Download to read offline





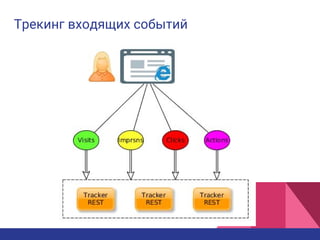
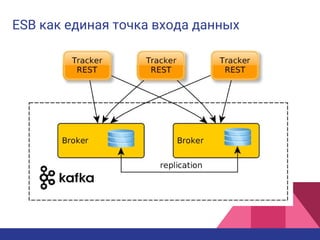
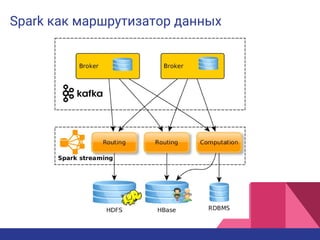






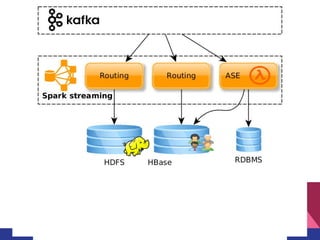





Документ описывает процессинг данных на лямбда-архитектуре для платформы управления данными в рекламной технологии. Основное внимание уделяется сбору и анализу пользовательской активности, созданию профиля пользователей и эффективной сегментации для улучшения релевантности рекламы. Также обсуждаются плюсы и минусы использования этой архитектуры, включая оперативность и масштабируемость, а также сложности и затраты на реализацию.































































