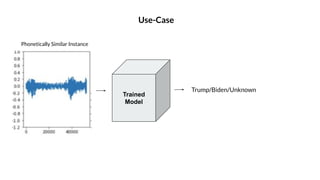
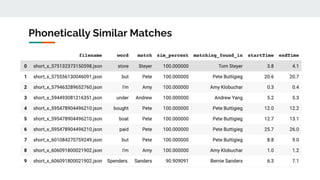
The document discusses the challenges of accurately transcribing candidate names using speech-to-text software and proposes a CNN-based name recognition model to address this issue. The approach includes extracting known name instances, training the model on these instances, and improving the dataset with audio data for uncommon names. Future steps involve testing the model's accuracy on specific candidates and generating additional data to enhance performance.