Download as PDF, PPTX
























![26
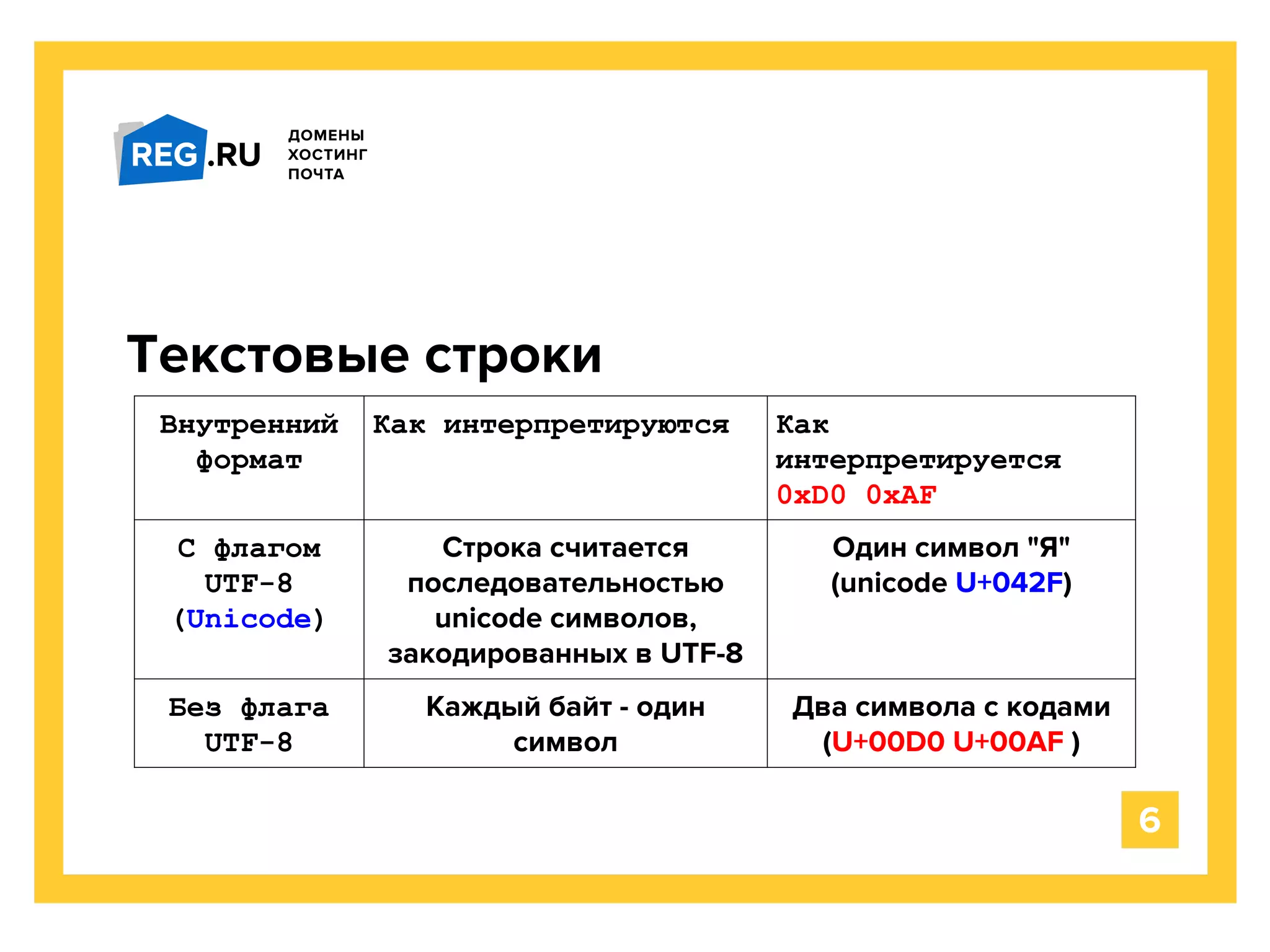
Сложные структуры данных
my $dataref = +{
x => [1,2,3,"тест"],
y => { a => 42 },
};
to_unicode_recursive($dataref);](https://image.slidesharecdn.com/unicodeperlyapcrussia2014-150530215552-lva1-app6891/75/Unicode-perl-yapc-russia-2014-26-2048.jpg)


