Download as PDF, PPTX














![Intents [*]
• SearchCreativeWork (e.g. Find me the I, Robot television show)
• GetWeather (e.g. Is it windy in Boston, MA right now?)
• BookRestaurant (e.g. I want to book a highly rated restaurant for
me and my boyfriend tomorrow night)
• PlayMusic (e.g. Play the last track from Beyoncé off Spotify)
• AddToPlaylist (e.g. Add Diamonds to my roadtrip playlist)
• RateBook (e.g. Give 6 stars to Of Mice and Men)
• SearchScreeningEvent (e.g. Check the showtimes for Wonder
Woman in Paris)
[*] quoted from https://github.com/snipsco/nlu-benchmark/tree/master/2017-06-custom-intent-engines
August 2017© Intento, Inc.](https://image.slidesharecdn.com/intentdetectionbenchmarkaugust2017-170817145622/75/NLU-Intent-Detection-Benchmark-by-Intento-August-2017-15-2048.jpg)


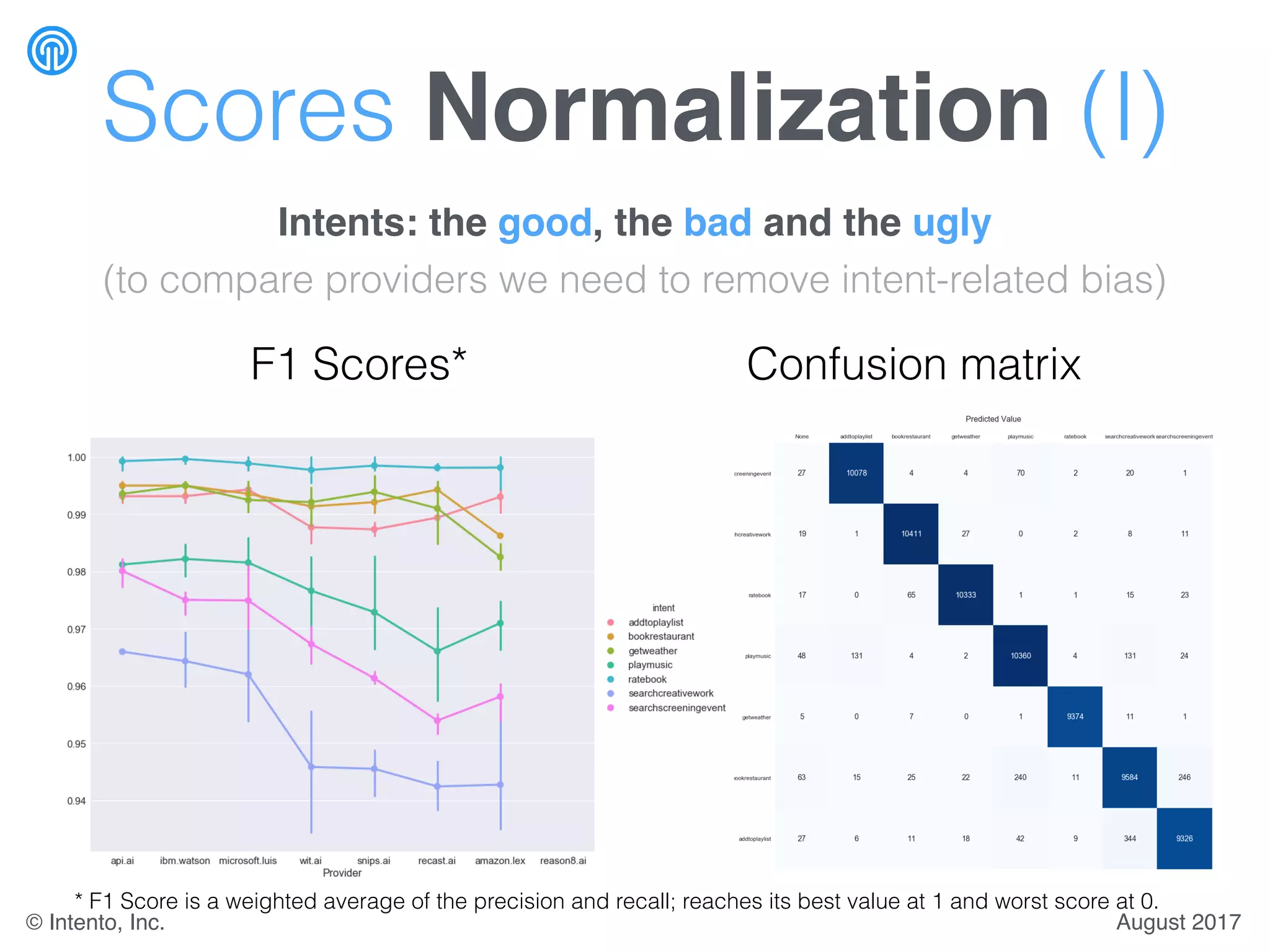
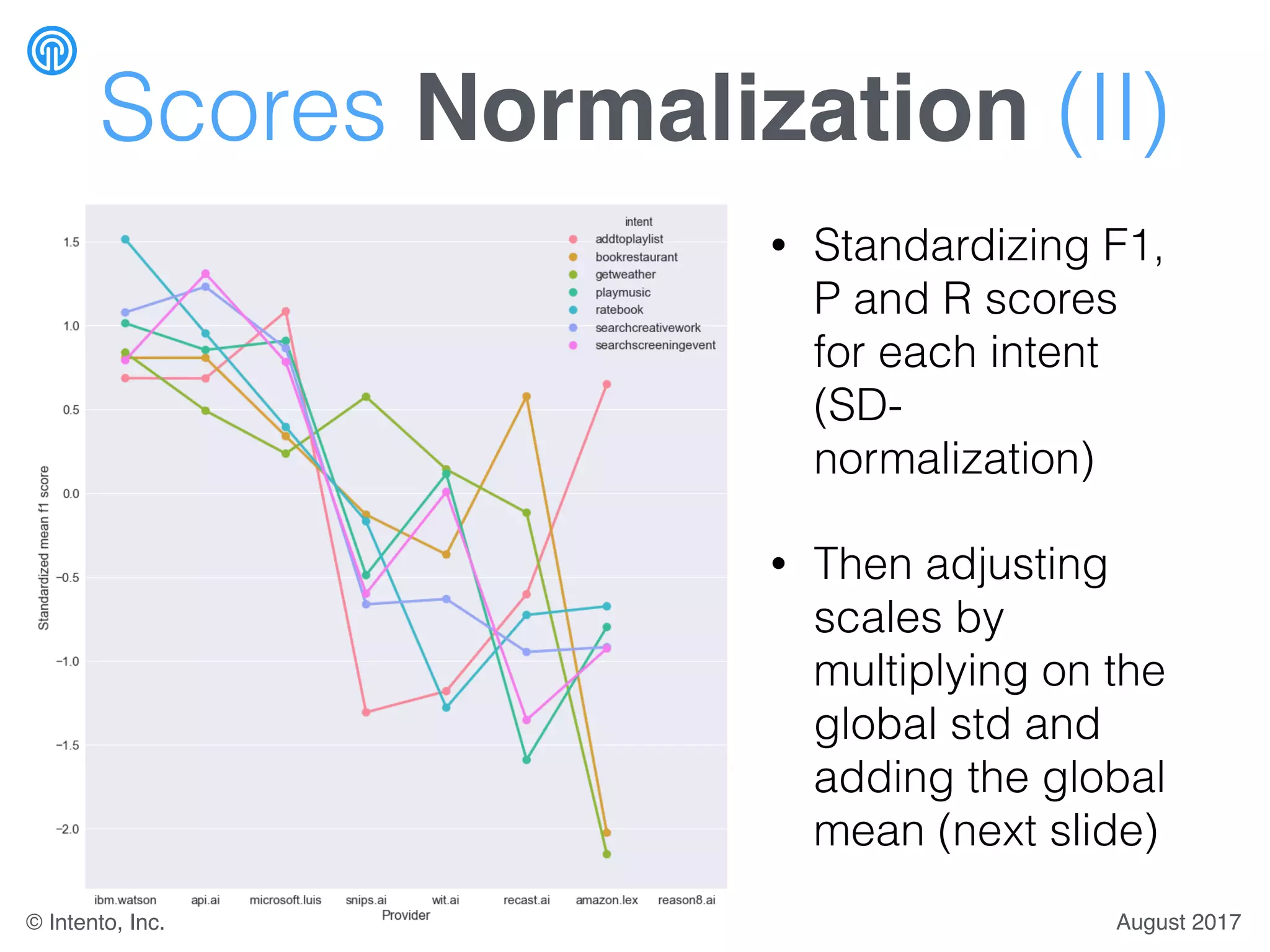
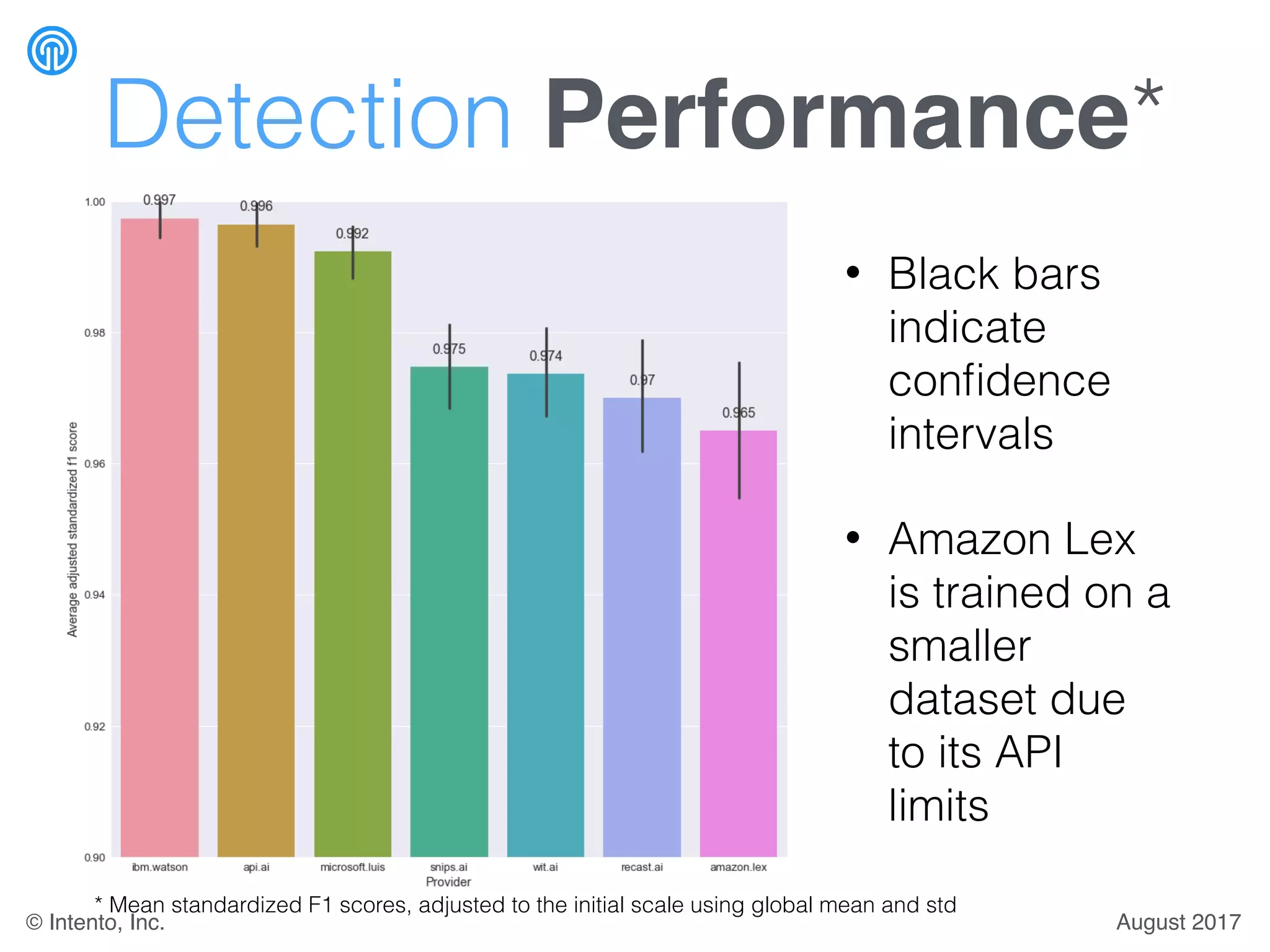
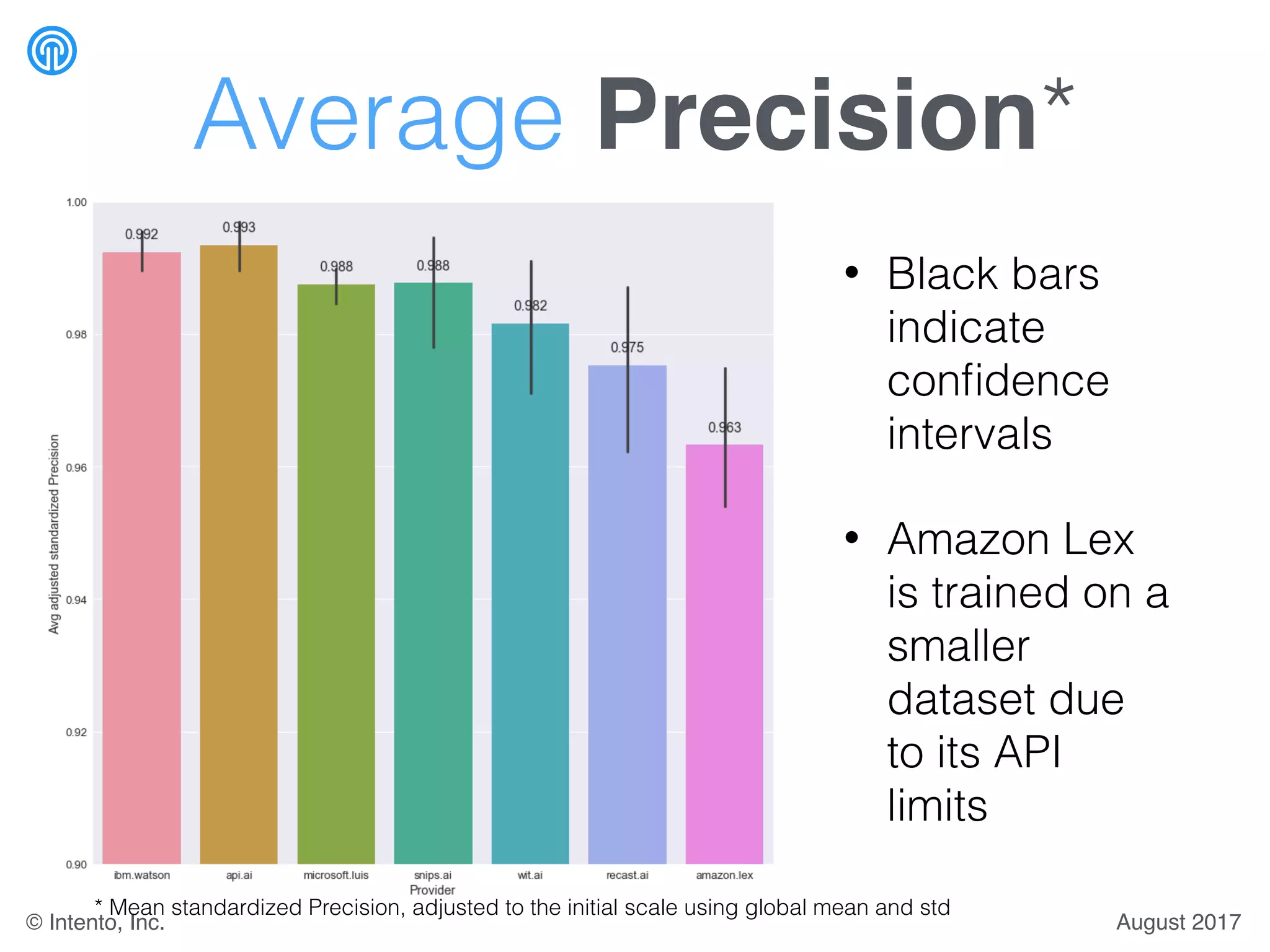
