Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Takuro Sasaki
PDF, PPTX
20,945 views
サイト/ブログから本文抽出する方法
ルールベースとヒューリスティック、二つの方法でサイト/ブログから本文抽出する方法
Technology
◦
Read more
25
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 31
2
/ 31
Most read
3
/ 31
4
/ 31
5
/ 31
6
/ 31
7
/ 31
8
/ 31
9
/ 31
10
/ 31
Most read
11
/ 31
12
/ 31
13
/ 31
14
/ 31
15
/ 31
16
/ 31
17
/ 31
18
/ 31
19
/ 31
20
/ 31
21
/ 31
22
/ 31
23
/ 31
24
/ 31
25
/ 31
26
/ 31
27
/ 31
28
/ 31
29
/ 31
30
/ 31
31
/ 31
More Related Content
PDF
数クリックで瞬時に切り替えられる メンテナンスページの作り方
by
Yuta Okoshi
PPTX
MongoDBの監視
by
Tetsutaro Watanabe
PDF
LogbackからLog4j 2への移行によるアプリケーションのスループット改善 ( JJUG CCC 2021 Fall )
by
Hironobu Isoda
PDF
Dapr × Kubernetes ではじめるポータブルなマイクロサービス(CloudNative Days Tokyo 2020講演資料)
by
NTT DATA Technology & Innovation
PDF
例外設計における大罪
by
Takuto Wada
PPTX
Apache Solr 入門
by
順平 西本
PDF
コンテナの作り方「Dockerは裏方で何をしているのか?」
by
Masahito Zembutsu
PPTX
Webアプリケーション負荷試験実践入門
by
樽八 仲川
数クリックで瞬時に切り替えられる メンテナンスページの作り方
by
Yuta Okoshi
MongoDBの監視
by
Tetsutaro Watanabe
LogbackからLog4j 2への移行によるアプリケーションのスループット改善 ( JJUG CCC 2021 Fall )
by
Hironobu Isoda
Dapr × Kubernetes ではじめるポータブルなマイクロサービス(CloudNative Days Tokyo 2020講演資料)
by
NTT DATA Technology & Innovation
例外設計における大罪
by
Takuto Wada
Apache Solr 入門
by
順平 西本
コンテナの作り方「Dockerは裏方で何をしているのか?」
by
Masahito Zembutsu
Webアプリケーション負荷試験実践入門
by
樽八 仲川
What's hot
PPTX
ぱぱっと理解するSpring Cloudの基本
by
kazuki kumagai
PPTX
Mongo dbを知ろう
by
CROOZ, inc.
PDF
CloudNativeな決済サービスの開発と2年間の歩み #sf_A4
by
Junya Suzuki
PDF
マイクロサービス化に向けて
by
HIRA
PPTX
機械学習の精度と売上の関係
by
Tokoroten Nakayama
PPTX
Linked Data (再)入門
by
National Institute of Informatics (NII)
PPTX
さくっと理解するSpring bootの仕組み
by
Takeshi Ogawa
PDF
ADFS クレームルール言語 Deep Dive
by
Suguru Kunii
PDF
AmebaのMongoDB活用事例
by
Akihiro Kuwano
PPTX
PHPのテスト名を日本語にした話
by
Norifumi Kawamoto
PDF
解説!30分で分かるLEAN ANALYTICS
by
しくみ製作所
PPTX
Oracleからamazon auroraへの移行にむけて
by
Yoichi Sai
PDF
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料)
by
NTT DATA Technology & Innovation
PDF
テスコン優勝事例におけるテスト分析公開用
by
Tetsuya Kouno
PDF
今だからこそ知りたい Docker Compose/Swarm 入門
by
Masahito Zembutsu
PPTX
今さら聞けない人のためのCI/CD超入門
by
VirtualTech Japan Inc./Begi.net Inc.
