Downloaded 42 times


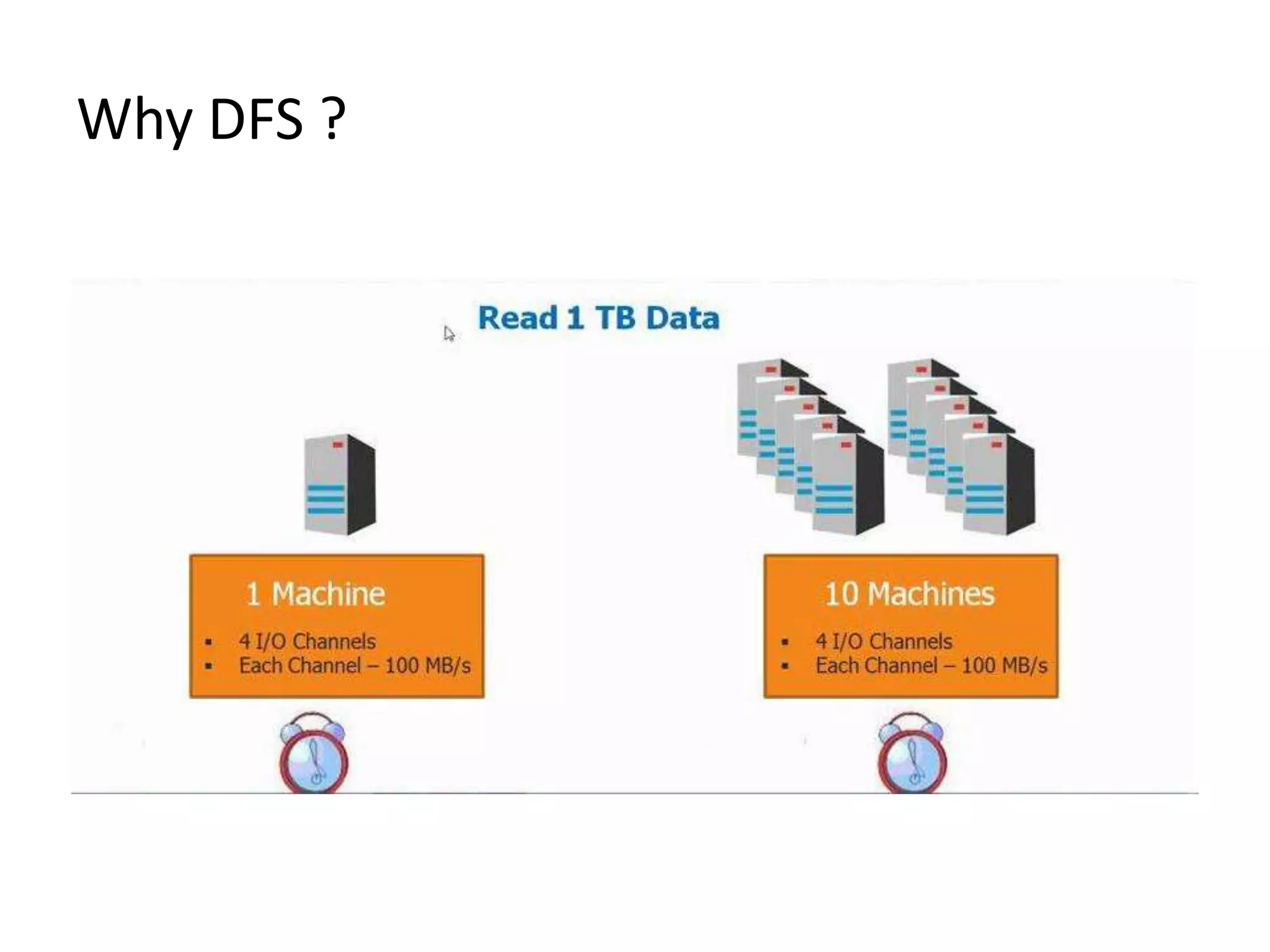





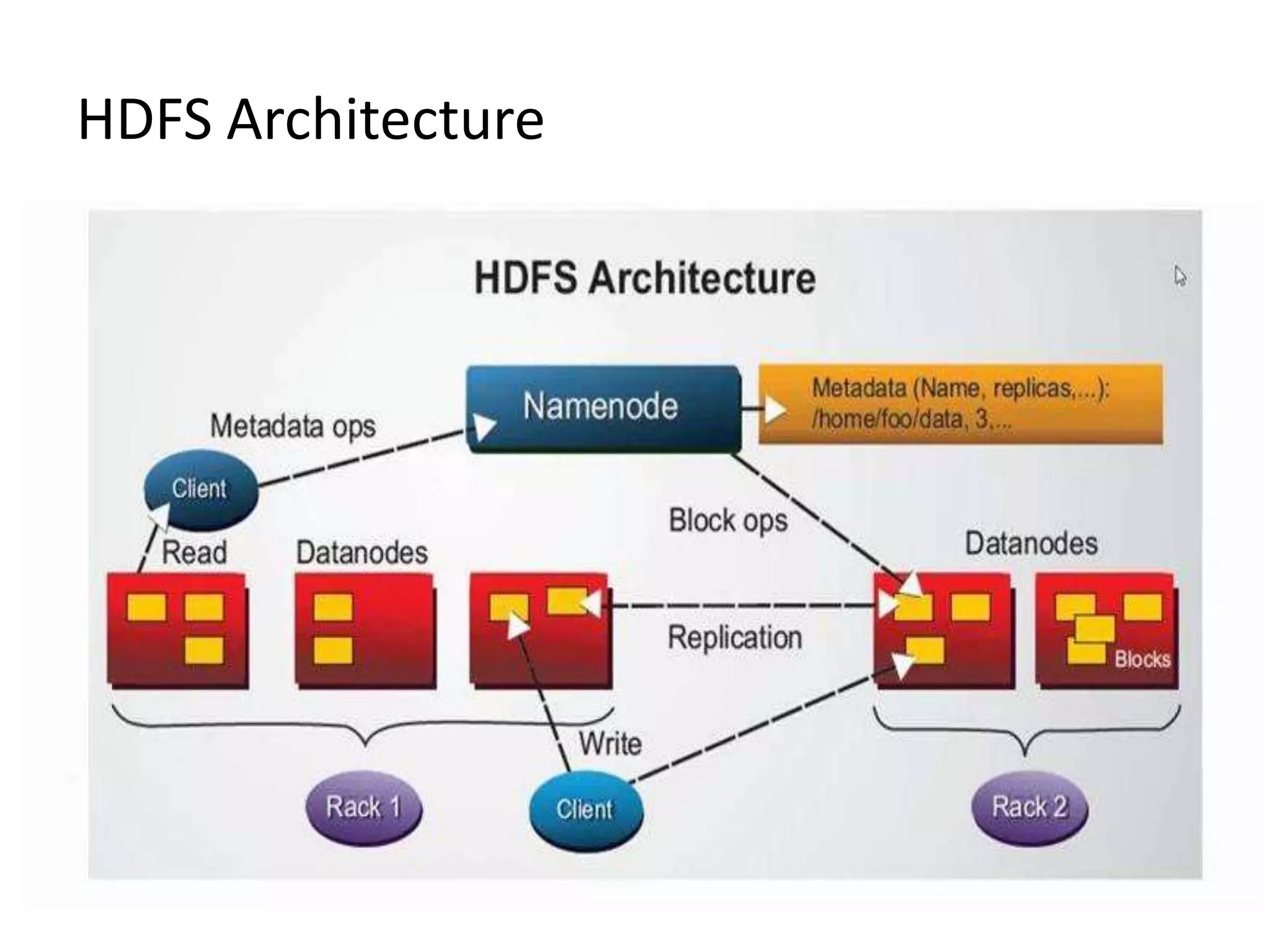
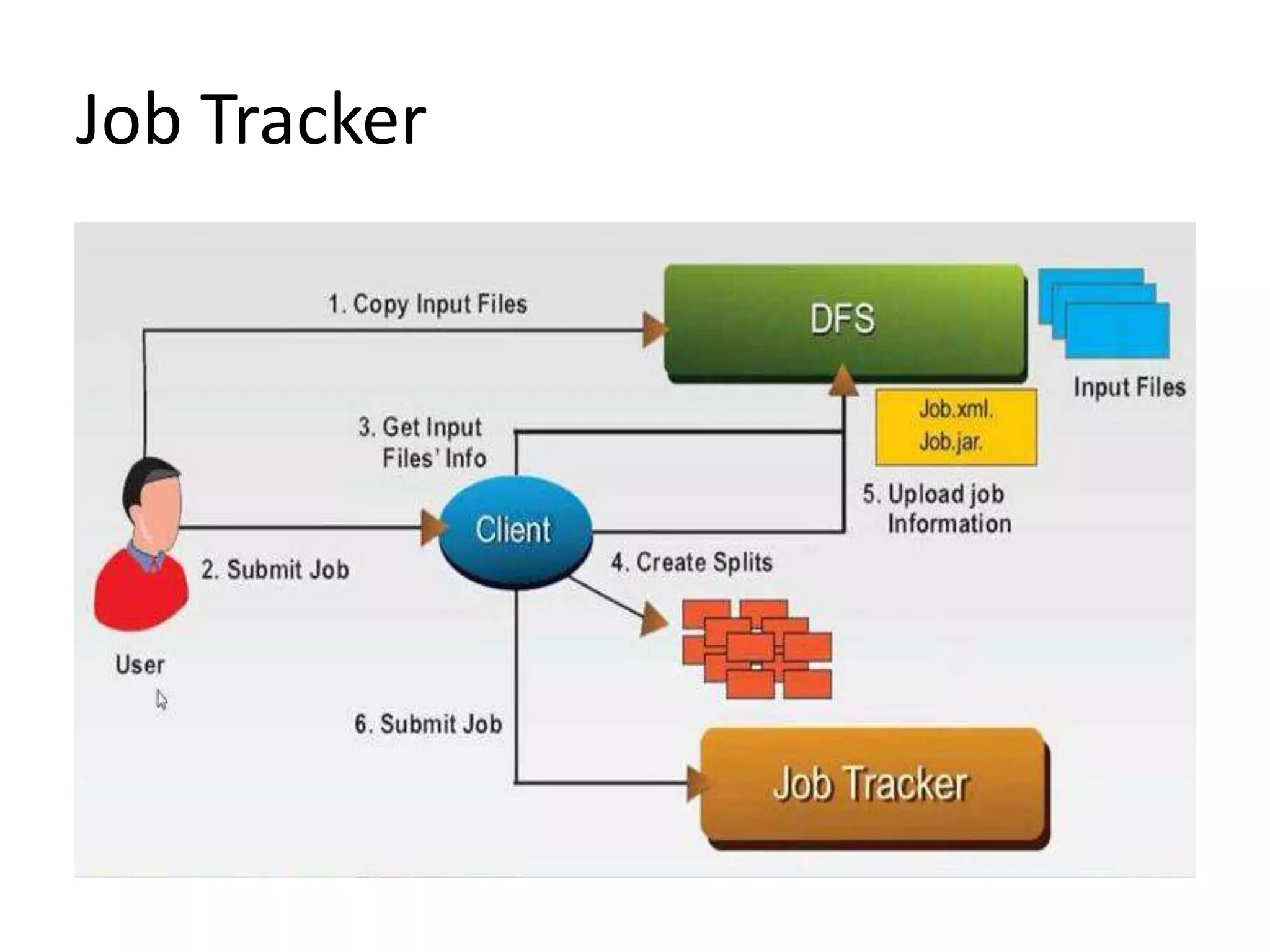
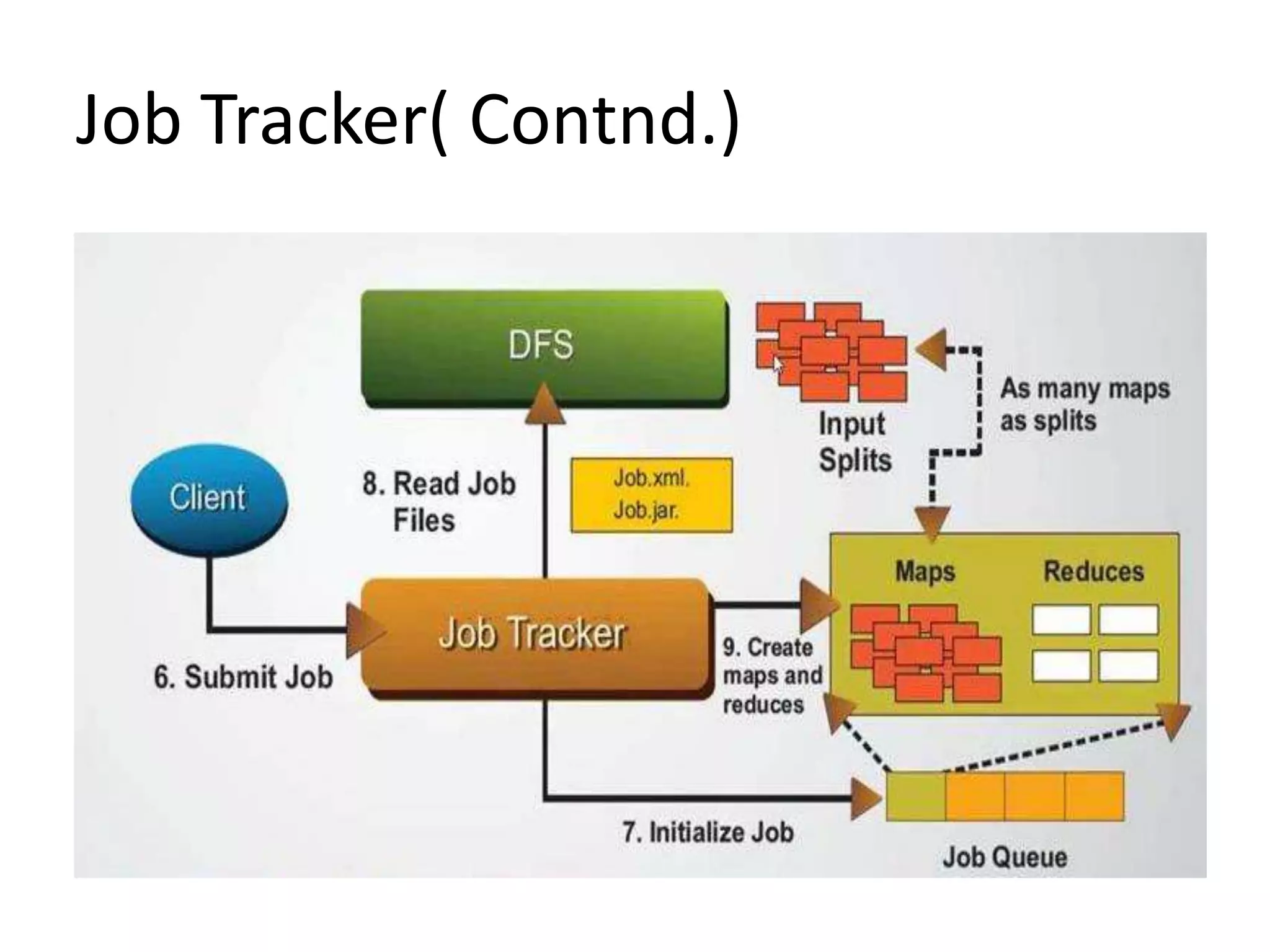




The document summarizes Hadoop HDFS, which is a distributed file system designed for storing large datasets across clusters of commodity servers. It discusses that HDFS allows distributed processing of big data using a simple programming model. It then explains the key components of HDFS - the NameNode, DataNodes, and HDFS architecture. Finally, it provides some examples of companies using Hadoop and references for further information.



































































