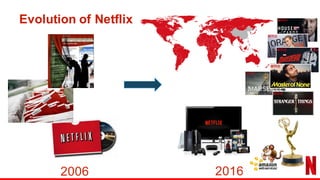
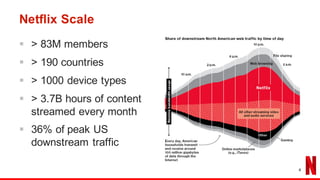
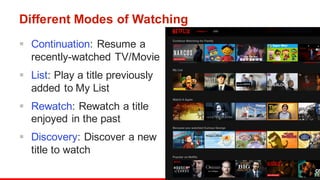
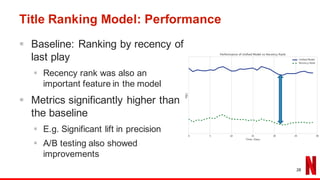
The document outlines the evolution of Netflix's recommendation system from 2006 to 2016, highlighting the importance of recommendation algorithms in enhancing user experience. It discusses various watching modes, such as continuation and discovery, and details different approaches to building models for recommendation, including unified and dedicated models. Key findings emphasize that improving recommendations for 'continue watching' significantly enhances member engagement and experience.