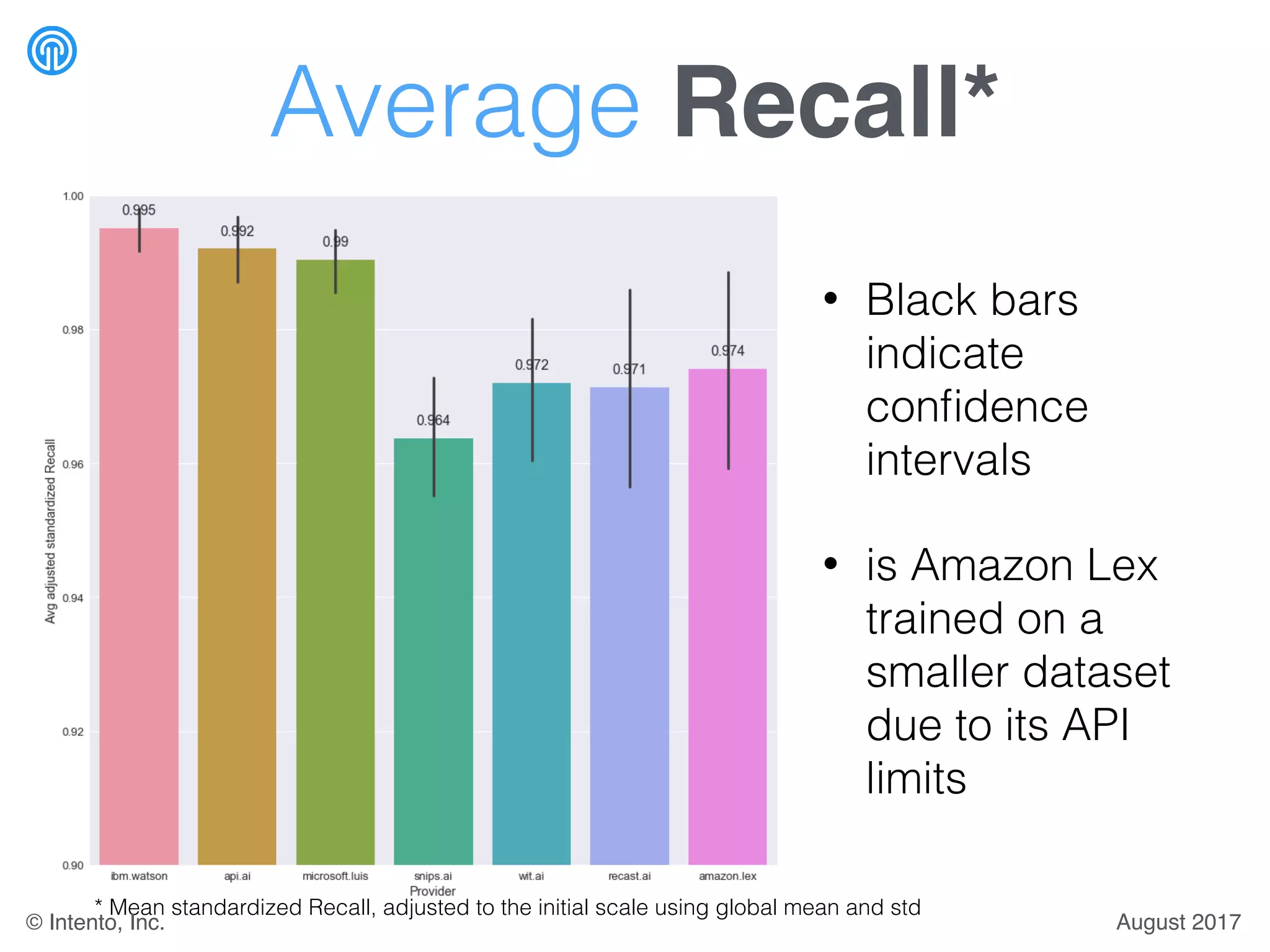
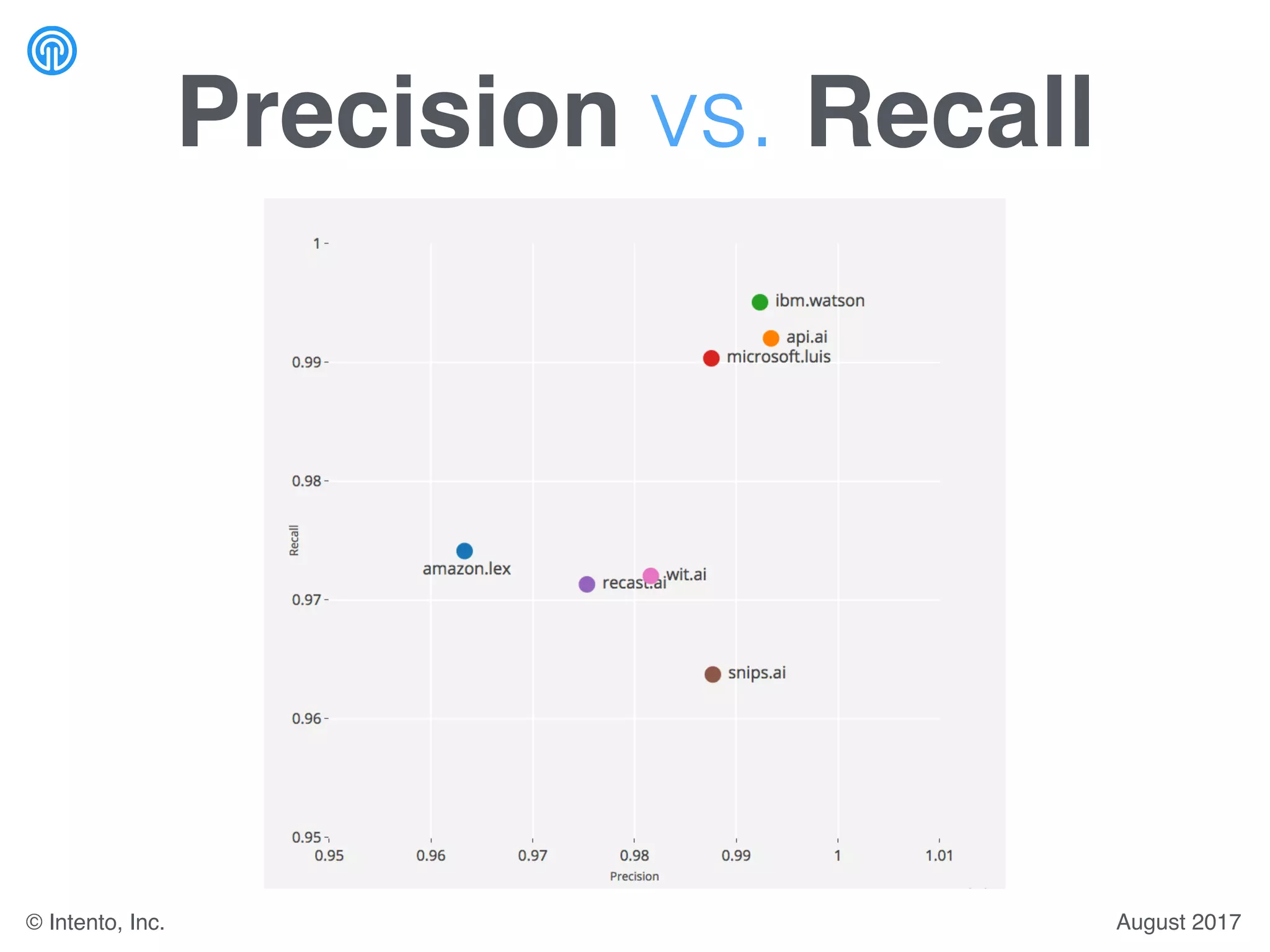



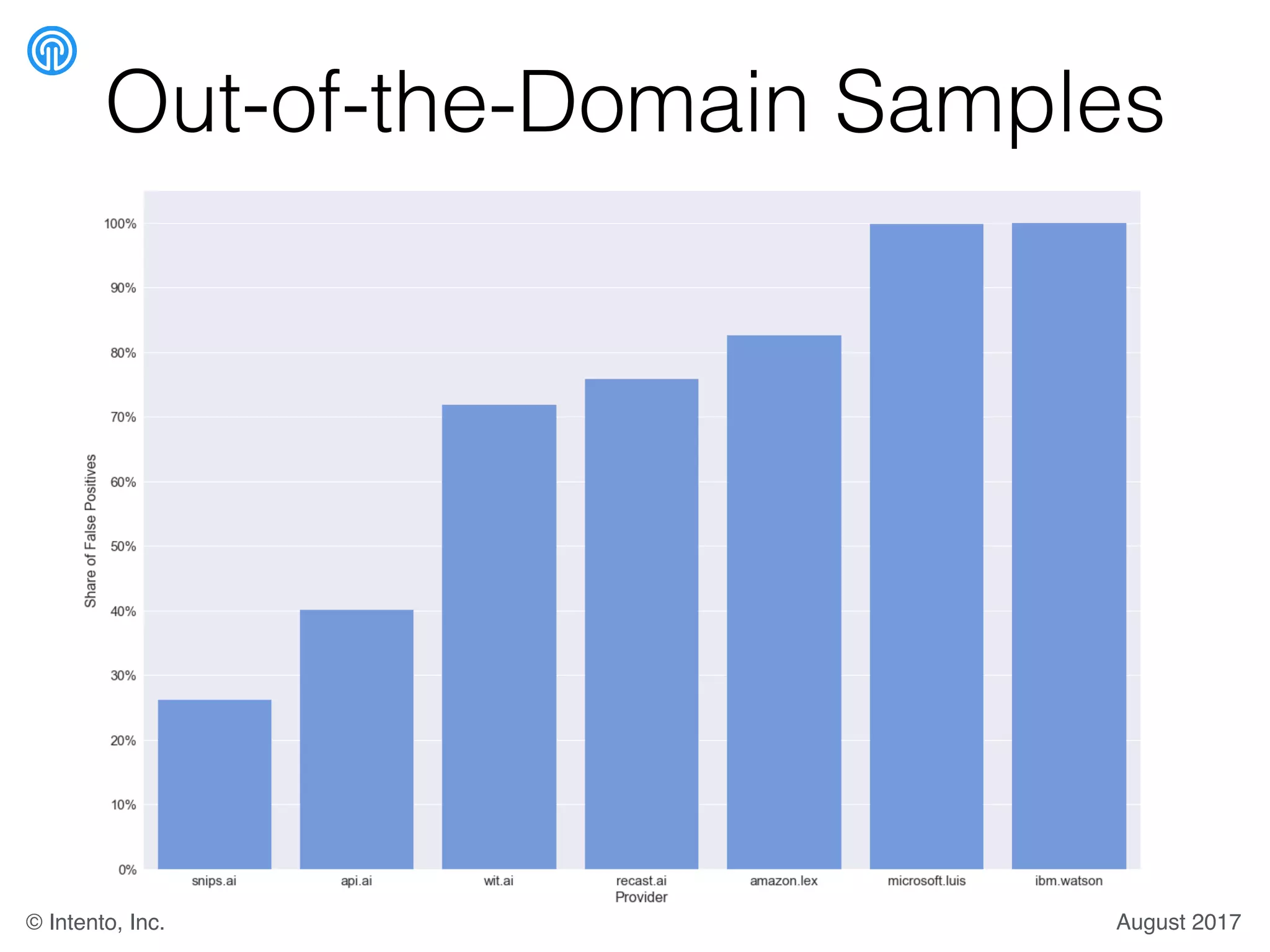



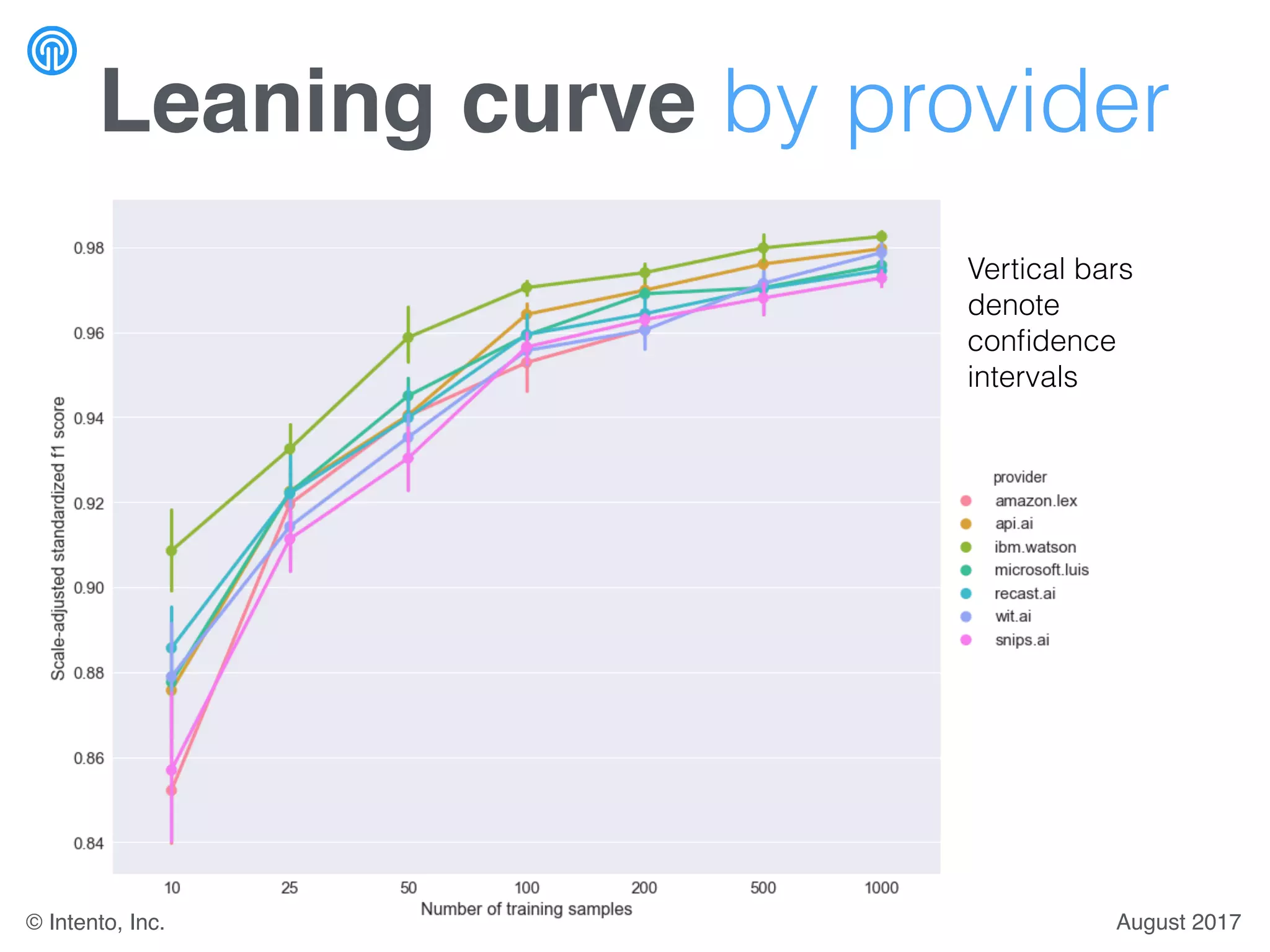



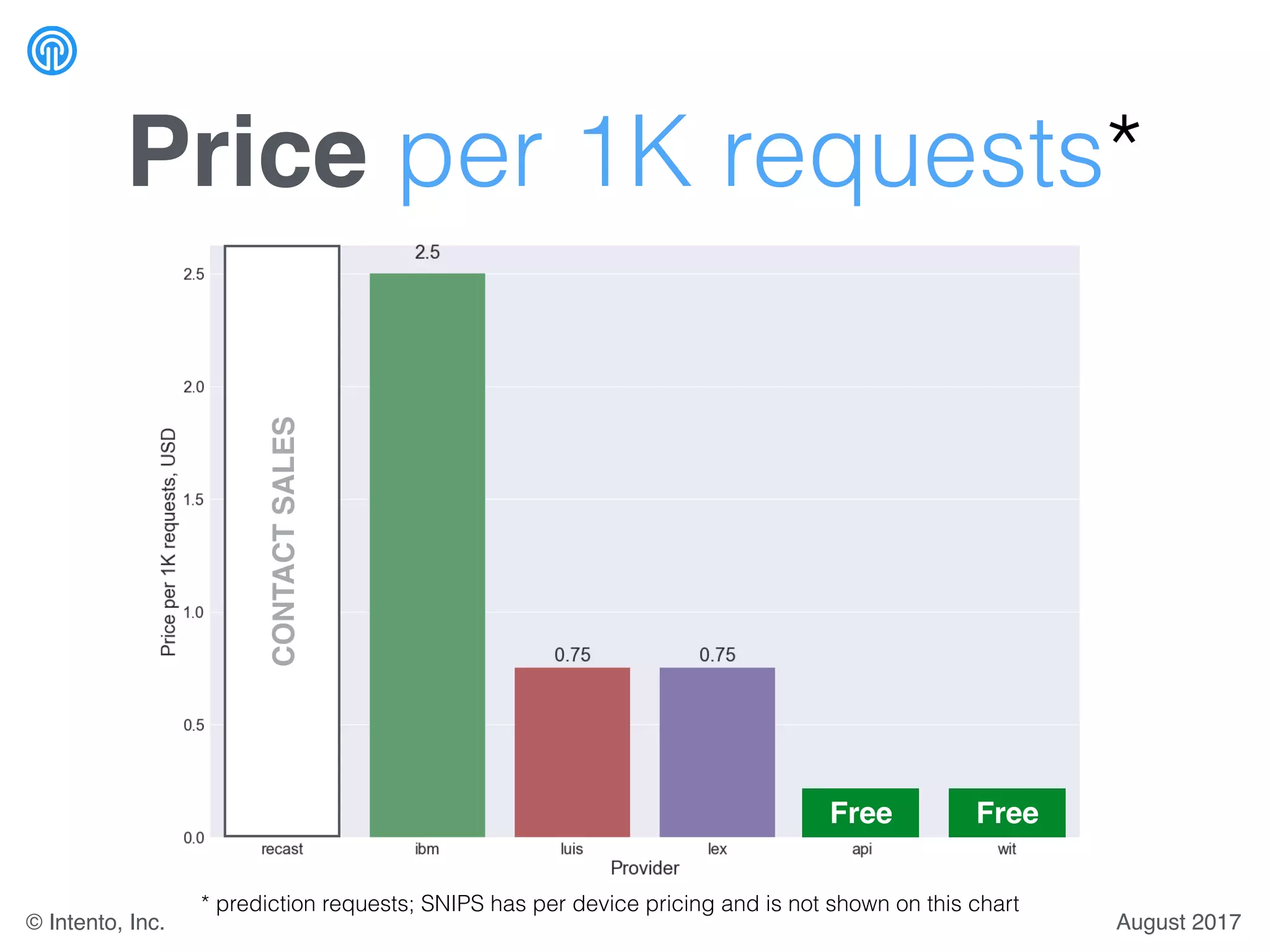

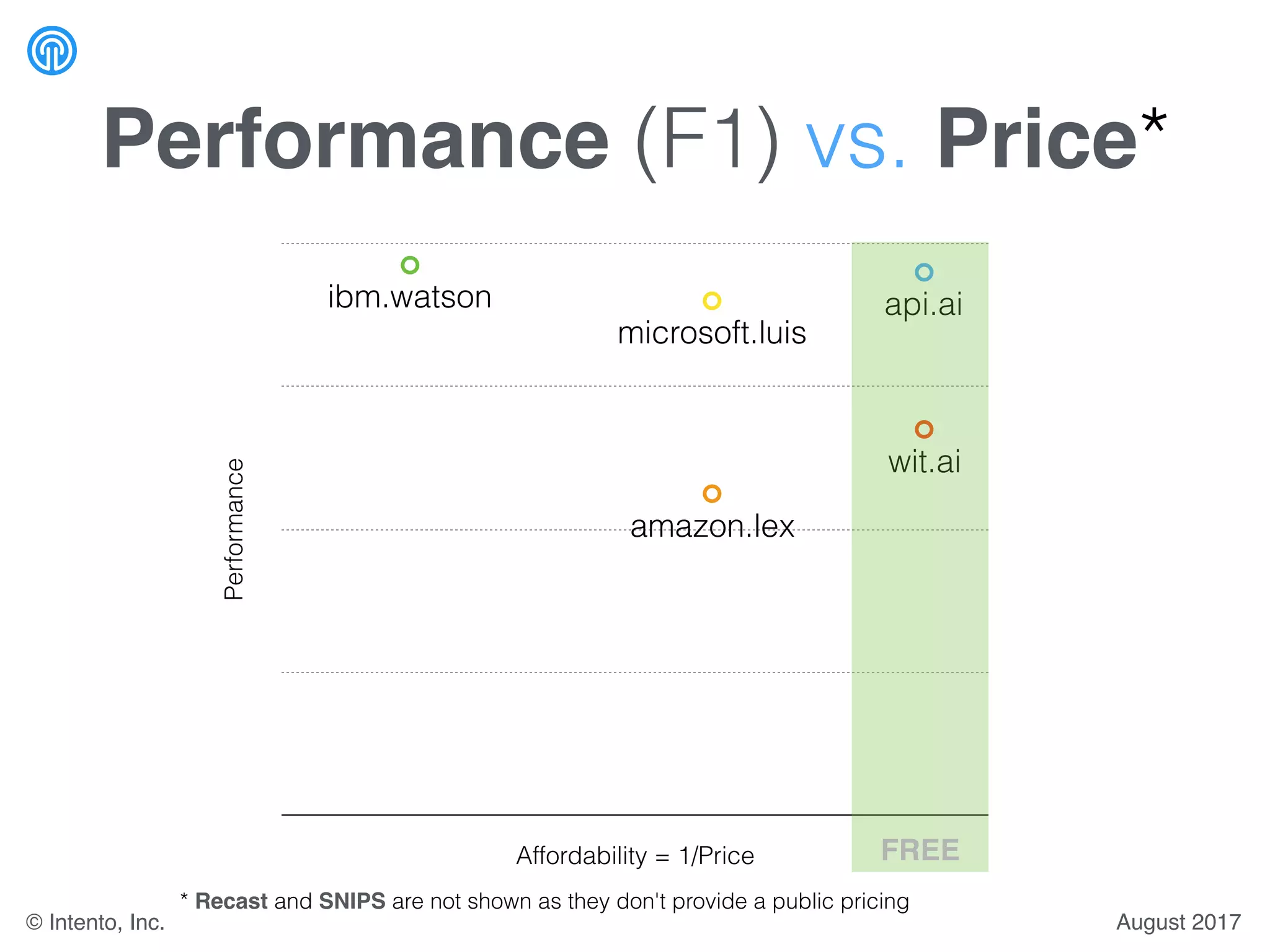
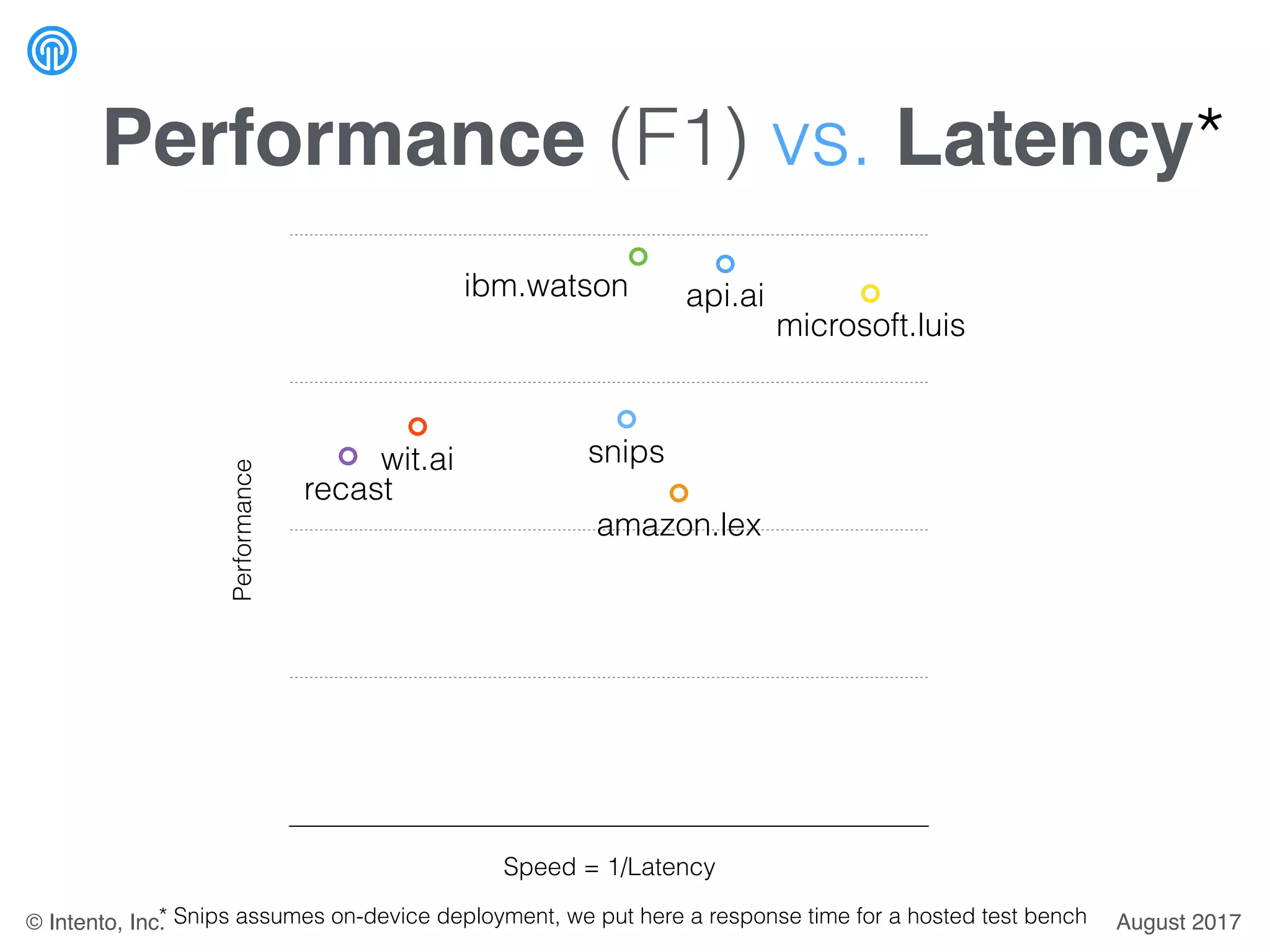




The document presents a benchmark for natural language understanding (NLU) services, evaluating various providers based on intent prediction performance, false positives, learning speed, language coverage, price, and response time. It ranks providers like IBM Watson, API.ai, and Microsoft LUIS as top performers while discussing challenges such as training models and detecting out-of-domain intents. The findings suggest a need for thorough evaluation of providers based on specific intent and dataset characteristics before making a provider choice.
























![MiniTool Partition Wizard 12.8 Crack License Key [2025] Free](https://cdn.slidesharecdn.com/ss_thumbnails/katherinemunro-intentdetection-250216113000-adcae328-250408154546-9489a8d6-250701095512-e9f48431-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 24] Katherine Munro - Where there’s a will, there’s a way: The ma...](https://cdn.slidesharecdn.com/ss_thumbnails/katherinemunro-intentdetection-250216113000-adcae328-thumbnail.jpg?width=640&height=640&fit=bounds)











![[2C3]Developing context-aware applications](https://cdn.slidesharecdn.com/ss_thumbnails/2c3marsalgavalda-expectlabs-final-140929193137-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
































