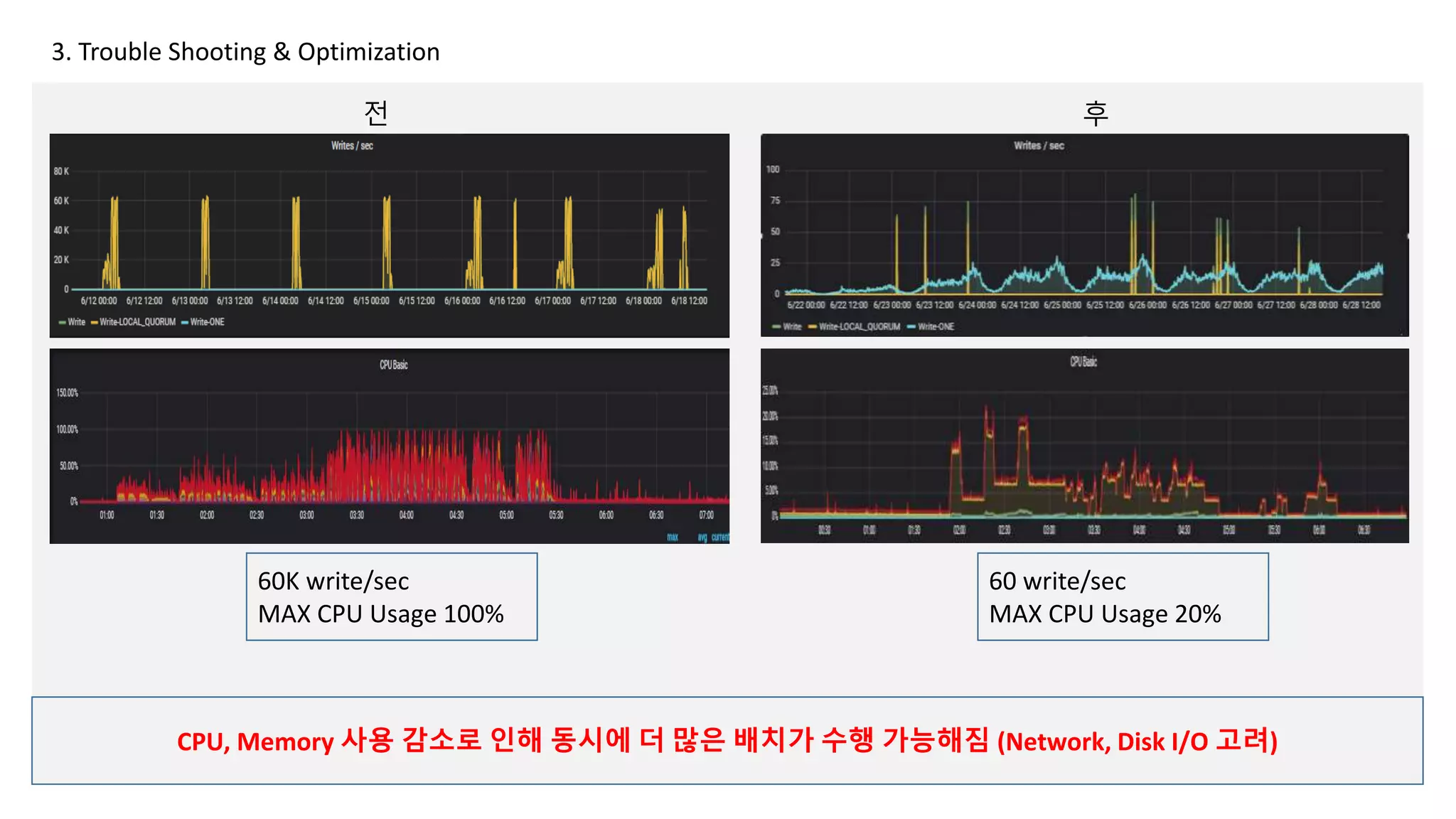
3. Trouble Shooting& Optimization
전 후
CPU, Memory 사용 감소로 인해 동시에 더 많은 배치가 수행 가능해짐 (Network, Disk I/O 고려)
60K write/sec
MAX CPU Usage 100%
60 write/sec
MAX CPU Usage 20%
23.
