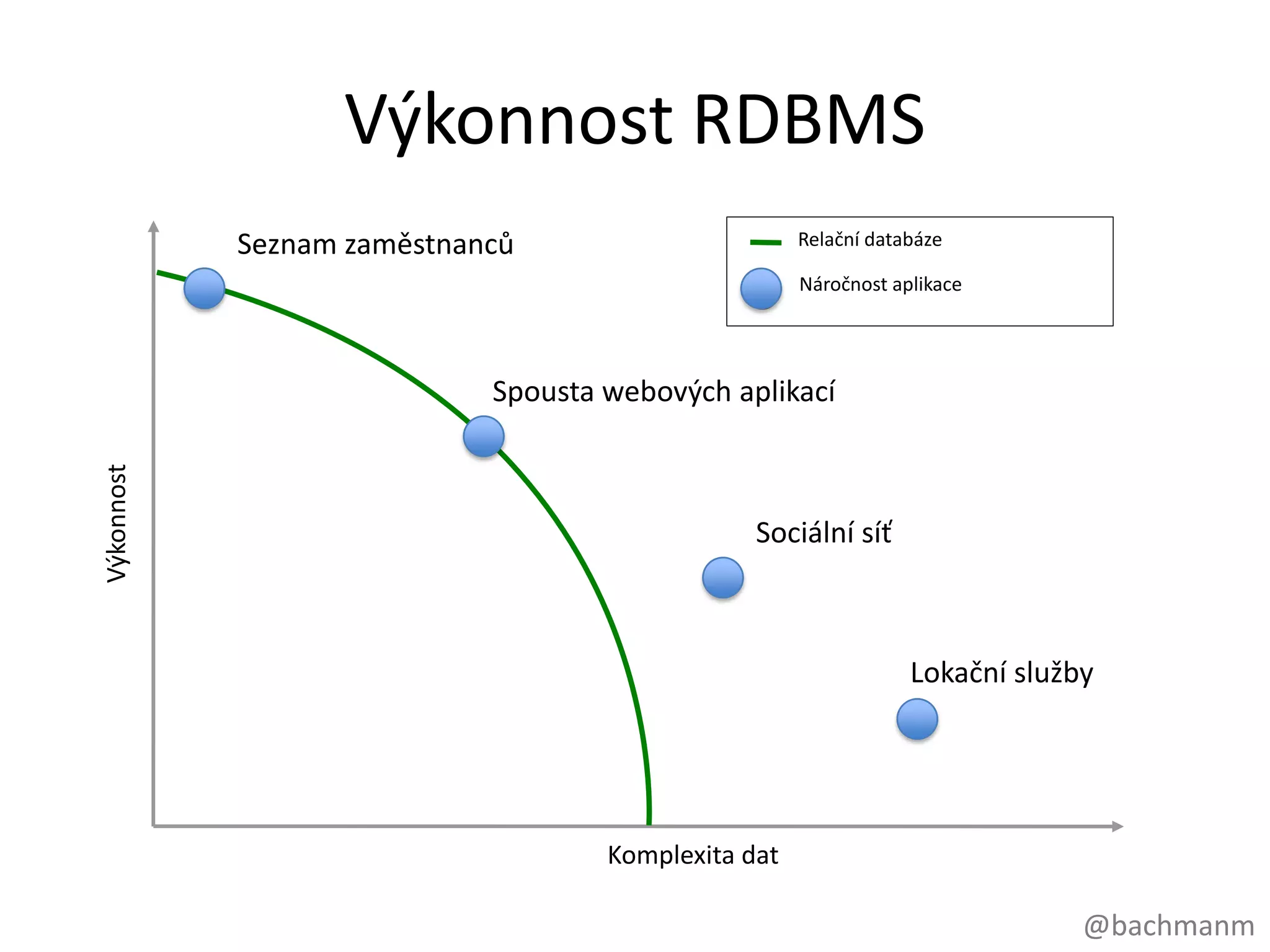
Výkonnost RDBMS
Seznam zaměstnanců Relační databáze
Náročnost aplikace
Spousta webových aplikací
Výkonnost
Sociální síť
Lokační služby
Komplexita dat
@bachmanm
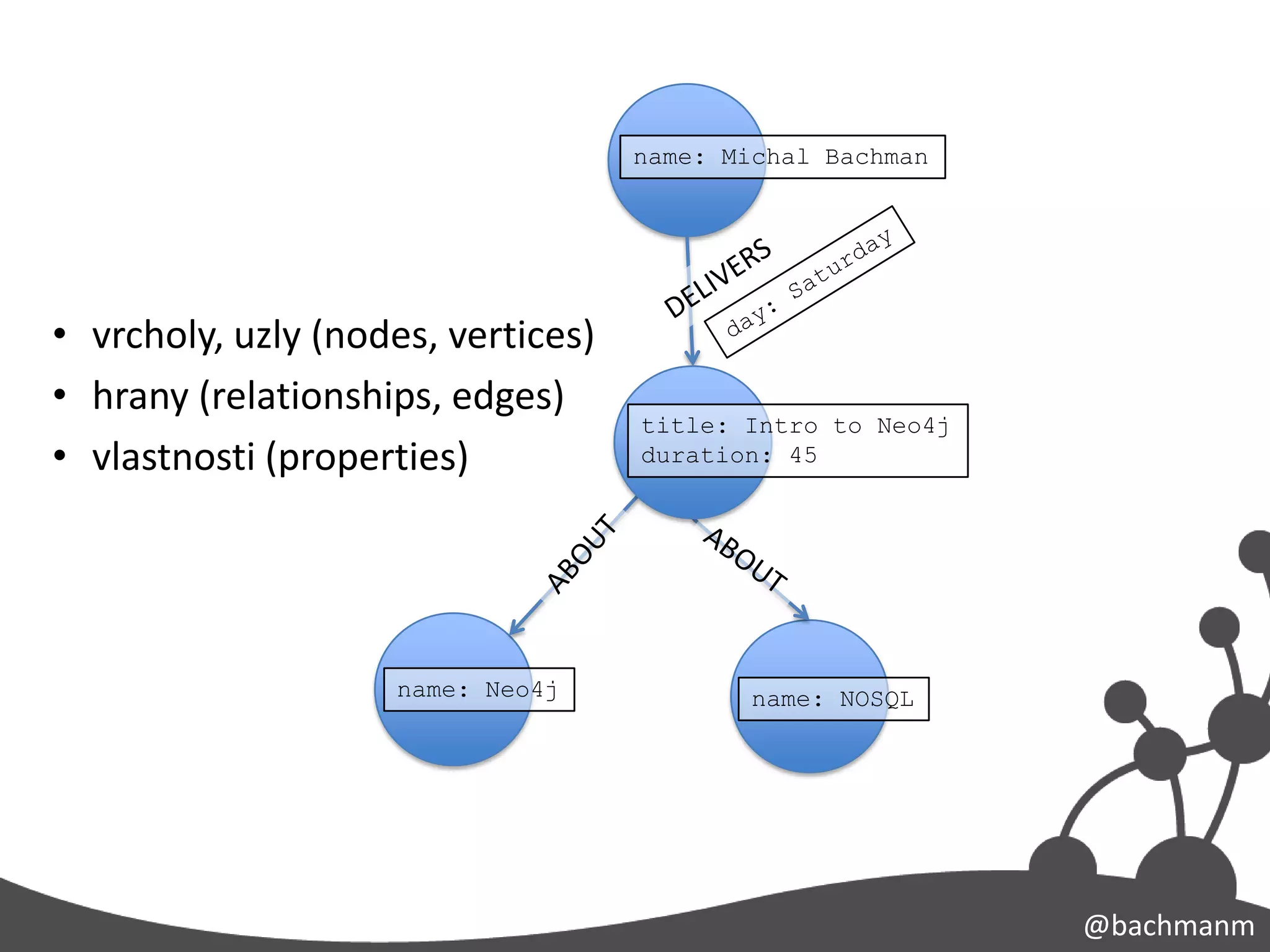
name: Michal Bachman
•vrcholy, uzly (nodes, vertices)
• hrany (relationships, edges)
title: Intro to Neo4j
• vlastnosti (properties) duration: 45
name: Neo4j name: NOSQL
@bachmanm
16.
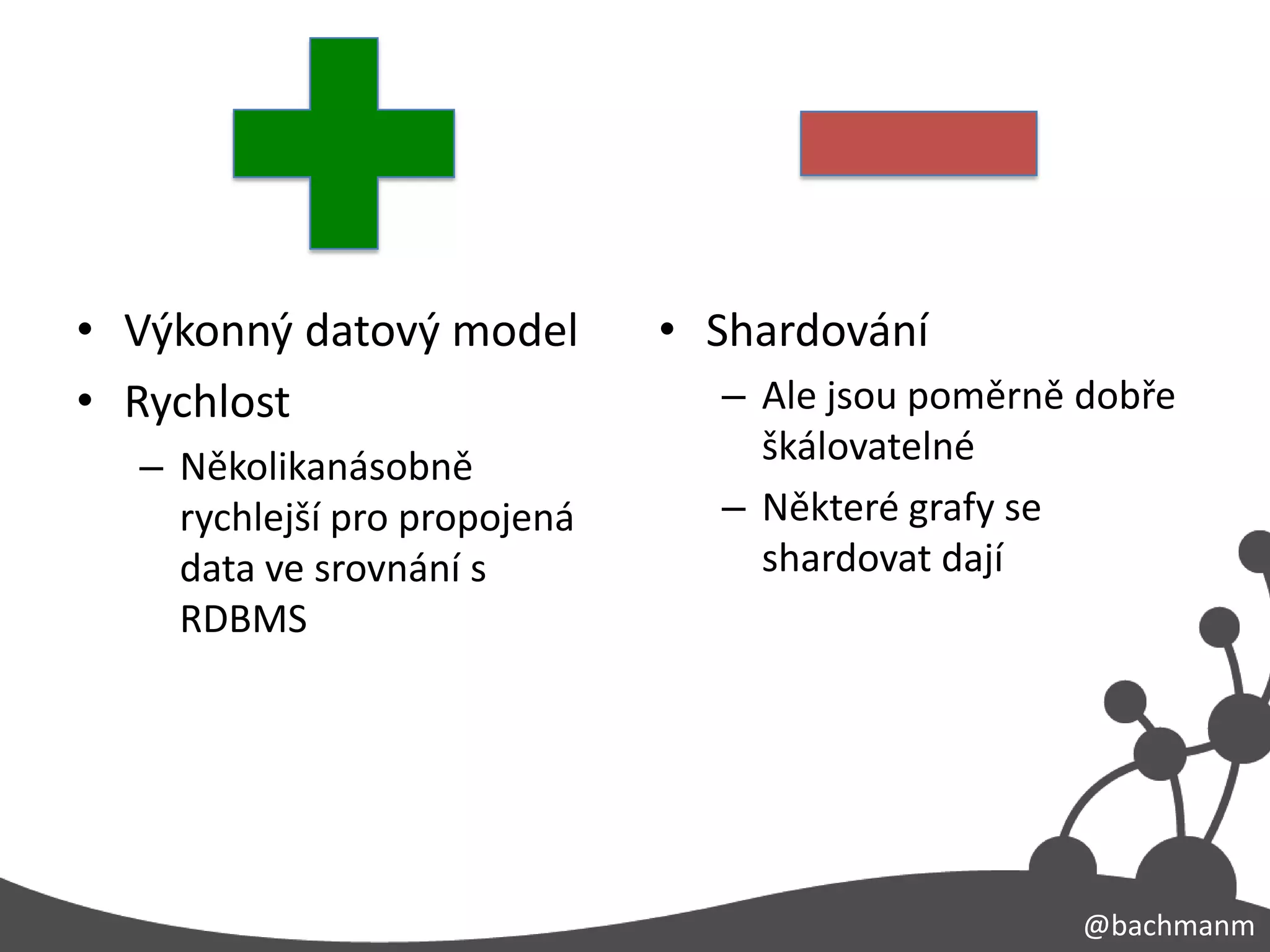
• Výkonný datovýmodel • Shardování
• Rychlost – Ale jsou poměrně dobře
– Několikanásobně škálovatelné
rychlejší pro propojená – Některé grafy se
data ve srovnání s shardovat dají
RDBMS
@bachmanm
17.
Výkonnost na příkladusociální sítě
(existuje cesta?)
• Experiment:
• cca 1000 lidí # lidí čas dotazu
• Každý průměrně 50 Relační 1000 2000ms
databáze
kamarádů
• pathExists(a,b)
do hloubky 4
• Cached (nečteme z
disku)
@bachmanm
18.
Výkonnost na příkladusociální sítě
(existuje cesta?)
• Experiment:
• cca 1000 lidí # lidí čas dotazu
• Každý průměrně 50 Relační 1000 2000ms
databáze
kamarádů
Neo4j 1000 2ms
• pathExists(a,b)
do hloubky 4
• Cached (nečteme z
disku)
@bachmanm
19.
Výkonnost na příkladusociální sítě
(existuje cesta?)
• Experiment:
• cca 1000 lidí # lidí čas dotazu
• Každý průměrně 50 Relační 1000 2000ms
databáze
kamarádů
Neo4j 1000 2ms
• pathExists(a,b)
Neo4j 1000000 2ms
do hloubky 4
• Cached (nečteme z
disku)
@bachmanm
20.
Použití grafů
• Sociální sítě
• Doporučovací systémy
• Telekomunikační sítě
• Business intelligence
• Geoprostorové problémy
• MDM
• ACL (access control lists)
• Rodokmeny
• Časové řady dat
• Web analytics
• Vědecká informatika (zejména bioinformatika)
• Indexování pomalých RDBMS
• Spousta dalších…!