PDF
Eclipseデバッガを活用するための31のtips
by
Hiroki Kondo
PPTX
テストコードの DRY と DAMP
by
Yusuke Kagata
PDF
CircleCIのinfrastructureを支えるTerraformのCI/CDパイプラインの改善
by
Ito Takayuki
PDF
Javaのログ出力: 道具と考え方
by
Taku Miyakawa
ぱぱっと理解するSpring Cloudの基本
by
kazuki kumagai
Mongo dbを知ろう
by
CROOZ, inc.
CloudNativeな決済サービスの開発と2年間の歩み #sf_A4
by
Junya Suzuki
マイクロサービス化に向けて
by
HIRA
機械学習の精度と売上の関係
by
Tokoroten Nakayama
Linked Data (再)入門
by
National Institute of Informatics (NII)
さくっと理解するSpring bootの仕組み
by
Takeshi Ogawa
ADFS クレームルール言語 Deep Dive
by
Suguru Kunii
AmebaのMongoDB活用事例
by
Akihiro Kuwano
PHPのテスト名を日本語にした話
by
Norifumi Kawamoto
解説!30分で分かるLEAN ANALYTICS
by
しくみ製作所
Oracleからamazon auroraへの移行にむけて
by
Yoichi Sai
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料)
by
NTT DATA Technology & Innovation
テスコン優勝事例におけるテスト分析公開用
by
Tetsuya Kouno
今だからこそ知りたい Docker Compose/Swarm 入門
by
Masahito Zembutsu
今さら聞けない人のためのCI/CD超入門
by
VirtualTech Japan Inc./Begi.net Inc.
Eclipseデバッガを活用するための31のtips
by
Hiroki Kondo
テストコードの DRY と DAMP
by
Yusuke Kagata
CircleCIのinfrastructureを支えるTerraformのCI/CDパイプラインの改善
by
Ito Takayuki
Javaのログ出力: 道具と考え方
by
Taku Miyakawa
More from Takuro Sasaki
PDF
JAWSUG初心者支部 AWSの勉強の仕方
by
Takuro Sasaki
PDF
Crawler for Non engineer
by
Takuro Sasaki
PDF
JAWSUG architecture-crowler
by
Takuro Sasaki
PDF
Innovation eggcloudnative
by
Takuro Sasaki
PDF
Lambda認証認可パターン
by
Takuro Sasaki
PDF
Swaggerで始めるモデルファーストなAPI開発
by
Takuro Sasaki
PDF
Jawsug chiba API Gateway
by
Takuro Sasaki
PDF
DevLove Kansai AWS
by
Takuro Sasaki
PDF
Rubyで操るAWS 第67回Ruby関西 勉強会
by
Takuro Sasaki
PDF
JAWS-UG初心者支部 AWS書籍活用術
by
Takuro Sasaki
PDF
JAWSUG Kansai Simple Workflow Service (SWF)
by
Takuro Sasaki
PDF
JAWSUG Osaka S3 CloudSearch
by
Takuro Sasaki
PDF
AWS Lambdaで作るクローラー/スクレイピング
by
Takuro Sasaki
PDF
Scraping withawsAWSを利用してスクレイピングの悩みを解決するチップス
by
Takuro Sasaki
PDF
Rubyで作るクローラー Ruby crawler
by
Takuro Sasaki
PDF
JAWS-UG三都物語2014 初心者向け Elasticity ELB/AutoScaling/EIP
by
Takuro Sasaki
PDF
Rubyで始めるWebスクレイピング
by
Takuro Sasaki
PDF
Jawsug osaka10 service®ions
by
Takuro Sasaki
PDF
第9回Jawsug大阪 ServiceProviders 現場で使えるAWS付随サービス!!
