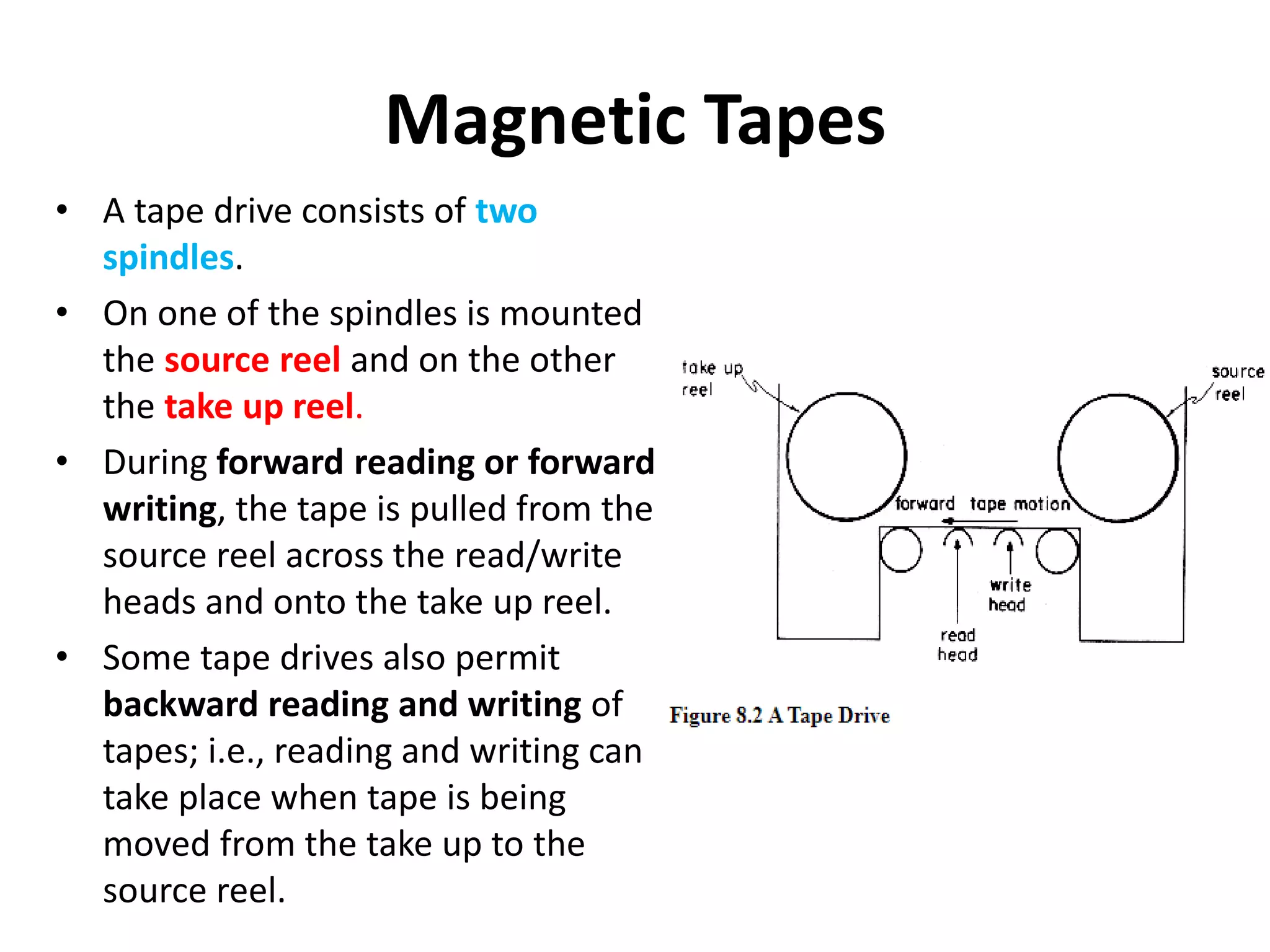
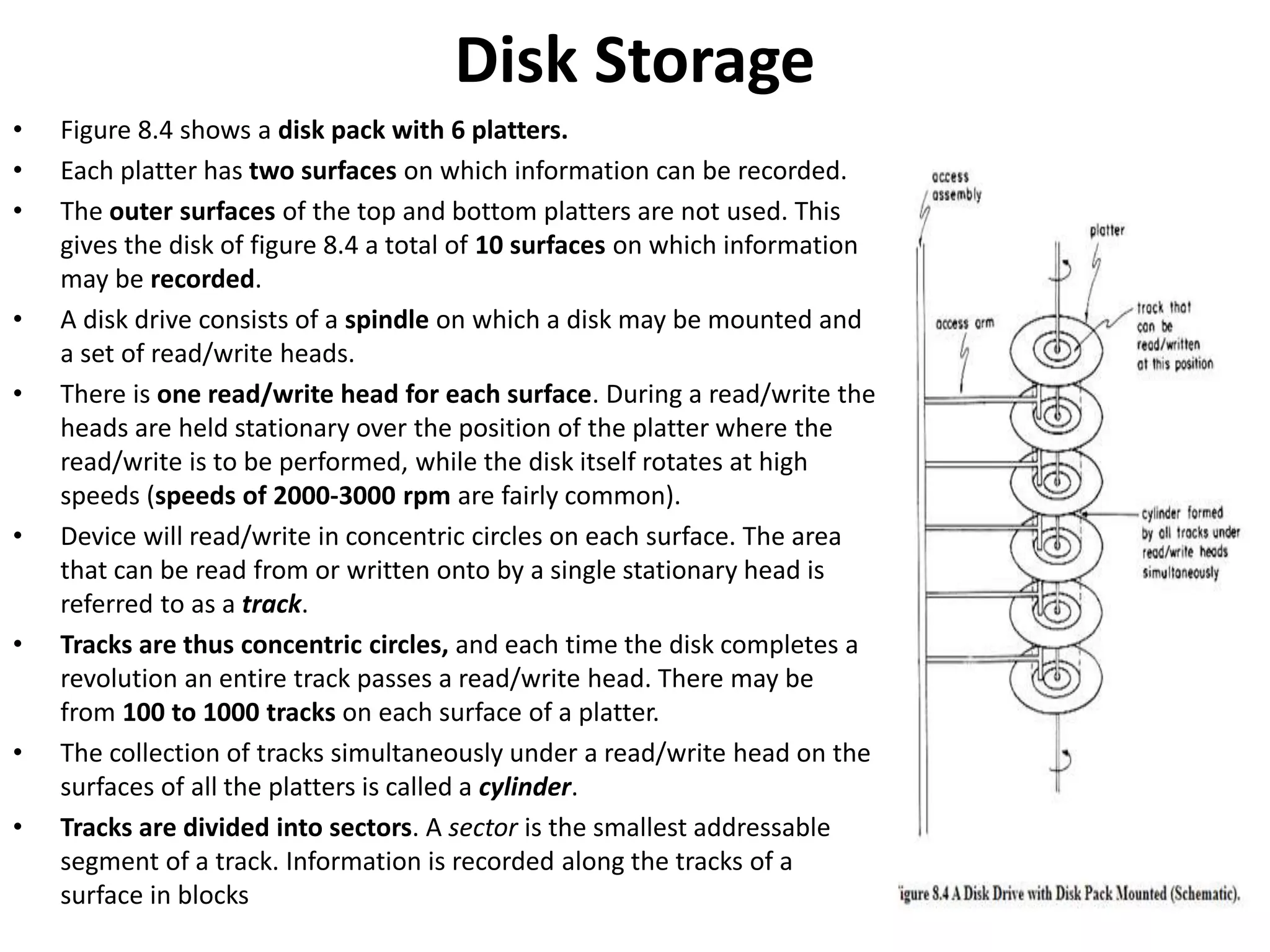
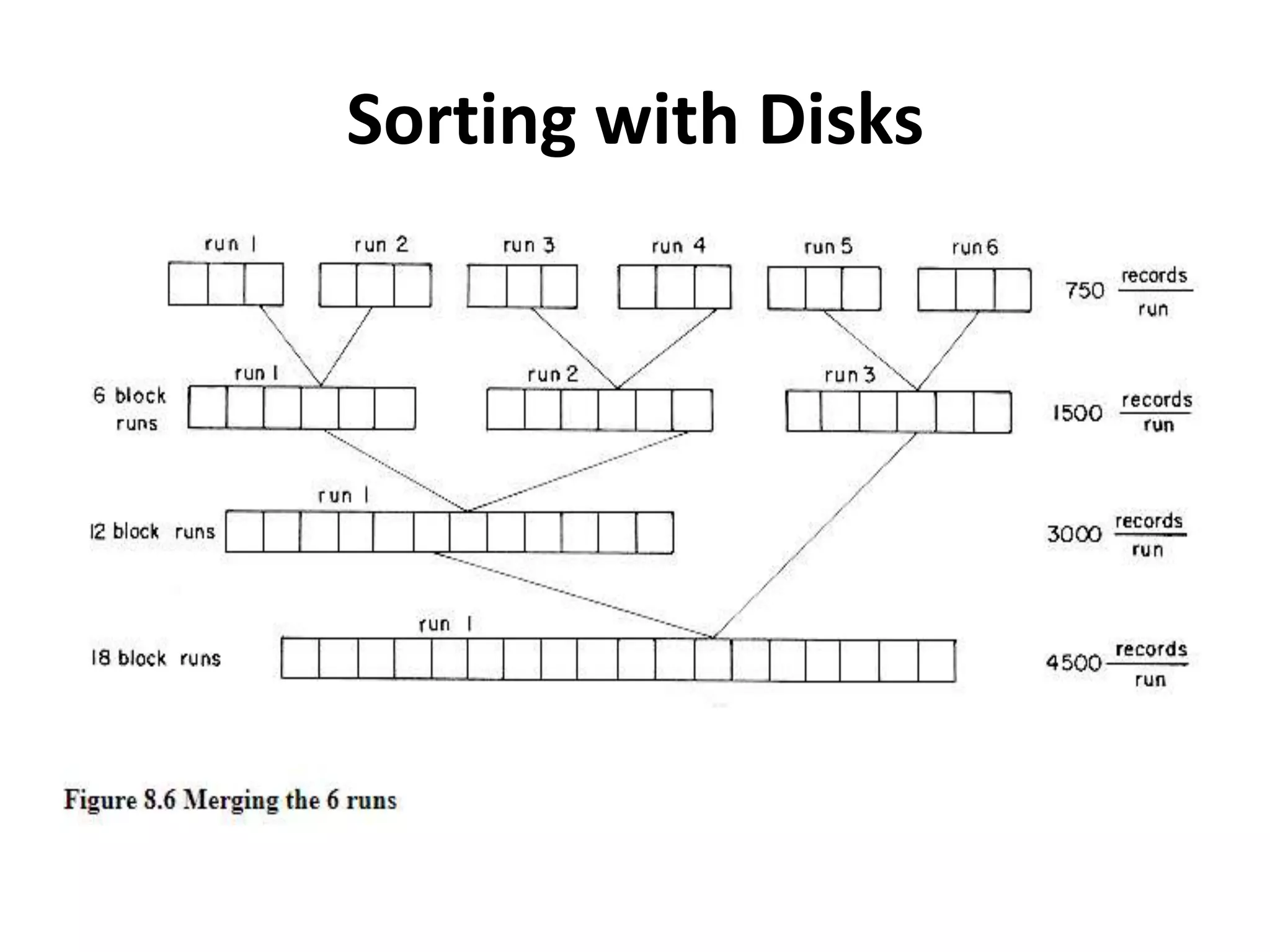
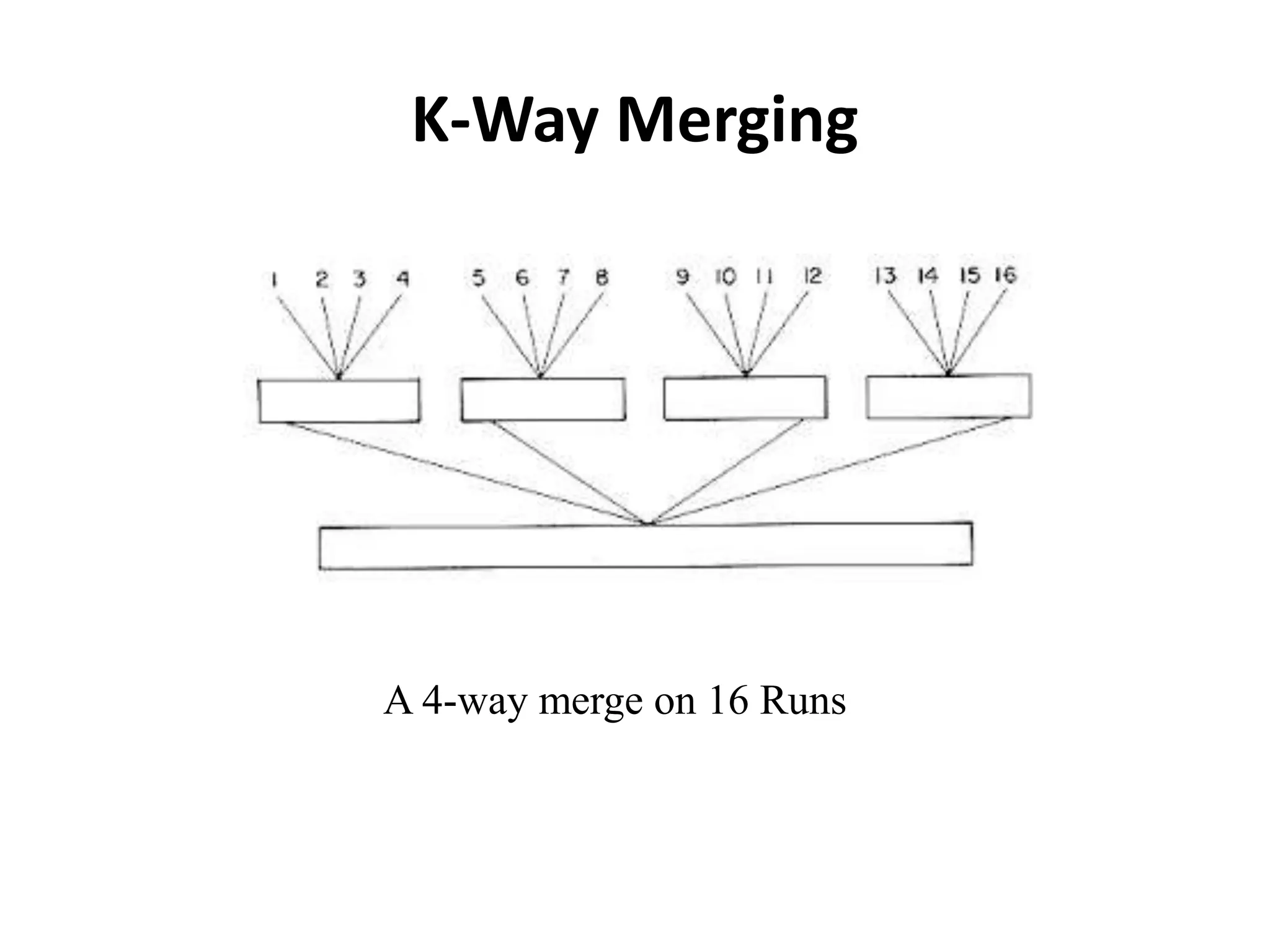
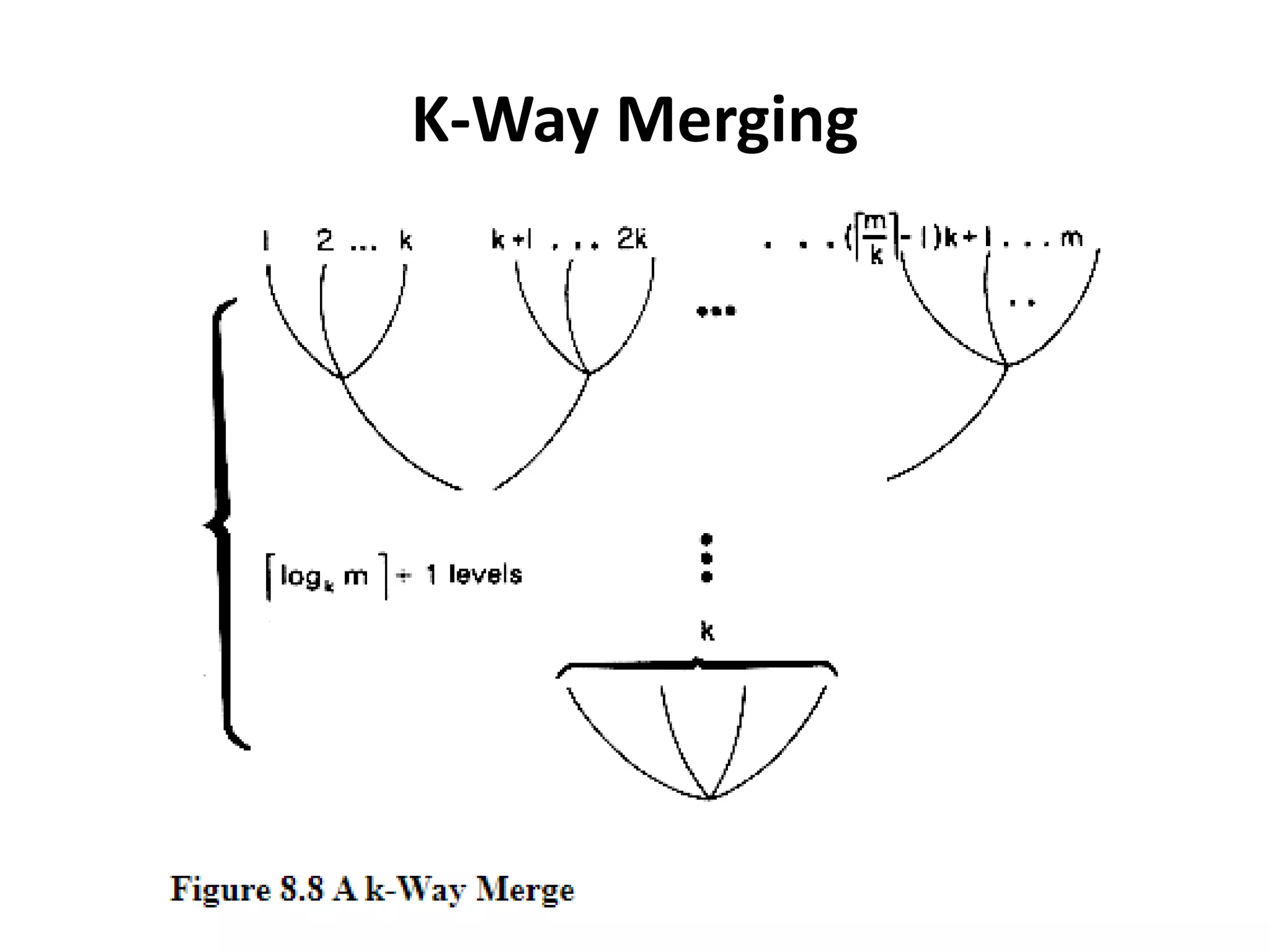