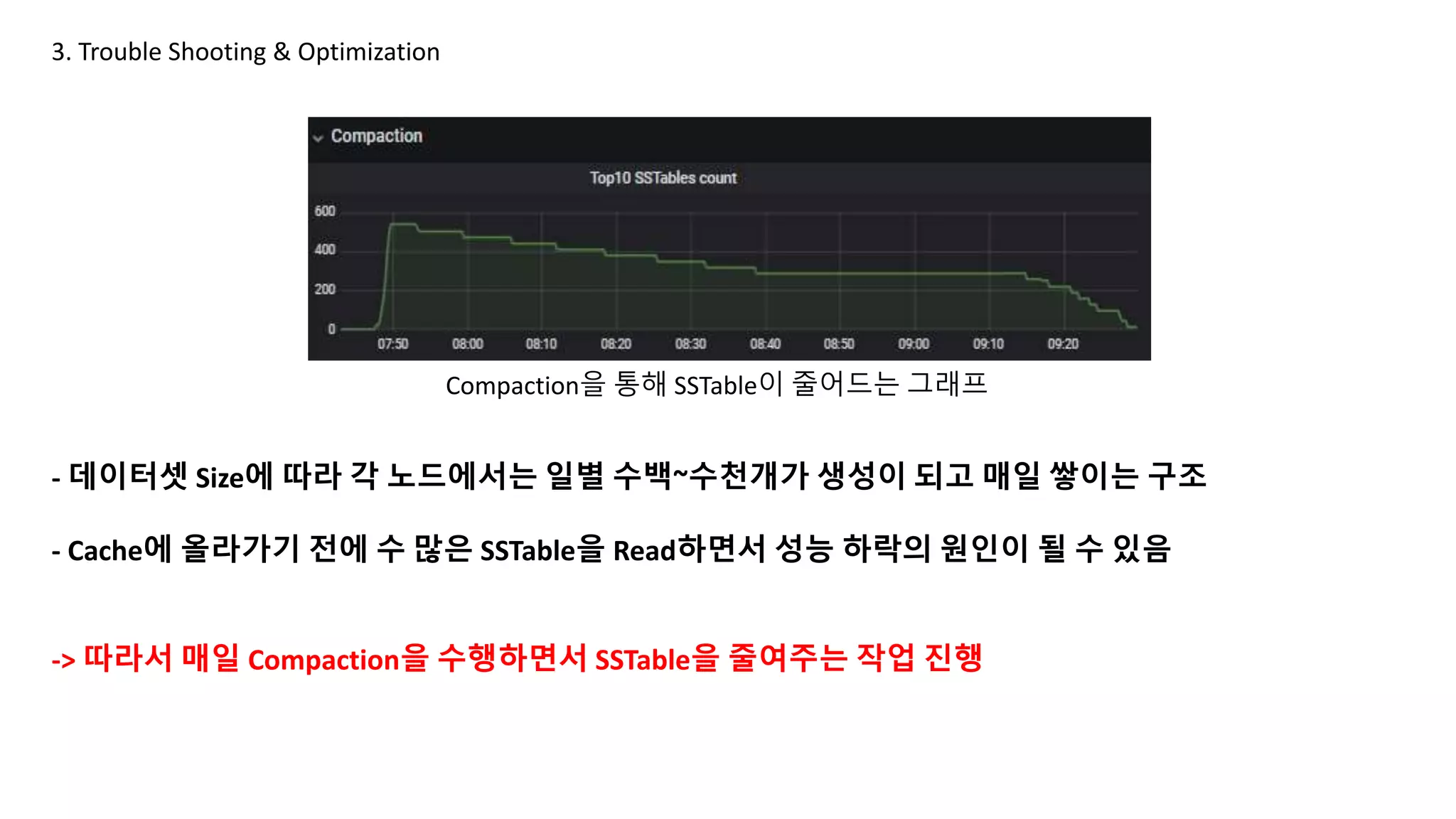
- 데이터셋 Size에따라 각 노드에서는 일별 수백~수천개가 생성이 되고 매일 쌓이는 구조
- Cache에 올라가기 전에 수 많은 SSTable을 Read하면서 성능 하락의 원인이 될 수 있음
-> 따라서 매일 Compaction을 수행하면서 SSTable을 줄여주는 작업 진행
3. Trouble Shooting & Optimization
Compaction을 통해 SSTable이 줄어드는 그래프
24.
