








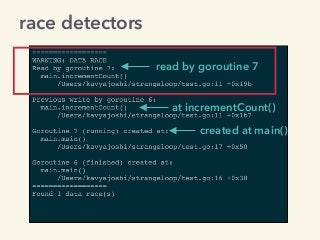










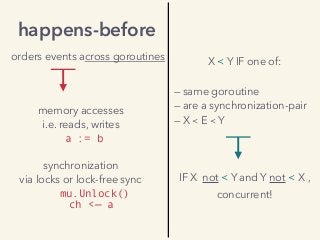


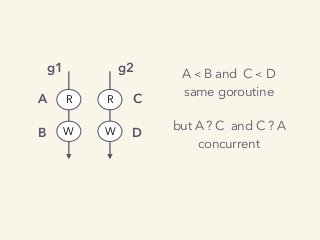

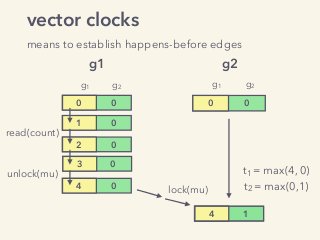

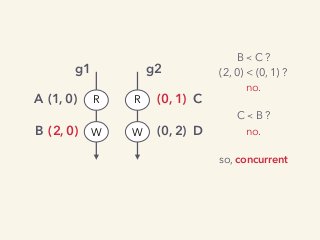



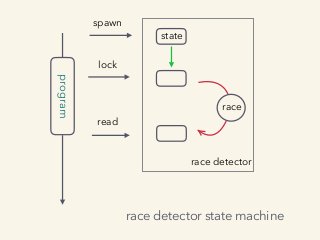

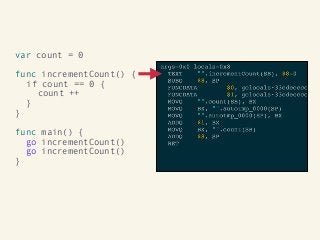
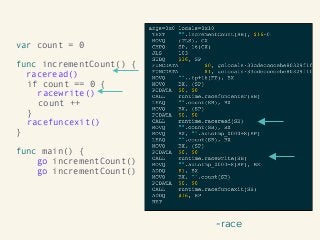





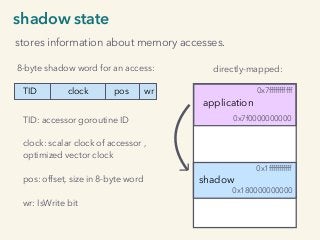
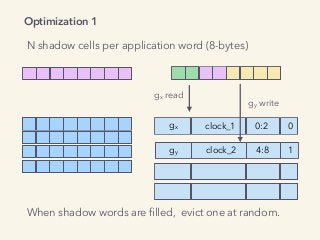
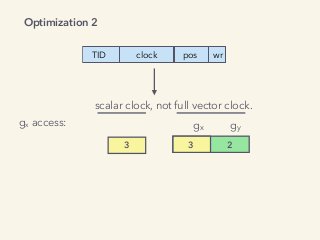
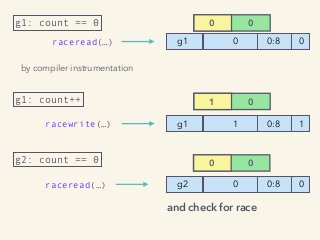

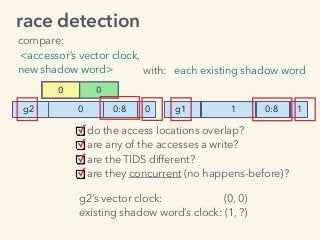

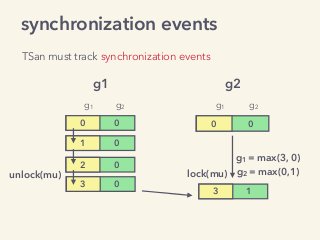
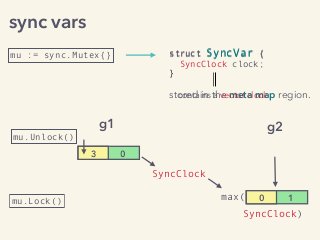











Video and slides synchronized, mp3 and slide download available at URL http://bit.ly/2mAUqqs. Kavya Joshi discusses the internals of the Go race detector and delves into the compiler instrumentation of the program, and the runtime module that detects data races. She also talks about the optimizations that make the dynamic race detector practical for use in the real world, and evaluates how practical it really is. Filmed at qconsf.com. Kavya Joshi is a Software Engineer at Samsara. She particularly enjoys architecting and building highly concurrent, highly scalable systems.































