by
Takuro Sasaki
PDF
第2回 JAWS−UG 神戸 開発運用の現場でのChef活用
by
Takuro Sasaki
JAWSUG初心者支部 AWSの勉強の仕方
by
Takuro Sasaki
Crawler for Non engineer
by
Takuro Sasaki
JAWSUG architecture-crowler
by
Takuro Sasaki
Innovation eggcloudnative
by
Takuro Sasaki
Lambda認証認可パターン
by
Takuro Sasaki
Swaggerで始めるモデルファーストなAPI開発
by
Takuro Sasaki
Jawsug chiba API Gateway
by
Takuro Sasaki
DevLove Kansai AWS
by
Takuro Sasaki
Rubyで操るAWS 第67回Ruby関西 勉強会
by
Takuro Sasaki
JAWS-UG初心者支部 AWS書籍活用術
by
Takuro Sasaki
JAWSUG Kansai Simple Workflow Service (SWF)
by
Takuro Sasaki
JAWSUG Osaka S3 CloudSearch
by
Takuro Sasaki
AWS Lambdaで作るクローラー/スクレイピング
by
Takuro Sasaki
Scraping withawsAWSを利用してスクレイピングの悩みを解決するチップス
by
Takuro Sasaki
Rubyで作るクローラー Ruby crawler
by
Takuro Sasaki
JAWS-UG三都物語2014 初心者向け Elasticity ELB/AutoScaling/EIP
by
Takuro Sasaki
Rubyで始めるWebスクレイピング
by
Takuro Sasaki
Jawsug osaka10 service®ions
by
Takuro Sasaki
第9回Jawsug大阪 ServiceProviders 現場で使えるAWS付随サービス!!
by
Takuro Sasaki
第2回 JAWS−UG 神戸 開発運用の現場でのChef活用
by
