Top 5 Lessons Learned in Building Streaming Applications at Microsoft Bing Scale
1.
Top Five LessonsLearned in
Building Streaming Applications at
Microsoft Bing Scale
Renyi Xiong
Microsoft
2.
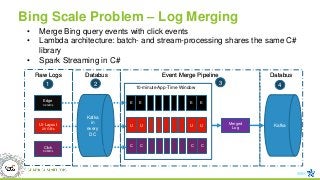
Bing Scale Problem– Log Merging
Edge
3.2 GB/s
UI-Layout
2.8 GB/s
Click
69 MB/s
Kafka
in
every
DC
E E E E
U U U U
C C C C
Merged
Log
Raw Logs Databus Event Merge Pipeline
10-minute App-Time Window10
Kafka
Databus
1 2 3 4
• Merge Bing query events with click events
• Lambda architecture: batch- and stream-processing shares the same C#
library
• Spark Streaming in C#
Lesson 1: UseUpdateStateByKey to join DStreams
• Problem
• Application time is not supported in Spark 1.6.
• Solution – UpdateStateByKey
• UpdateStateByKey takes a custom JoinFunction as input parameter;
• Custom JoinFunction enforces time window based on Application Time;
• UpdateStateByKey maintains partially joined events as the state
Edge DStream
Click DStream
Batch job 1
RDD @ time 1
Batch job 2
RDD @ time 2
State DStream
UpdateStateByKey
Batch job 3
RDD @ time 3
Pseudo Code
Iterator[(K, S)] JoinFunction(
int pid, Iterator[(K:key, Iterator[V]:newEvents, S:oldState)] events)
{
val currentTime = events.newEvents.max(e => e.eventTime);
foreach (var e in events) {
val newState = <oldState join newEvents>
if (oldState.min(s => s.eventTime) + TimeWindow < currentTime) // TimeWindow 10minutes
<output to external storage>
else
return (key, newState)
}
}
UpdateStateByKey C# API
PairDStreamFunctions.cs, https://github.com/Microsoft/Mobius
5.
Lesson 2: DynamicRepartition with Kafka Direct Approach
• Problem
• Unbalanced Kafka partitions caused delay in the pipeline
• Solution – Dynamic Repartition
1. Repartition data from one Kafka partition into multiple RDDs without extra
shuffling cost of DStream.Repartition
2. Repartition threshold is configurable per topic
After Dynamic Repartition
Pseudo Code
class DynamicPartitionKafkaRDD(kafkaPartitionOffsetRanges)
override def getPartitions {
// repartition threshold per topic loaded from config
val maxRddPartitionSize = Map<topic, partitionSize>
// apply max repartition threshold
kafkaPartitionOffsetRanges.flatMap { case o =>
val rddPartitionSize = maxRddPartitionSize(o.topic)
(o.fromOffset until o.untilOffset by rddPartitionSize).map(
s => (o.topic, o.partition, s, (o.untilOffset, s + rddPartitionSize)))
}
}
Source Code
DynamicPartitionKafkaRDD.scala - https://github.com/Microsoft/Mobius
2-minute interval Before Dynamic Repartition
6.
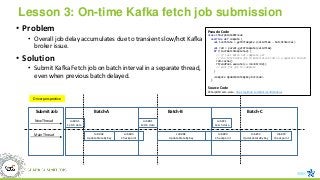
Lesson 3: On-timeKafka fetch job submission
• Problem
• Overall job delay accumulates due to transient slow/hot Kafka
broker issue.
• Solution
• Submit Kafka Fetch job on batch interval in a separate thread,
even when previous batch delayed.
Job#A2
UpdateStateByKey
Job#A1
Fetch data
Batch-A
New Thread
Job#A3
Checkpoint
Job#B2
UpdateStateByKey
Job#B1
Fetch data
Batch-B
Job#B3
Checkpoint
Job#C2
UpdateStateByKey
Job#C1
Fetch data
Batch-C
Job#C3
checkpoint
Main Thread
Submit Job
Pseudo Code
class CSharpStateDStream
override def compute {
val lastState = getOrCompute (validTime - batchInterval)
val rdd = parent.getOrCompute(validTime)
if (!lastBatchCompleted) {
// if last batch not complete yet
// run Fetch data job to materialize rdd in a separate thread
rdd.cache()
ThreadPool.execute(sc.runJob(rdd))
// wait for job to complele
}
<compute UpdateStateByKey Dstream>
}
Source Code
CSharpDStream.scala - https://github.com/Microsoft/Mobius
Driver perspective
7.