@bachmanm
Server mode
– cd <install directory>
– bin/neo4j start
– bin/neo4j stop
• REST API
• JMX, prohlížeč dat, vizualizace
@bachmanm
32.
Embedded mode
• Vestejném procesu, jako aplikace
– Stáhnout .jar knihovny
– Nasměrovat na místo na disku
• Embedded mode má naprostou většinu funkcí
@bachmanm
33.
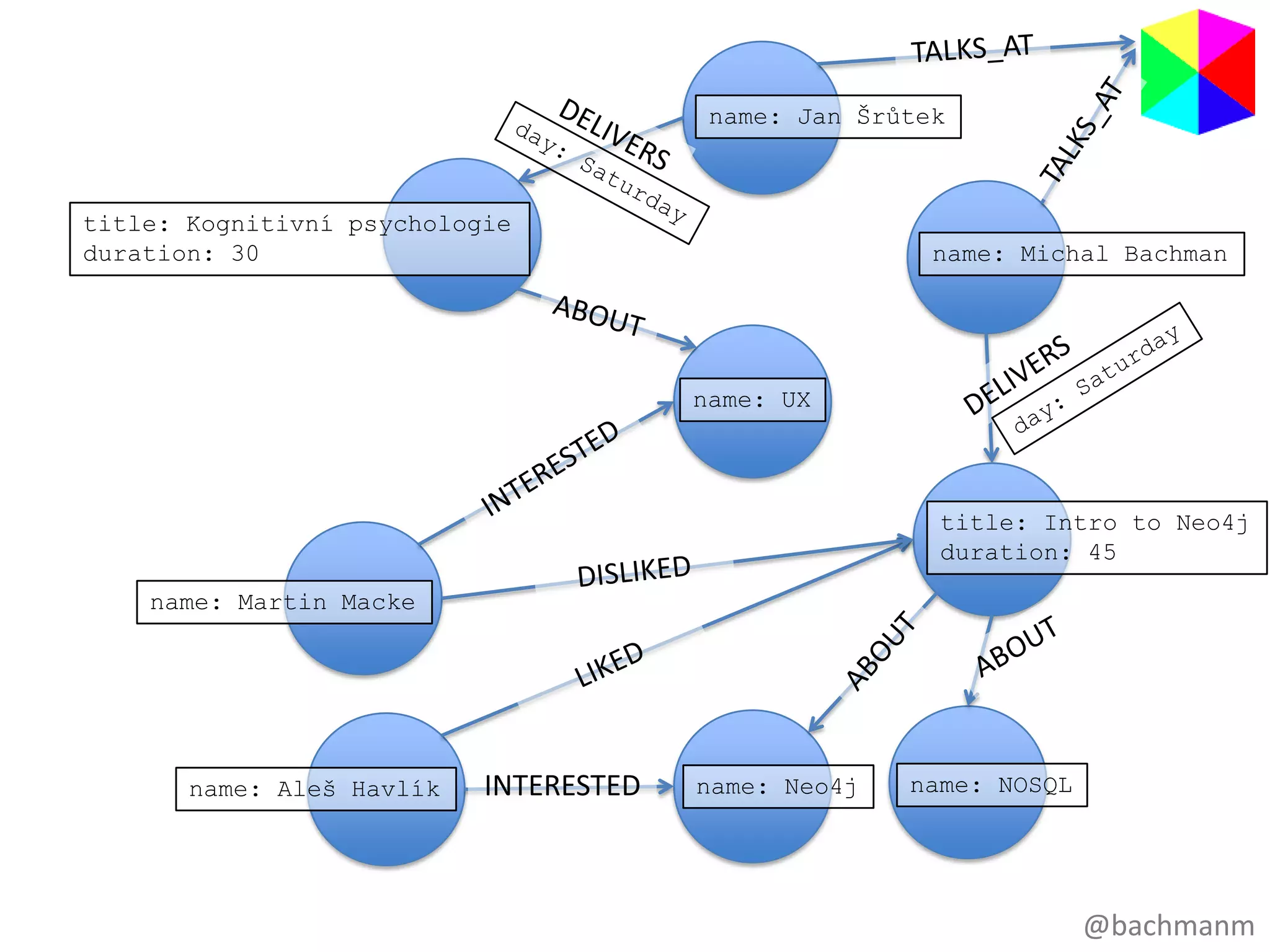
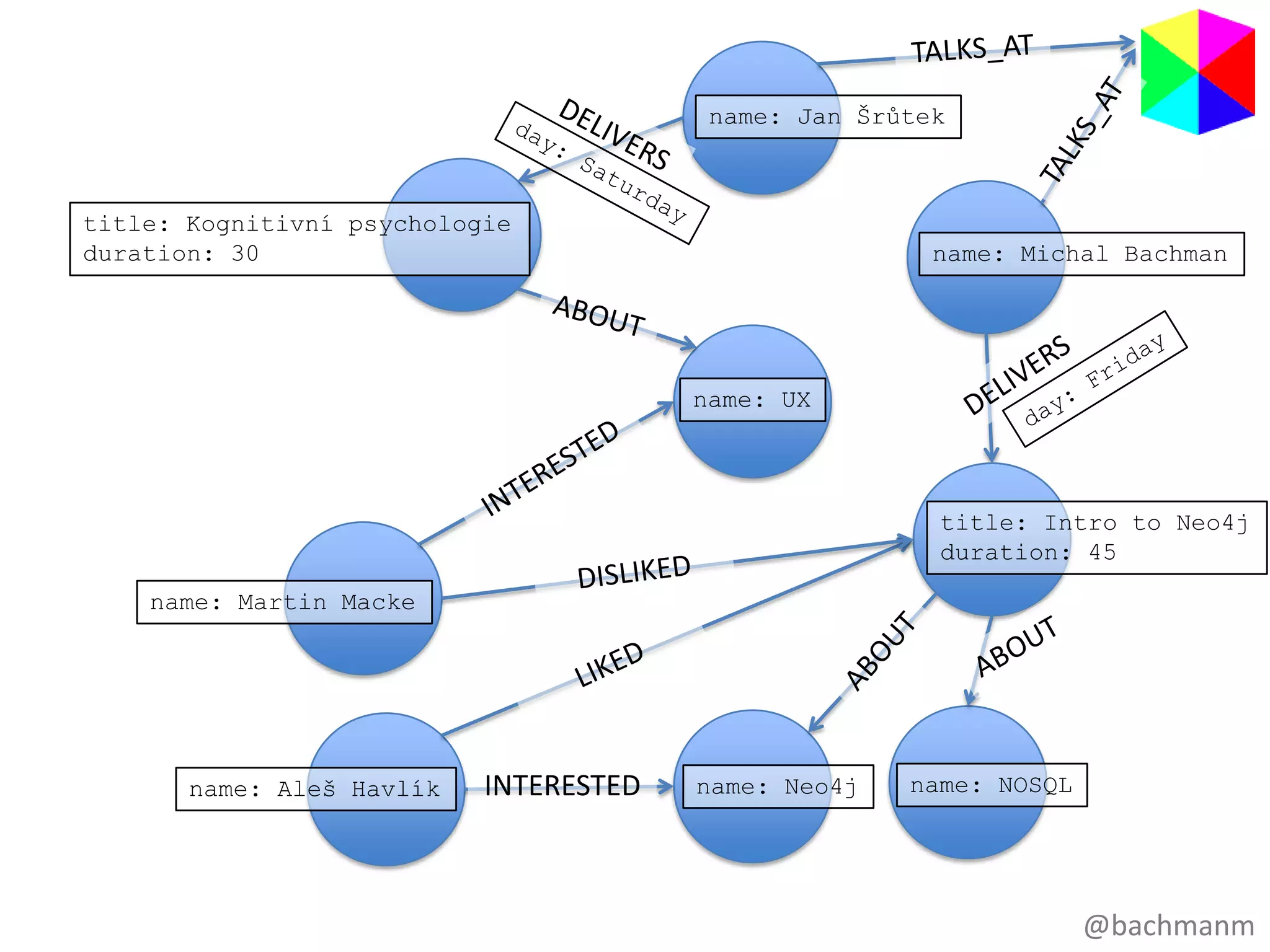
name: Jan Šrůtek
title:Kognitivní psychologie
duration: 30 name: Michal Bachman
name: UX
title: Intro to Neo4j
duration: 45
name: Martin Macke
name: Aleš Havlík INTERESTED name: Neo4j name: NOSQL
@bachmanm
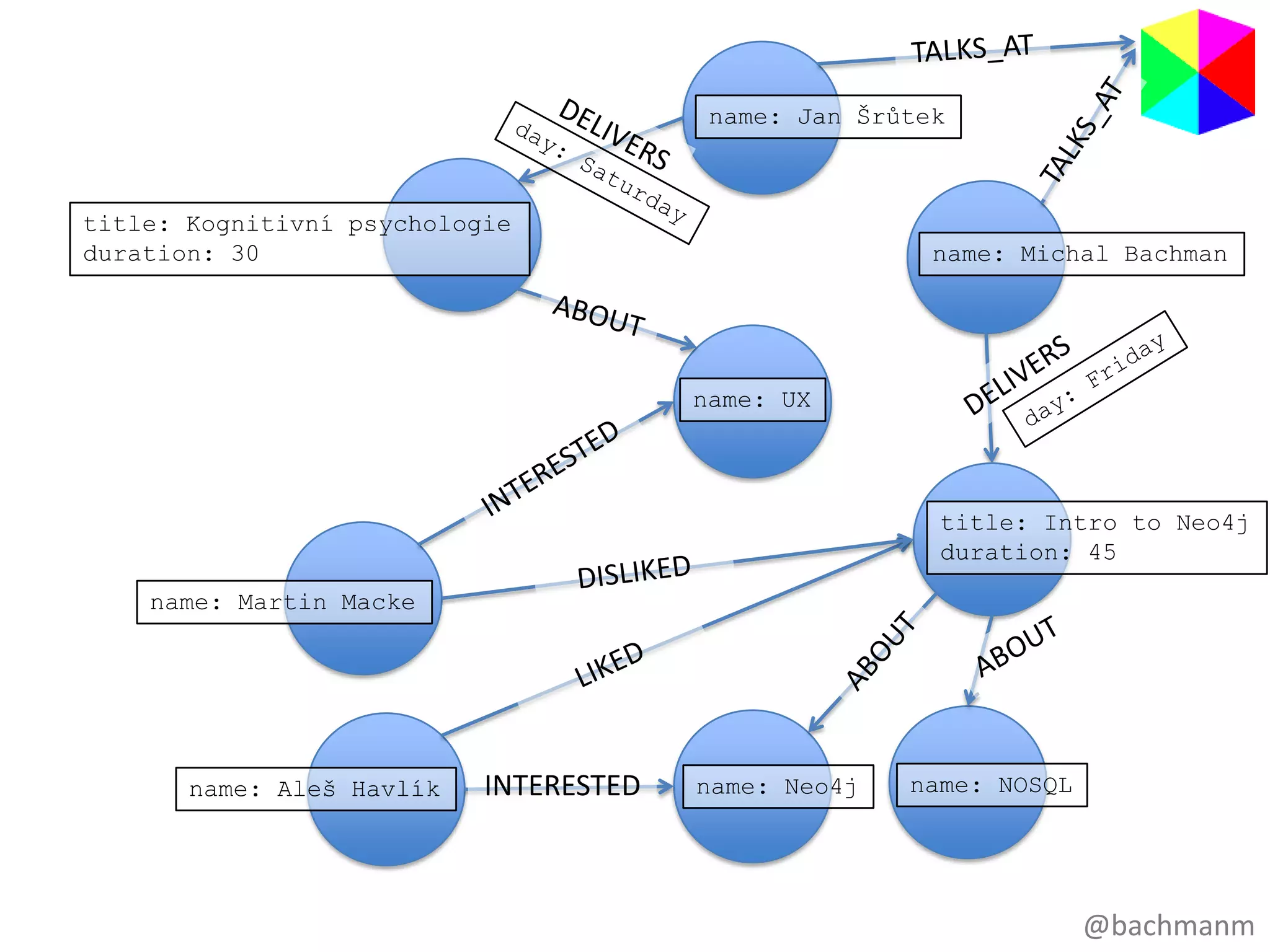
name: Jan Šrůtek
title:Kognitivní psychologie
duration: 30 name: Michal Bachman
name: UX
title: Intro to Neo4j
duration: 45
name: Martin Macke
name: Aleš Havlík INTERESTED name: Neo4j name: NOSQL
@bachmanm
43.