Takuro Sasaki
サイト/ブログから本文抽出する方法
1.
第2回Webスクレイピング勉強会@東京 ! サイト/ブログから 本文抽出する方法 2014年8月17日 @dkfj 佐々木拓郎
2.
✦ プロフィール ‣ Webシステムを得意とするSIerで勤務 ‣
最近の仕事はAWS事業の推進 ‣ Webスクレイピングして、データマイニングするのが趣味 ★ ソーシャル・ネットワーク ‣ blog: http://blog.takuros.net/ ‣ twitter: @dkfj ‣ Facebook: takuro.sasaki ‣ SlideShare: http://www.slideshare.net/takurosasaki/ ‣ http://www.justyo.co/TAKUROS/ @dkfj 自己紹介: 佐々木拓郎
3.
主にJAWSUG大阪で活動しています (AWS勉強会)
4.
「Rubyによるクローラー開発技法」 Rubyのクローラー/スクレイピング本を 書きました。8月24日に発売予定です。
5.
本日のテーマ ! サイト/ブログから 本文抽出する方法
6.
本日のテーマ ! サイト/ブログから 本文抽出する方法 何故、必要なのか?
7.
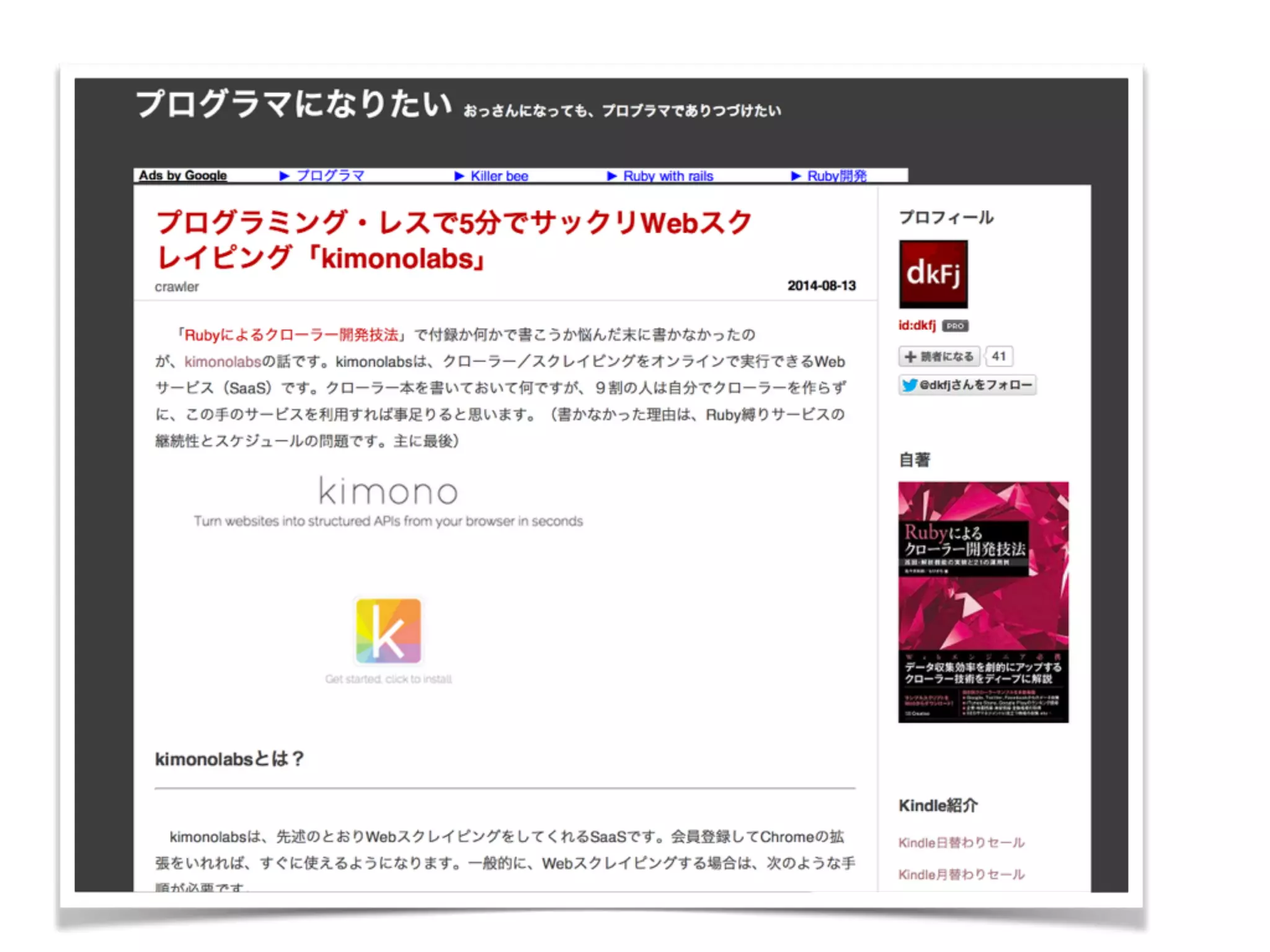
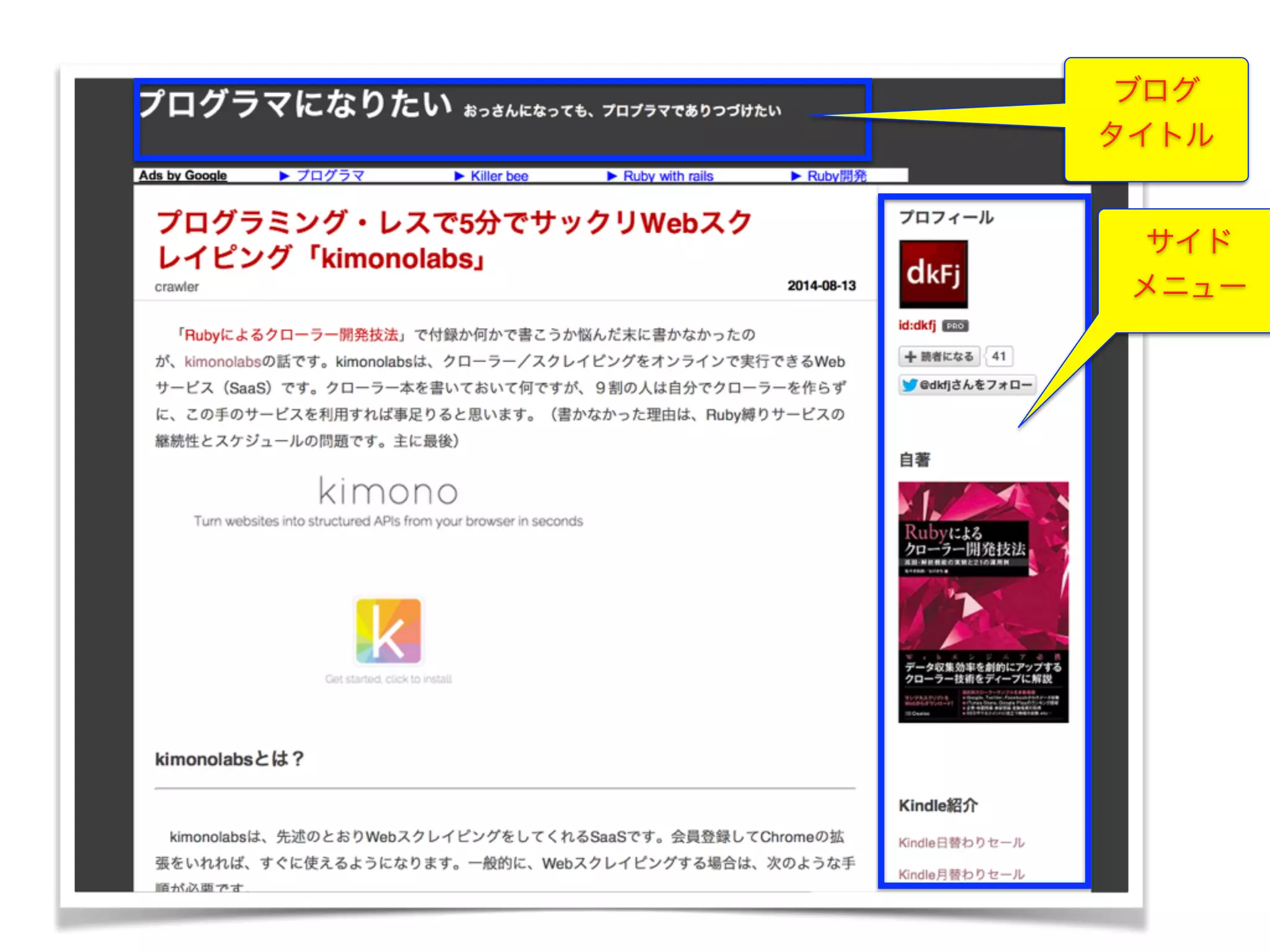
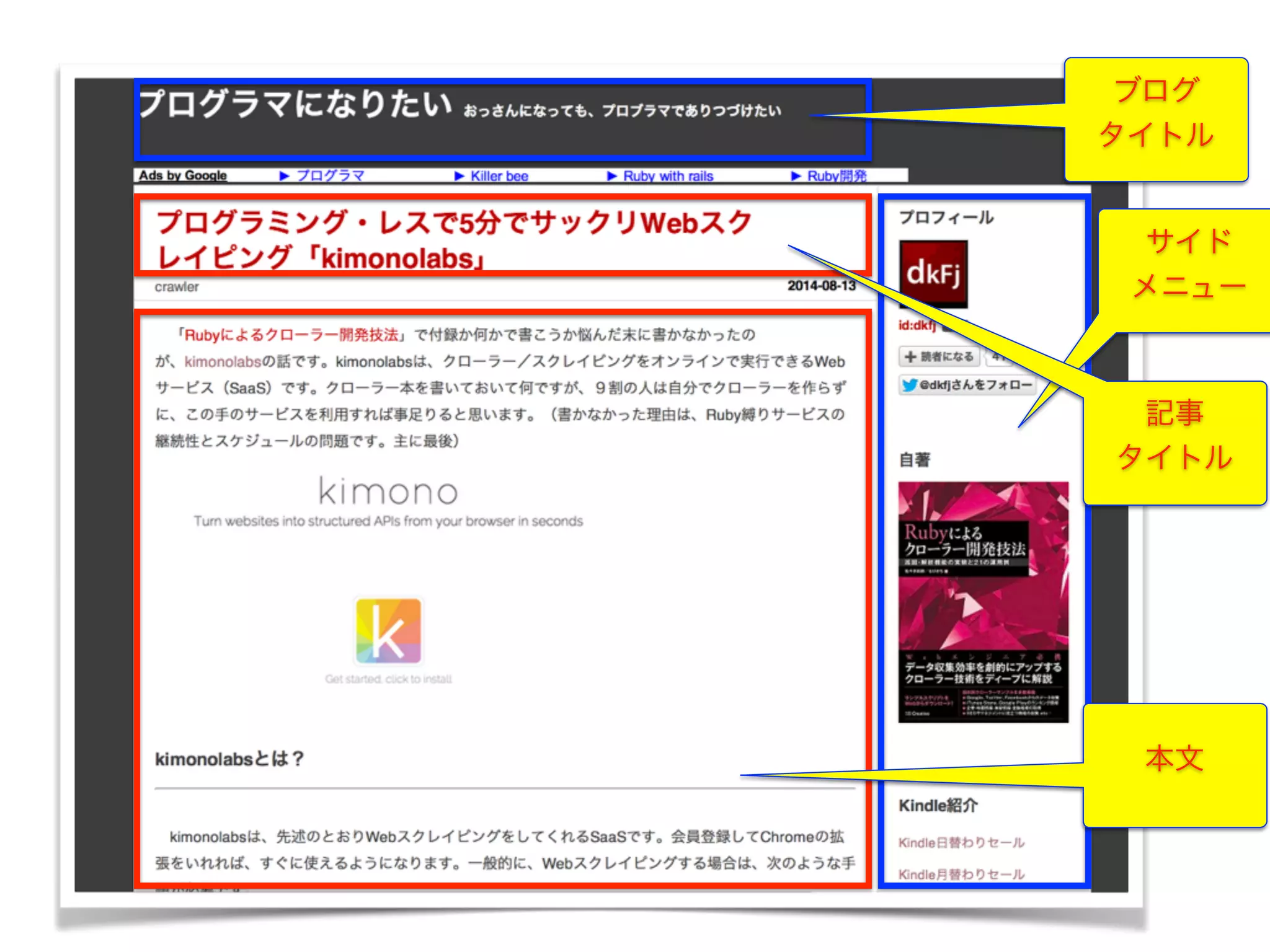
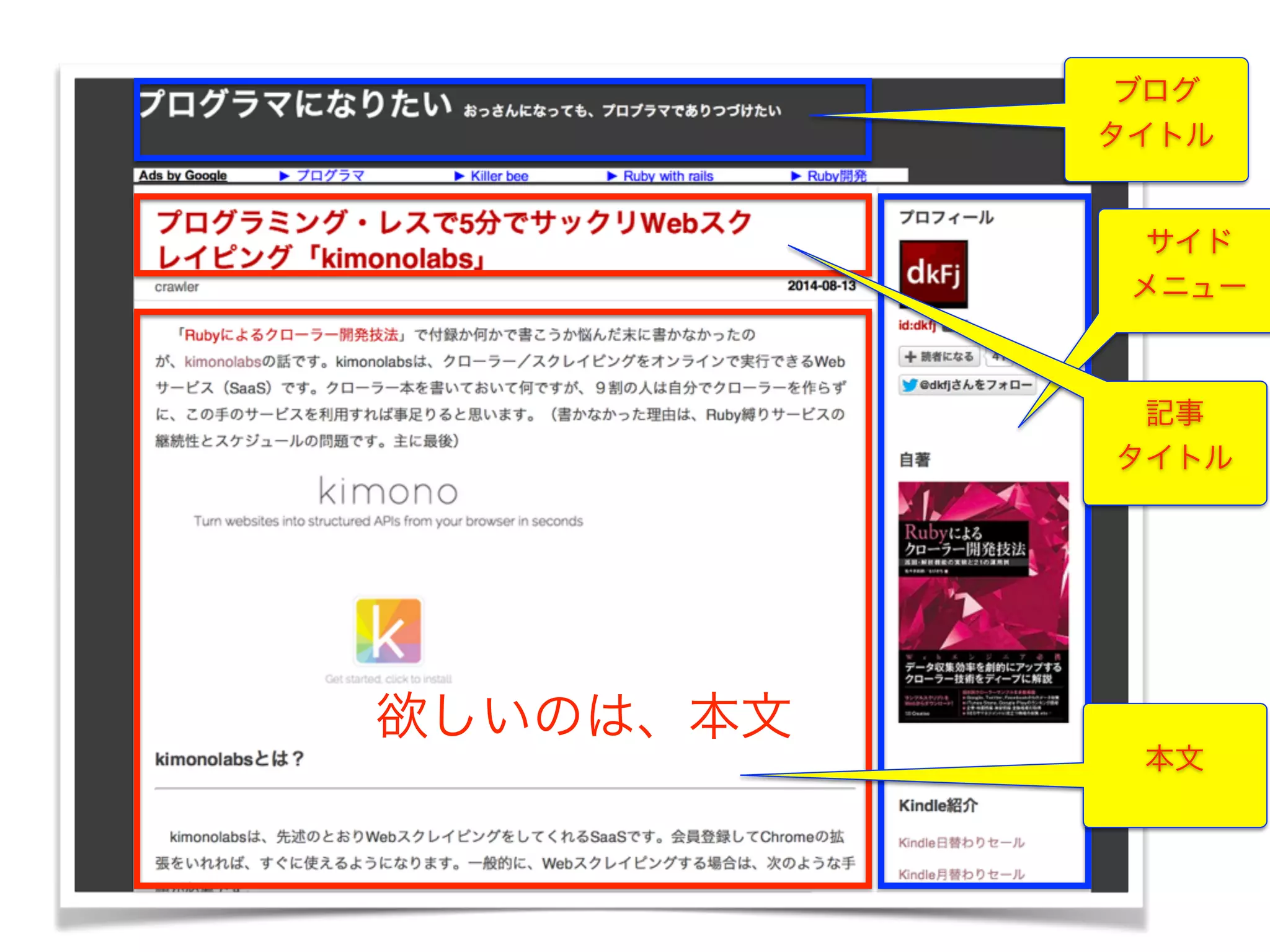
一般的なブログの構造
9.
ブログ タイトル サイド メニュー
10.
ブログ タイトル サイド メニュー 本文 記事 タイトル
11.
ブログ タイトル サイド メニュー 本文 記事 タイトル 欲しいのは、本文
12.
サイト/ブログの本文抽出の目的 • 書かれている記事を読みたい • コーパス/解析の元データとして利用したい
13.
コーパスとは? コーパス(corpus)とは、言語学において、自然言語処理の 研究に用いるため、自然言語の文章を構造化し大規模に集積した もの。構造化では言語的な情報(品詞、統語構造など)が付与さ れる。コンピュータ利用が進み、電子化データとなった。 ! ウィキペディアより
14.
自然文としてのブログの特徴 • 新聞に較べて、口語に近い単語/フレーズが出現する • タグやカテゴリーなどのメタデータがあり、分類しやすい •
投稿者の属性を、ある程度推定できる ex) 男性/女性、社会人/学生、10代、20代、30代
15.
自然文としてのブログの特徴 • 新聞に較べて、口語に近い単語/フレーズが出現する • タグやカテゴリーなどのメタデータがあり、分類しやすい •
投稿者の属性を、ある程度推定できる ex) 男性/女性、社会人/学生、10代、20代、30代 わりと貴重なデータ
16.
本文抽出の方法 • パーサーを利用して、HTML構造を分析しての抽出 • 自然言語処理を利用して、本文らしさを分析しての抽出
17.
HTMLの構文解析 ! • 取得対象のHTMLの構文を分析して、本文を抽出 • いわゆるルール・ベース ex)
HTMLのタグのidが、contentのものを取得
18.
はてなブログの場合 entry-contentの中が ブログ本文
19.
