Downloaded 113 times

![Lift Charts and Decile Tables
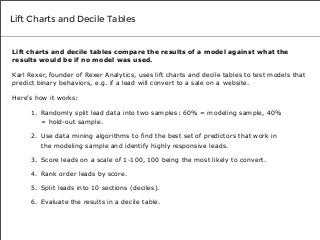
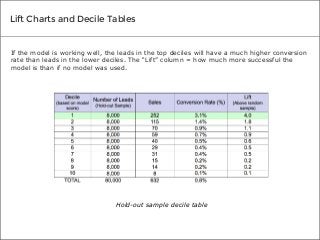
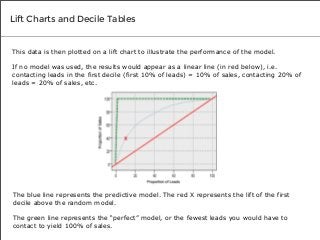
“[With data mining algorithms, lift charts and decile tables],
you’re doing something called supervised learning. You’re using
historical data where you know the outcome of the scenario to
supervise the creation of your model and evaluate how well it will
work to predict a certain behavior. It’s a different methodology.”
- Karl Rexer, founder of Rexer Analytics](https://image.slidesharecdn.com/3testsexpertsusetovalidatepredictivemodelaccuracy-140212144905-phpapp02/85/3-Tests-Experts-Use-to-Validate-Predictive-Model-Accuracy-5-320.jpg?cb=1392216967)

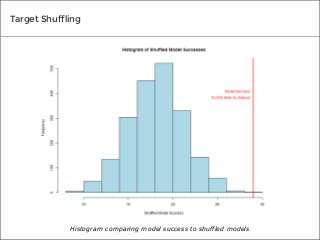



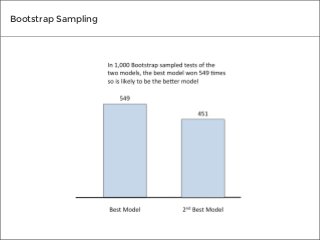
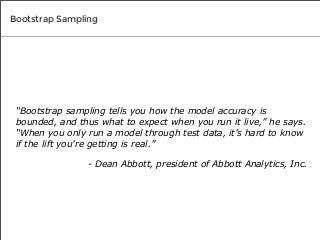

There are many different tests you can use to determine if the predictive models you create will prove valuable to your organization. We spoke to three top data mining experts to learn the tests they use to measure the accuracy of their own results, and what makes each test so effective.






![Big Data [sorry] & Data Science: What Does a Data Scientist Do?](https://cdn.slidesharecdn.com/ss_thumbnails/dslatcloudmsevent20130125-130126065651-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





















































