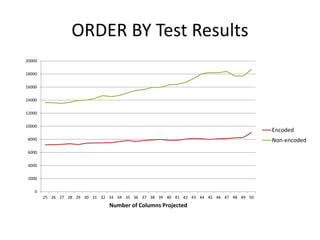
Column qualifier encoding in Apache Phoenix provides benefits over using column names as column qualifiers. It assigns numbers as column qualifiers instead of names, allowing for more efficient column renaming and optimizations. Test results showed the encoded approach used less disk space, improved ORDER BY and GROUPED AGGREGATION performance by up to 2x, and had near constant growth in ORDER BY performance as columns increased versus non-encoded approaches. Further work is ongoing to fully implement and test column encoding.














![ORDER BY with Column Encoding
• Use numbers as column qualifiers
• Custom list implementation for HBase
scanners to fill the key values in
• Key values added to the list at index
determined by converting qualifier byte[] to
integer/short
• Replaces binary search with O(1) lookup](https://image.slidesharecdn.com/columnencoding-160525233346/85/Column-encoding-14-320.jpg)