Download to read offline








![Sum recursion - No Tail Call Optimization
defmodule NoTCO do
def sum_no_tco([]), do: 0
def sum_no_tco([head | tail]) do
head + sum_no_tco(tail)
end
end](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-10-320.jpg)
![Sum function - Without Tail Call
defmodule NoTCO do
def sum_no_tco([]), do: 0
def sum_no_tco([head | tail]) do
head + sum_no_tco(tail)
end
end
NoTCO.sum_no_tco([1, 2, 3, 4])](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-11-320.jpg)
![Sum function - Without Tail Call
defmodule NoTCO do
def sum_no_tco([]), do: 0
def sum_no_tco([head | tail]) do
head + sum_no_tco(tail)
end
end
NoTCO.sum_no_tco([1, 2, 3, 4])
1 + sum_no_tco([2, 3, 4])](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-12-320.jpg)
![Sum function - Without Tail Call
defmodule NoTCO do
def sum_no_tco([]), do: 0
def sum_no_tco([head | tail]) do
head + sum_no_tco(tail)
end
end
NoTCO.sum_no_tco([1, 2, 3, 4])
1 + sum_no_tco([2, 3, 4])
+ 2 + sum_no_tco([3, 4])](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-13-320.jpg)
![Sum function - Without Tail Call
defmodule NoTCO do
def sum_no_tco([]), do: 0
def sum_no_tco([head | tail]) do
head + sum_no_tco(tail)
end
end
NoTCO.sum_no_tco([1, 2, 3, 4])
1 + sum_no_tco([2, 3, 4])
+ 2 + sum_no_tco([3, 4])
+ 3 + sum_no_tco([4])](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-14-320.jpg)
![Sum function - Without Tail Call
defmodule NoTCO do
def sum_no_tco([]), do: 0
def sum_no_tco([head | tail]) do
head + sum_no_tco(tail)
end
end
NoTCO.sum_no_tco([1, 2, 3, 4])
1 + sum_no_tco([2, 3, 4])
+ 2 + sum_no_tco([3, 4])
+ 3 + sum_no_tco([4])
+ 4 + sum_no_tco([])](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-15-320.jpg)
![Sum function - Without Tail Call
defmodule NoTCO do
def sum_no_tco([]), do: 0
def sum_no_tco([head | tail]) do
head + sum_no_tco(tail)
end
end
NoTCO.sum_no_tco([1, 2, 3, 4])
1 + sum_no_tco([2, 3, 4])
+ 2 + sum_no_tco([3, 4])
+ 3 + sum_no_tco([4])
+ 4 + sum_no_tco([])
+ 0](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-16-320.jpg)
![Sum function - Without Tail Call
defmodule NoTCO do
def sum_no_tco([]), do: 0
def sum_no_tco([head | tail]) do
head + sum_no_tco(tail)
end
end
NoTCO.sum_no_tco([1, 2, 3, 4])
1 + sum_no_tco([2, 3, 4])
+ 2 + sum_no_tco([3, 4])
+ 3 + sum_no_tco([4])
+ 4 + 0](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-17-320.jpg)
![Sum function - Without Tail Call
defmodule NoTCO do
def sum_no_tco([]), do: 0
def sum_no_tco([head | tail]) do
head + sum_no_tco(tail)
end
end
NoTCO.sum_no_tco([1, 2, 3, 4])
1 + sum_no_tco([2, 3, 4])
+ 2 + sum_no_tco([3, 4])
+ 3 + 4](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-18-320.jpg)
![Sum function - Without Tail Call
defmodule NoTCO do
def sum_no_tco([]), do: 0
def sum_no_tco([head | tail]) do
head + sum_no_tco(tail)
end
end
NoTCO.sum_no_tco([1, 2, 3, 4])
1 + sum_no_tco([2, 3, 4])
+ 2 + 7](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-19-320.jpg)
![Sum function - Without Tail Call
defmodule NoTCO do
def sum_no_tco([]), do: 0
def sum_no_tco([head | tail]) do
head + sum_no_tco(tail)
end
end
NoTCO.sum_no_tco([1, 2, 3, 4])
1 + 9](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-20-320.jpg)
![Sum function - Without Tail Call
defmodule NoTCO do
def sum_no_tco([]), do: 0
def sum_no_tco([head | tail]) do
head + sum_no_tco(tail)
end
end
NoTCO.sum_no_tco([1, 2, 3, 4])
= 10](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-21-320.jpg)
![Sum function - Tail Call Optimization
defmodule TCO do
def sum([], acc), do: acc
def sum([head | tail], acc) do
sum(tail, head + acc)
end
end](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-22-320.jpg)
![Sum function - Tail Call Optimization
defmodule TCO do
def sum([], acc), do: acc
def sum([head | tail], acc) do
sum(tail, head + acc)
end
end
TCO.sum([1, 2, 3, 4], 0)](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-23-320.jpg)
![Sum function - Tail Call Optimization
defmodule TCO do
def sum([], acc), do: acc
def sum([head | tail], acc) do
sum(tail, head + acc)
end
end
TCO.sum([1, 2, 3, 4], 0)
sum([2, 3, 4], 1)](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-24-320.jpg)
