Download to read offline






![14
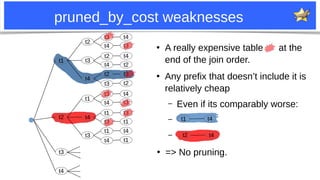
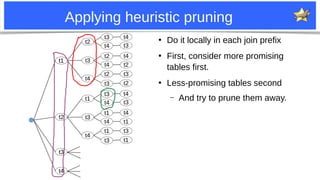
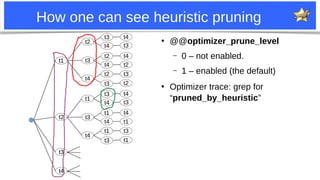
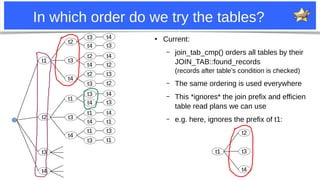
MDEV-28073: patch #1: “edge tables”
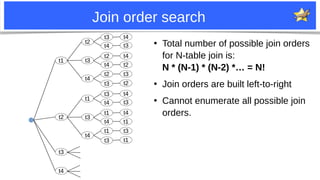
●
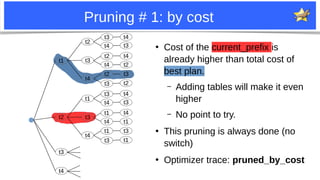
If the suffix t1-t4-t3 uses only eq_ref or similar:
– It is [nearly] the best
– Don’t enumerate other table combinations.
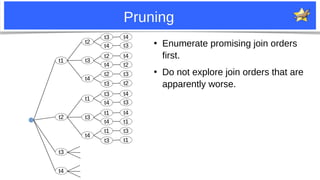
●
They can’t be much better.
●
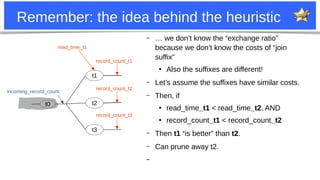
Optimizer trace: pruned_by_hanging_leaf
t1
t1
t2
t2
t3
t4
t3
t4
t2
t4
t2
t3
t4
t3
t4
t2
t3
t2
t1
t3
t4
t3
t4
t1
t4
t1
t3
t4
t3
t4
t1
t3
t1
commit b729896d00e022f6205399376c0cc107e1ee0704
Author: Monty <monty@mariadb.org>
Date: Tue May 10 11:47:20 2022 +0300
MDEV-28073 Query performance degradation in newer MariaDB versions when
using many tables
The issue was that best_extension_by_limited_search() had to go through
too many plans with the same cost as there where many EQ_REF tables.
Fixed by shortcutting EQ_REF (AND REF) when the result only contains one
row. This got the optimization time down from hours to sub seconds.
t0](https://image.slidesharecdn.com/join-optimizer-how-it-works-and-current-fixes-220720101135-7b46daa2/85/MariaDB-s-join-optimizer-how-it-works-and-current-fixes-14-320.jpg)







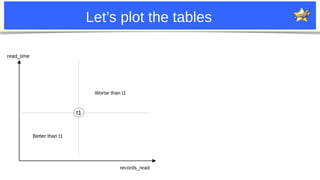


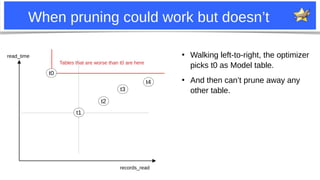
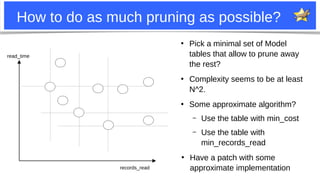


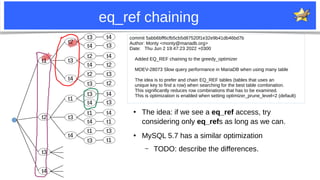

The document discusses improvements to MariaDB's join optimizer. It describes how the optimizer currently works, including join order search, pruning techniques, and greedy search. It then outlines several patches and improvements made to better prune join order search spaces and find optimal plans more quickly. This includes handling "edge tables", improving heuristics for key dependencies and model tables, pre-sorting tables during search, and exploring eq_ref chaining to further reduce search space for attribute tables.












































![[Www.pkbulk.blogspot.com]dbms13](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comdbms13-130615034551-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)










