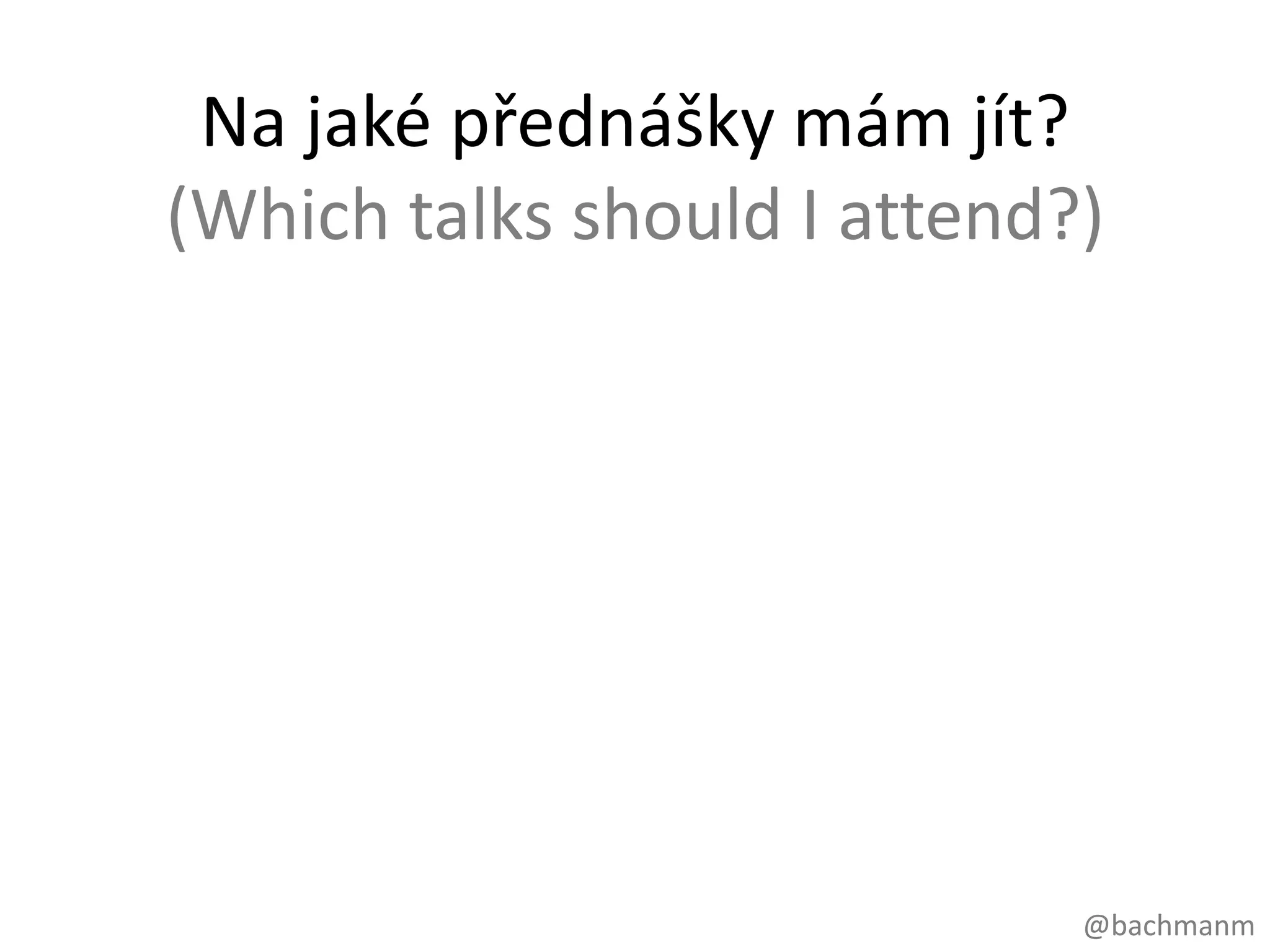
Na jaké přednáškymám jít?
TraversalDescription talksTraversal = Traversal.description()
.uniqueness(Uniqueness.NONE)
.breadthFirst()
.relationships(INTERESTED, OUTGOING)
.relationships(ABOUT, INCOMING)
.evaluator(Evaluators.atDepth(2));
Node attendee =
neo.index().forNodes("people").get("name", ”Aleš Havlík").getSingle();
Iterable<Node> talks = talksTraversal.traverse(attendee).nodes();
//iterate over talks and print
------------------------------------------
Suggesting talks for 100 random attendees.
...
Aneta Lebedová: Co nezměříš, nezměníš!, Do ameriky, The real me. Took: 1 ms
Bohumír Kubát: Beyond the polar bear, Jak (ne)dělat api, Critical interface design. Took: 1 ms
Vladimír Valeš: Vývoj aplikací pro windows 8 metro. Took: 1 ms
Suggested talks for 100 random attendees in 449 ms
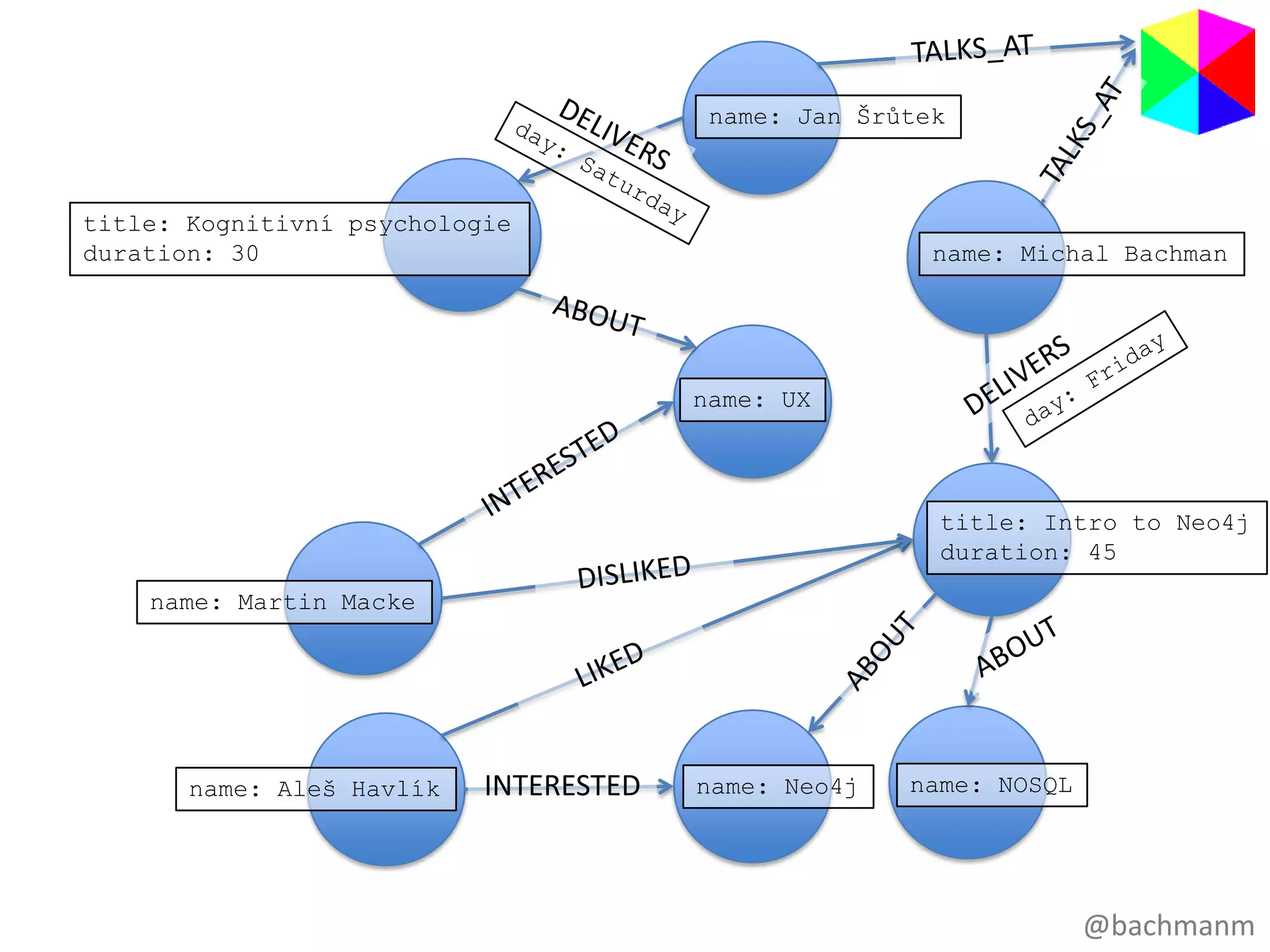
name: Jan Šrůtek
title:Kognitivní psychologie
duration: 30 name: Michal Bachman
name: UX
title: Intro to Neo4j
duration: 45
name: Martin Macke
name: Aleš Havlík INTERESTED name: Neo4j name: NOSQL
@bachmanm
46.
Co máme společného?
//retrieve attendeeOne and attendeeTwo from index
int maxDepth = 2;
Iterable<Path> paths = GraphAlgoFactory
.allPaths(Traversal.expanderForAllTypes(), maxDepth)
.findAllPaths(attendeeOne, attendeeTwo);
for (Path path : paths) {
//print it
}
------------------------------------------------------------
Finding things in common for 100 random couples of attendees
...
Karel Kunc and Aleš Matějka:
(Karel Kunc)--[INTERESTED]-->(ux)<--[INTERESTED]--(Aleš Matějka),
(Karel Kunc)--[DISLIKED]-->(Buď punkový konzument!)<--[DISLIKED]--(Aleš Matějka),