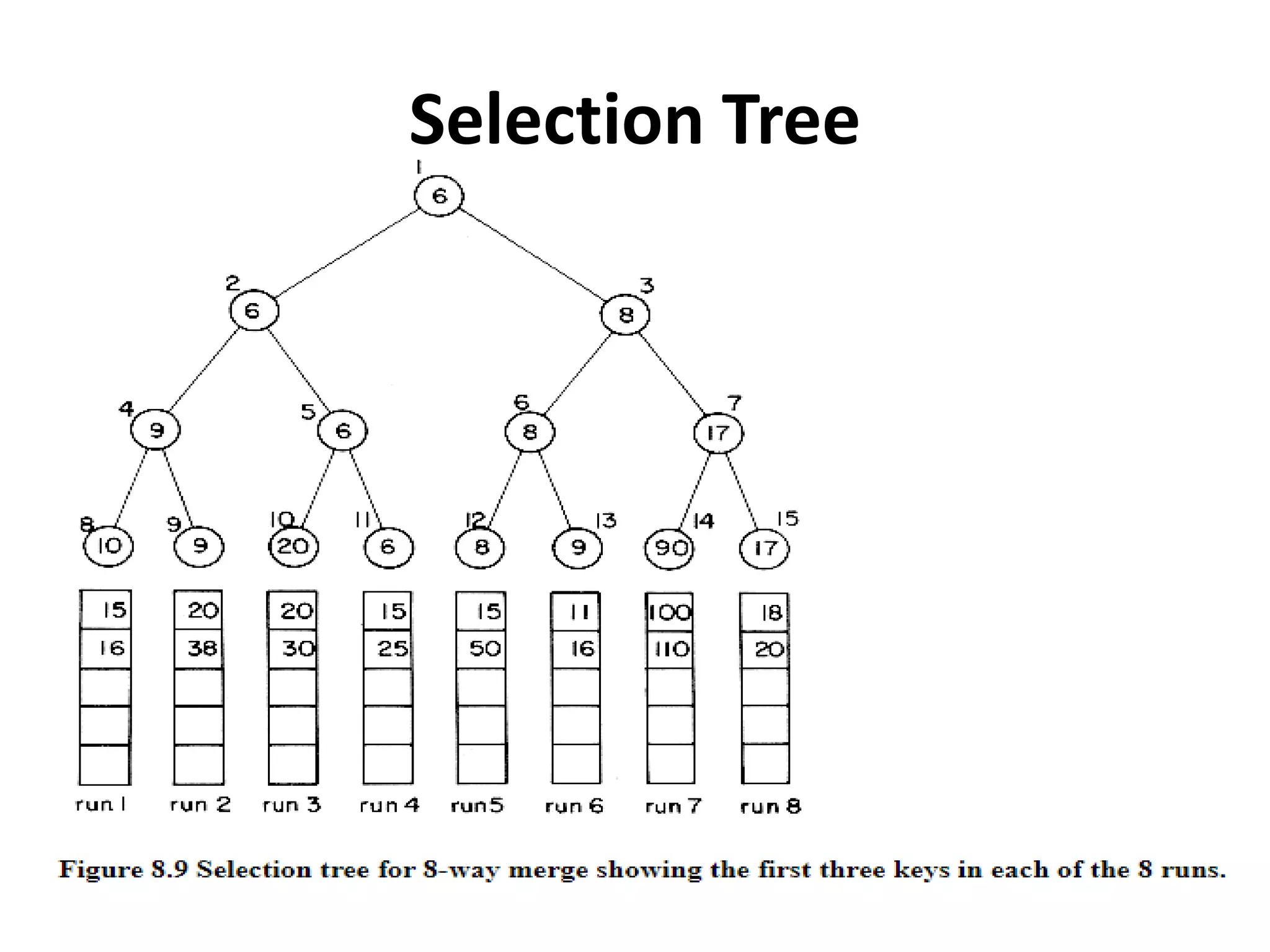
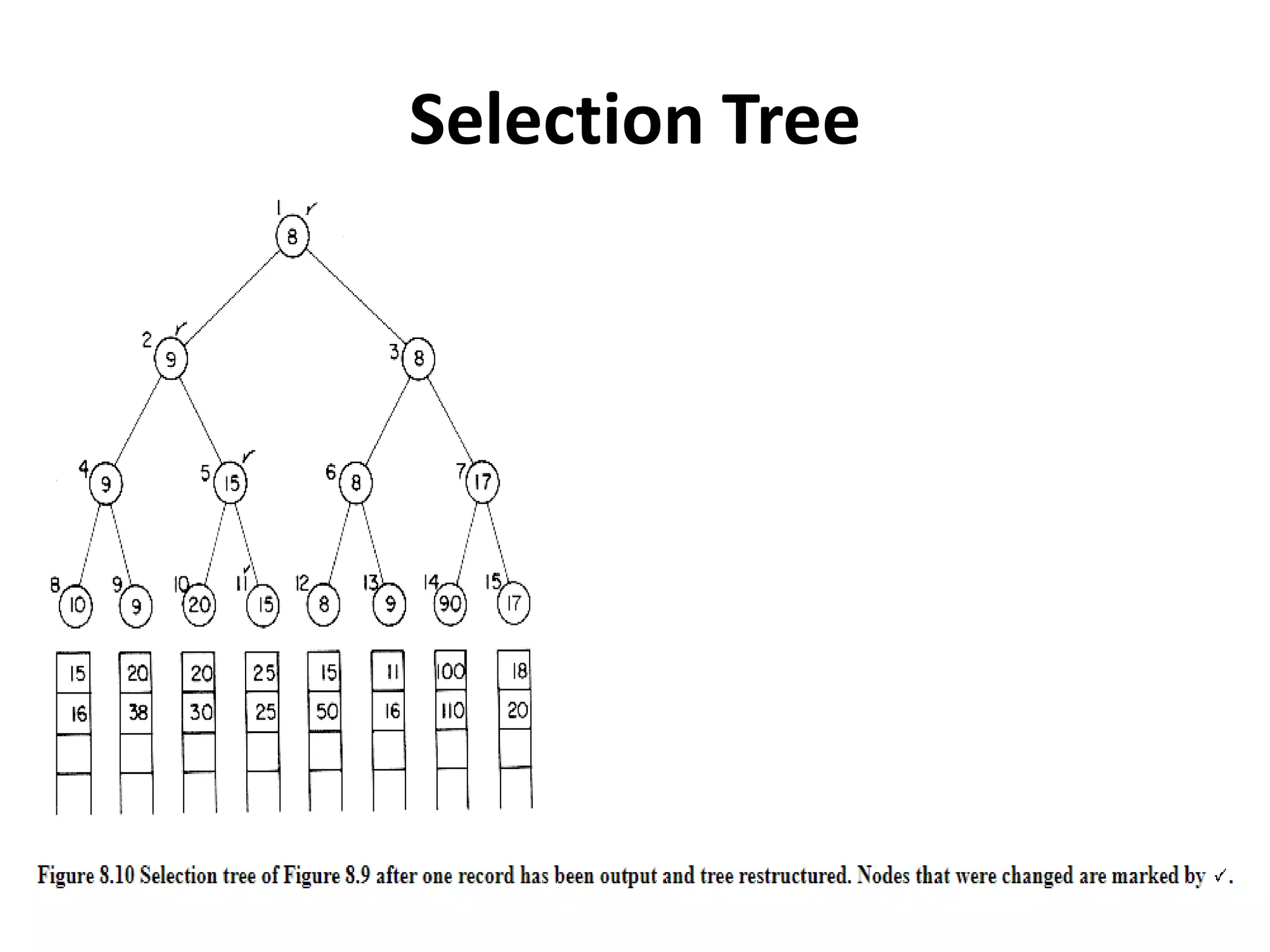
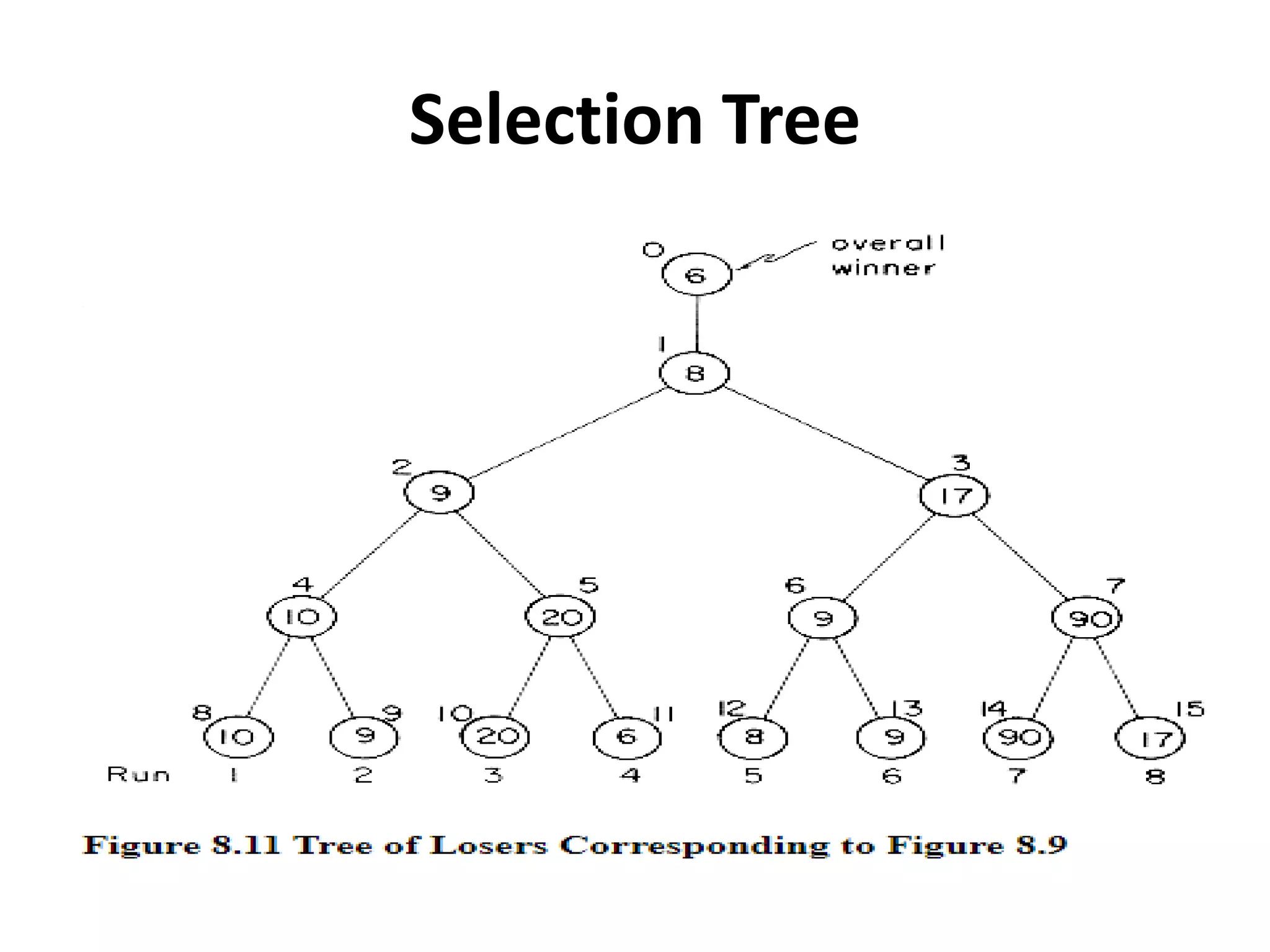
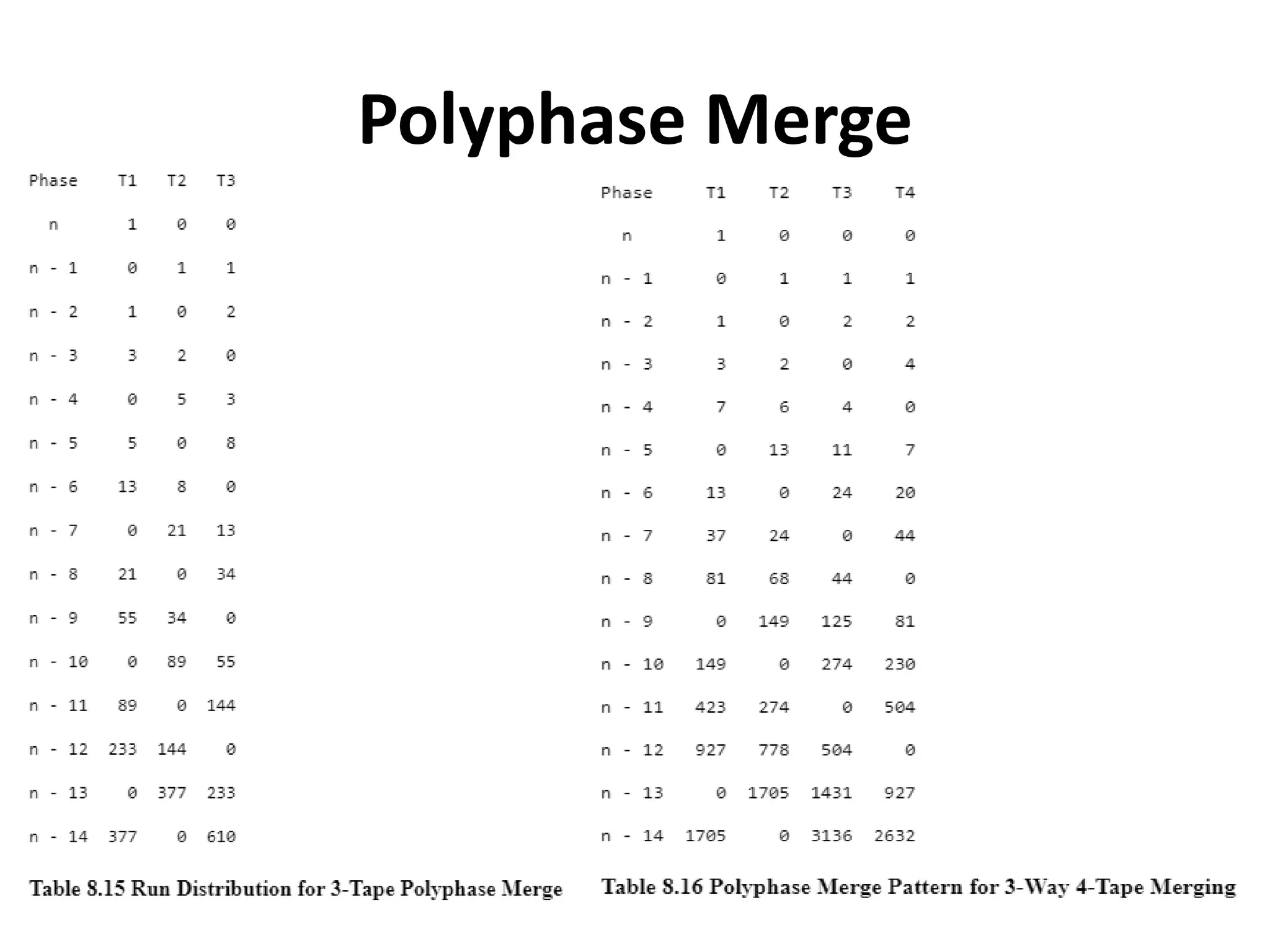
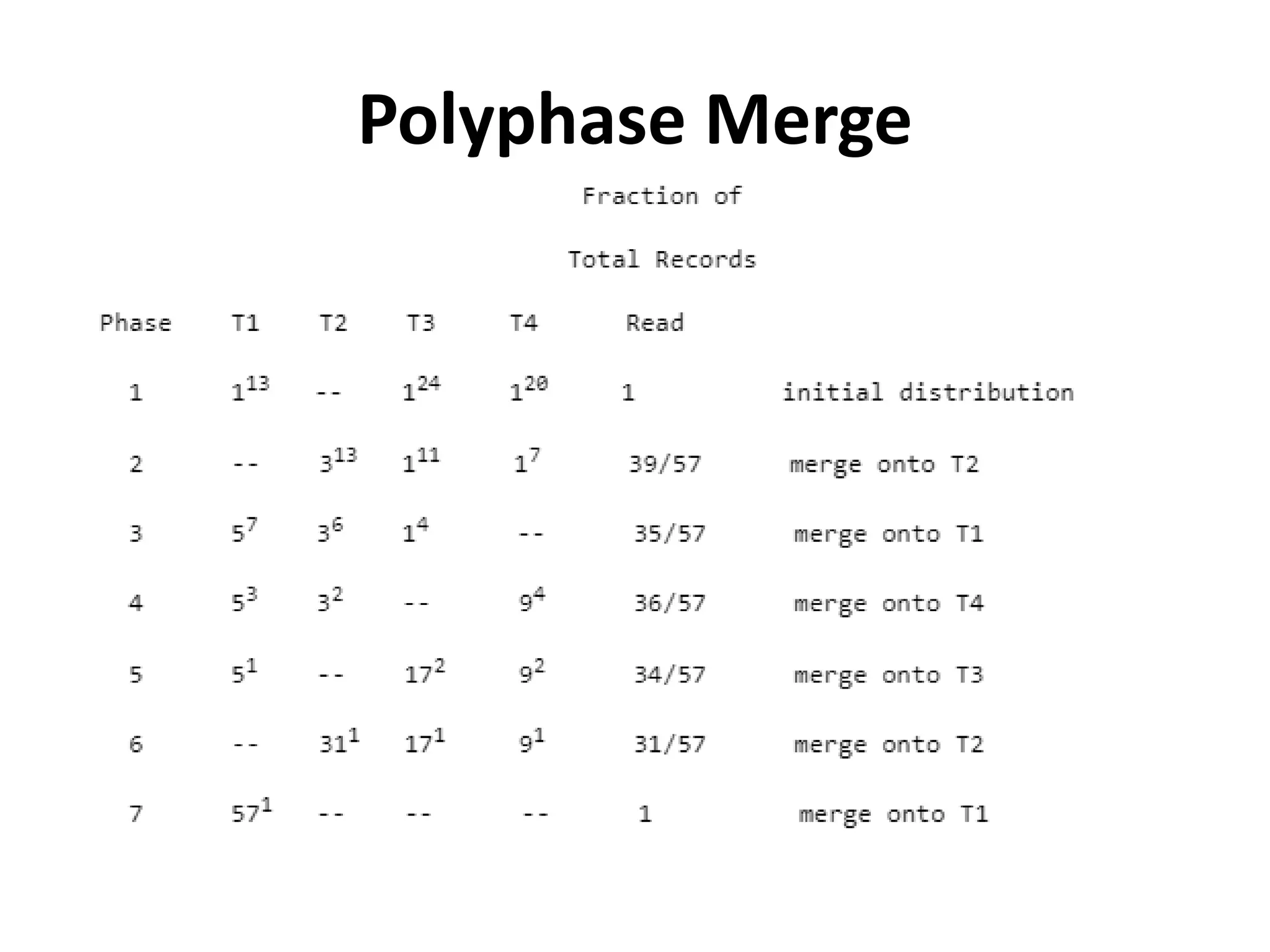