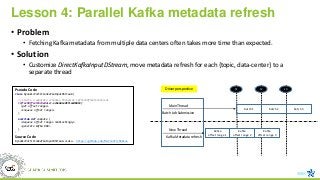
Lesson 4: ParallelKafka metadata refresh
• Problem
• Fetching Kafka metadata from multiple data centers often takes more time than expected.
• Solution
• Customize DirectKafkaInputDStream, move metadata refresh for each {topic, data-center} to a
separate thread
Kafka
offset range 1
t3
Main Thread
t2
New Thread
t1
Kafka
offset range 2
Kafka
offset range 3
batch 1 batch 2 batch 3
Batch Job Submission
Kafka Metadata refresh
Pseudo Code
class DynamicPartitionKafkaInputDStream {
// starts a separate schedule thread at refreshOffsetsInterval
refreshOffsetsScheduler.scheduleAtFixedRate(
<get offset ranges>
<enqueue offset ranges>
)
override def compute {
<dequeue offset ranges nonblockingly>
<generate kafka RDD>
}
}
Source Code
DynamicPartitionKafkaInputDStream.scala - https://github.com/Microsoft/Mobius
Driver perspective
8.
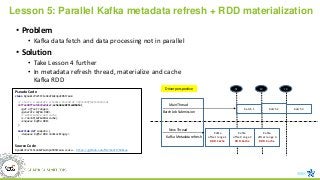
Lesson 5: ParallelKafka metadata refresh + RDD materialization
• Problem
• Kafka data fetch and data processing not in parallel
• Solution
• Take Lesson 4 further
• In metadata refresh thread, materialize and cache
Kafka RDD
Kafka
offset range 1
RDD.Cache
t3
Main Thread
t2
New Thread
t1
Kafka
offset range 2
RDD.Cache
Kafka
offset range 3
RDD.Cache
batch 1 batch 2 batch 3
Batch Job Submission
Kafka Metadata refresh
Driver perspective
Pseudo Code
class DynamicPartitionKafkaInputDStream
// starts a separate schedule thread at refreshOffsetsInterval
refreshOffsetsScheduler.scheduleAtFixedRate(
<get offset ranges>
<generate kafka RDD>
// materialize and cache
sc.runJob(kafkaRdd.cache)
<enqueue kafka RDD>
)
override def compute {
<dequeue kafka RDD nonblockingly>
}
Source Code
DynamicPartitionKafkaInputDStream.scala - https://github.com/Microsoft/Mobius
9.
THANK YOU.
• Specialthanks to TD and Ram from Databricks for all the support
• Contact us
• Renyi Xiong, renyix@microsoft.com
• Kaarthik Sivashanmugam, ksivas@microsoft.com
• mobiuscore@microsoft.com


![Lesson 1: Use UpdateStateByKey to join DStreams
• Problem
• Application time is not supported in Spark 1.6.
• Solution – UpdateStateByKey
• UpdateStateByKey takes a custom JoinFunction as input parameter;
• Custom JoinFunction enforces time window based on Application Time;
• UpdateStateByKey maintains partially joined events as the state
Edge DStream
Click DStream
Batch job 1
RDD @ time 1
Batch job 2
RDD @ time 2
State DStream
UpdateStateByKey
Batch job 3
RDD @ time 3
Pseudo Code
Iterator[(K, S)] JoinFunction(
int pid, Iterator[(K:key, Iterator[V]:newEvents, S:oldState)] events)
{
val currentTime = events.newEvents.max(e => e.eventTime);
foreach (var e in events) {
val newState = <oldState join newEvents>
if (oldState.min(s => s.eventTime) + TimeWindow < currentTime) // TimeWindow 10minutes
<output to external storage>
else
return (key, newState)
}
}
UpdateStateByKey C# API
PairDStreamFunctions.cs, https://github.com/Microsoft/Mobius](https://image.slidesharecdn.com/1frenyixiong-160614003642/85/Top-5-Lessons-Learned-in-Building-Streaming-Applications-at-Microsoft-Bing-Scale-4-320.jpg?cb=1465864660)



























































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)









