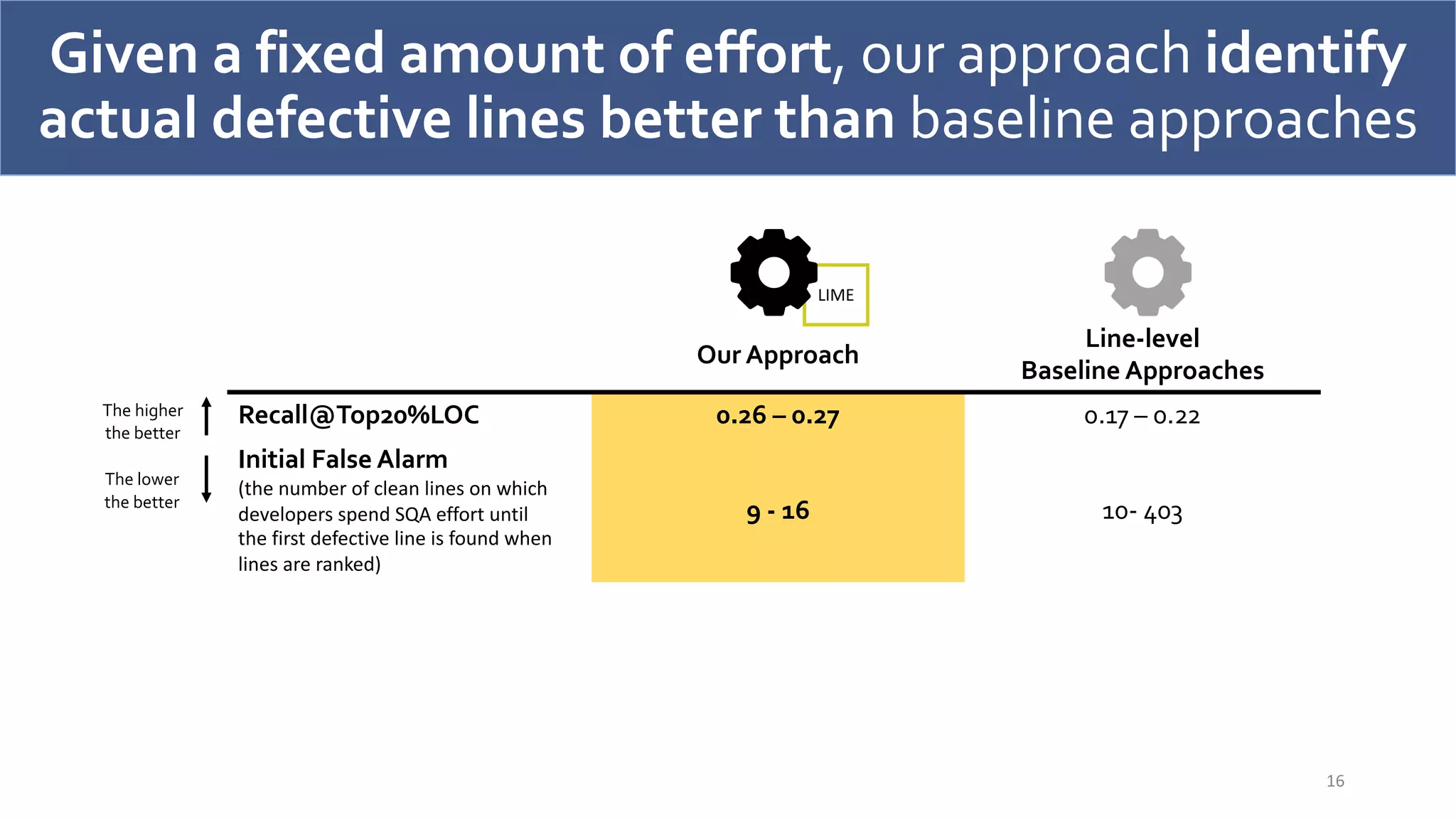
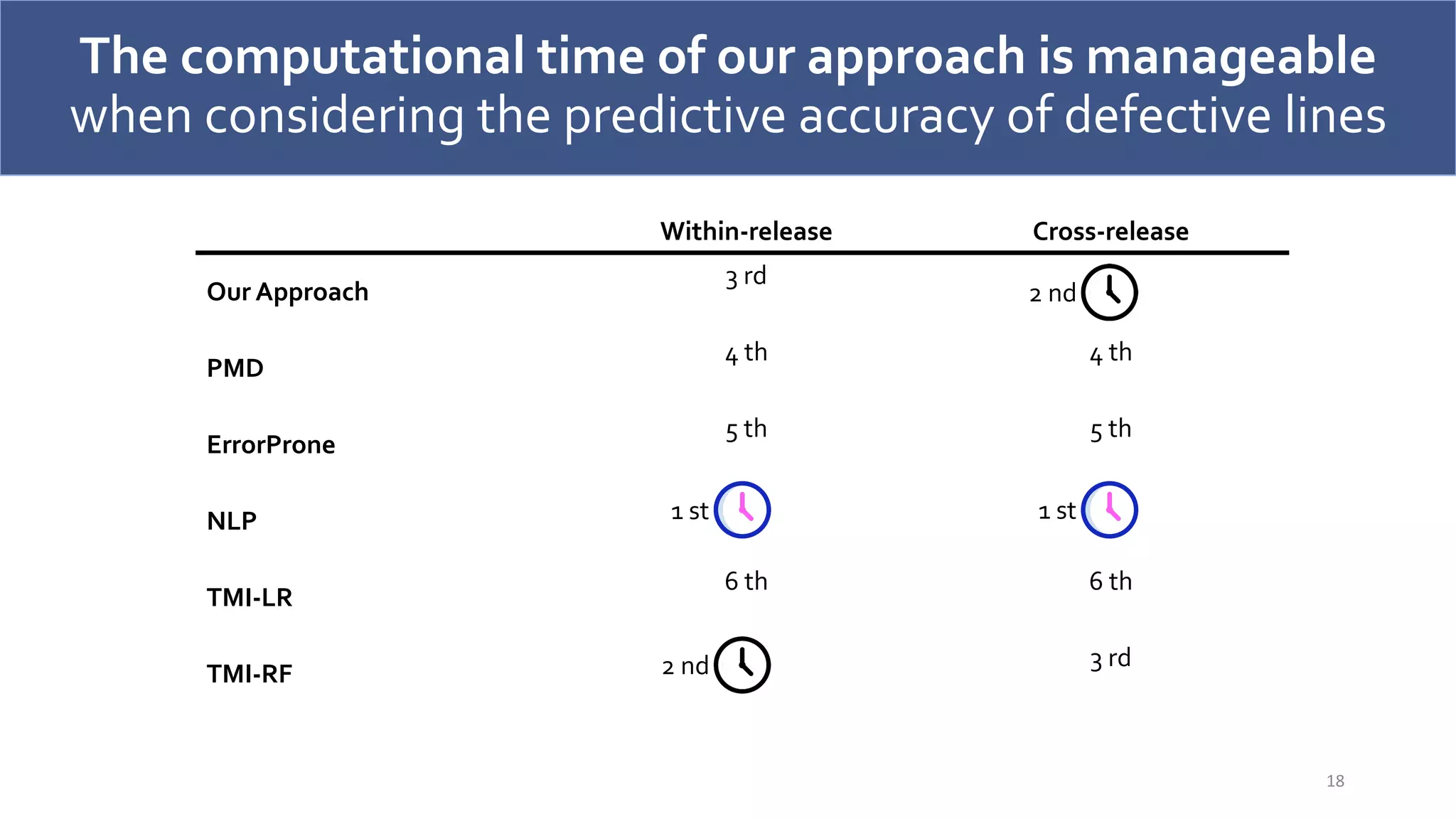
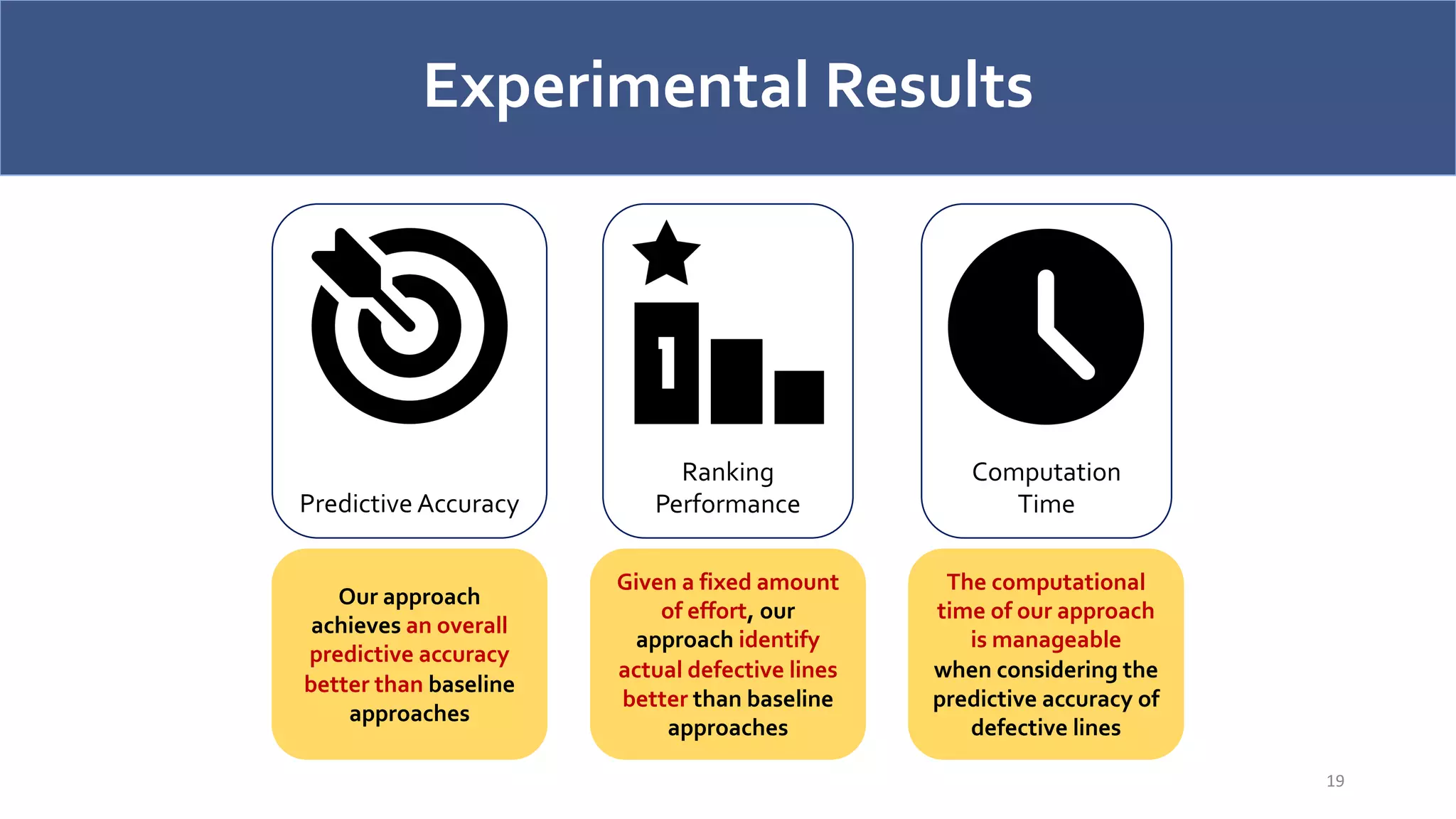
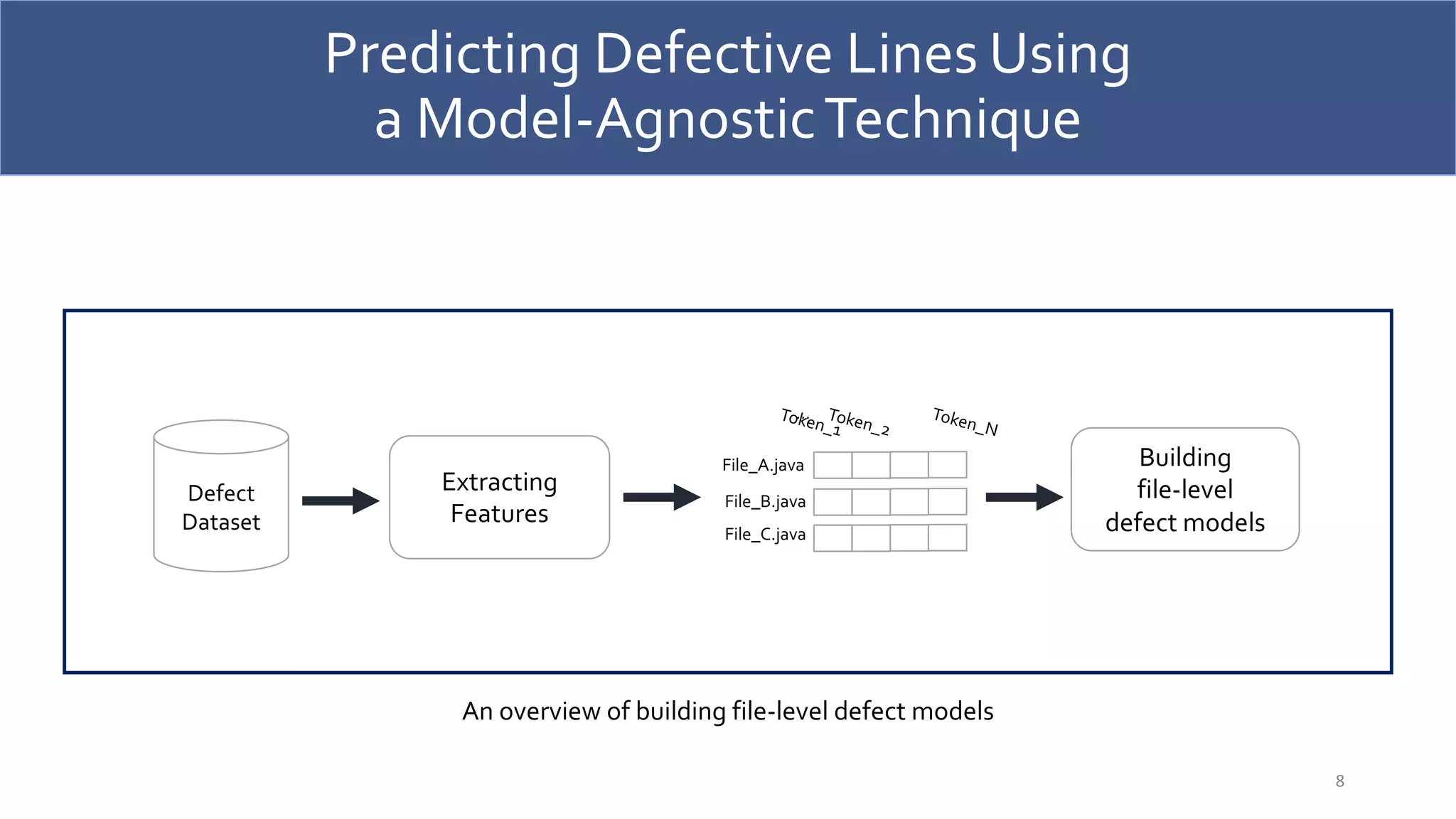
The document discusses a model-agnostic technique for predicting defective lines in software by using a framework that aids software quality assurance (SQA) teams in prioritizing their efforts on defect-prone code. It compares the effectiveness of this approach against traditional defect prediction models, demonstrating improved predictive accuracy and efficiency in identifying actual defective lines. The findings emphasize the importance of focusing SQA efforts on a small subset of code that is likely to contain defects, thereby optimizing resources and reducing wasted effort.