![Sum function - Tail Call Optimization
defmodule TCO do
def sum([], acc), do: acc
def sum([head | tail], acc) do
sum(tail, head + acc)
end
end
TCO.sum([1, 2, 3, 4], 0)
sum([3, 4], 3)](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-25-320.jpg)
![Sum function - Tail Call Optimization
defmodule TCO do
def sum([], acc), do: acc
def sum([head | tail], acc) do
sum(tail, head + acc)
end
end
TCO.sum([1, 2, 3, 4], 0)
sum([4], 6)](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-26-320.jpg)
![Sum function - Tail Call Optimization
defmodule TCO do
def sum([], acc), do: acc
def sum([head | tail], acc) do
sum(tail, head + acc)
end
end
TCO.sum([1, 2, 3, 4], 0)
sum([], 10)](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-27-320.jpg)
![Sum function - Tail Call Optimization
defmodule TCO do
def sum([], acc), do: acc
def sum([head | tail], acc) do
sum(tail, head + acc)
end
end
TCO.sum([1, 2, 3, 4], 0)
10](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-28-320.jpg)
![Difference
defmodule TCO do
def sum([], acc), do: acc
def sum([head | tail], acc) do
sum(tail, head + acc)
end
end
defmodule NoTCO do
def sum_no_tco([]), do: 0
def sum_no_tco([head | tail]) do
head + sum_no_tco(tail)
end
end](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-29-320.jpg)
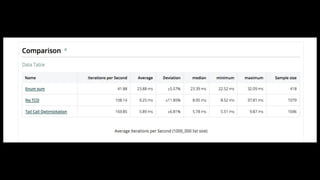
![inputs = %{
"1_000 list size" => Enum.to_list(1..1_000),
"100_000 list size" => Enum.to_list(1..1000_000),
"1000_000 list size" => Enum.to_list(1..1000_000),
}
Benchee.run(%{
"Tail Call Optimizitation" => fn(list) -> TCO.sum(list, 0) end,
"No TCO" => fn(list) -> NoTCO.sum_no_tco(list) end,
"Enum sum" => fn(list) -> Enum.sum(list) end
},
time: 10,
memory_time: 2,
inputs: inputs,
formatters: [
Benchee.Formatters.HTML,
Benchee.Formatters.Console
],
formatter_options: [html: [file: "lib/report/tco.html"]]
)](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-31-320.jpg)
![Real example
def parse(file_path, modifiers %{}, options %{}, take) do
file_path
|> File.stream!()
|> CsvParser.decode_csv()
|> Stream.take(take)
|> Stream.map(&process_item(&1, options, modifiers))
|> Stream.filter(&filter_items(&1, options["elastic_search_index" ]))
|> Stream.chunk_every(1000)
|> Stream.each(&store_items(&1, options["elastic_search_index" ]))
|> Stream.run()
end](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-34-320.jpg)
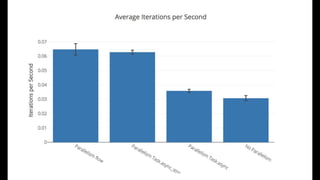
![[modifiers, file_path] = PpcbeeElixirBackend.Enhance.download(191)
Benchee.run(
%{
"No Parallelism" => fn ->
PpcbeeElixirBackend.DataParser.parse(file_path, modifiers, %{}, 10_000)
end,
"Parallelism Task.async_stream" => fn ->
PpcbeeElixirBackend.DataParser.parse_async_stream(file_path, modifiers, %{},10_000)
end,
"Parallelism Task.async" => fn ->
PpcbeeElixirBackend.DataParser.parse_async_task(file_path, modifiers, %{}, 10_000)
end,
"Parallelism flow" => fn ->
PpcbeeElixirBackend.DataParser.parse_flow(file_path, modifiers, %{}, 10_000)
end
},
time: 5 * 60,
formatters: [
Benchee.Formatters.HTML,
],
formatter_options: [html: [file: "lib/benchmark/report/parallelism/report.html"]]
)](https://image.slidesharecdn.com/benchmarkinginelixir-181106083508/85/FPBrno-2018-05-22-Benchmarking-in-elixir-35-320.jpg)






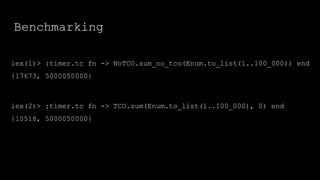
The document discusses benchmarking and profiling in Elixir. It begins with an introduction to Elixir and some of its common uses like web applications. It then covers topics like what benchmarking is, different types of benchmarks, and tools for benchmarking in Elixir. An example is provided benchmarking tail call optimization by comparing recursive and iterative sum functions. The document ends by discussing parallelism benchmarks and noting that benchmarks may not represent real user performance.

![[EN] Ada Lovelace Day 2014 - Tampon run](https://cdn.slidesharecdn.com/ss_thumbnails/adalovelaceday2014-tamponrun-141013165702-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)












![JFugue, Music, and the Future of Java [JavaOne 2016, CON1851]](https://cdn.slidesharecdn.com/ss_thumbnails/con1851jfuguev2-160921161450-thumbnail.jpg?width=640&height=640&fit=bounds)