(Karel Kunc)--[DISLIKED]-->(Beyond the polar bear)<--[LIKED]--(Aleš Matějka),
(Karel Kunc)--[LIKED]-->(Shipito.com - podnikání v usa)<--[LIKED]--(Aleš Matějka).
Took: 0 ms.
...
Found things in common for 100 random couples of attendees in 142 ms.
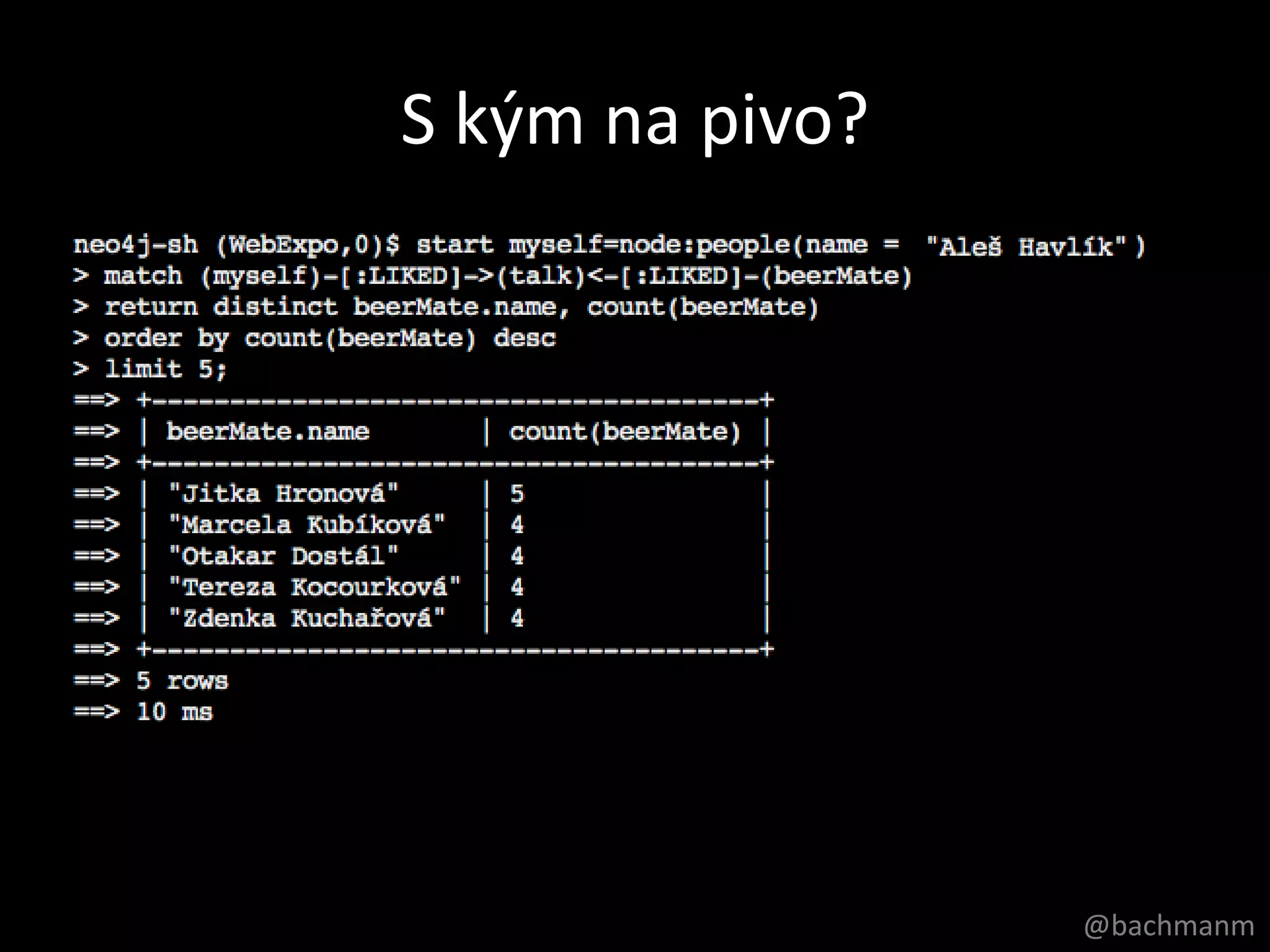
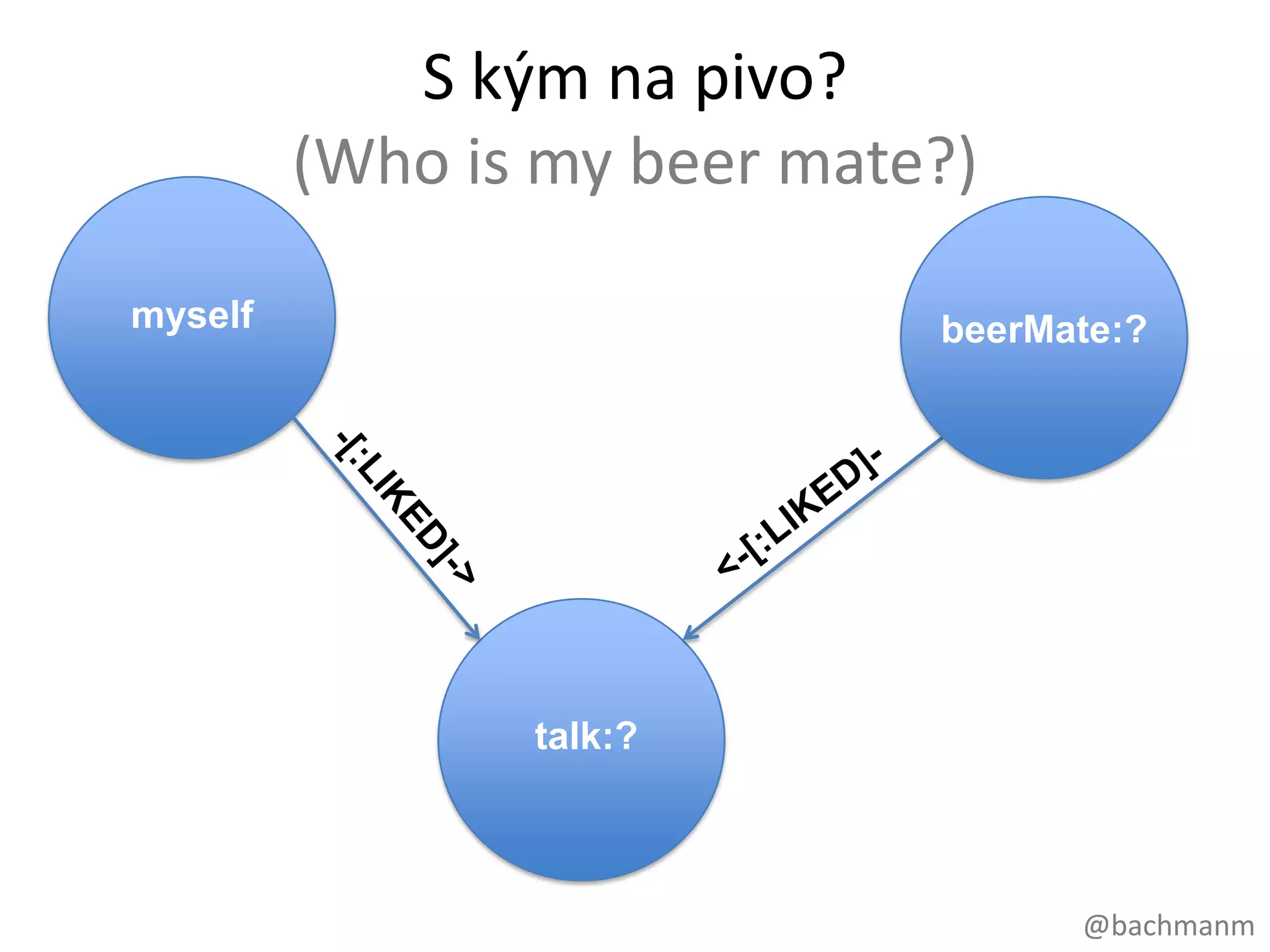
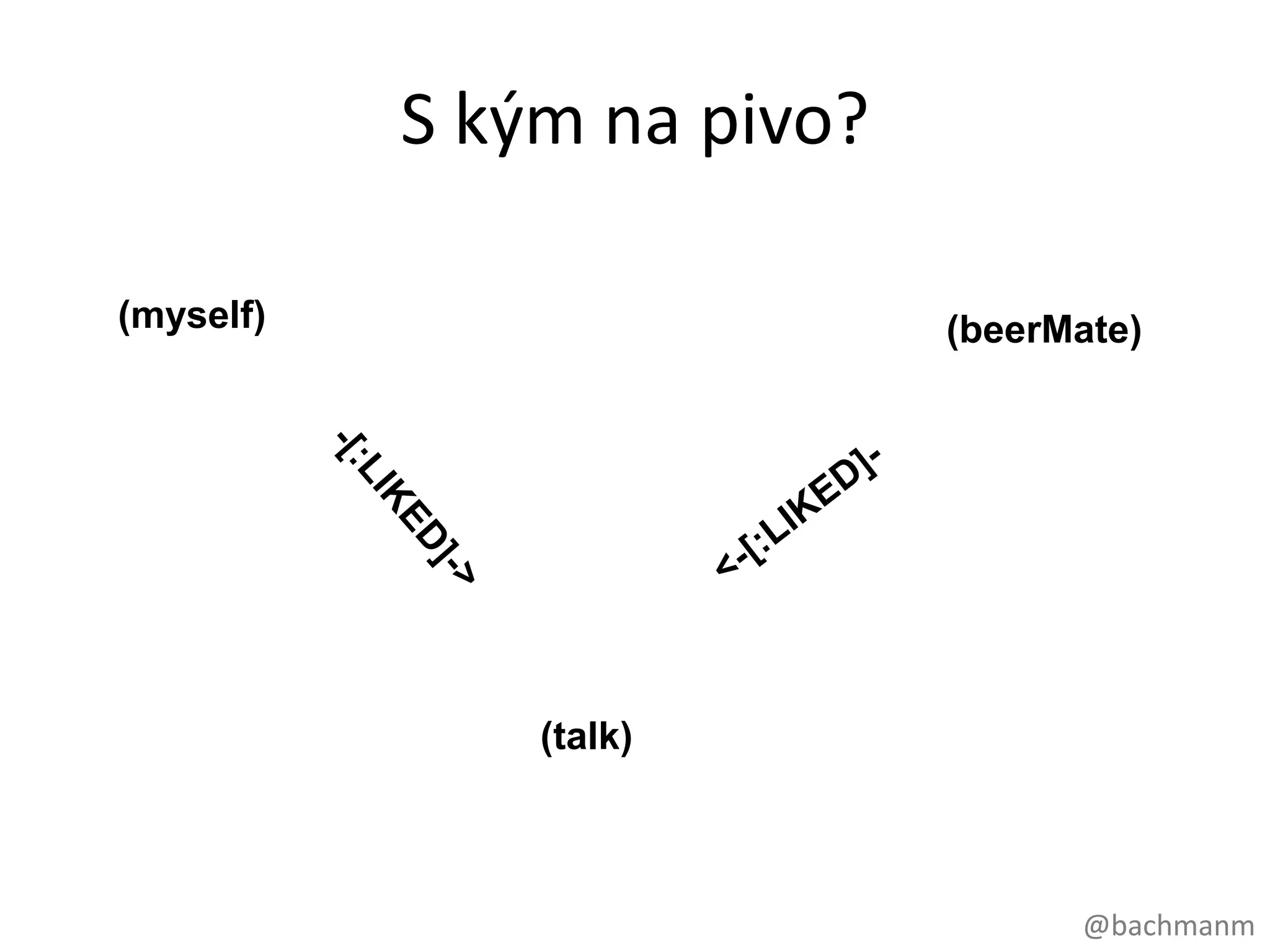
S kým napivo?
(Who is my beer mate?)
myself beerMate:?
talk:?
@bachmanm
49.
S kým napivo?
(myself) (beerMate)
(talk)
@bachmanm
50.
S kým napivo?
start myself=node:people(name = "Emil Votruba")
match (myself)-[:LIKED]->(talk)<-[:LIKED]-(beerMate)
return distinct beerMate.name, count(beerMate)
order by count(beerMate) desc
limit 5;
@bachmanm
51.
Cypher Query
start myself=node:people(name= ”Aleš Havlík")
match (myself)-[:LIKED]->(talk)<-[:LIKED]-(beerMate)
return distinct beerMate.name, count(beerMate)
order by count(beerMate) desc
limit 5;
@bachmanm
52.
Cypher Query
start myself=node:people(name= ”Aleš Havlík")
match (myself)-[:LIKED]->()<-[:LIKED]-(beerMate)
return distinct beerMate.name, count(beerMate)
order by count(beerMate) desc
limit 5;
@bachmanm
Novinky a budoucnost
•Verze 1.8.RC1 vydána tento měsíc
• Cypher dotazy mohou zapisovat do grafu
– CREATE, SET, DELETE, …
• “Labels” pro vrcholy (1.9?)
• Zaměření na škálovatelnost a shardování
@bachmanm
55.
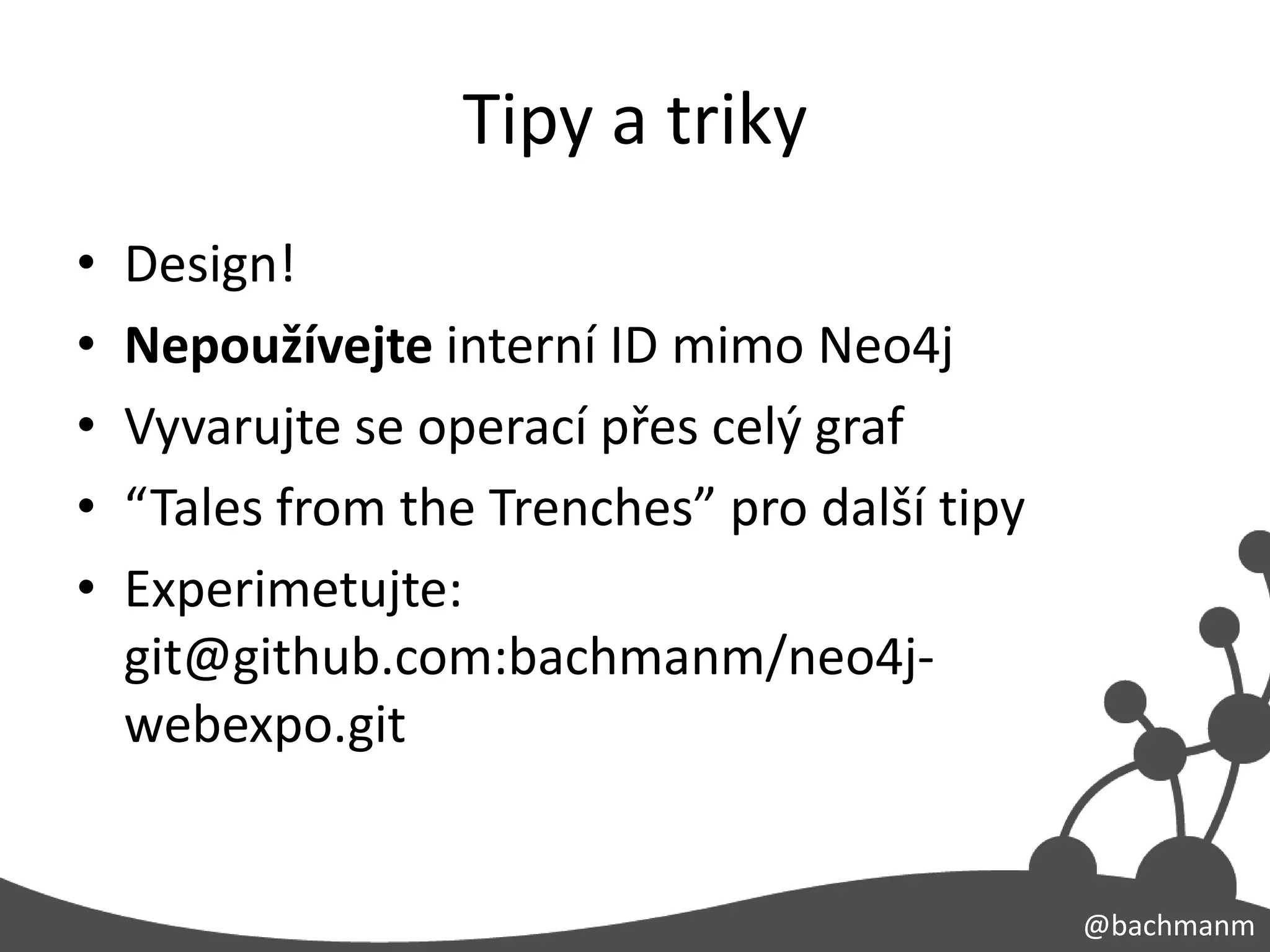
Tipy a triky
• Design!
• Nepoužívejte interní ID mimo Neo4j
• Vyvarujte se operací přes celý graf
• “Tales from the Trenches” pro další tipy
• Experimetujte:
git@github.com:bachmanm/neo4j-
webexpo.git
@bachmanm
56.