HTMLの構文解析 メリット • 正確に本文を抽出できる • 比較的、(コンピュータリソースの)負荷が低い デメリット •
ブログ種別ごとに、開発が必要 • 取得元のHTML構造の変更に弱い
20.
nokogoriを使って取得 require 'open-uri' require 'nokogiri' ! html
= open('http://blog.takuros.net/entry/ 20140104/1388788175').read ! doc = Nokogiri::HTML(html) puts doc.xpath("//div[@class='entry-content']").text
21.
• HTML/XMLの構文解析器(パーサー) • ほぼデファクトスタンダード •
XPath or CSSセレクタで、HTML中の要素を選択 • UTF-8以外の文字コードを扱う場合は注意 require 'nokogiri' require 'open-uri' ! doc = Nokogiri.HTML(open("http://nokogiri.org/")) doc.css('a').each do ¦element¦ puts element[:href] end 参照:Ruby製の構文解析ツール、Nokogiriの使い方 with Xpath http://blog.takuros.net/entry/2014/04/15/070434
22.
自然言語処理を利用した本文抽出 • 文章内から本文らしい部分を抜き出す • ヒューリスティック(経験則) •
自分で一から実装するのは、割と大変
23.
本文抽出モジュール • ExtractContnt (Ruby) •
HTML::Extract (Perl) • HTML-Feature (Perl) • ExtractContnt/webextract.py (Python)
24.
ExtractContentの実装 • html をブロックに分離、スコアの低いブロックを除外 •
評価の高い連続ブロックをクラスタ化し、クラスタ間でさ らに比較を行う • スコアは配置、テキスト長、アフィリエイトリンク、フッ タ等に特有のキーワードが含まれているかによって決定 • Google AdSense Section Target ブロックには本文が記 述されているとし、特に抽出
25.
自然言語処理を利用した本文抽出 メリット • ブログ種別に依存しない • 取得元のHTML変更に強い デメリット •
構文解析に比べると、精度が落ちる • 比較的、(コンピュータリソースの)負荷が高い
26.
nokogoriを使って取得 require 'extractcontent' require open-uri' ! html
= open( 'http://blog.takuros.net/entry/ 20140104/1388788175').read ! content, title = ExtractContent.analyse(html) puts title puts content
27.
まとめ • 本文抽出の方法は、主に2種類 • どちらも一長一短あるので、用途に応じて使う •
正確さを期すならば、HTMLの構文解析 書かれている内容、そのものが必要な場合 • 厳密さがいならいのであれば、本文抽出モジュール コーパスや解析用の元データとして利用
28.
今日の話は、 この辺に書いています
29.
おまけ キーワード抽出 • 辞書方式 • Mecabを利用した未知語抽出
30.
おまけ その2 特徴語抽出 • TD/IDFが一般的 • Yahooのキーフレーズ抽出APIなどもあり http://developer.yahoo.co.jp/webapi/jlp/keyphrase/ v1/extract.html
31.
ご清聴ありがとうございました 後日の質問は、@dkfjまで
Download
















![nokogoriを使って取得
require 'open-uri'
require 'nokogiri'
!
html = open('http://blog.takuros.net/entry/
20140104/1388788175').read
!
doc = Nokogiri::HTML(html)
puts doc.xpath("//div[@class='entry-content']").text](https://image.slidesharecdn.com/abstractblog-140817020906-phpapp01/75/slide-20-2048.jpg)
![• HTML/XMLの構文解析器(パーサー)
• ほぼデファクトスタンダード
• XPath or CSSセレクタで、HTML中の要素を選択
• UTF-8以外の文字コードを扱う場合は注意
require 'nokogiri'
require 'open-uri'
!
doc = Nokogiri.HTML(open("http://nokogiri.org/"))
doc.css('a').each do ¦element¦
puts element[:href]
end
参照:Ruby製の構文解析ツール、Nokogiriの使い方 with Xpath
http://blog.takuros.net/entry/2014/04/15/070434](https://image.slidesharecdn.com/abstractblog-140817020906-phpapp01/75/slide-21-2048.jpg)

























