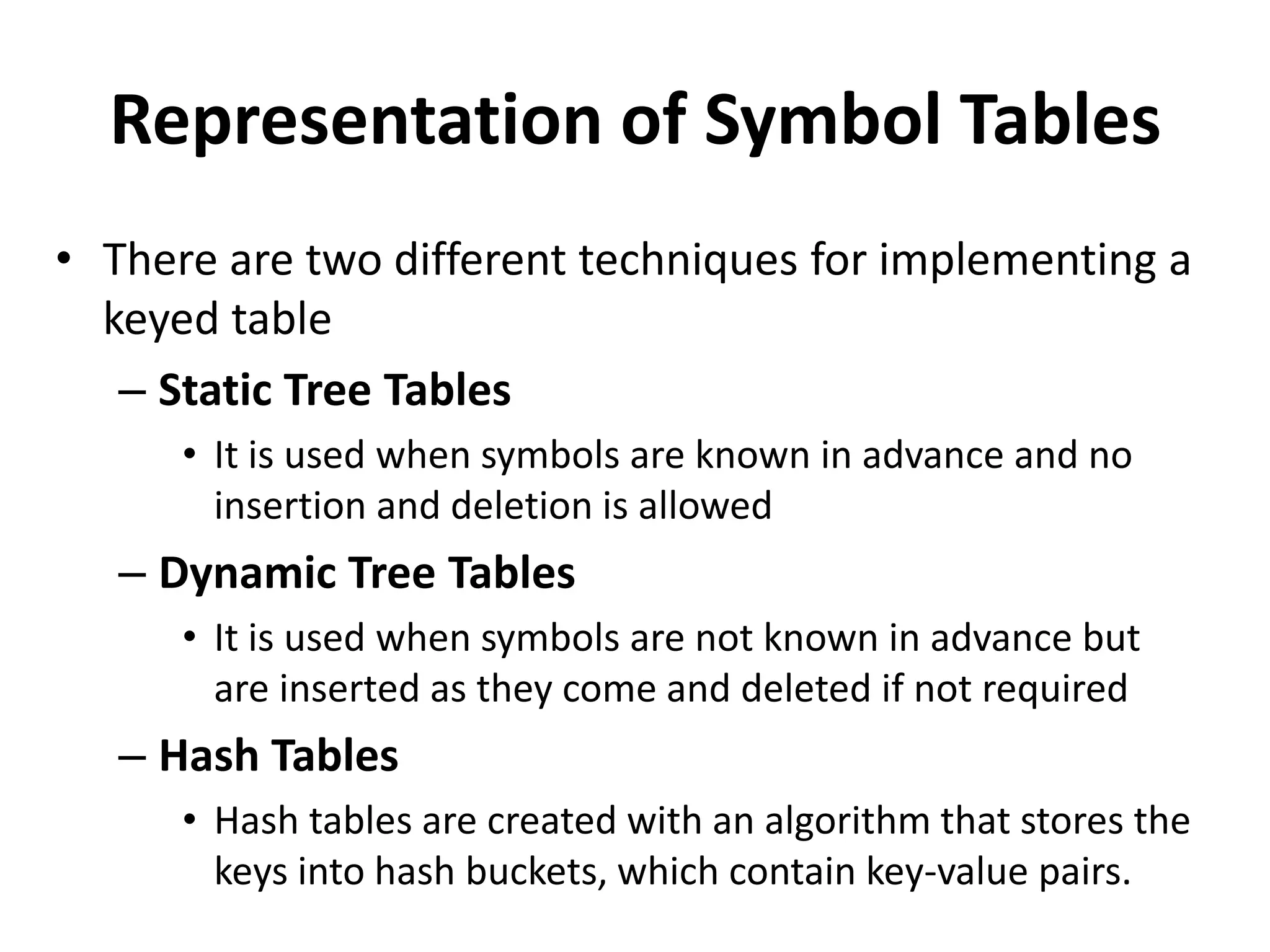
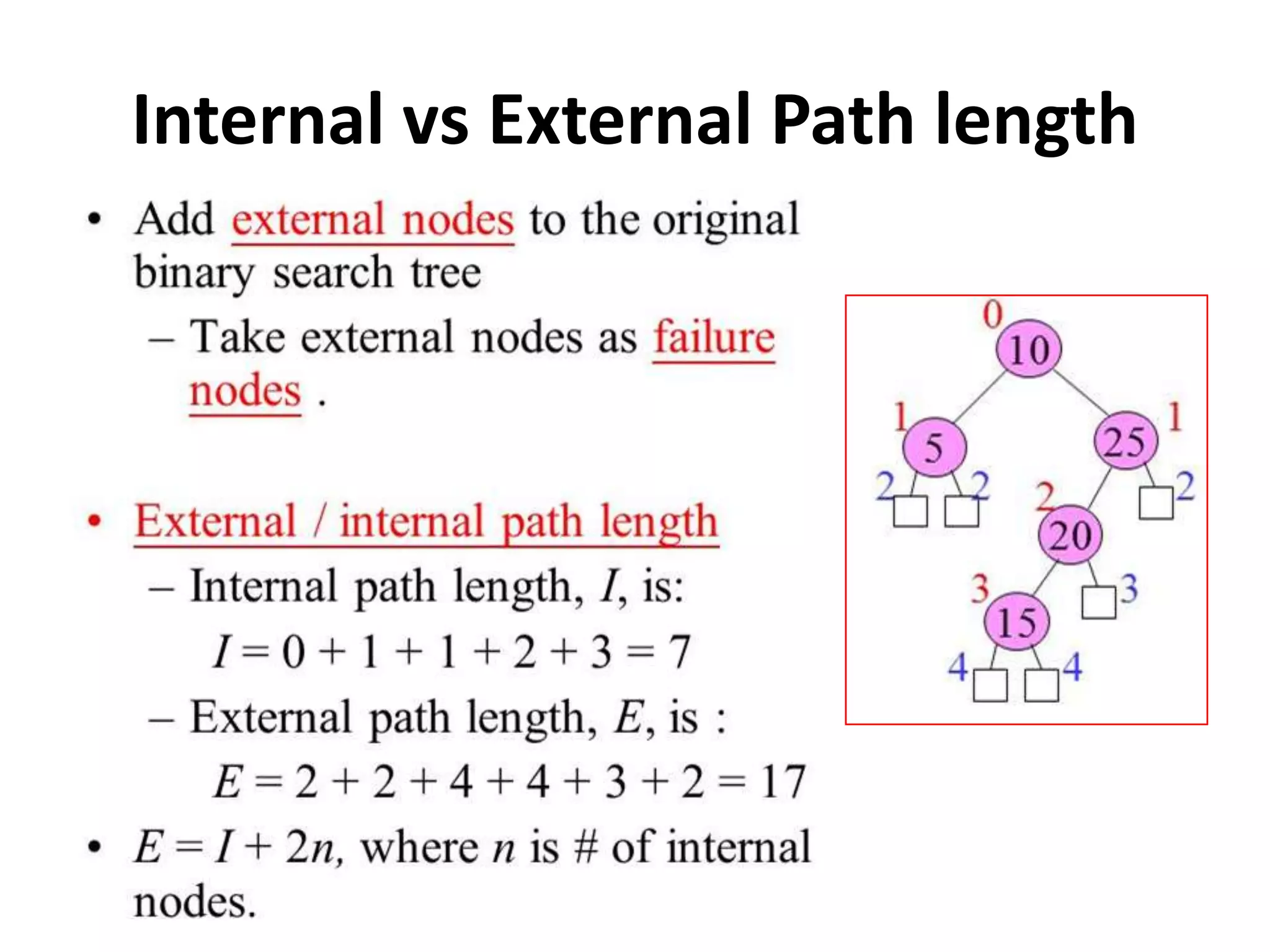
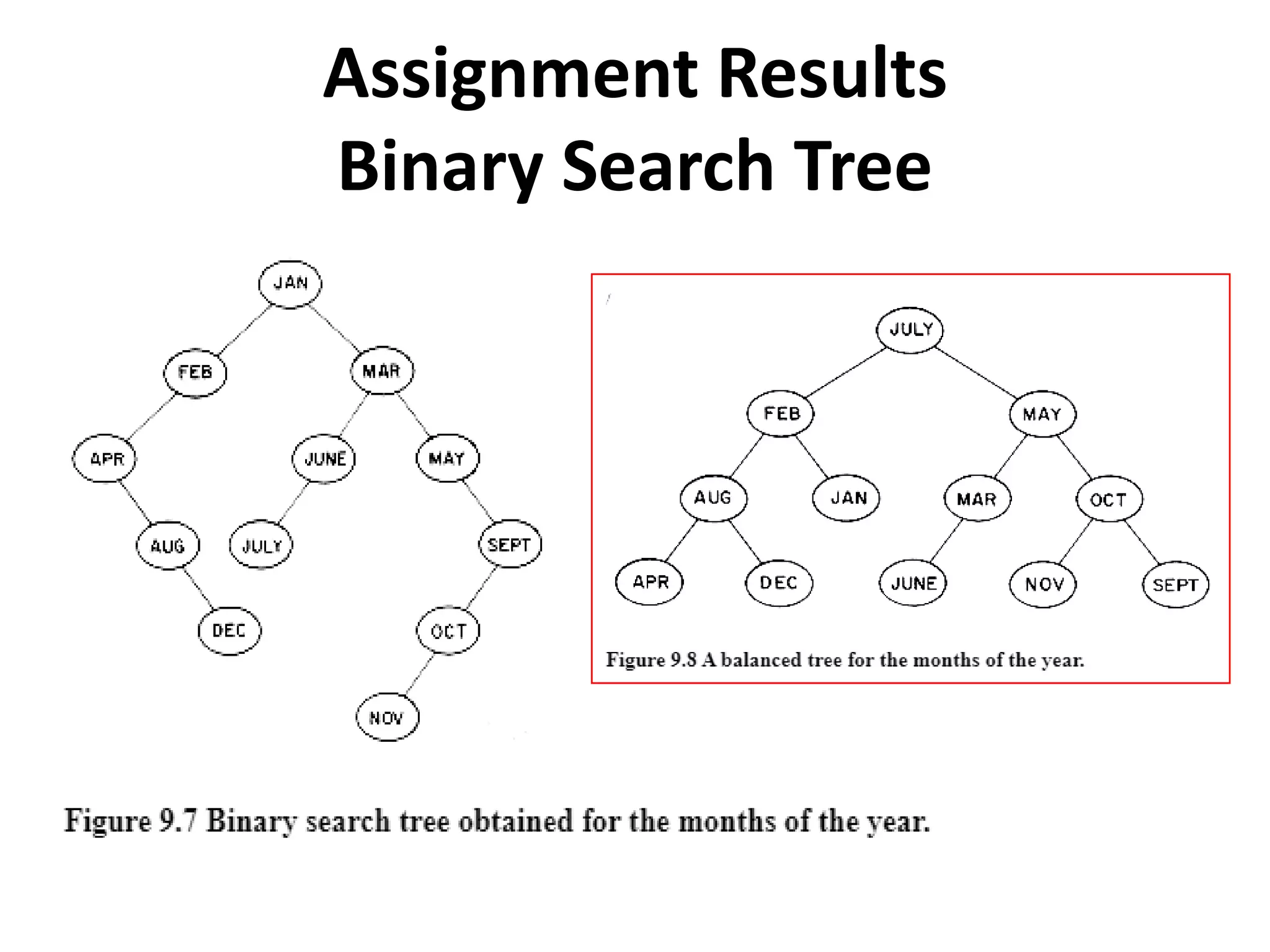
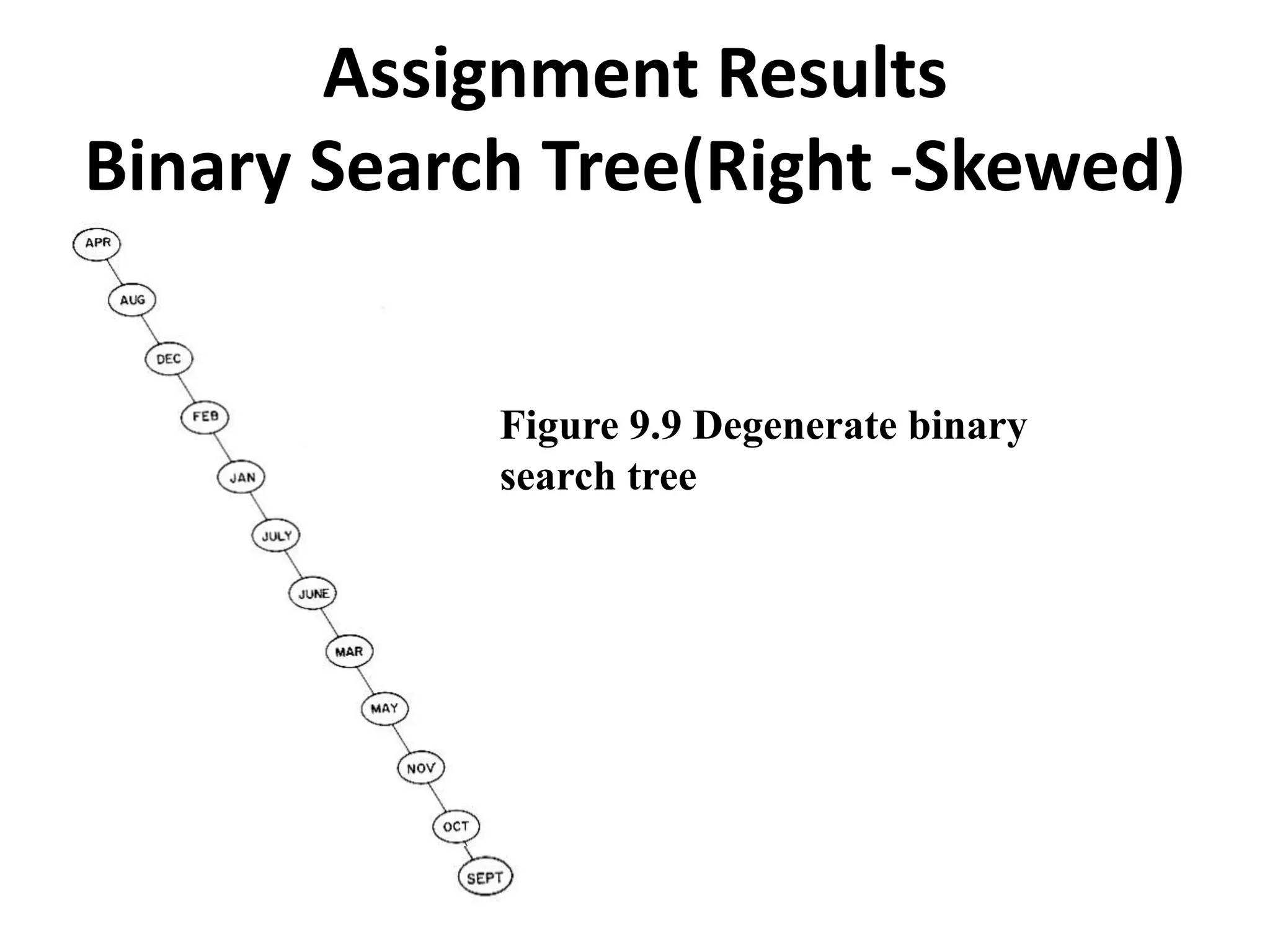
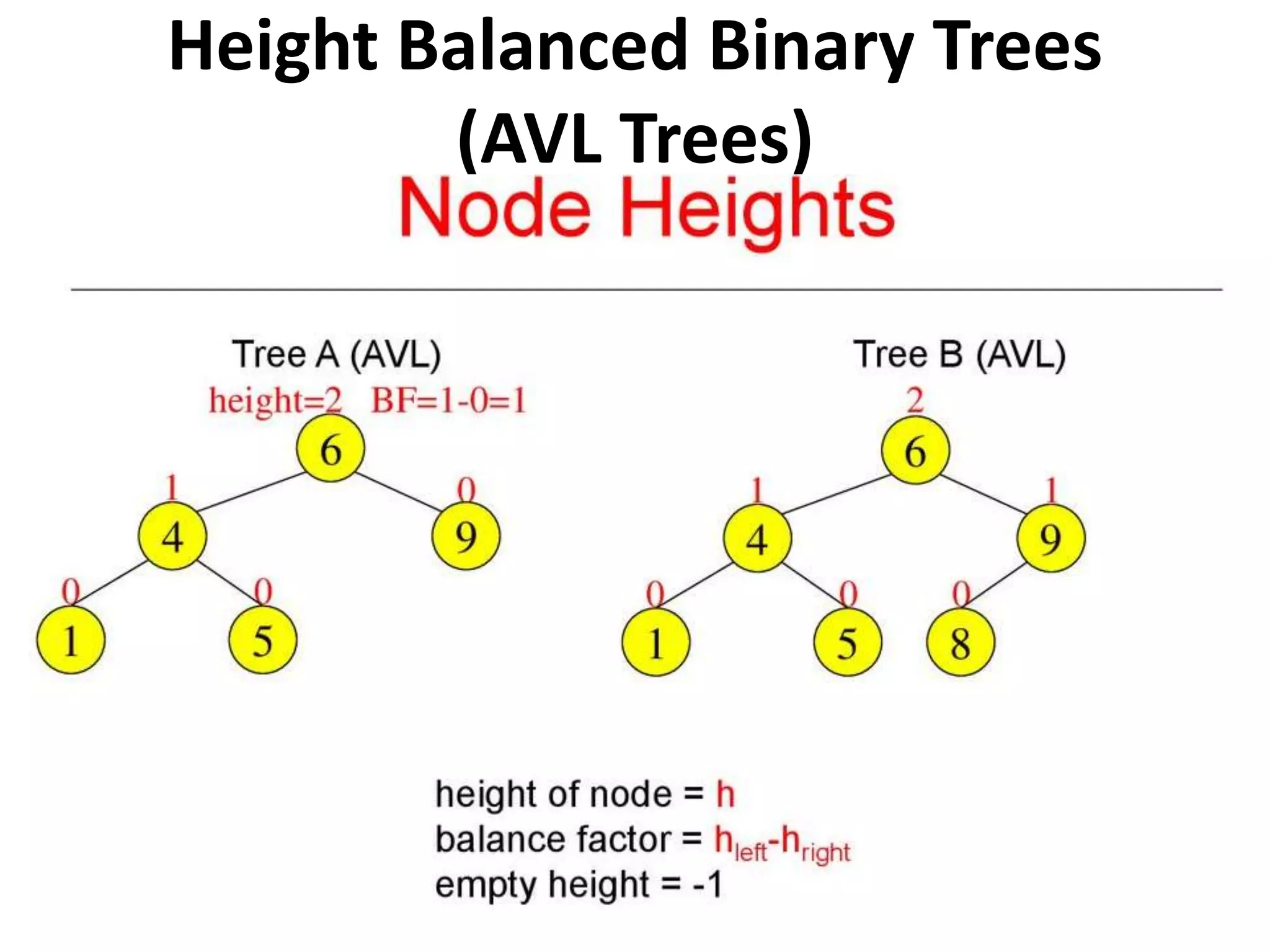