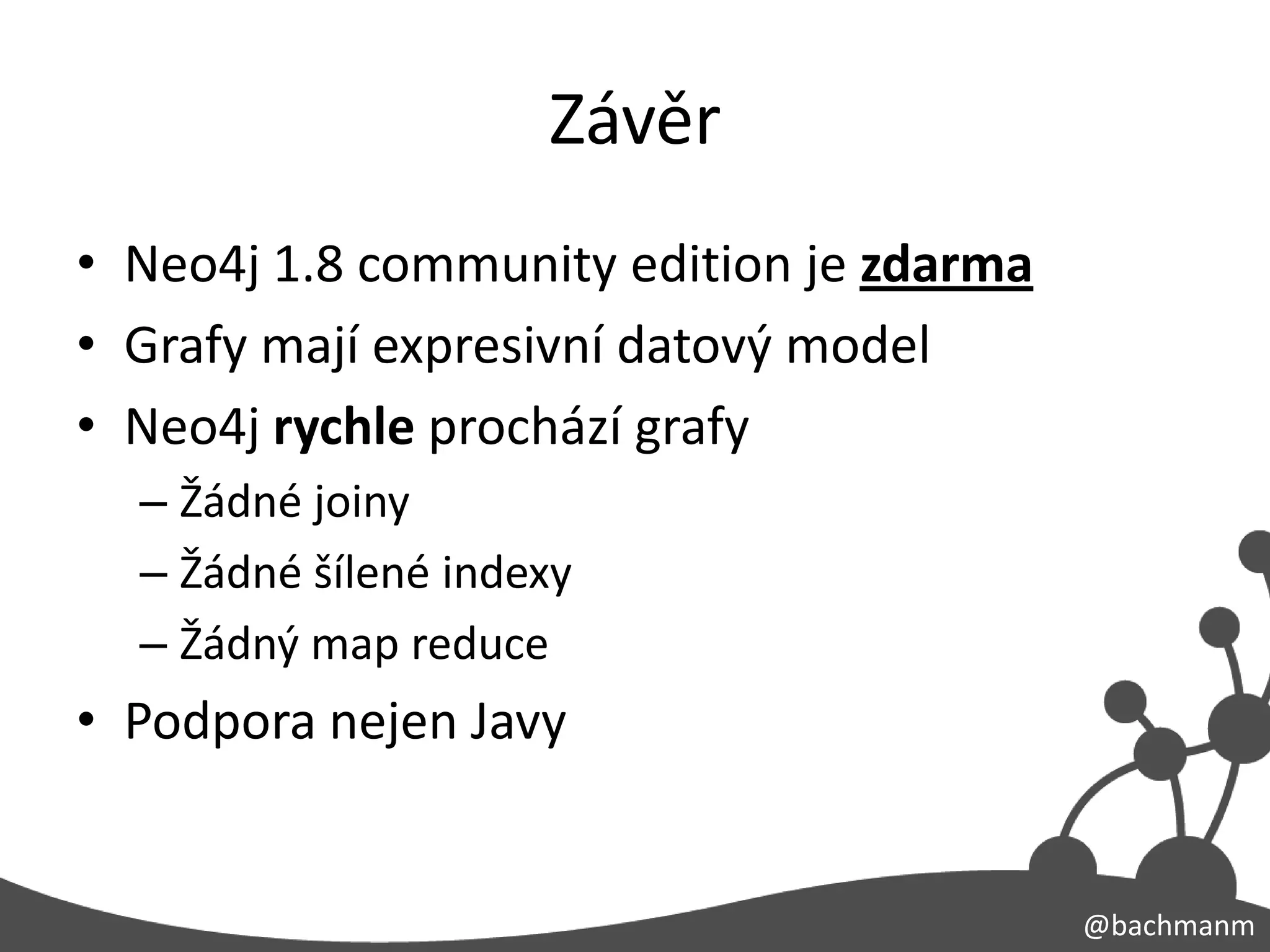
Závěr
• Neo4j 1.8community edition je zdarma
• Grafy mají expresivní datový model
• Neo4j rychle prochází grafy
– Žádné joiny
– Žádné šílené indexy
– Žádný map reduce
• Podpora nejen Javy
@bachmanm
#2 VitejteDobrý den, jájsem Michal Bachman a rádbychdnespředstavil open-source grafovoudatabázi Neo4J a podělil se s Vámi o některézkušenosti s jejímpoužívánímZeptat se, koliklidíslyšelo o grafovýchdatabázích, kdo je používáExistujeněkolikgrafovýchdatabází (OrientDB, AllegroGraph) a my se dneszaměřímenanejpopulárnější z nich, která se jmenuje Neo4J. Jápracuju v Londýnějakokonzultant pro firmu OpenCredo, která je blízkýmpartneremŠvédsko-Americkéfirmy Neo Technology. Neo Technology je firma, kterástojízavývojem Neo4J.Bylo by těžkémluvit o Neo4J, anižbychommělijasnoupředstavu, kamzapadá v celkemnepřehlednémsvětě NOSQL technologií, takženejdříverychlezrekapitulujeme NOSQL.Potompředstavímgrafovédatabáze a Neo4j.Následujepraktickáčást, kdesiukážem, jakpracovat s daty v Neo4j.Jápoužívám Neo4J naopravdovýchprojektech pro klientybezpřestávky od října 2011, čilitéměřrok, a tak se v závěrečnéčástiprezentacepřednáškypodělím o některédůležitézkušenosti z tohotoobdobí. To budedoufámužitečnézejména pro těchpárjedinců, kteří se přihlásilijakosoučasníuživateléčity, kteří o používání Neo4J vážněuvažují.Nakonec se podívámena to, co násčeká v příštíchdnech, měsících a letechBudu se snažitnazávěrnechatdostatekprostorunaotázky----- Meeting Notes (20/09/2012 15:25) -----kdo se nehlasil, nebojte, prednaska je urcena hlavne Vamale i na zkusene a pokrocile dojde, na zaver se podivame na tipy a triky
#3 Slychamehodne, nezdrzovatdlouhoProc ted? Neprobudili,rel DB jsou OK naspoustuproblemuExistuji trendy, kteredaly NOSQL zivot, 4 pripomenuNOSQL je trend, o kterémslýchámehodně, takže se u nějnebuduzdržovatpřílišdlouho. Nicménědatabáze, o kterébudememluvit je s tímtotrendemspojen a tak je důležitéudělatsiobrázek o tom, kamvesvětě NOSQL Neo4j zapadá. V prvnířaděbychrádzdůratnil, žejsemjedním z těch, kteřísivykládají NOSQL jako NOSQL, ne NoSQL a takhlemyšlenka se v tétopřednášceještěněkolikrátobjeví.Pročprávěteď?Není to proto, žejsme se všichnijeden den ránoprobudili a řeklisi, žerelačnímodely a databázejsounuda a proto musímepřijít s něčímvíc cool. Relačnídatabázenejsoutotižvůbecšpatnávěc, naopak. Existujespoustadobrýchproduktůpostavenýchnarelačníchdatabázích a spoustaskvělých, nabušenýchwebových, desktopovýchimobilníchaplikací a systémů, kterétytoproduktypoužívají. Zatěchněkolikdesítek let, co jsourelačnídatabázenasvětějsmejimsvěřiliobrovskákvanta dat. Ale v našemoboruexitujíurčité trendy, kterédalytomuto NOSQL hnutíživot. Vybraljsem 4, kterébychrádkrátcepřipomenul.
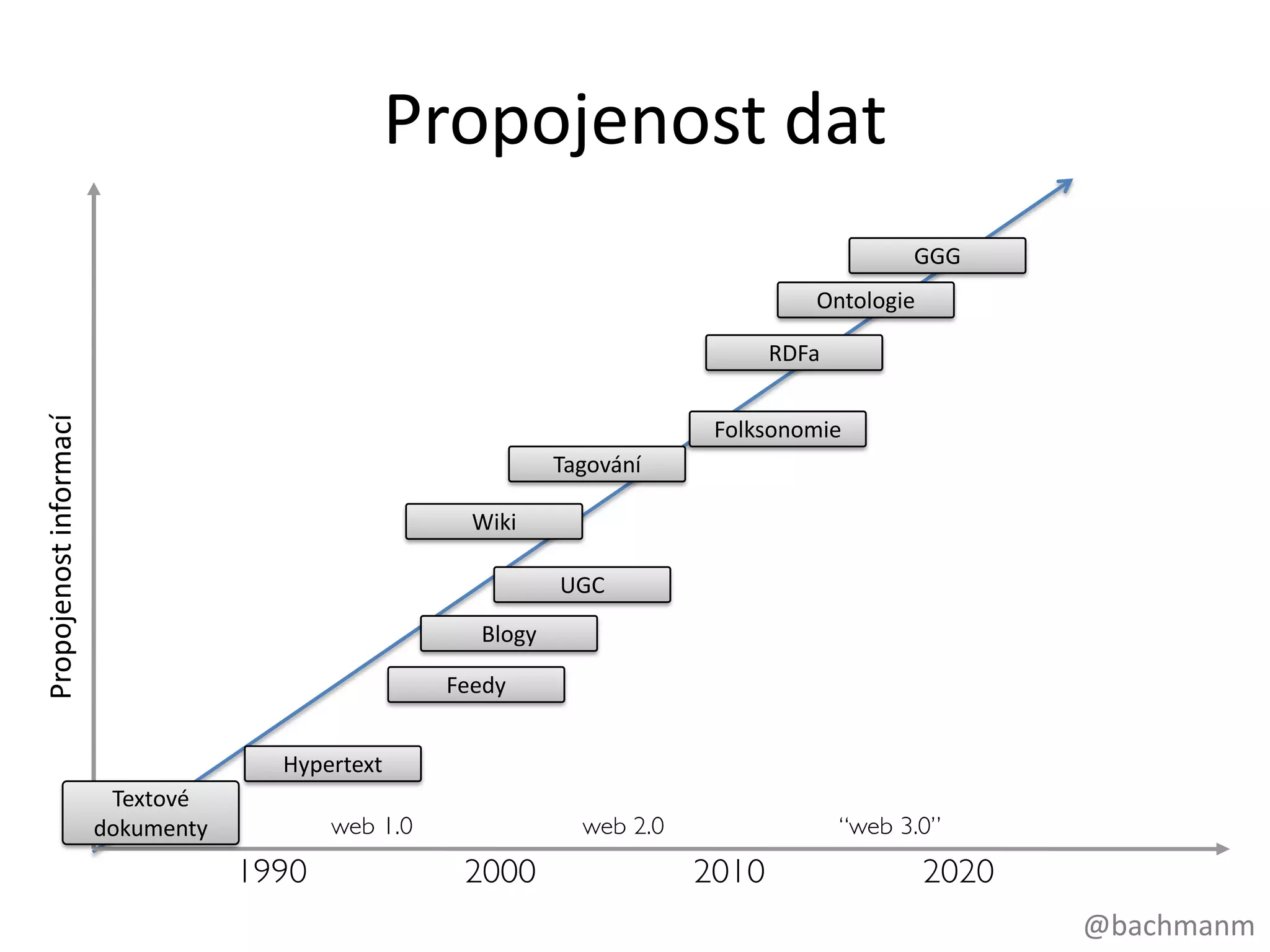
#4 Jendím z nichjsoudnodušeobjemydat, kterélidstvogenruje, zpracovává a ukládá. Ukazuje se, že pro tradičnírelačnídatabáze je velikostdat, se kteroudnespracujeme, stálevětší a většíproblém.
#5 Srostoucímobjememdatroste I propojenost/složitost/komplexitadatUGC = User Generated ContentGGG = Giant Global Graph (what the web will become) – každýkousíček, každájednotkazajímavýchdat je sémantickypropojená s každoudalšízajímavoujednotkoudat (Tim Berners-Lee)Data jsoupropojenější (lineárně)RDFa (Resource Description Framework in attributes), českysystémpopisuzdrojů v atributech, je technologie pro přenosstrukturovanýchinformacíuvnitřwebovýchstránek. RDFa je jedenzezpůsobůzápisu (serializace) datovéhoformátu Resource Description Framework (RDF). Ontologie je v informaticevýslovný (explicitní) a formalizovanýpopisurčitéproblematiky. Je to formální a deklarativníreprezentace, kteráobsahujeglosář (definicipojmů) a tezaurus (definicivztahůmezijednotlivýmipojmy). Ontologie je slovníkem, kterýslouží k uchovávání a předáváníznalostitýkající se určitéproblematiky.
#6 Data majívětšíobjem, jsoupropojenější a ztácenípředpovídatelnoustrukturuDochází k Individualizaci dat. Přestávábýtjednoduchézařaditkaždéhojedince do škatulkypodlepřesněnadefinovanýchkritérií, chci, abymoje data byla o mě.Tvardat se mění, dá se dalekohůřpředpovídatjejichstrukturaVlastnímodelyceléhosvětaVíceinformací o každémsubjektuDecentralizacetvorbyobsahu trend zrychluje
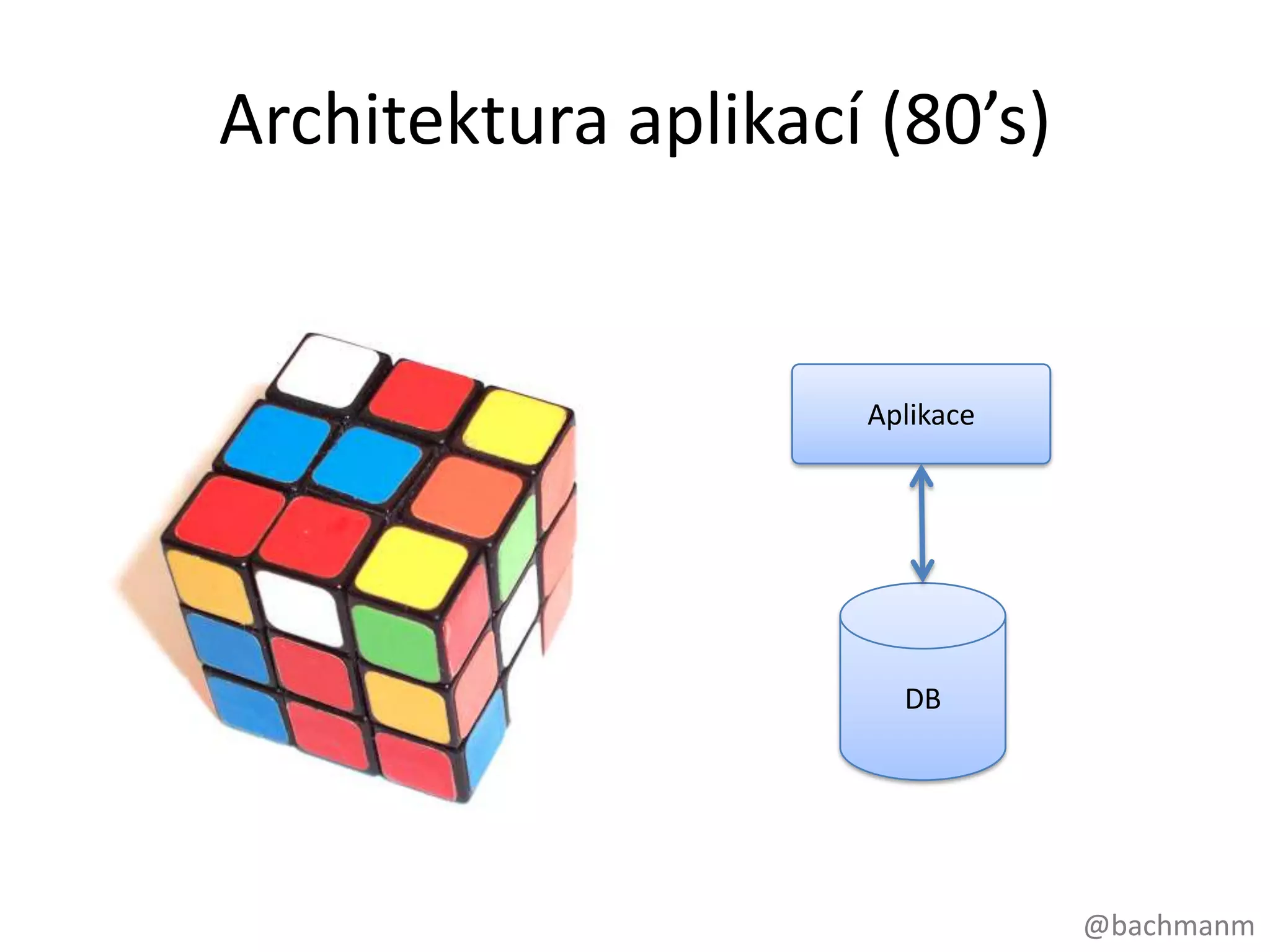
#7 Dalšímtrendem je to, jakstavíme software,neboliarchitekturaaplikací. Typickáaplikace 80. let vypadalaasitakhle.
