Download to read offline


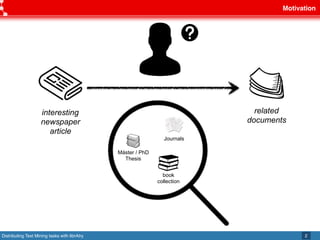

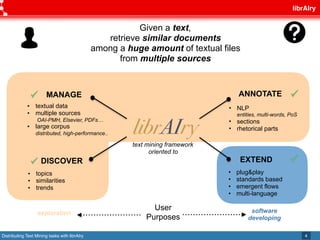
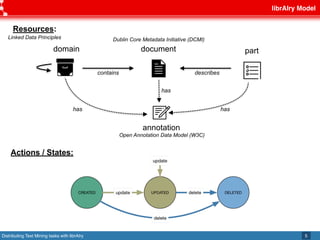
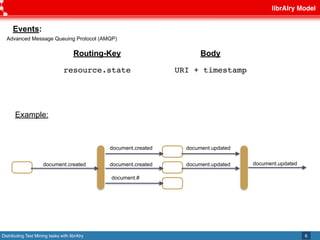
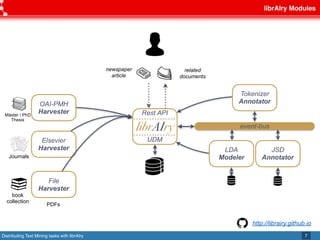




This document discusses librAIry, a text mining framework that can distribute text mining tasks across multiple sources and retrieve similar documents from a large corpus. LibrAIry uses standards like OAI-PMH, Linked Data Principles and AMQP to harvest and process textual data from sources like repositories, newspapers and PDFs. It provides modules for tasks like tokenization, annotation and topic modeling. LibrAIry has been used in real world applications to analyze patents and recommend books. Future work aims to improve resource definition and use resource URIs in routing keys.




















