![Defect prediction models are proposed to help
SQA teams prioritize their effort
4
Source Code
Files
Version Control
System
Prioritize files
using defect
models
Ranked Source
Code Files
…
[Kamei et al. ICSME 2010]
[Mende and Koschke CSMR 2010]
…](https://image.slidesharecdn.com/jricse2-210604055826/75/Predicting-Defective-Lines-Using-a-Model-Agnostic-Technique-4-2048.jpg)
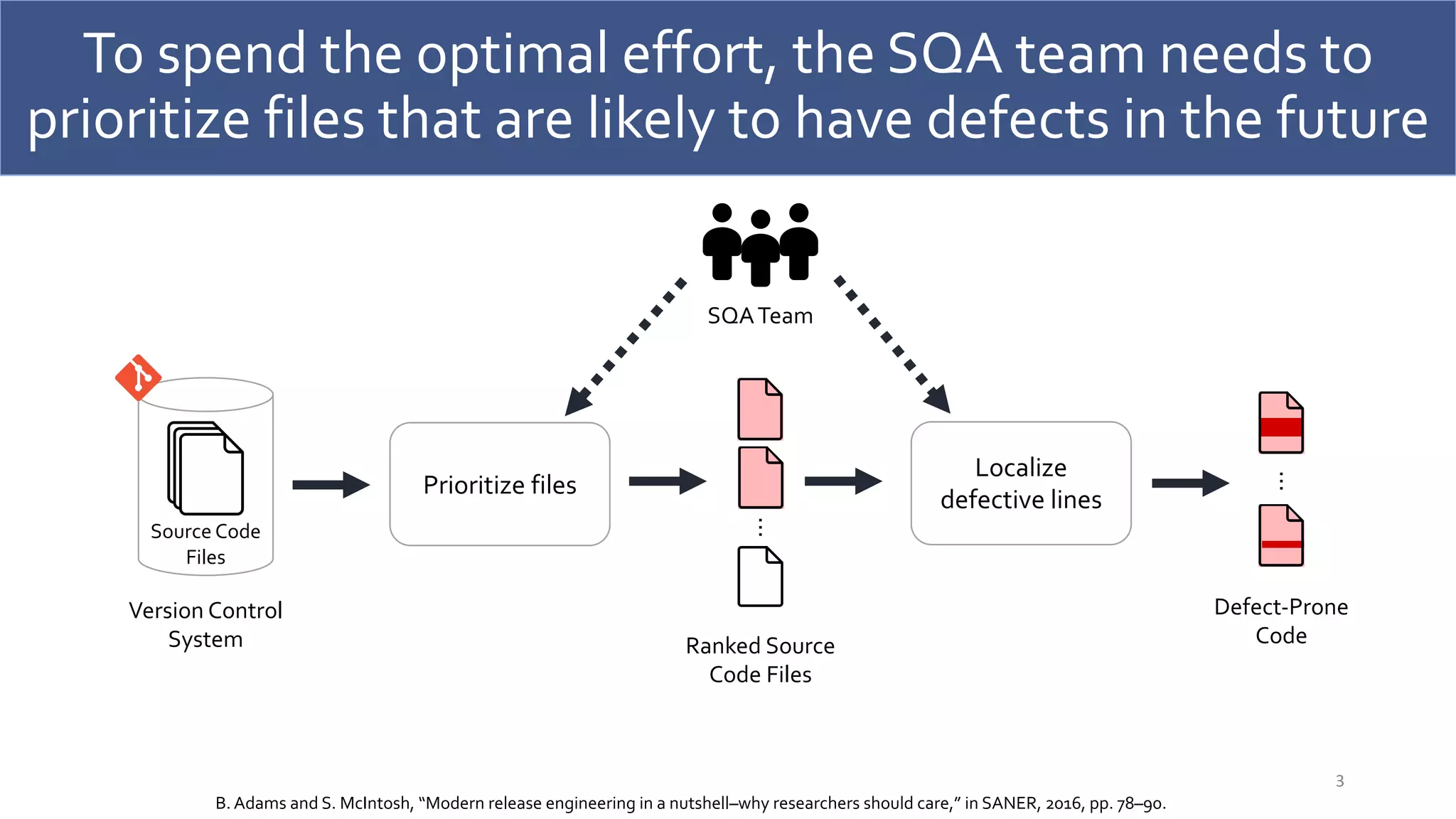
![However, developers could still waste an SQA effort on
manually identifying the most risky lines
5
Source Code
Files
Version Control
System
Prioritize files
using defect
models
Ranked Source
Code Files
Defect-Prone
Code
…
Localize
defective lines
…
SQATeam
[Kamei et al. ICSME 2010]
[Mende and Koschke CSMR 2010]
…](https://image.slidesharecdn.com/jricse2-210604055826/75/Predicting-Defective-Lines-Using-a-Model-Agnostic-Technique-5-2048.jpg)


![Predicting Defective Lines Using
a Model-AgnosticTechnique
9
File-Level
Defect Models
LIME
Testing Files
Predicting
defect-prone
lines
Defect-Prone
Files
Identifying
defect-prone
lines
Identified Defect-
Prone Lines
Ranking
defect-prone
lines
…
Most-risky
Least-risky
[Ribeiro et al. SIGKDD 2016]
**LIME is a model-agnostic technique that aims to mimic the behavior of the predictions of the defect model by explaining the individual predictions](https://image.slidesharecdn.com/jricse2-210604055826/75/Predicting-Defective-Lines-Using-a-Model-Agnostic-Technique-9-2048.jpg)
![An illustrative example of our approach
for identifying defect-prone lines
10
LIME
A Defect-Prone
File
Identified defect-prone lines
File-Level Defect
Prediction Model
A File of Interest
(Testing file)
LIME
oldCurrent
current
node
closure
Defective
(LIME Score >0)
Clean
(LIME score < 0)
0.8
0.1
-0.3
-0.7
Ranking tokens based on
LIME scores
Mapping tokens
to lines
if(closure != null){
Object oldCurrent = current;
setClosure(closure, node);
closure.call();
current = oldCurrent;
}
if(closure != null){