* Azul Systems의Zing 도입 배경
- 추천셋 배치가 점점 더 많아짐
- 데이터 사이즈가 계속해서 커짐
- 추가 프로젝트 진행시 트래픽이 보수적으로 5배는 늘어날 것으로 예상
특히 추후 트래픽이 많아질 경우 안정적인 response를 위해 Zing GC 테스트 해보기로 결정
Cassandra + Zing 조합이 국내 레퍼런스가 없었기 때문에 내부에서 자체 테스트를 진행
3. Trouble Shooting & Optimization
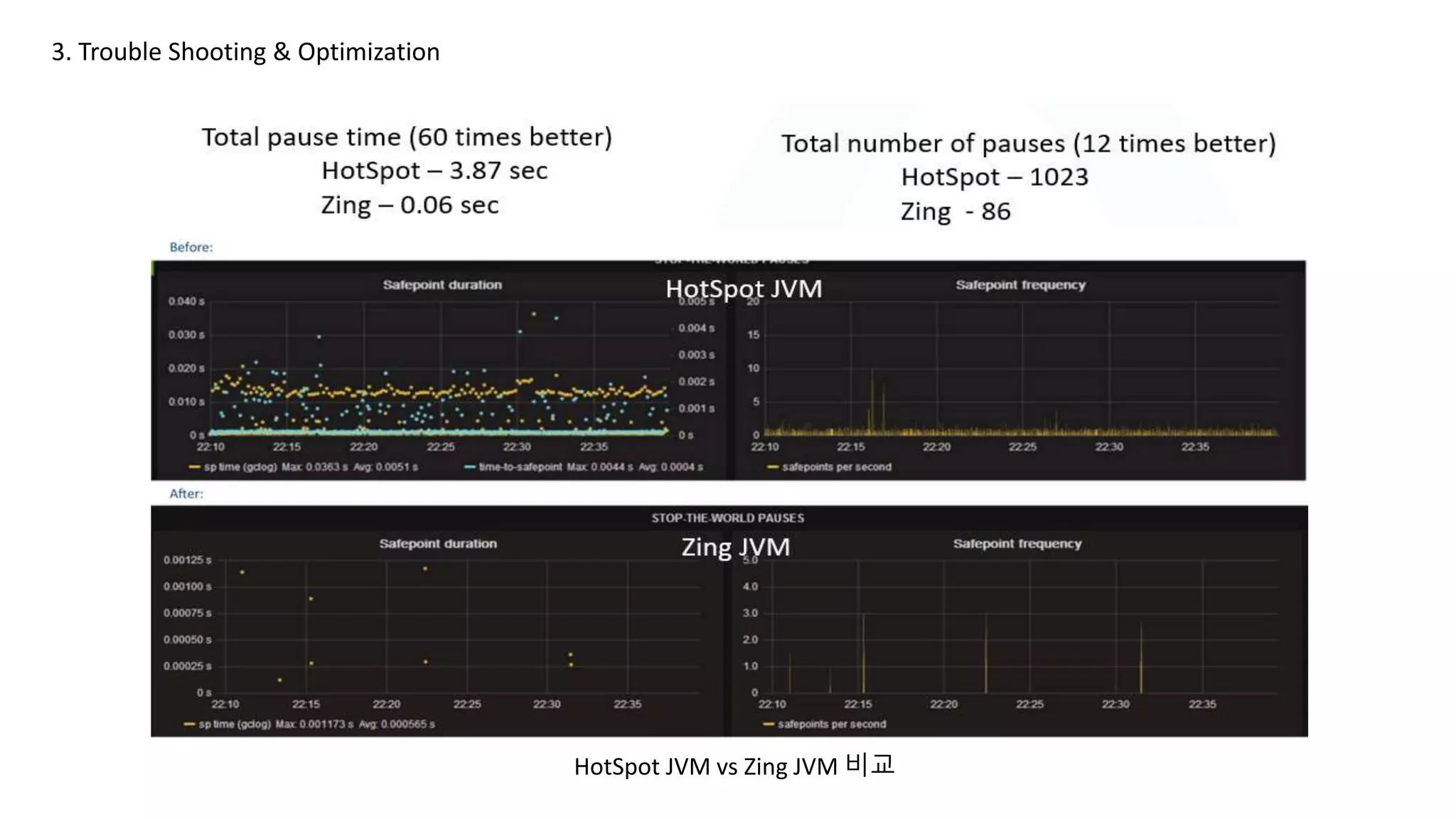
ZING GC
G1GC
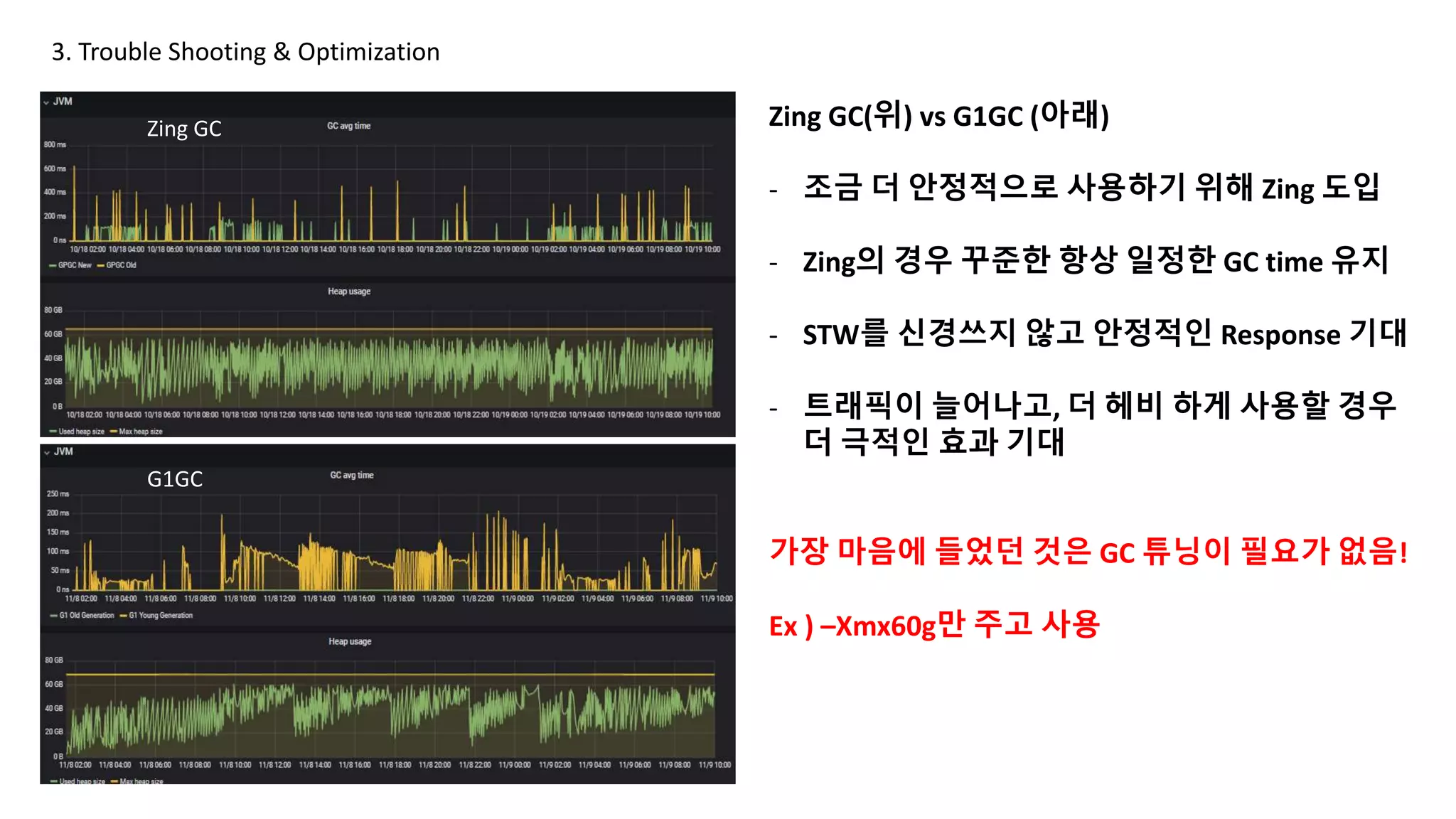
Zing GC(위) vsG1GC (아래)
- 조금 더 안정적으로 사용하기 위해 Zing 도입
- Zing의 경우 꾸준한 항상 일정한 GC time 유지
- STW를 신경쓰지 않고 안정적인 Response 기대
- 트래픽이 늘어나고, 더 헤비 하게 사용할 경우
더 극적인 효과 기대
가장 마음에 들었던 것은 GC 튜닝이 필요가 없음!
Ex ) –Xmx60g만 주고 사용
