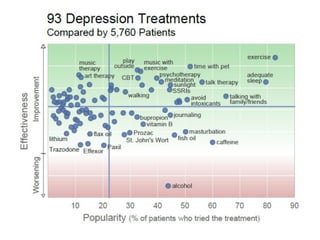
At a "Quantified Self and Science" meetup, Daniel Reda talks about the issue of correlation.Read less