Download as PDF, PPTX



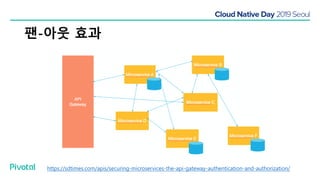
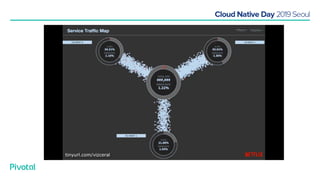

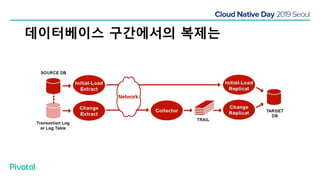
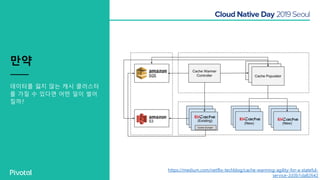



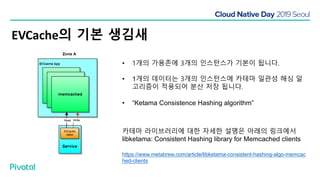
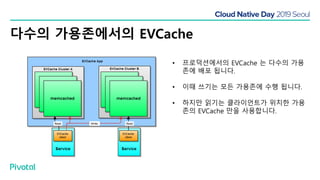
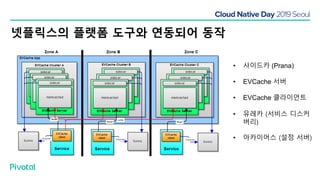
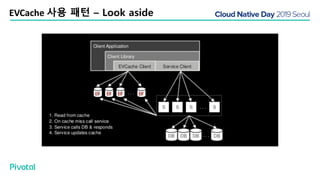
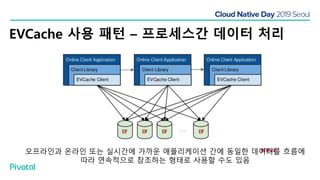
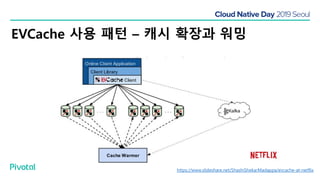
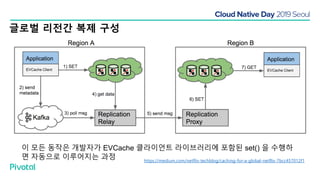



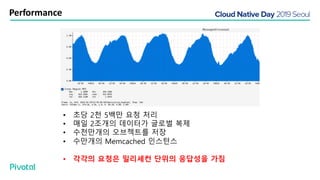

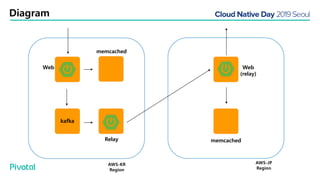



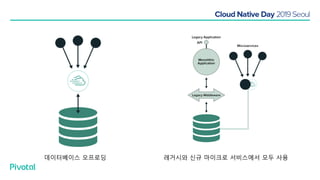
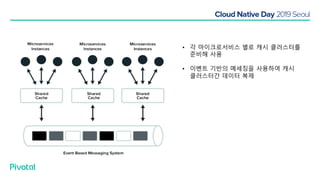
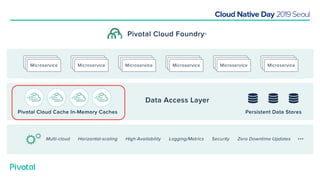