3. Trouble Shooting & Optimization
Zing GC
G1GC
- CPU 사용량100% -> 20%로 감소함으로써 운영 안정성 확보
- 처리율 증가로 인해 배치 속도 2H -> 15M 으로 감소
- Network & Disk I/O 만 고려하면서 다중 배치 수행 가능
- Zing GC 도입 후 안정적인 Response 및 메모리 관리
- Full Data가 아닌 Key Cache만 메모리에 올려놓음으로써 효율적 운영
- 실시간/대용량 배치를 분리 운영함으로써 안정성 확보
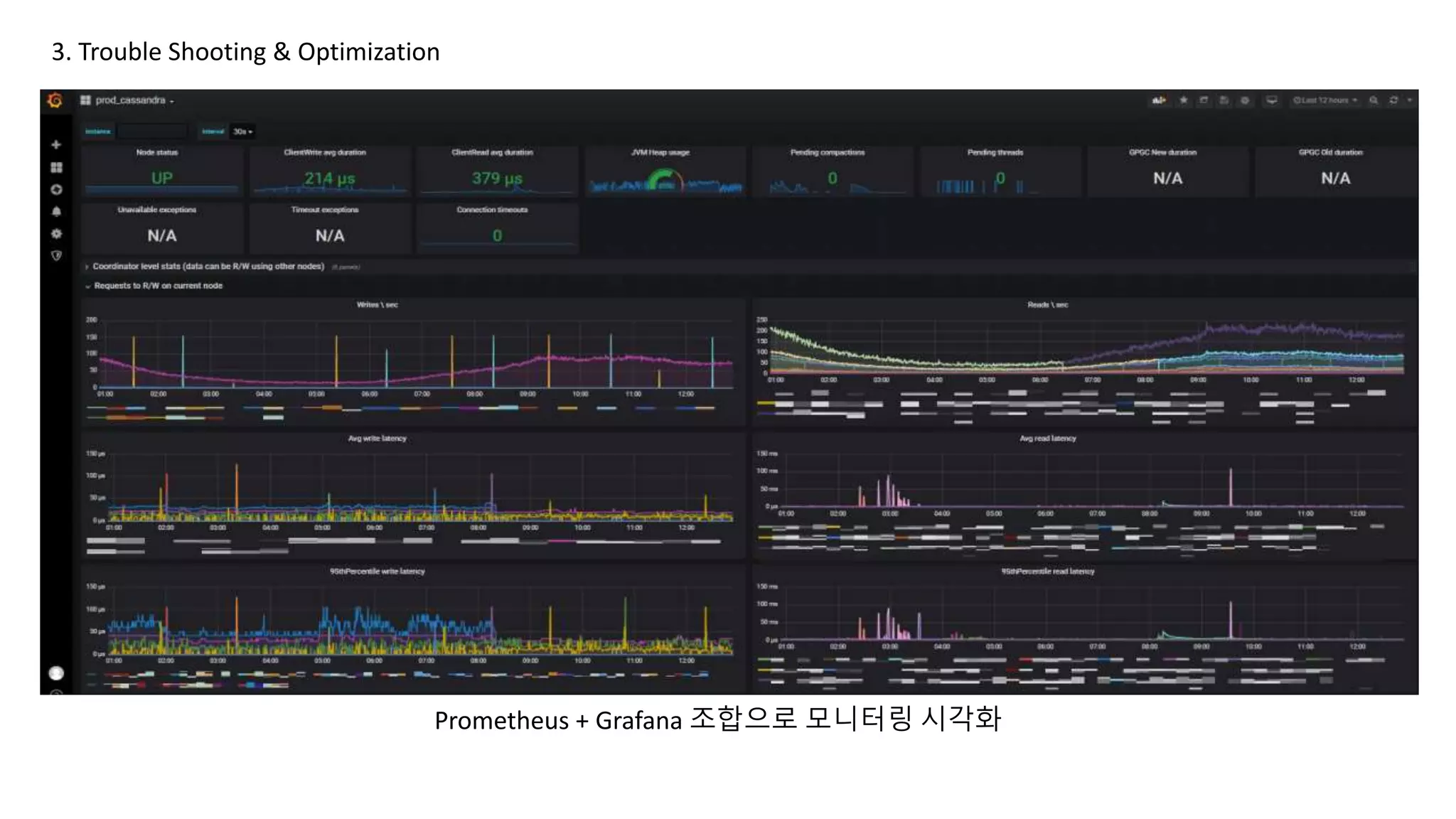
3. Trouble Shooting & Optimization




























![[우리가 데이터를 쓰는 법] 모바일 게임 로그 데이터 분석 이야기 - 엔터메이트 공신배 팀장](https://cdn.slidesharecdn.com/ss_thumbnails/5-160415084345-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Gaming on AWS] AWS와 함께 한 쿠키런 서버 Re-architecting 사례 - 데브시스터즈](https://cdn.slidesharecdn.com/ss_thumbnails/6-140305055030-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Azure study group] azure의 부하분산](https://cdn.slidesharecdn.com/ss_thumbnails/azurestudygroupazure-171115181528-thumbnail.jpg?width=640&height=640&fit=bounds)



![[AWSKRUG&JAWS-UG Meetup #1] 태양광발전소 원격 감시 시스템의 대량데이터 해석【株式会社fusic】](https://cdn.slidesharecdn.com/ss_thumbnails/160526krugfusic-160526114434-thumbnail.jpg?width=640&height=640&fit=bounds)




![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유 (2부)](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-2-180430180517-thumbnail.jpg?width=640&height=640&fit=bounds)




![[경북] I'mcloud information](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudinformation-151105091525-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)





![제 21회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [LKVK] : 디토다이닝_서버리스 데이터 파이프라인을 곁들인 맛집 추천 서비스](https://cdn.slidesharecdn.com/ss_thumbnails/random-250208084808-3f257f02-thumbnail.jpg?width=640&height=640&fit=bounds)