#9 No a v 21. století, aťuž ten trendnazívámecloudemnebo ne, směřujeme k rozkouskovánítěchtradičníchmonolytickýchaplikacínamenší, samostatné, mezisebouintegrovanémikroaplikace.Poznamenatžeteďmůžeme pro každou z aplikacízvolitdatabázi, kterátukonkrétníaplikacidávásmysl. REST, hypermedia, composite micro-appsClarify
#10 Ale mimochodem, promnohověcíjsourelačnídatabázestálenaprosto v pořádku. Seznamzaměstnancůnapřiklad, data kterápřirozeněvypadajíjakotabulkypatřínaprostologicky do relačnídatabáze.Pro spoustuwebovýchaplikací, dokonce pro webovéaplikacekteréjsouveřejněpřístupné.Ale v momentě, kdy se začnemepohybovatdopravapoose X do prostoru, kde se komplexitadatzvětšuje, data jsoupropojenější a propojenější a objemná, relačnídatabázepřestávajíbýttímsprávnýmřešením.BTW: komplexita = funkceobjemu, propojenosti a strukturydatTakže: pro transakčnízpracovánítabulárníchdat a pro menšíwebovéaplikace, relačnídatabáze je OK! Pro jinýtypdatsimusímevybratjiné NOSQL řešení.This is strictly about connected data – joins kill performance there.No bashing of RDBMS performance for tabular transaction processingGreen line denotes “zone of SQL adequacy”
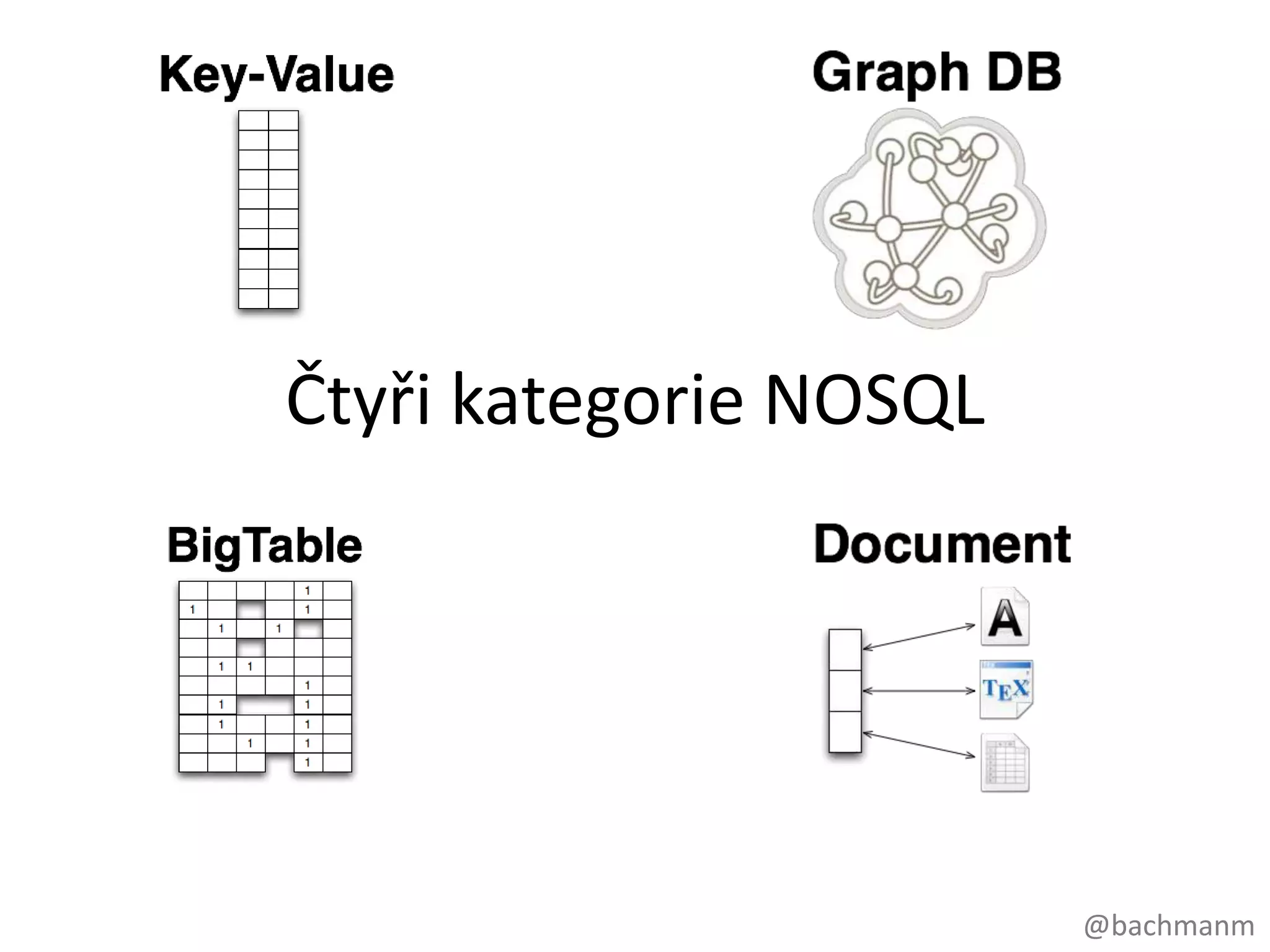
#11 Krásavesvětě NOSQL - nikdovámnepřikazuje, vybratdatabázi, kteráodpovídátypučicharakteristicedat, se kterýmipracujete. key-value databáze: jedenklíč - jednahodnota, hash mapy, Redis, Riak (Amazon Dynamo), Většinouvysocetolerantnívůčivýpadkům, Jednoduchýdatový model, Vynikajícíhorizontálníškálovatelnost, Dostupnost, BigTabledatabáze: k-vvvvvvv store s implicitnímiindexy, Cassandra (Google), PodporačástečněstrukturovanýchdatAutomatický index (sloupce), Dobráhorizontálníškálovatelnost, opětnevhodné pro propojená dataDokumentovédatabáze, známá je například subversion, MongoDB, CouchDB, …Kolekcedokumentů, Dokument je kolekce key-value párů, Index je důležitý, hodně map-reduce,Škálovatelnostcelkemdobrá. (Ne takjako key-value, složitějšímdatovýmmodelem, Jednoduchý a výkonýdatový model, jako subversion.Nevýhodouvšech 3 je nejsouúplněvhodné pro hustěpropojená data. Přílišjednoduchýdatový (HashMap, rychlá, ale…) model znamená, žechceme-li získatjakékolivokamžitéhlubšíporozuměníuloženýmdatům. Musí to býtzodpovědnostíaplikačnívrstvy (čili to musímenějaknaprogramovat). Velmičastojsoutedytytodatabázespojeny s frameworkyjako Map-Reduce, pro kterémusímevytvořitúlohy, kterénámtotoporozuměníumožnízískat.Map-reduce je dávkováoperace (to bychuvedl v kontrastu s on-line / in-the-click-stream synchronníoperací), abystezískalipohlednavašepropojená data.Všechny 3 pracují s agregovanýmidaty, tzn. Ževyžadujístruktutupředem, data, kterápatřílogicky k sobě (jakoobjednávka a jejíjednotlivépoložky), jsou v databáziuloženy u sebe a je k nimtaké v dotazechpřistupovánojako k celku. V key-value úložištích je tímcelkemhodnota, v CF CF a v Dok. Dbsdokumenty.OKvpřípadech, kdypřístup k datůmvyžadujepřesnětutostrukturu. Pokud se ale chcemena data podívatjinak, napříkladanalyzovat z objednávekcelkovéprodejejednotlivýchproduktů, musíme s toustrukturoutrochubojovat a to je ten důvod, proč se tolikmluví o map-reduce vespojení s těmitodatabázemi. Výhodouukládánídat v neagregovanýchformách je to, že se dajíanalyzovat a prezentovat z různáchúhlůpohledy v závislotinakonkrétnímpřípadě.A samozřejměgrafovédatabáze, kvůlikterýmtudnesjsme a o kterých se tohodozvíme o něcovíczaminutku
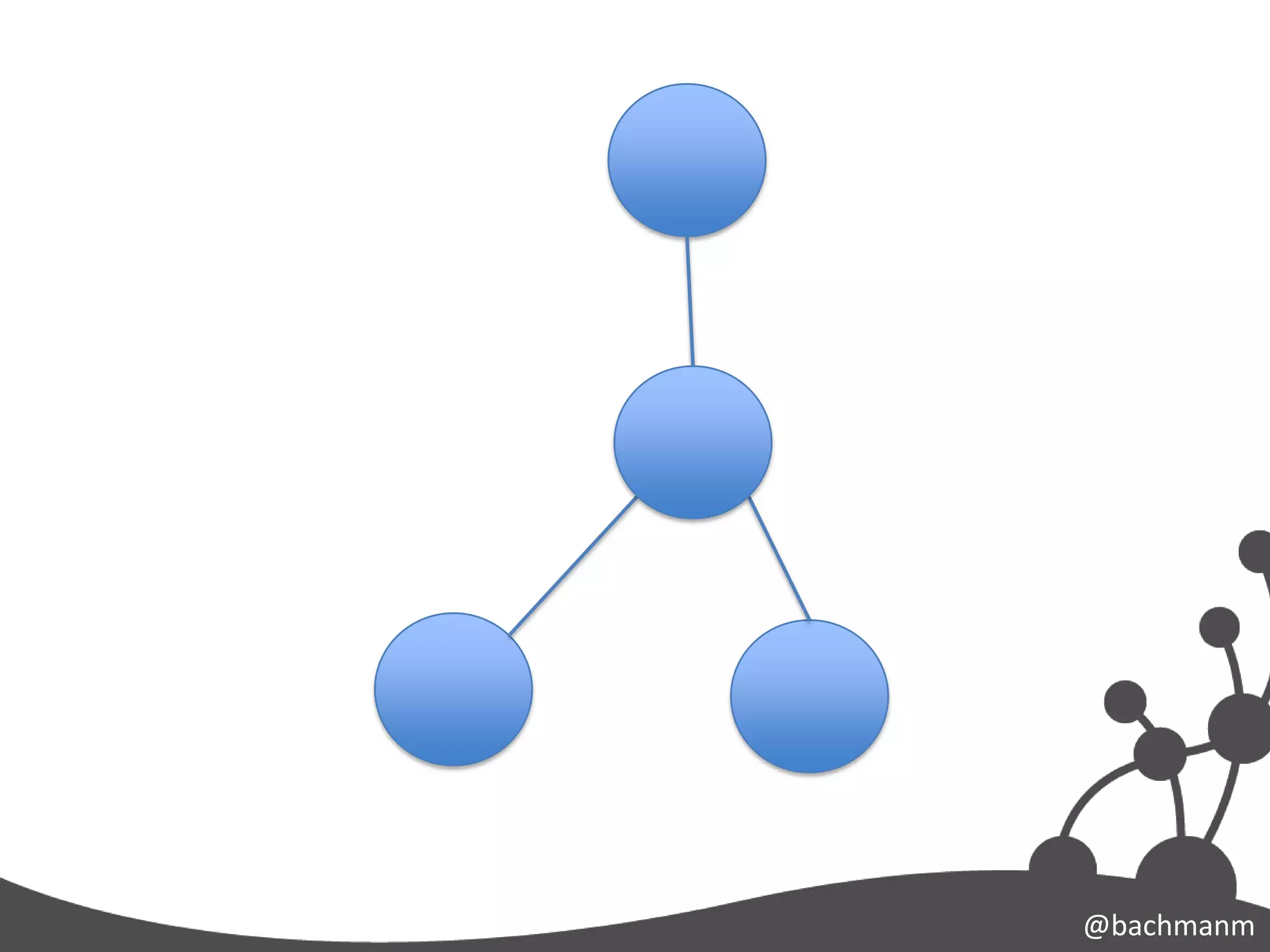
#12 Od teď se konečněbudemebavit o grafovýchdatabázích. Co to jsoutygrafy? V žádnémpřípadě se nejedná o grafnaobrázku, ale o bavíme se o grafech v matematickémslovasmyslu. Udělejmesitedykratičkouodbočku do teoriegrafů, nebojte se, žádnámatematikaVásnečeká
#13 Teoriegrafůzkoumávlastnostistruktur, zvanýchgrafy. Ty jsoutvořenyvrcholy, kteréjsouvzájemněspojenéhranami. Znázorňuje se obvyklejakomnožinabodůspojenýchčárami. Formálně je grafuspořádanoudvojicímnožinyvrcholů V a množinyhran E.