![29
Сложные структуры данных
my $dataref = +{
x => [1,2,3,"тест"],
y => { a => 42 },
z => bless { field => "привет"}, 'MyObject'
};
to_unicode_recursive($dataref); # ошибка](https://image.slidesharecdn.com/unicodeperlyapcrussia2014-150530215552-lva1-app6891/75/Unicode-perl-yapc-russia-2014-29-2048.jpg)
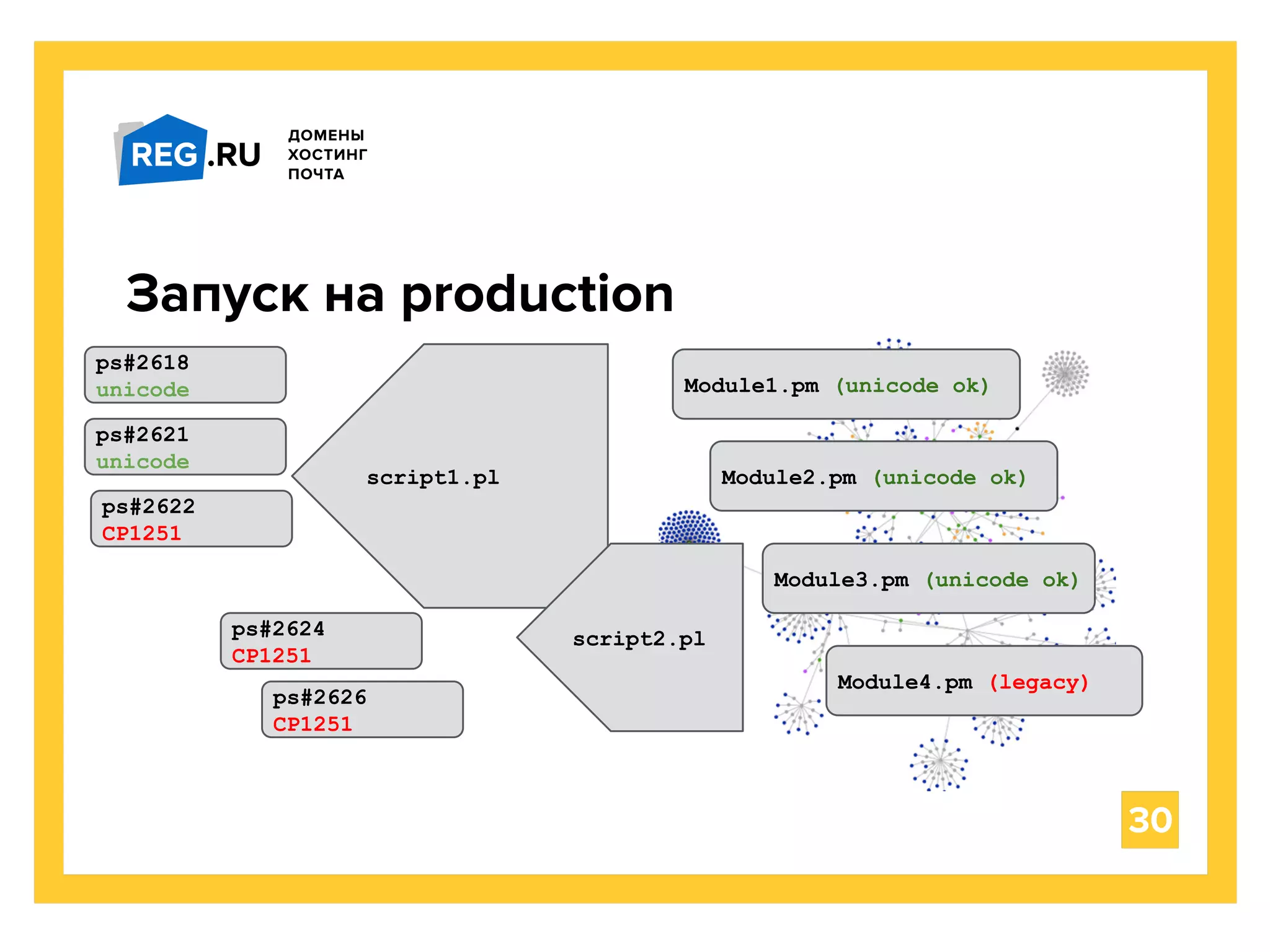



Документ обсуждает переход с кодировки cp1251 на Unicode в веб-приложении на Perl для поддержки многоязычности. Рассматриваются различные способы работы с текстом в разных кодировках, включая кодовые примеры и особенности реализации. В заключение подчеркивается важность корректного ввода-вывода и бизнес-логики для обеспечения совместимости с современными стандартами кодирования.








