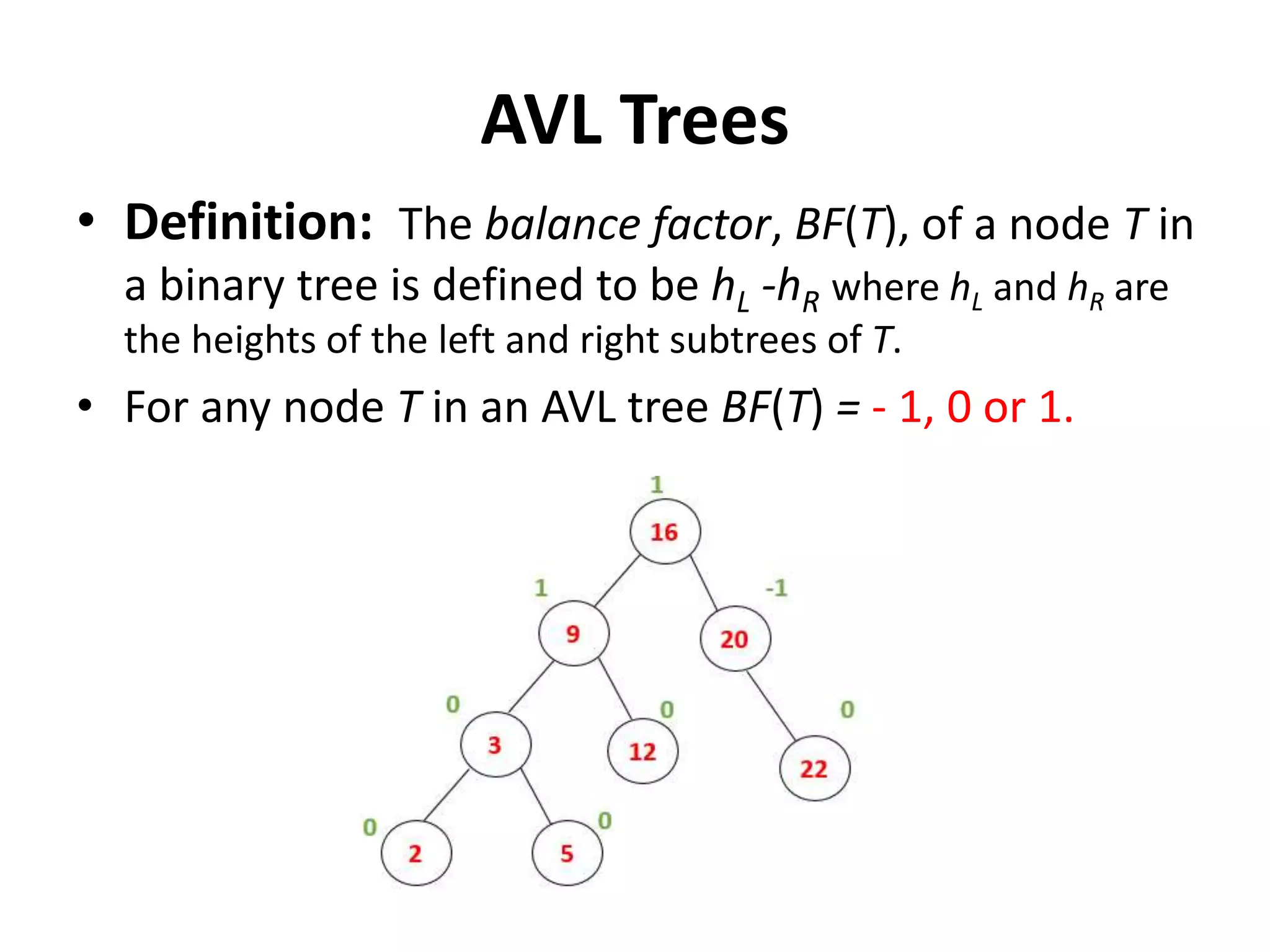
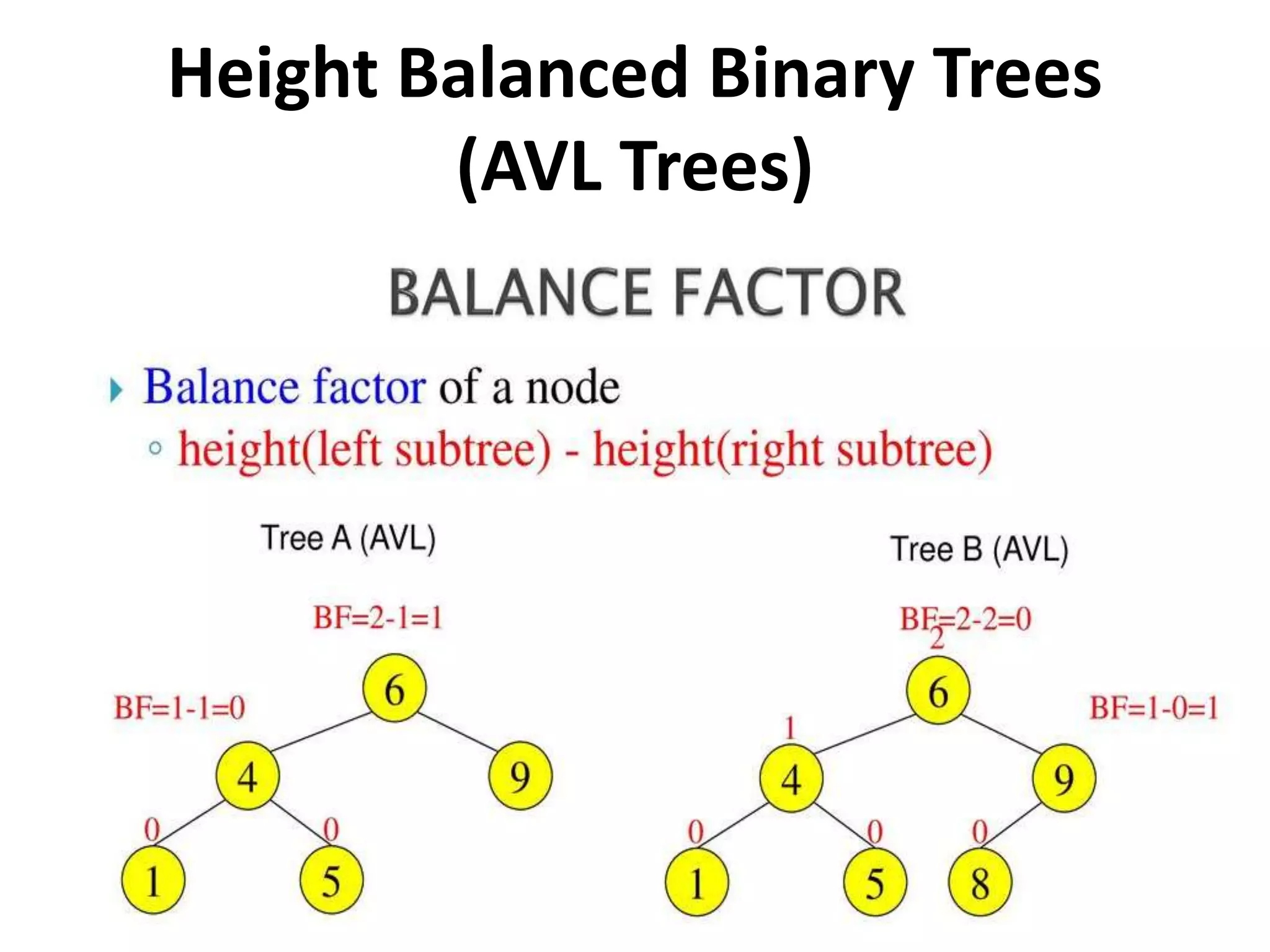
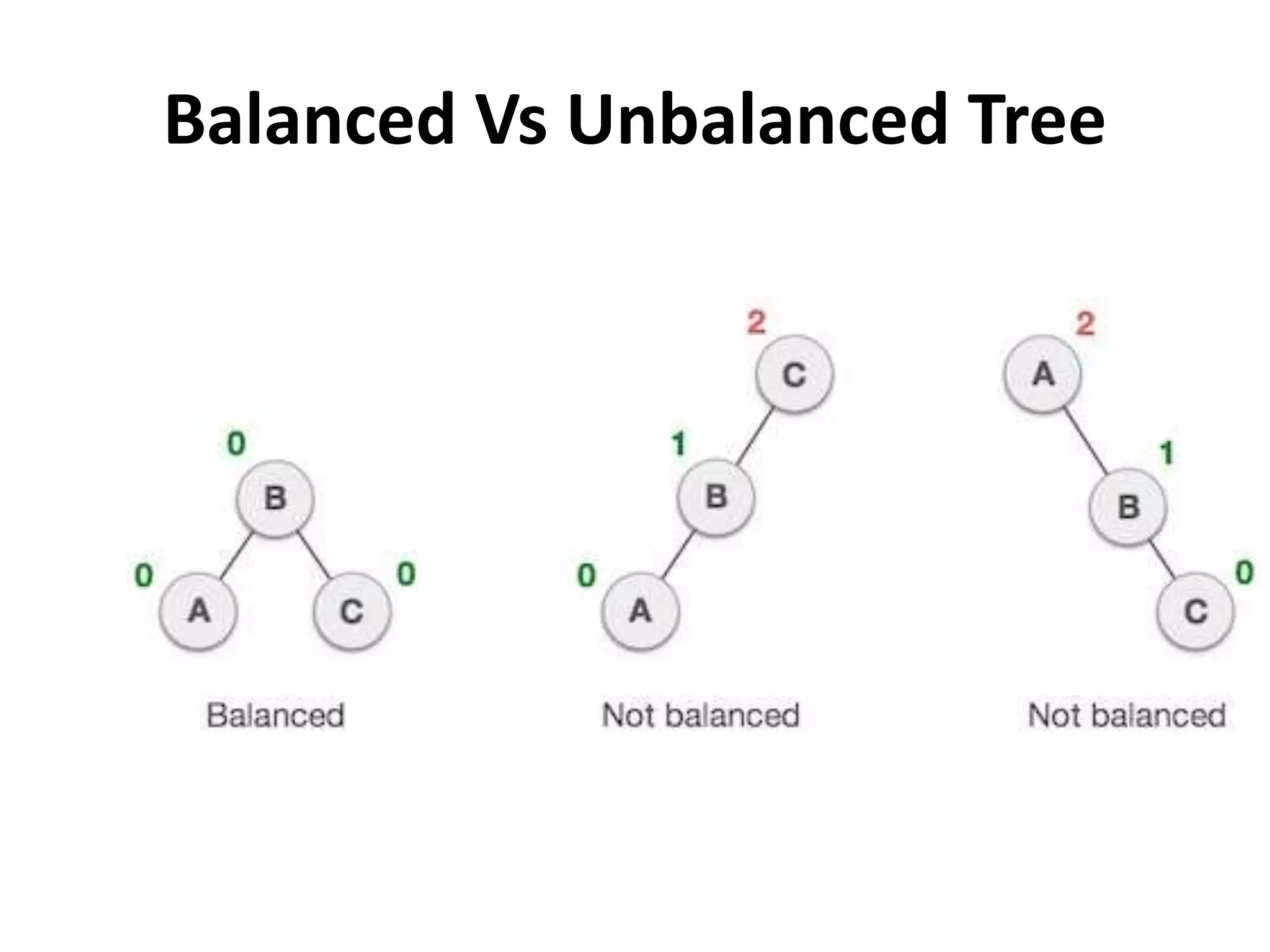
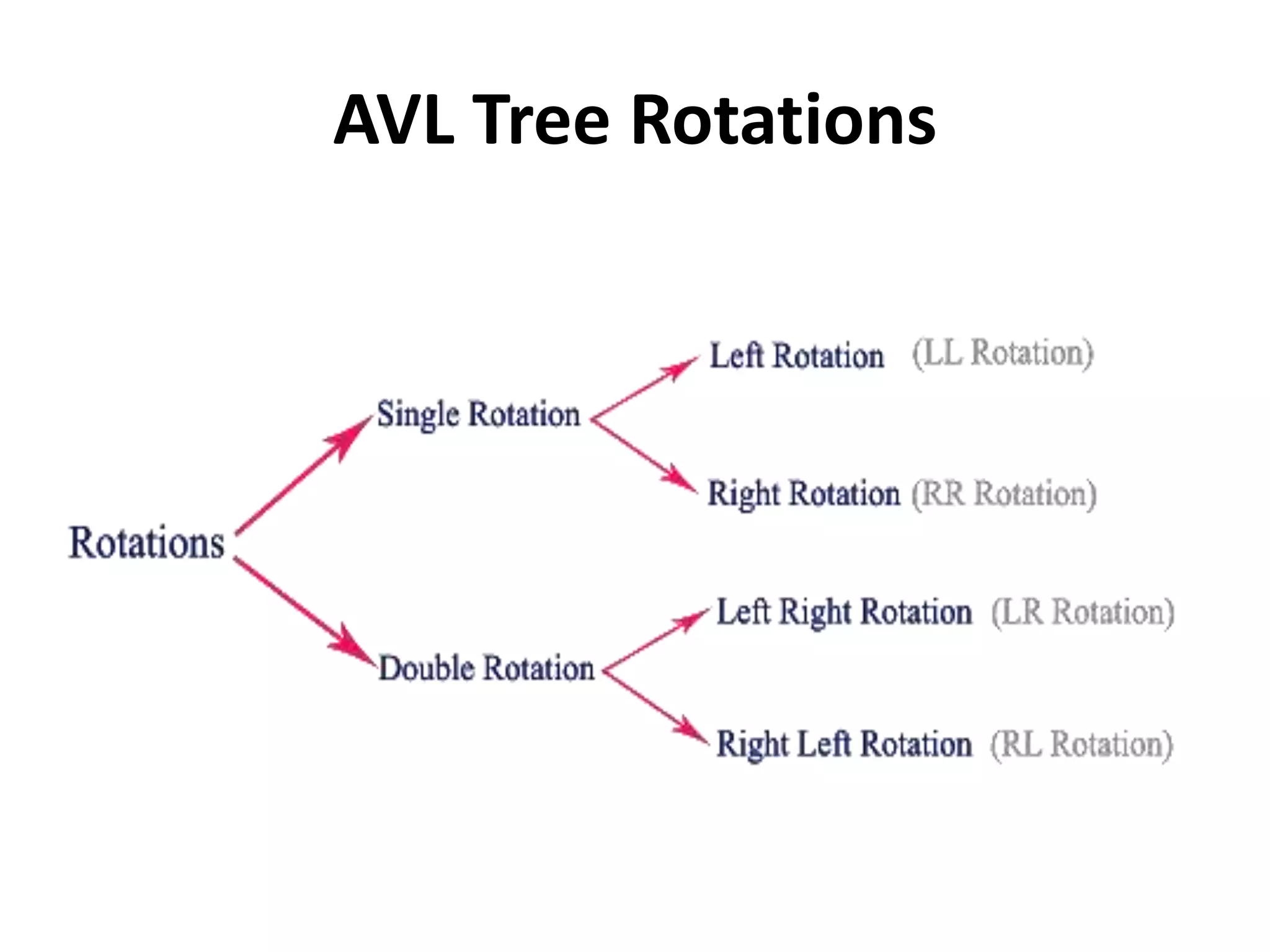
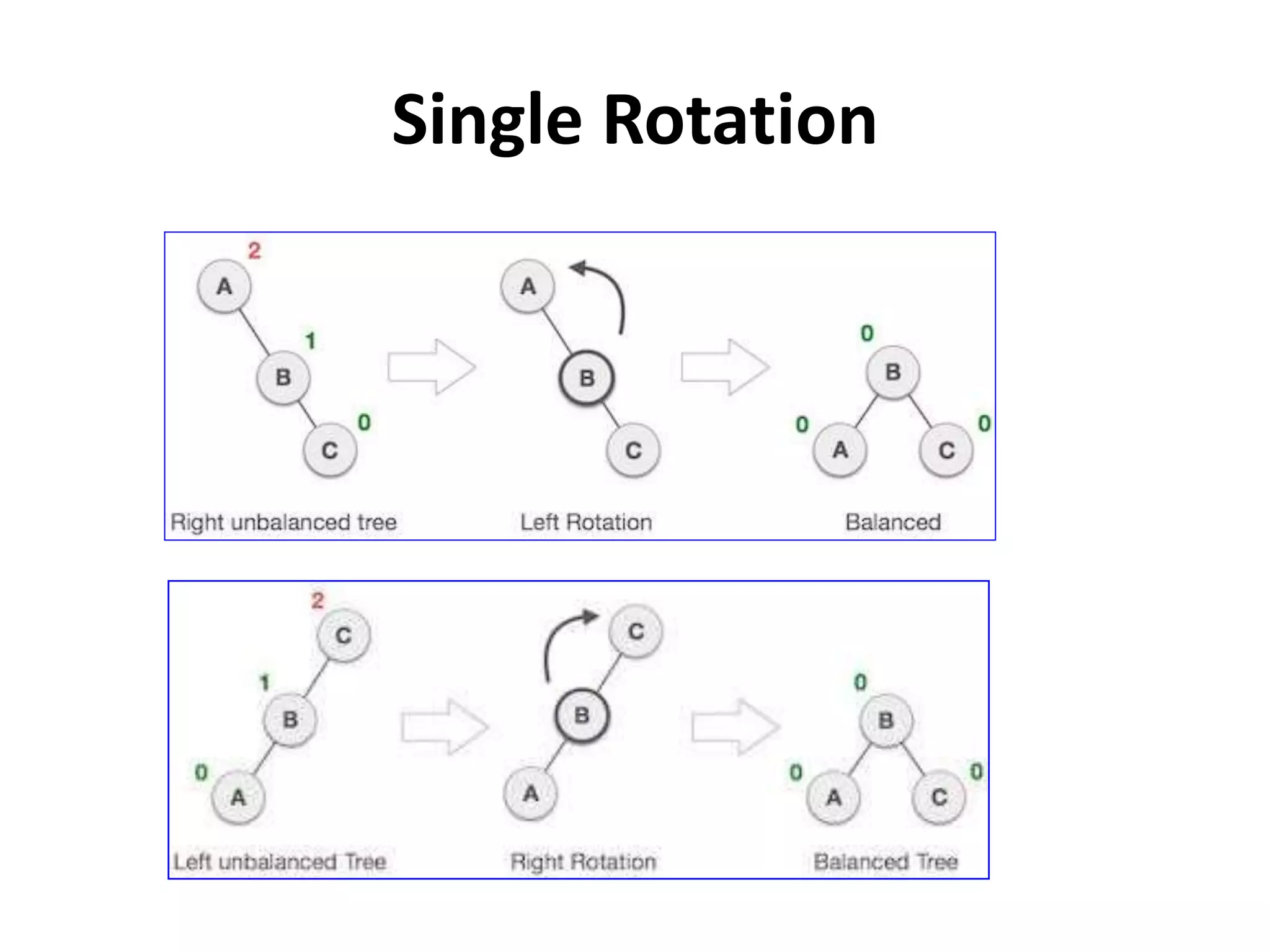