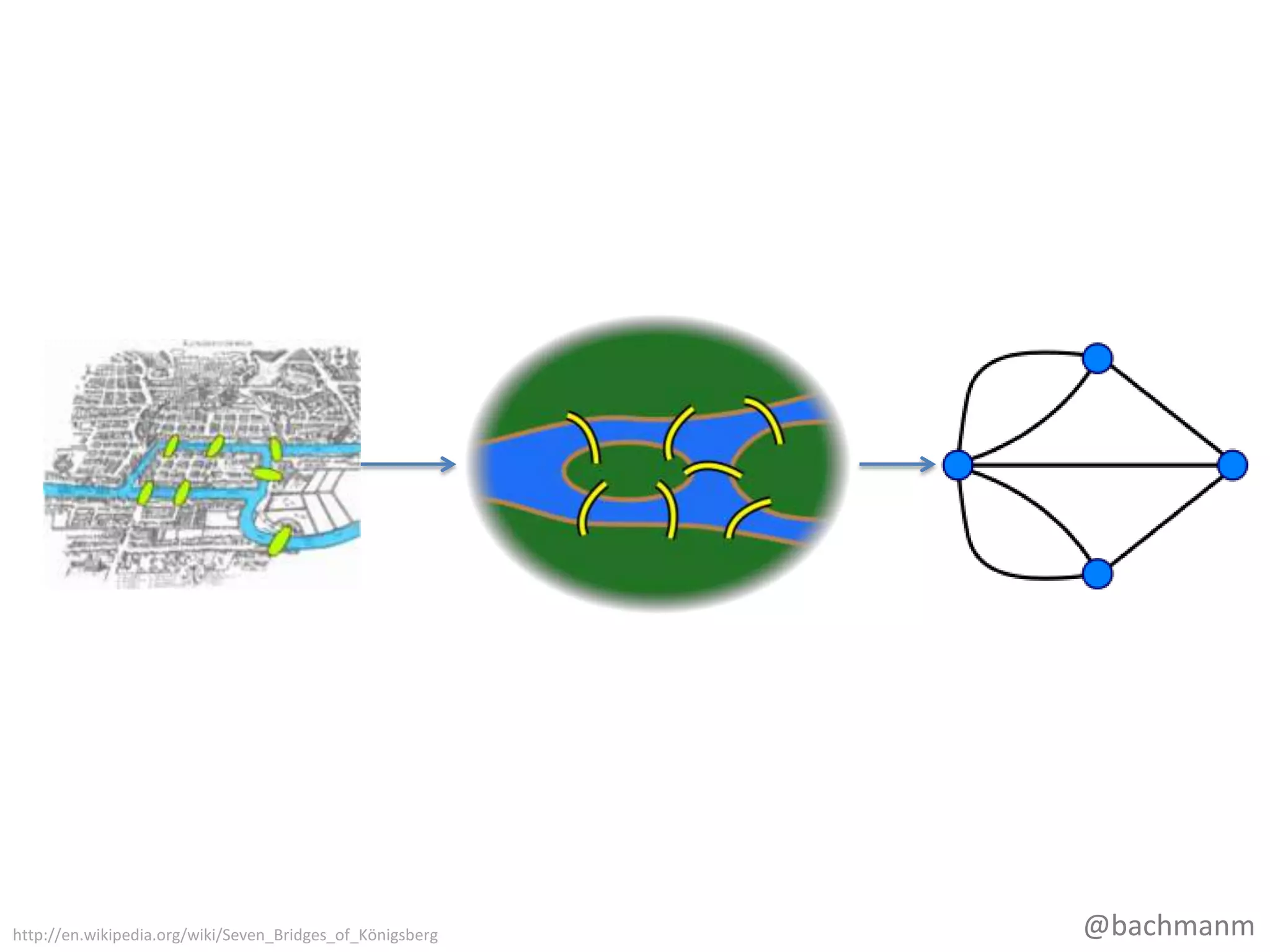
#14 Tradičně se zazakladateleteoriegrafůpovažuješvýcarskýmatematik Leonhard Euler, kterýroku 1736 řešilúlohu, jakprojítpřessedmmostů v Královci (každý z nichprávějednou) a vrátit se do výchozíhomísta. To v moderníteoriiodpovídápojmueulerovskýgraf.
#15 SedmmostůměstaKrálovce (dnes Kaliningrad)Kdodělá pro velkoufirmu, tímmyslímněkolikvrstevmanagementu, softwarovýarchitektnajinémpatřenežvývojářiTatoinformace je pro Vás, v těchtofirmáchbývátěžképrosadit “nové” technologie. Ale relační model, se kterýmpřišel E.F. Codd v roce 1969, je pouze 43 let starý. Grafový model je 276 starý. TakžepříštěažVámšéfnebochytrýarchitektřeknenaadopci NOSQL něcovesmyslu “tadypoužívámejenomzralé a prokázanévyspělétechnologie”, víte, kterýmsměrem ho máteposlat… tímmámnamyslitřebatutopřednáškunawebunebopříslušnéstránkynawikipedii. Takžejakukládáme data v grafu…
#16 Takžejakukládáme data v grafu…V grafuukládámedata jakovrcholy a vrcholyjsouvlastnědokumenty, kterémodoumítlibovolnéklíče a k nimpřiřazenéhodnoty. Stejnějakodokument v MongoDB. V čem se grafliší od MongoDB je že v grafujsouvztahymezivrcholy. A to je trade-off, MongoDB je lépeškálovatelné, protožetohlenedělá. Neo4J je lepší pro propojená data, tohledělá. Ukládávztahymezijednotlivýmivrcholy. Ale nenítakdobřeškálovatelné. A do musímevzít v potazpřiřešeníVašichproblémů: chcetemasivníškálovatelnost, nebookamžitýnáhled do propojenostiVašich dat. POPSAT GRAFVztahymajisemantickyvyznam! Recnici, prednasky v RDBMSJe to poměrněintuitivnízpůsobukládánídat! Úkolgrafovédatabáze je vzíttatointuitivní data, kterásimůžemejednodušenačrtnoutnatabulinebokuspapíru a rychle je procházetvevašichprogramech.
#17 Sílatohotomodeluspočívá v tom, že je velicedobrý pro hustěpropojená (komplexní – objem, propojenost, struktura) data. Vrcholy a hranyzprostředkovávajípřirozený index a umožňujíokamžitýnáhled do vztahůmezivěcmi.Jsoutakyvelicerychlé v procházení / traversování, což je většinouveliceobtížné v relačníchdatabázích, protože je zapotřebíjoinovattabulky.Na druhoustranu je extréměobtížnéškálovatgrafstějnějakotřeba K-V úložiště, protožegrafyjsouproměnlivé, dynamické, neustále se mění. Některégrafy se shardovatdají, ale pro některé je nemožnédosáhnoutstejnéškálovatelnostishardováním, jakotřeba u dokumentovýchdatabází.
#18 Grafovédatabázejsounaprostoskvělé v některýchsituacích. Tady je malý experiment.Popsat experiment
#20 Protože Neo4J a ostatnínativnígrafovédatabázenetrpí JOIN problémemrelačníchdatabází, nemusíjoinovattabulky, tak ten výkonzůstanena 2ms i pro miliardulidí. V relačníchdatabázíchbudoujoinynavětších a většíchsadáchdatpomalejší a pomalejší.
#21 Na jakétypyproblémůjsougrafydobré? Spoustadalšíchproblémů… pro kterébystesipředtoutopřednáškoumožnázvolilirelačnídatabázi, ale třebatomubudezítrajinakS Neo4J pracuji v produkčnímnasazeníužpřesrok a úspěšnějsme s nímimplementovalijednupoměrněvelkousociálnísíť s prvkydoporučovacíhosystému, kteráběží v Británii a Americe pro cca 500k uživatelů, Pliny, pivo, playstationfrancouzskoutelekomunikačníspolečnostnaanalýzudopaduporuch v síti (asi 2M vrcholů / nód) a v produkčnímplánováníjednéněmeckéautomobilky.Najednouuvidítegrafyvšude----- Meeting Notes (18/09/2012 17:14) -----zasazeny
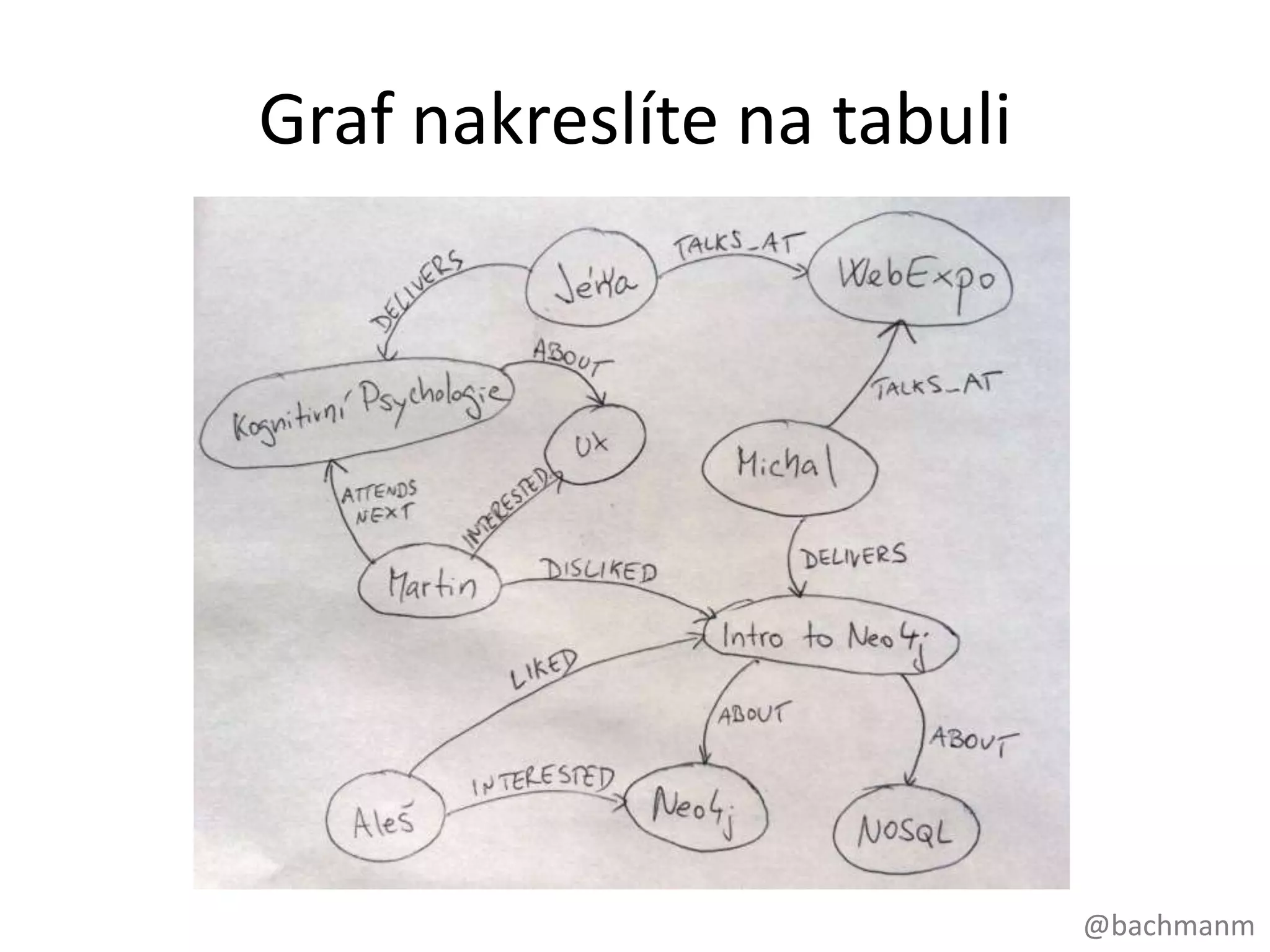
#22 A to je jednahezkávlastnostgrafů – jsouideální pro tabule,zadnístranyobálek, pivníchtácků a krabiček od cigaret… to jsouvěci, nakterýchtynejlepšídesigny (zejménavestartupech) většinouvznikajíJájsemsivybraljakopříkladWebExpo, původnějsemchtělzmapovatkorupčníaféryčeskýchpolitiků, ale tohle je o něconeškodnější. Vztahymeziřečníky, přednáškam, tématy, účastníky a podobněsimůžemenakreslitnapivnítácek! WebExpo je doména,kterámáspoustuvztahů – řečnícimajípřednášky, …To simůžetejednodušenakreslitnatabuli, to je mimochodem to, co dělámejakoprogramátoři, kdyžsedíme s lidmi, kteřípotřebujínějakýkussoftwaru a my se snažímetomu business problému, tédoméněporozumět. Sednemsi k tabuli, nakreslímezákazníky, objednávky, faktury, produkty a podobně a vztahymezinimi!A co udělámepak – vezmemenášpěkný design a denormalizujeme ho. Potíme se vymýšlením, jak to všechnonaládujeme do tabulek. A jsmešťastní a usměvaví, než to zpustímenaživo, do provozu…. A ono to bežíjakželva… Co uděláme? Denormalitzujemenáš model! Všechnaenergie, kteroujsmeinvestovali, krev, pot a slzy, všechno v niveč. U grafovédatabáze, to co je napapíře je přesně to, co naházíte do databáze.