Object oldCurrent = current;
setClosure(closure, node);
closure.call();
current = oldCurrent;
}
Identified defect-prone lines
File-Level Defect
Prediction Model
A File of Interest
(Testing file)
LIME
oldCurrent
current
node
closure
Defective
(LIME Score >0)
Clean
(LIME score < 0)
0.8
0.1
-0.3
-0.7
Ranking tokens based on
LIME scores
Mapping tokens
to lines
if(closure != null){
Object oldCurrent = current;
setClosure(closure, node);
closure.call();
current = oldCurrent;
}
if(closure != null){
Object oldCurrent = current;
setClosure(closure, node);
closure.call();
current = oldCurrent;
}
Mapping tokens
to lines
Identified defect-prone lines
File-Level Defect
Prediction Model
A File of Interest
(Testing file)
LIME
oldCurrent
current
node
closure
Defective
(LIME Score >0)
Clean
(LIME score < 0)
0.8
0.1
-0.3
-0.7
Ranking tokens based on
LIME scores
Mapping tokens
to lines
if(closure != null){
Object oldCurrent = current;
setClosure(closure, node);
closure.call();
current = oldCurrent;
}
if(closure != null){
Object oldCurrent = current;
setClosure(closure, node);
closure.call();
current = oldCurrent;
}
Ranking tokens
based on LIME
scores
Identified Defect-
Prone Lines
[Ribeiro et al. SIGKDD 2016]](https://image.slidesharecdn.com/jricse2-210604055826/75/Predicting-Defective-Lines-Using-a-Model-Agnostic-Technique-10-2048.jpg)


![LIME
We compare our approach
against six line-level baseline approaches
13
Our Appraoch
Random Guessing PMD ErrorProne
NLP
Random
Forest
Logistic
Regression
ErrorProne
!= null)
If ( closure
TMI-RF TMI-LR
[Copeland PMDApplied 2005] [Aftandilian et al SCAM 2012]
[Hellendoorn et al
ESEC/FSE 2017]
**TMI-LR is a traditional model interpretation based approach with logistic regression
**TMI-RF is a traditional model interpretation based approach with random forest](https://image.slidesharecdn.com/jricse2-210604055826/75/Predicting-Defective-Lines-Using-a-Model-Agnostic-Technique-13-2048.jpg)