#SMX #23A @maxxeight
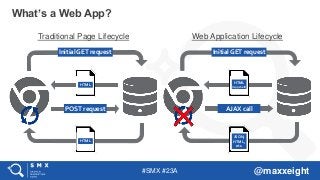
TraditionalPage Lifecycle Web Application Lifecycle
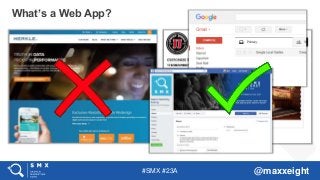
What’s a Web App?
Initial GET request
POST request
HTML
HTML
Initial GET request
AJAX call
HTML
(App shell)
JSON,
HTML,
etc.
#SMX #23A @maxxeight
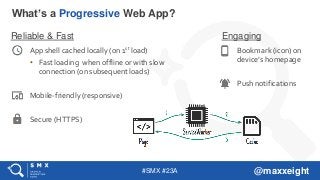
Reliable& Fast
App shell cached locally (on 1st load)
• Fast loading when offline or with slow
connection (on subsequent loads)
Mobile-friendly (responsive)
Secure (HTTPS)
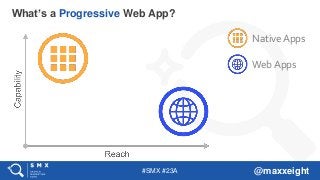
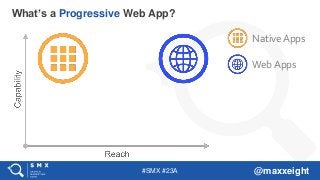
What’s a Progressive Web App?
Engaging
Bookmark (icon) on
device’s homepage
Push notifications
#SMX #23A @maxxeight
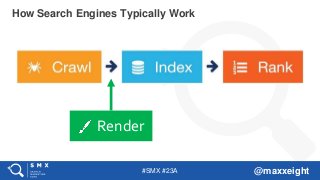
RenderingOn Google Search
Googlebot uses a web rendering service (WRS)
that is based on Chrome 41 (M41).
However:
Some features and APIs, such as IndexedDB
or Service Workers, are disabled.
Google doesn’t install or use Service Workers
when crawling PWAs #SMXInsights
12.
#SMX #23A @maxxeight
Issuesfor all crawlers
Potentially a unique URL (or non-crawlable URLs)
A unique HTML document (the “app shell”)
– Same <head> section (title, meta and link tags, etc.)
Issues for crawlers other than Google (and Baidu)
Client-side rendering of content (HTML source code vs. DOM)
Web Apps (SPAs, PWAs)
13.
#SMX #23A @maxxeight
Crawling
– 1 unique “clean” URL per piece of content (and vice-versa)
Making Sure Search Engines Can Understand Your Pages
14.
#SMX #23A @maxxeight
Crawling:Provide “Clean”/Crawlable URLs
Fragment Identifier: example.com/#url
– Not supported. Ignored. URL = example.com
Hashbang: example.com/#!url (pretty URL)
– Google and Bing will request:
example.com/?_escaped_fragment_=url (ugly URL)
– The escaped_fragment URL should return an HTML snapshot
Clean URL: example.com/url
– Leveraging the pushState function from the History API
– Must return a 200 status code when loaded directly
15.
#SMX #23A @maxxeight
Crawling
– 1 unique “clean” URL per piece of content (and vice-versa)
– onclick + window.location ≠ <a href=”link.html”>
Making Sure Search Engines Can Understand Your Pages
16.
#SMX #23A @maxxeight
Crawling
– 1 unique “clean” URL per piece of content (and vice-versa)
– onclick + window.location ≠ <a href=”link.html”>
Rendering
– Don’t block JavaScript resources via robots.txt
Making Sure Search Engines Can Understand Your Pages
#SMX #23A @maxxeight
Crawling
– 1 unique “clean” URL per piece of content (and vice-versa)
– onclick + window.location ≠ <a href=”link.html”>
Rendering
– Don’t block JavaScript resources via robots.txt
– Load content automatically, not based on user interaction (click,
mouseover, scroll)
– For Bing and other crawlers: HTML snapshots
Making Sure Search Engines Can Understand Your Pages
21.