#23 To neznamená,žejsteomluveni s designovéfáze. Pořád se musítehlubocezamysletnadtím, jaké entity (neboobjekty) tvořívašidoménu a jakéjsoumezinimivztahy! Stálepotřebujete design.Nemůžetejednoduševzít data ztabulek, kterámáte a násilím je natřískat do vašízbrusunovégrafovédatabáze. Člověkmusízačítmyslet v nódách a vztazích.Přinavrhovánídatovéhomodelu pro WebExpomusímeudělathodnědesignovýchrozhodnutí: jakodlišitřečníky od účastníků? A je to vůbecpotřeba? Udělatzepátka a sobotynódy, nebojenomvlastnostnajednotlivýchpřednáškách?Stálemusítedělat design, ale pointa je že design datovéhomodelu pro grafovoudatabázimůžebýtpříjemná a přirozenázkušenost.
#24 Stará se proVás o nódy, vztahymezinimi a indexy.Neo4j je stabilní a běží od roku 2003ProcházíaktivnímvývojemPrimárně pro Javu, ale použitelná se spoustoudalšíchtechnologiíIdeální pro škáludesítekserverů v clusteru, ne pro stovkyPro hustěpropojená data, není to KV store
#26 Plně a militantně ACID. Kdoneví, co to znamená?Rychlevysvětlit: atomicity, consistency, isolation, durabilityNěkterédalší NOSQL databáze se vzdávajíněkterýchgarancíveprospěchvýkonu, u Neo4j tohlevypnoutnejde. Data jsouvždyzapsánana disk.
#27 Vyhledatzacatek v indexu (Lucene)Prozkoumavatokoli
#28 Vyhledatzacatek v indexu (Lucene)Prozkoumavatokoli
#29 Neo mázabudovanoucelouknihovnugrafovýchalgoritmů, jakonejkratšícesta, všechnycesty, atp
#30 1m hops zasekundunanormálnímlaptopu, žádnýrozdílpřiznásobenípočtudatHigh performance graph operationsTraverses 1,000,000+ relationships / second on commodity hardware
#31 Obecněpokudpoužíváte MySQL a neplatítezaněj, nebudeteplatitaniza Neo.
#34 Pojďmesikázatpoužití v embedded módunakonkrétnímpříkladu. Vytvořiljsemgraf z webexpa, řečníci a přednáškyjsouopravdové, 1000 účastníkůmánáhodněvygenerovanájména. Popsatgraf a scénář.KdonečteJavuKodbudenagithubu
#35 Vztahymůžoubýtbuďřetězceznaků, neboEnum, kterévámdajívýhodustatickéhotypování v IDE, pro Neo4j v tom nenížádnýrozdíl.Postupopakujemedokudnemámecelýgraf
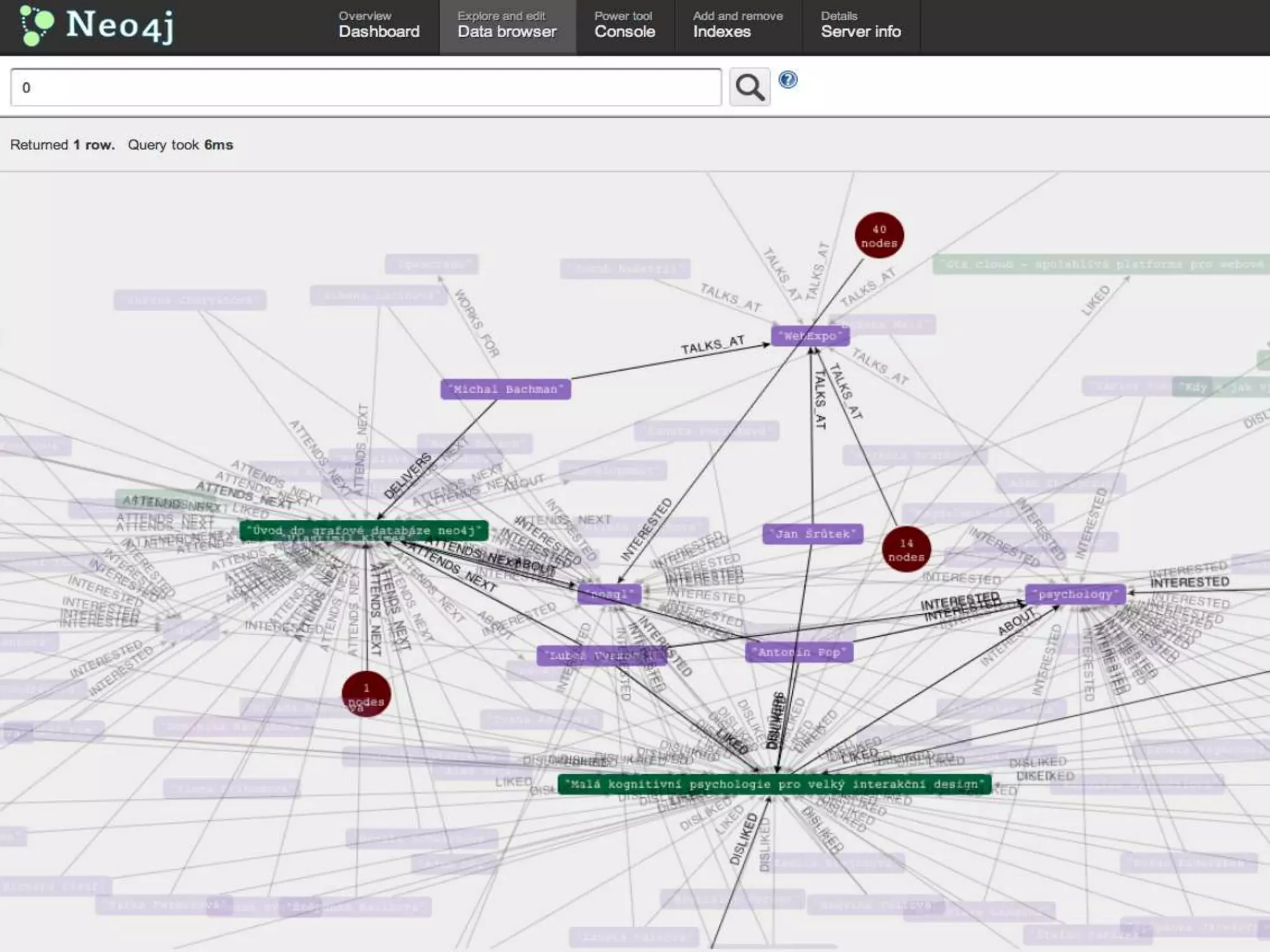
#36 Tohle je screenshot z webovékonzole, kdemůžemegrafvizálněprocházet. Běžínalaptopu, dámVámnakonci URL, abystesi s tímmohlipohrát.Tak, mámegraf, ale jak z nějteďdostaneme data ven?
#37 Existujeněkolikzpůsobů,jakpsátdotazy v Neo4j, liší se čitelností, složitostí, výkonem a úrovníabstrakce. UkážuVámněkterézezpůsobů a začnuodspoda, tzn. On nativníhonejrychlejšího API.
#38 Core API pracujepřímo s jednotkami, kteréjsme do databázeuložili – vrcholy, hrany a jejichvlastnosti.
#40 Podívejme se ještějednounavelýgraf. Novýgrafmávždyjednunódu s ID 0, z téjsmeudělalliWebExpo.
#41 Tohle je imperativní API, všechnupráciděláprogramátor, je nejvýkonnější
#42 Pojďme se podívat o úroveňvýš co se abstrakcetýčenatakzvané traversal API, kterénámumožnípsátdotazydeklarativně, to znamenápopsat, jakchcemegrafprocházet. Samotnéprocházeníudělá Neo4J zanás.
#48 Těžké pro neprogramátory, pojďmě se podívatnaněcojednoduššího
#50 Na nejvyššíúrovniabstrakce Neo4j zprostředkovávásvůjvlastníjazyk pro psanídotazů, částečněinspirovaný SQL. Ten jazyk se jmenuje Cypher a rozumílidskyčitelnýmpříkazům, jakonapříkladtomu, kterýtadyteďvidíte.
#51 Musímenědezačít, napomocsivezmeme index s názvem people, kdenajdemepanaEmilaVotrubupodlejména.Dálemusímeupřesnit, co za data vlastněchcemezískat, v tomtopřípadějménočlověka a skóre, kolikvěcímámespolečnýchNakonecasinechcemejítnapivoúplně se všemi, ale janomřekněme s 5 lidmi, se kterýmitohomámespolečnéhonejvícAsividítevliv SQL----- Meeting Notes (09/09/2012 20:18) -----animace
#52 Musímenědezačít, napomocsivezmeme index s názvem people, kdenajdemepanaEmilaVotrubupodlejména.Dálemusímeupřesnit, co za data vlastněchcemezískat, v tomtopřípadějménočlověka a skóre, kolikvěcímámespolečnýchNakonecasinechcemejítnapivoúplně se všemi, ale janomřekněme s 5 lidmi, se kterýmitohomámespolečnéhonejvícAsividítevliv SQL----- Meeting Notes (09/09/2012 20:18) -----animace
#53 Musímenědezačít, napomocsivezmeme index s názvem people, kdenajdemepanaEmilaVotrubupodlejména.Dálemusímeupřesnit, co za data vlastněchcemezískat, v tomtopřípadějménočlověka a skóre, kolikvěcímámespolečnýchNakonecasinechcemejítnapivoúplně se všemi, ale janomřekněme s 5 lidmi, se kterýmitohomámespolečnéhonejvícAsividítevliv SQL----- Meeting Notes (09/09/2012 20:18) -----animace
#58 Můžemeudělat z relačnídatabáze key-value store, stejnějako z dokumentovédatabázegrafovou, ale proč?NOSQL Vámumožňujevybratsi ten nejvhodnějšídatový model pro konrétníproblém, pakdatabázi, kterátímtomodelemdisponuje.Vybíratdatabázi (a jakoukolivjinoutechnologii) rozumně a pragmaticky je poslednírada, se kteroubych se s Vámirádrozloučil.
#59 Odkaznaslajdy dam na twitterCastokladenouotazkou

























![Co máme společného?
//retrieve attendeeOne and attendeeTwo from index
int maxDepth = 2;
Iterable<Path> paths = GraphAlgoFactory
.allPaths(Traversal.expanderForAllTypes(), maxDepth)
.findAllPaths(attendeeOne, attendeeTwo);
for (Path path : paths) {
//print it
}
------------------------------------------------------------
Finding things in common for 100 random couples of attendees
...
Karel Kunc and Aleš Matějka:
(Karel Kunc)--[INTERESTED]-->(ux)<--[INTERESTED]--(Aleš Matějka),
(Karel Kunc)--[DISLIKED]-->(Buď punkový konzument!)<--[DISLIKED]--(Aleš Matějka),
(Karel Kunc)--[DISLIKED]-->(Beyond the polar bear)<--[LIKED]--(Aleš Matějka),
(Karel Kunc)--[LIKED]-->(Shipito.com - podnikání v usa)<--[LIKED]--(Aleš Matějka).
Took: 0 ms.
...
Found things in common for 100 random couples of attendees in 142 ms.](https://image.slidesharecdn.com/neo4j-webexpo2012-slideshare-120923093125-phpapp02/75/WebExpo-Prague-2012-Introduction-to-Neo4j-Czech-46-2048.jpg)

![S kým na pivo?
start myself=node:people(name = "Emil Votruba")
match (myself)-[:LIKED]->(talk)<-[:LIKED]-(beerMate)
return distinct beerMate.name, count(beerMate)
order by count(beerMate) desc
limit 5;
@bachmanm](https://image.slidesharecdn.com/neo4j-webexpo2012-slideshare-120923093125-phpapp02/75/WebExpo-Prague-2012-Introduction-to-Neo4j-Czech-50-2048.jpg)
![Cypher Query
start myself=node:people(name = ”Aleš Havlík")
match (myself)-[:LIKED]->(talk)<-[:LIKED]-(beerMate)
return distinct beerMate.name, count(beerMate)
order by count(beerMate) desc
limit 5;
@bachmanm](https://image.slidesharecdn.com/neo4j-webexpo2012-slideshare-120923093125-phpapp02/75/WebExpo-Prague-2012-Introduction-to-Neo4j-Czech-51-2048.jpg)
![Cypher Query
start myself=node:people(name = ”Aleš Havlík")
match (myself)-[:LIKED]->()<-[:LIKED]-(beerMate)
return distinct beerMate.name, count(beerMate)
order by count(beerMate) desc
limit 5;
@bachmanm](https://image.slidesharecdn.com/neo4j-webexpo2012-slideshare-120923093125-phpapp02/75/WebExpo-Prague-2012-Introduction-to-Neo4j-Czech-52-2048.jpg)