넷플릭스에서는 높은 속도로 데이터를 제공하기 위해서 뿐만 아니라 멀티 리전의 데이터 가용성을 바탕으로한 전체 서비스 가용성 유지를 위해 캐시를 사용하고 있습니다. 이 앞의 세션에서 보았던 마이크로서비스 구조를 염두해 둘때 한가지 가장 간단한 변화는 외부 클라이언트로 부터 유입되는 단 하나의 요청에 대한 응답을 만들기 위해 다수의 내부 서비스들로 부터 데이터를 확보해야 하며, 이는 다수 서비스들에 대한 요청과 응답으로 이루어지게 됩니다. 내부 네트워크 성능, 데이터 저장소의 응답속도등의 복합적인 영향으로 인해 마이크로 서비스는 쉽게 느려질 수 있으며, 이는 보통 '팬아웃 효과'로 알려져 있습니다. 뿐만 아니라 다수 서비스간의 데이터 정합성 유지, 필요에 따라 각 서비스간 데이터의 다운타임 없는 이동, 증가하는 데이터량에 동시에 증가하는 데이터 소스의 부하, 그리고 이런 것들을 모두 감안한 데이터 복제 등을 처리해야 할 필요가 있습니다. 본 세션에서는 넷플릭스에서는 이런 문제를 어떤 방식으로 해결하는지, 그리고 스프링 부트, 스프링 클라우드를 비롯한 피보탈의 기술을 사용해서 어떻게 빠르고 쉽게 사용할 수 있는지에 대해 알아봅니다.


![[오픈소스컨설팅]Data Center to cloud - 최지웅 컨설팅코치, 오픈소스컨설팅](https://cdn.slidesharecdn.com/ss_thumbnails/awssummit2017datacentertocloud-170529054823-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] (Track 1) From OpenStack to cloud native](https://cdn.slidesharecdn.com/ss_thumbnails/162018openstacktocloudnative-180704054221-thumbnail.jpg?width=640&height=640&fit=bounds)





![[OpenInfra Days Korea 2018] (Track 4) - FreeIPA와 함께 SSO 구성](https://cdn.slidesharecdn.com/ss_thumbnails/45feeipasso-180704060033-thumbnail.jpg?width=640&height=640&fit=bounds)



![[OpenInfra Days Korea 2018] K8s workshop: Kubernetes for Beginner](https://cdn.slidesharecdn.com/ss_thumbnails/kubernetesforbegginer20180628v1-180702075619-thumbnail.jpg?width=640&height=640&fit=bounds)

![[OpenInfra Days Korea 2018] (Track 1) IaaS에서 PaaS로의 고도화 여정](https://cdn.slidesharecdn.com/ss_thumbnails/12fromiaastopaas-180628162504-thumbnail.jpg?width=640&height=640&fit=bounds)


![[웨비나] 클라우드 마이그레이션 수행 시 가장 많이 하는 질문 Top 10!](https://cdn.slidesharecdn.com/ss_thumbnails/cloudmigrationwebinar-210726021030-thumbnail.jpg?width=640&height=640&fit=bounds)




![[OpenInfra Days Korea 2018] (Track 1) 커뮤니티 오픈스택 패키징 도입 전략 및 구현사례 발표](https://cdn.slidesharecdn.com/ss_thumbnails/14openstackpackagingstrategy-180704054102-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]오픈소스 클라우드 개발플랫폼_및_Docker의_이해_v1](https://cdn.slidesharecdn.com/ss_thumbnails/dockerv2-140827202405-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


![[OpenInfra Days Korea 2018] (오픈소스컨설팅) 키노트 - 최지웅 이사님](https://cdn.slidesharecdn.com/ss_thumbnails/064osic-180628162142-thumbnail.jpg?width=640&height=640&fit=bounds)



![[AWSKRUG] 모바일게임 하이브 런칭기 (2018)](https://cdn.slidesharecdn.com/ss_thumbnails/awskrugawsformobilegame-190419125248-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Partner TechShift 2017] 클라우드 시대 기존 Legacy에서 벗어나는 방법](https://cdn.slidesharecdn.com/ss_thumbnails/6-171101053200-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]이기종 WAS 클러스터링 솔루션- Athena Dolly](https://cdn.slidesharecdn.com/ss_thumbnails/athena-dollyv3-150206074107-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)





![[오픈소스컨설팅]파일럿진행예제 on AWS](https://cdn.slidesharecdn.com/ss_thumbnails/osconaws-151026093255-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
