#SMX #23A @maxxeight
Crawling
– 1 unique “clean” URL per piece of content (and vice-versa)
– onclick + window.location ≠ <a href=”link.html”>
Rendering
– Don’t block JavaScript resources via robots.txt
– Load content automatically, not based on user interaction (click,
mouseover, scroll)
– For Bing and other crawlers: HTML snapshots
Indexing
– Avoid duplicate <head> section elements (title, meta description,
etc.)
Making Sure Search Engines Can Understand Your Pages
22.
#SMX #23A @maxxeight
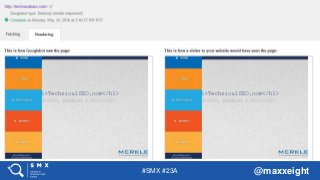
Maincontent gets
rendered here
Same title, description,
canonical tag, etc. for
every URL
23.
#SMX #23A @maxxeight
Sharethese #SMXInsights on your social channels!
#SMXInsights
SEO Best Practices For JavaScript
Sites
– Crawling: use clean URLs and proper <a href> elements
– Rendering: avoid blocking resources and loading content
upon user interaction
– Indexing: make sure meta data in <head> is not
duplicated across pages
#SMX #23A @maxxeight
Sharethese #SMXInsights on your social channels!
#SMXInsights
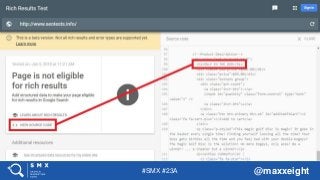
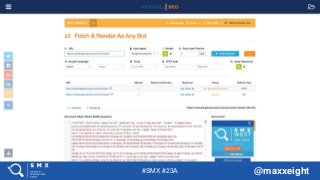
The Rich Results Testing Tool is the only Google-
provided tool showing the rendered code (DOM)
#4 In computing, a web application or web app is a client–server computer program in which the client (including the user interface and client-side logic) runs in a web browser. Common web applications include webmail, online retail sales, online auctions, wikis, instant messaging services and many other functions.
https://en.wikipedia.org/wiki/Web_application
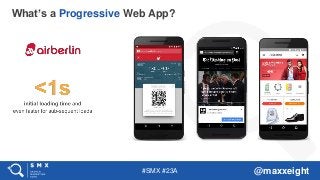
Any website can be a web app. But in general, a web app provides some type of functionality/interactive experience such as ordering something online.
“In general” sites with static content such as corporate websites and news publishers are not web apps. This changed with the rise of PWAs.
#5 Single-Page Applications (SPAs) are Web apps that load a single HTML page and dynamically update that page as the user interacts with the app. SPAs use AJAX and HTML5 to create fluid and responsive Web apps, without constant page reloads. However, this means much of the work happens on the client side, in JavaScript.
https://msdn.microsoft.com/en-us/magazine/dn463786.aspx
#6 Why is the reach of web apps higher? Search engines (vs. app stores).
#11 “rendering” is the keyword. Google is, since a few years now, rendering web pages, after crawling and before indexing, in order to understand them better.
#15 Fragment identifier: this URL structure is already a concept in the web and relates to deep linking into content on a particular page (“jump links”).
Can’t be accessed/crawled/indexed.
Hashbang: Used with the “old” AJAX crawling scheme. Not recommended, more complex to implement.
Clean URL using History API’s pushState function.
AJAX-crawling scheme
Google has deprecated this recommendation in October 2015
Won’t be supported by ~Q2 2018
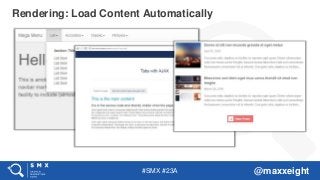
#20 Mega menu – mouseover + ajax
Tabs/accordeons – click + ajax
Load more/infinite scroll - click/scroll + ajax
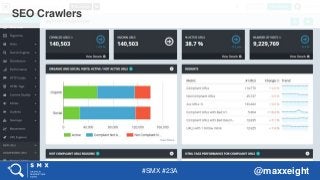
#27 But it’s still a better source of info than the cache.
It fetches pages from a Google IP (it makes a difference sometimes for websites blocking “Googlebot” user-agent if not coming from a known Google IP)
It leverages Googlebot’s JavaScript rendering engine which is likely to be more advanced than PhantomJS.
#28 But it’s still a better source of info than the cache.
It fetches pages from a Google IP (it makes a difference sometimes for websites blocking “Googlebot” user-agent if not coming from a known Google IP)
It leverages Googlebot’s JavaScript rendering engine which is likely to be more advanced than PhantomJS.