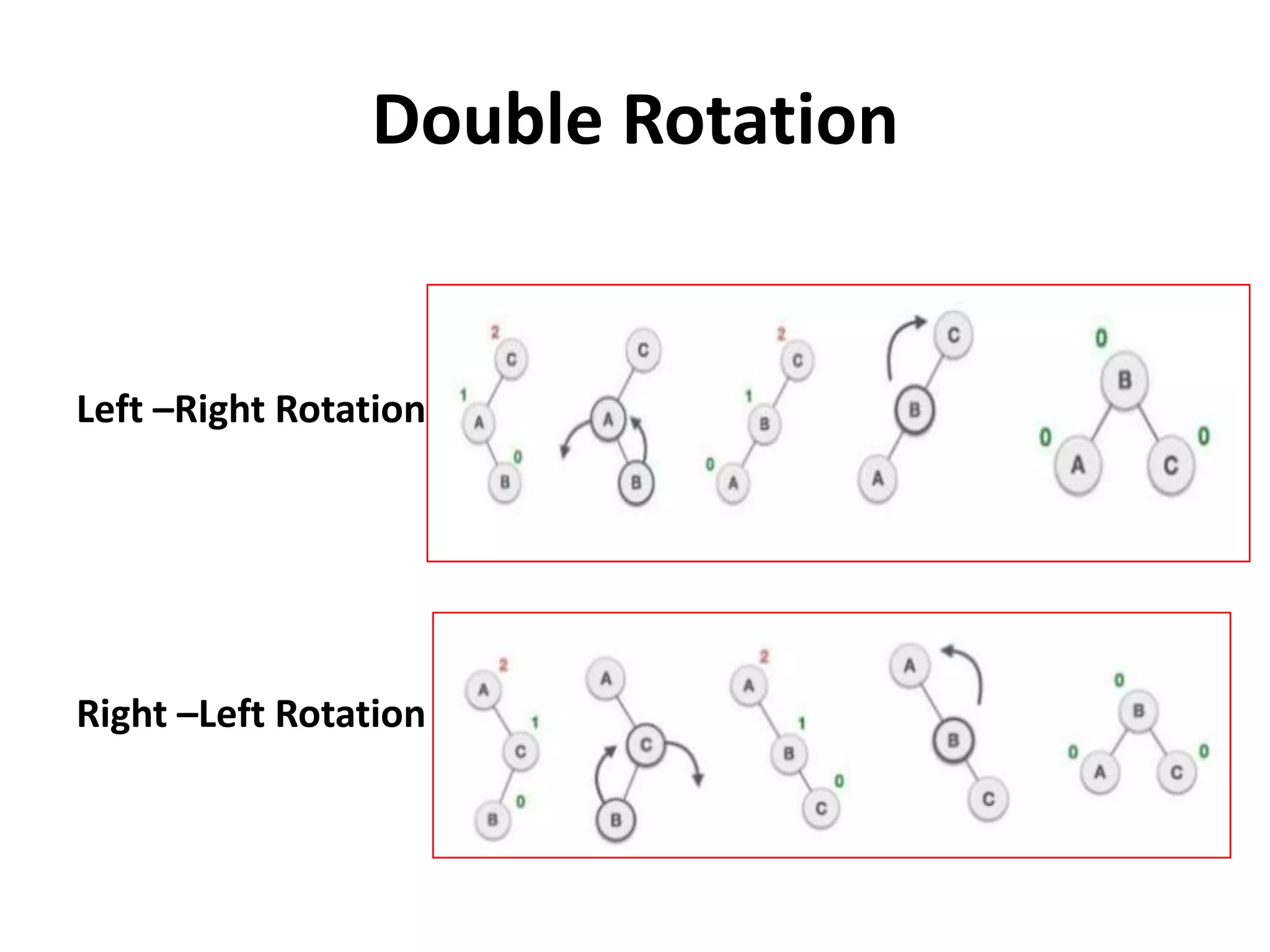
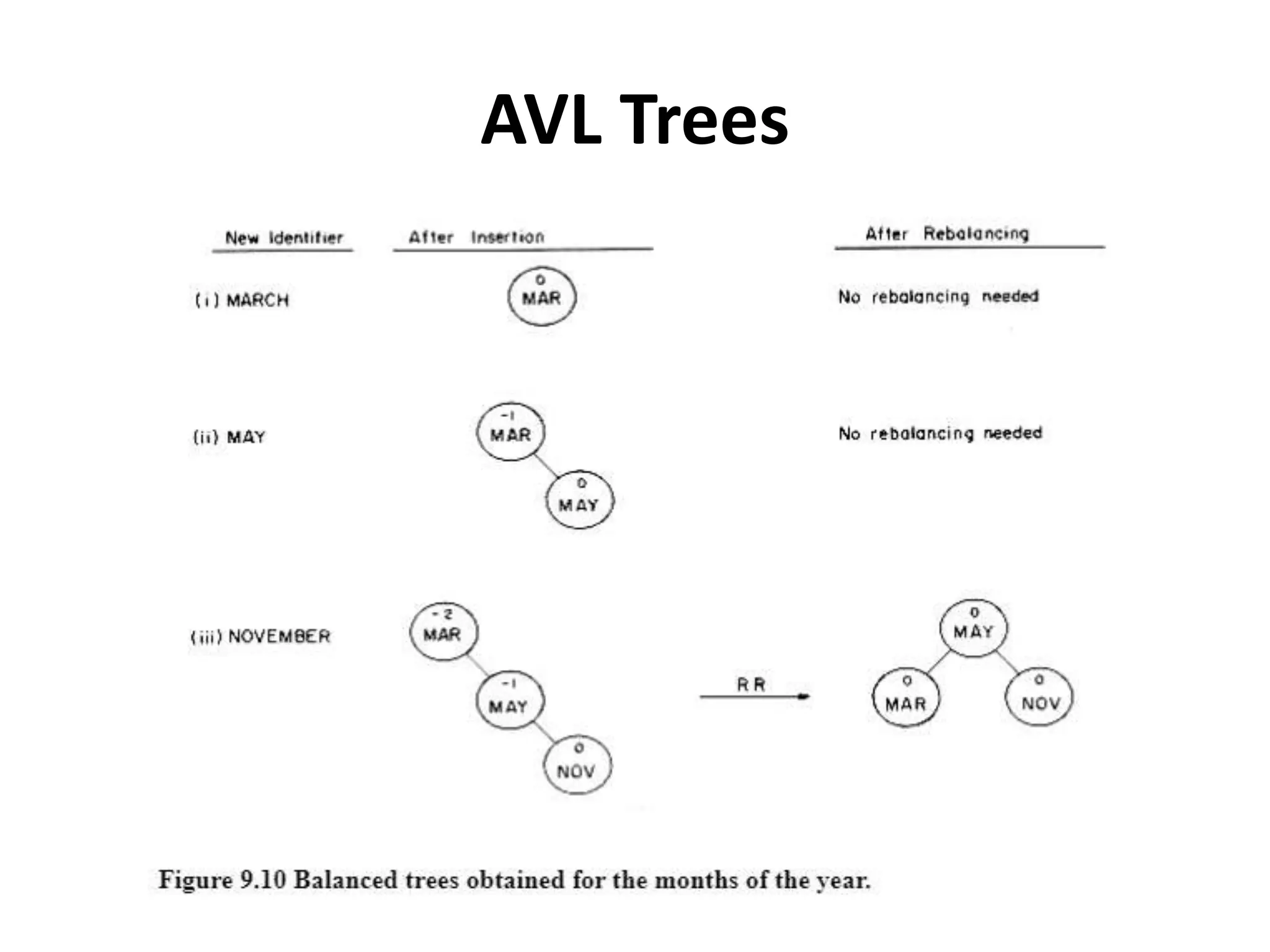
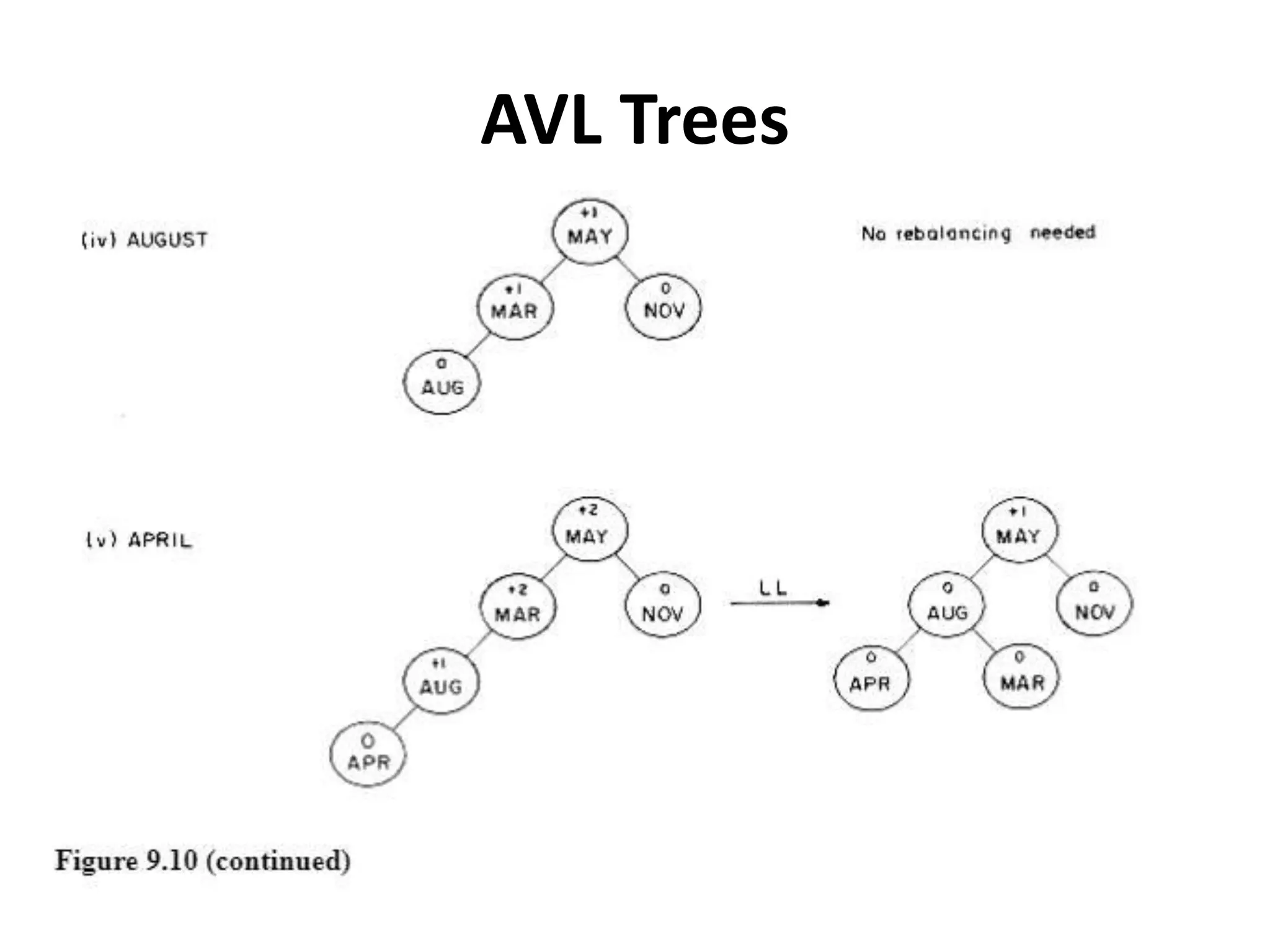
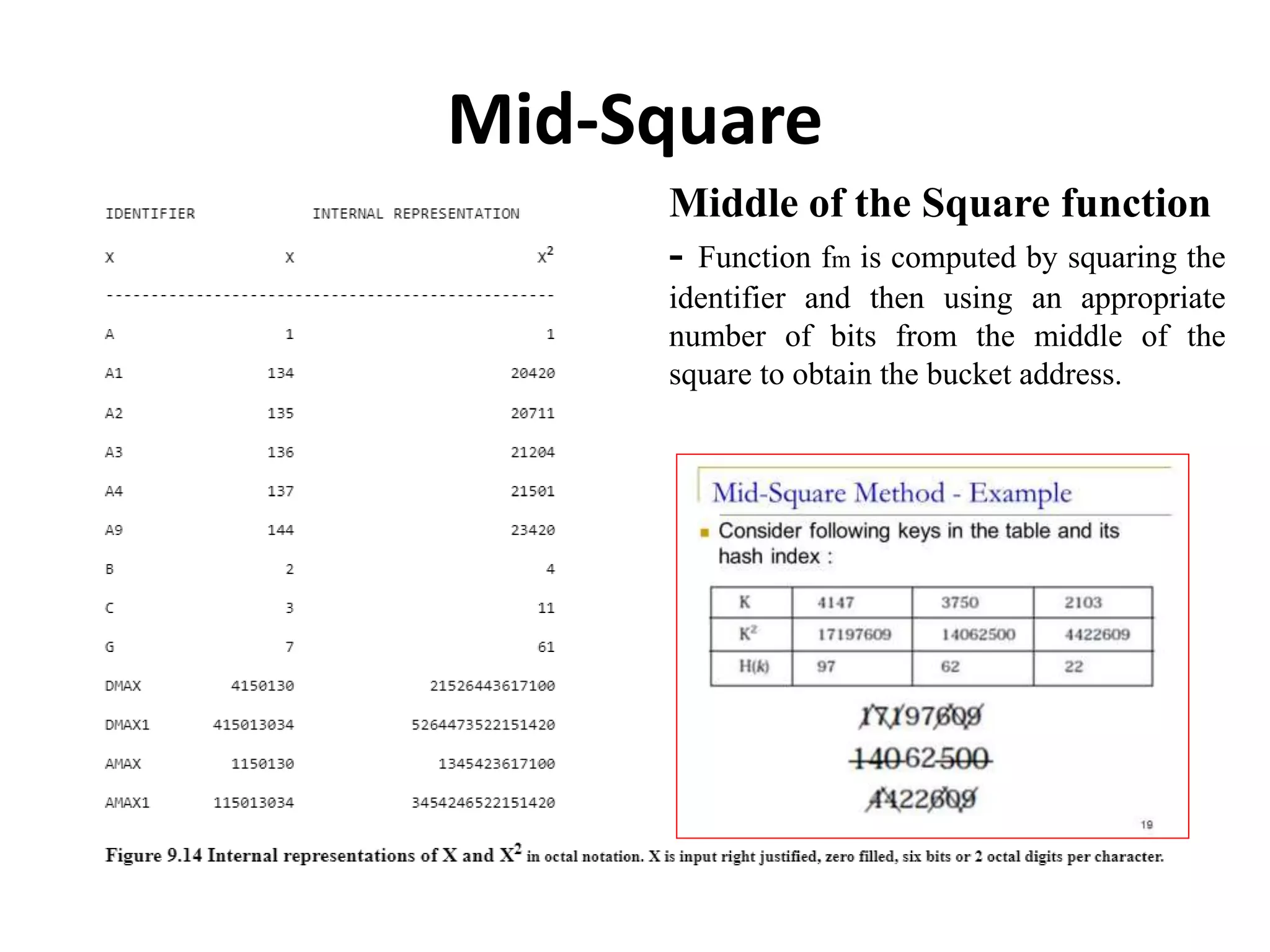
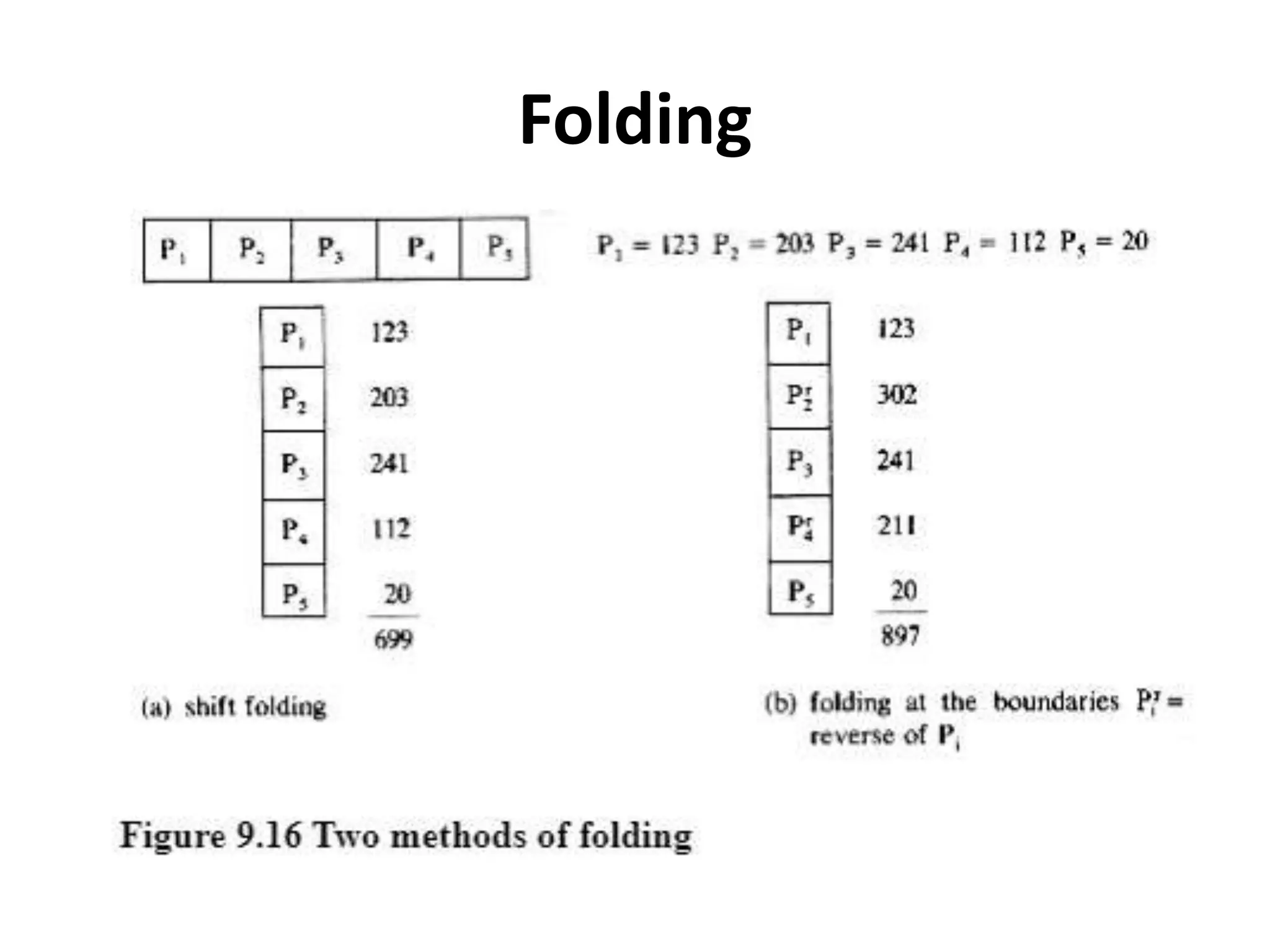
