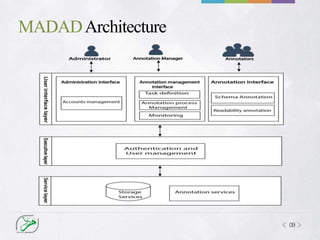
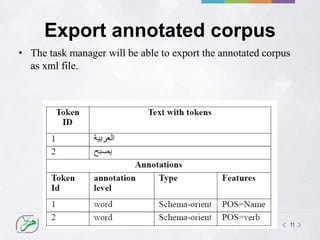
MADAD is an online tool for annotating Arabic text. It allows users to create customized annotation schemes to annotate texts for various linguistic phenomena. MADAD has two functions for annotating readability - a pairwise comparison method where annotators compare the readability of text pairs, and a direct evaluation method where annotators assign a readability score on a scale. The tool calculates inter-annotator agreement to measure the reliability of annotations and resolve differences between annotators. It can export annotated corpora in XML format.




![01
Text Readability
• Degree to which a text can be understood (Klare, 2000).
• Readability is a way of deciding how hard a text is.
• Sum of all elements in textual material that affect a reader’s
understanding (graphical aspects or linguistic variables [semantic or syntax]).](https://image.slidesharecdn.com/madadv1-180628120806/85/Madad-Arabic-Annotation-Tool-for-Arabic-Text-4-320.jpg)