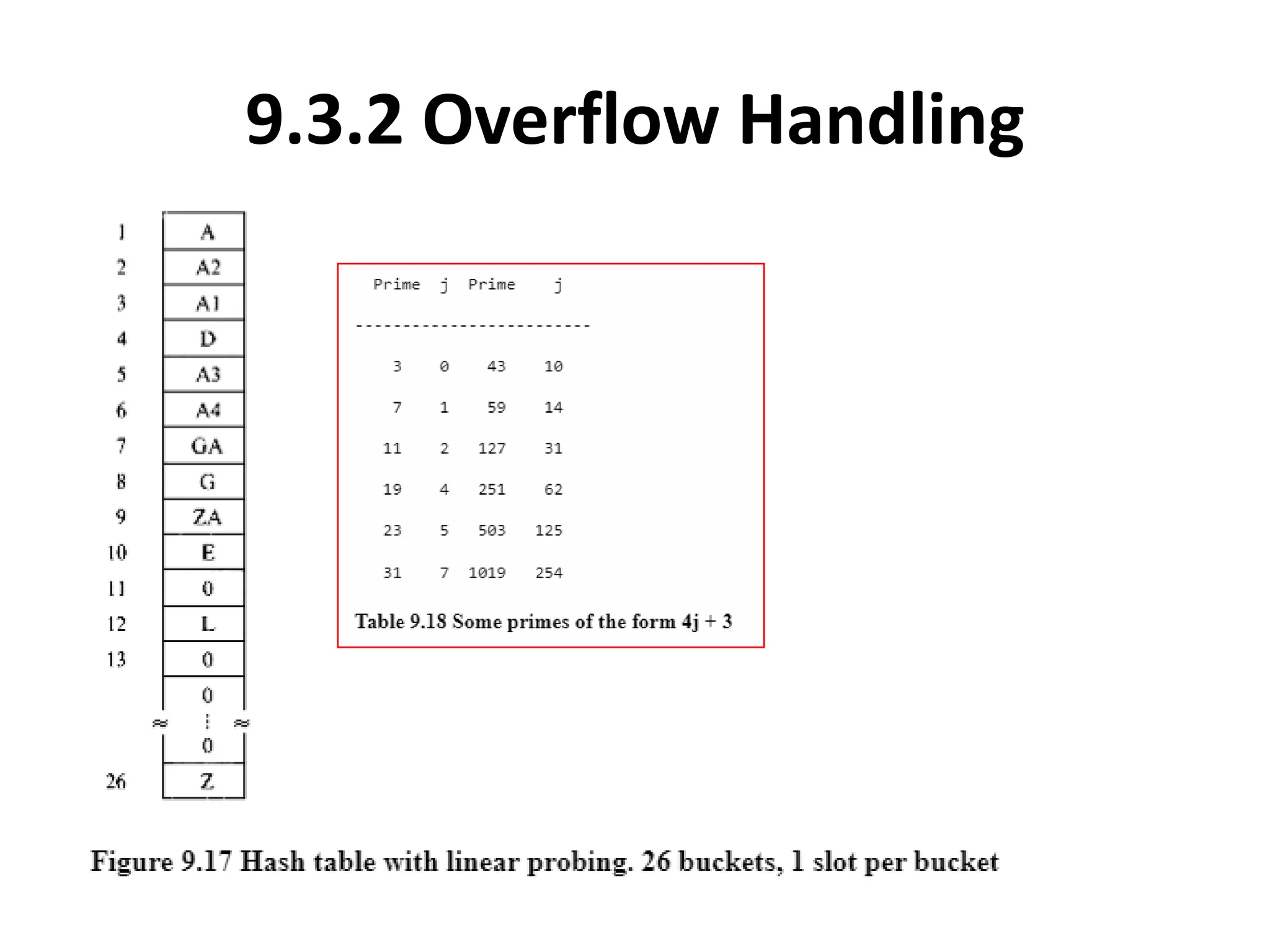
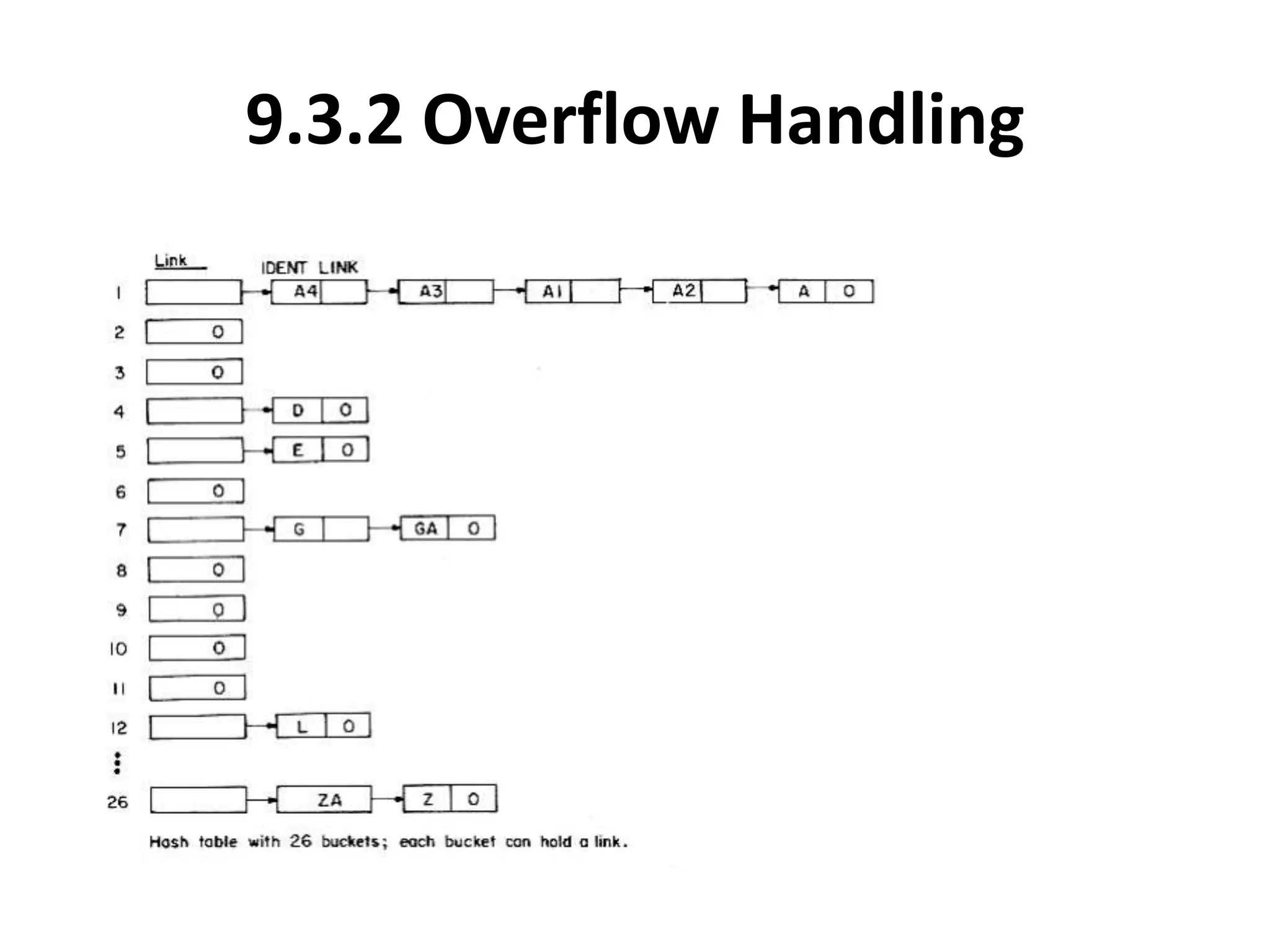
This document discusses external sorting methods and symbol tables, detailing the technical aspects of magnetic tape and disk storage systems, as well as common algorithms for sorting including merge sort. It covers the physical characteristics of storage devices, the operational principles of reading and writing data, and the efficiency of different sorting techniques. Additionally, it explains symbol table operations and various data structures for managing symbols, including binary and hash tables.