Download as ODP, PPTX











![XML::XParent utilities: how to use them
• Configure parameters into xparent.yml file:
• To load an XML file: schema_params:
perl xparentparse.pl 'dbi:Pg:dbname=xparent'
i <input file> # 'dbi:SQLite:xparent.db'
driver <the Schema driver to use>
grubert
grubert
[config_file <the config file>]
[verbose]
AutoCommit: 1
[clean] #plugins:
[compact] # 'SLMS::Redis::ParserPlugin':
• To query the Xparent data store:# 'tag': 'MovingRegion'
perl xparentsearch.pl
path <path regex>
driver <the Schema driver to use>
[config_file <the config file>]
• To clean the data store:
perl xparentclean.pl
driver <the Schema driver to use>
[config_file <the config file>]](https://image.slidesharecdn.com/xml-xparent2-121104055057-phpapp02/75/Xml-parent-Yet-another-way-to-store-XML-files-18-2048.jpg)



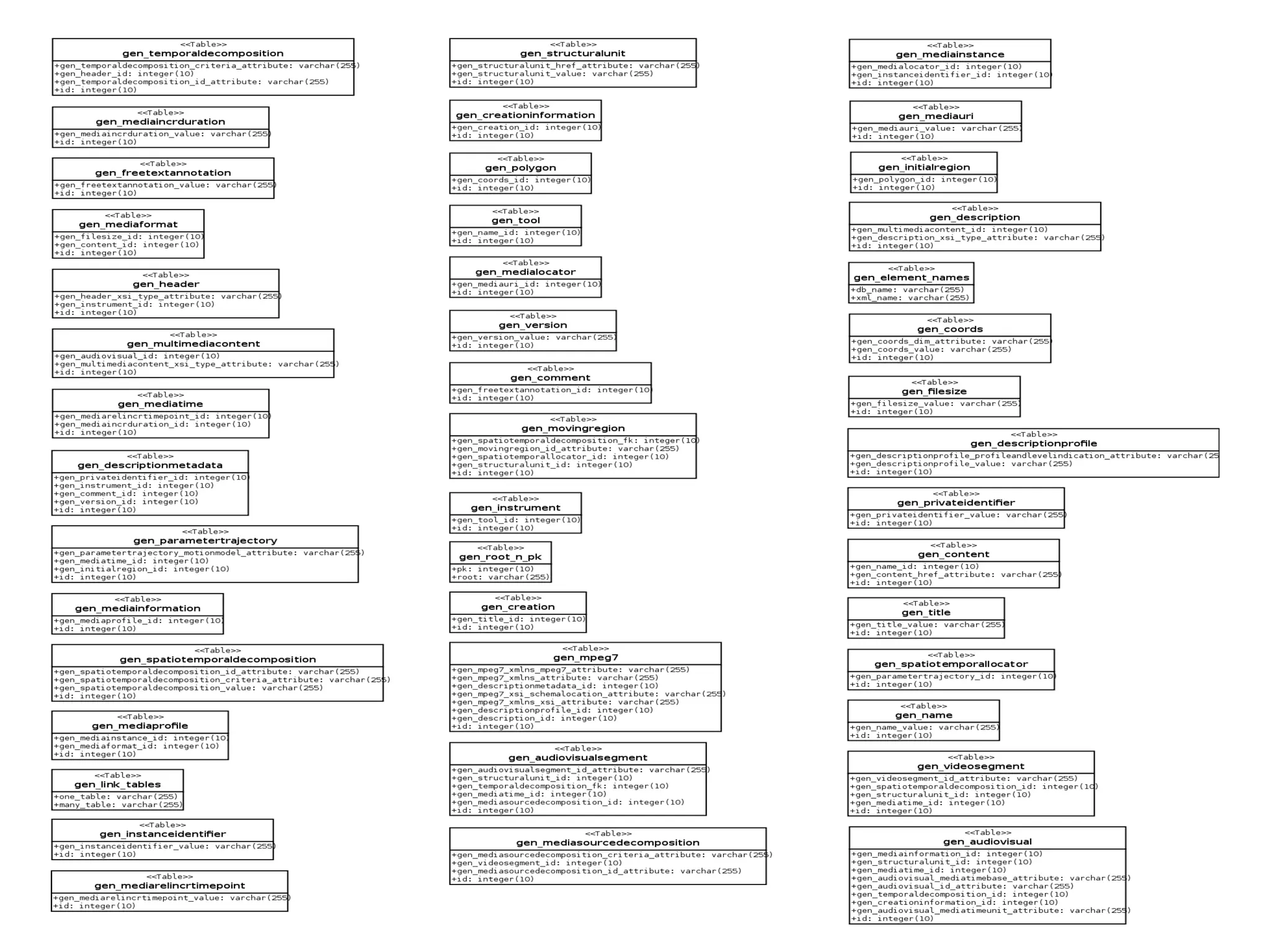
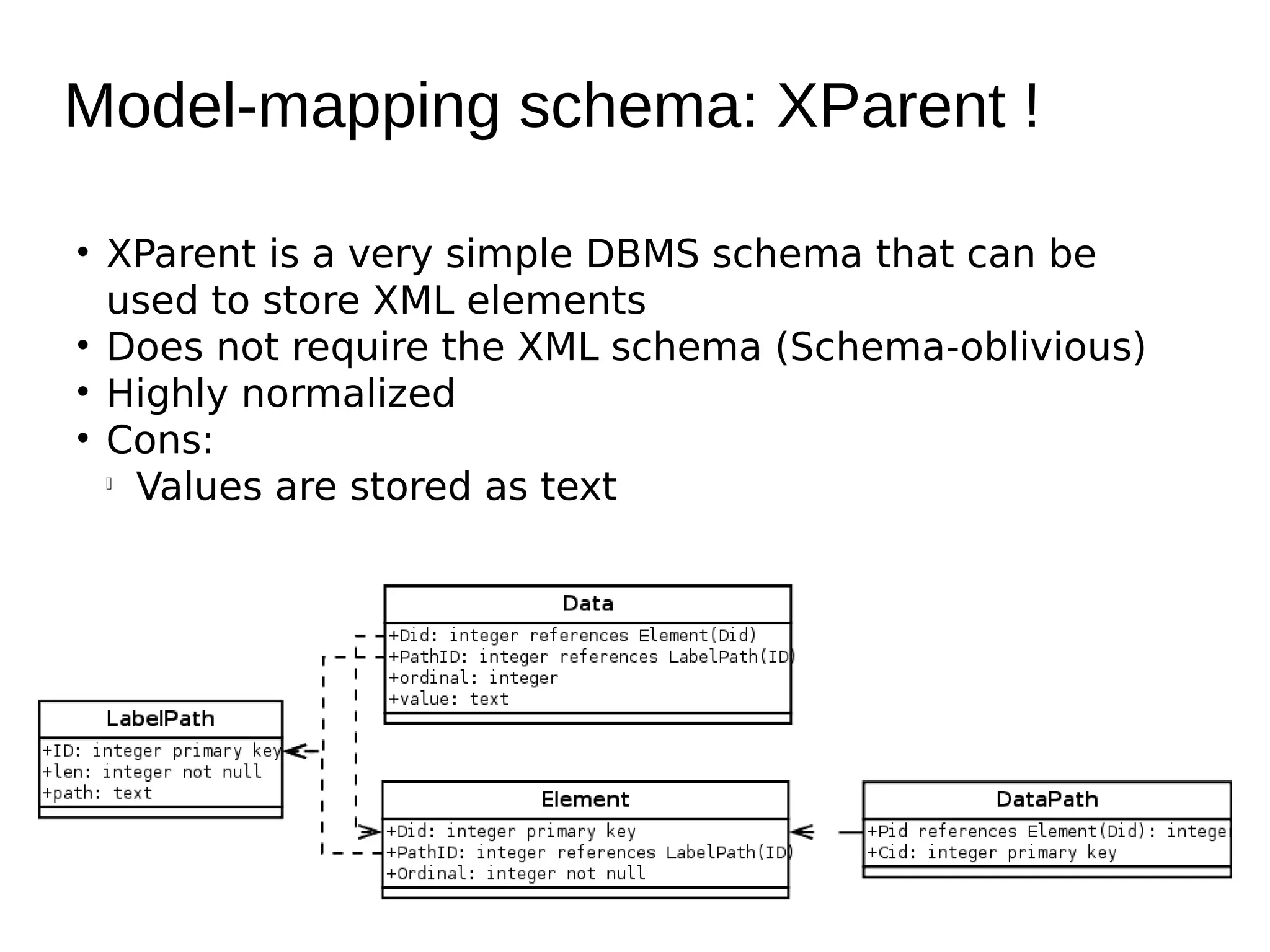
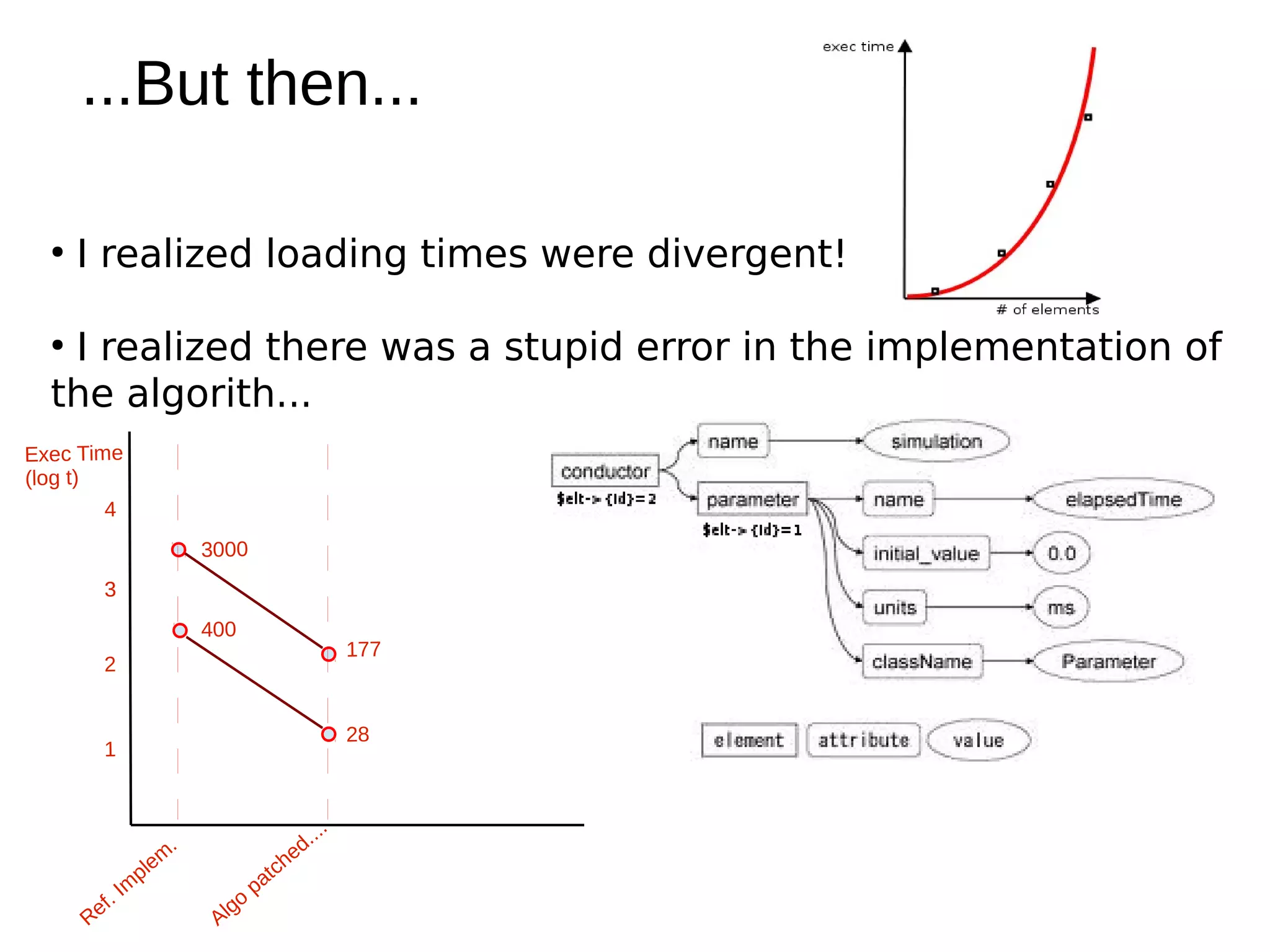
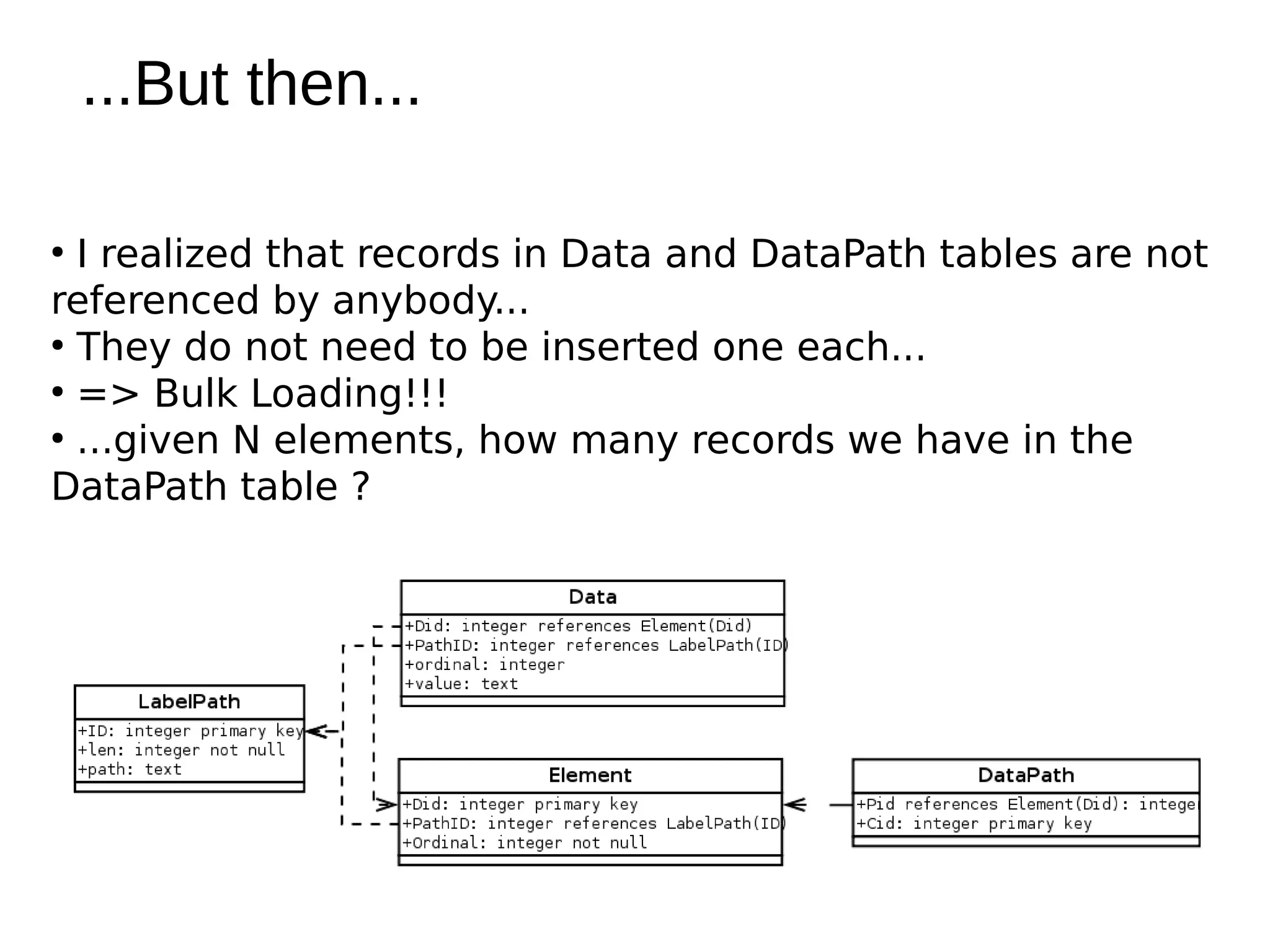
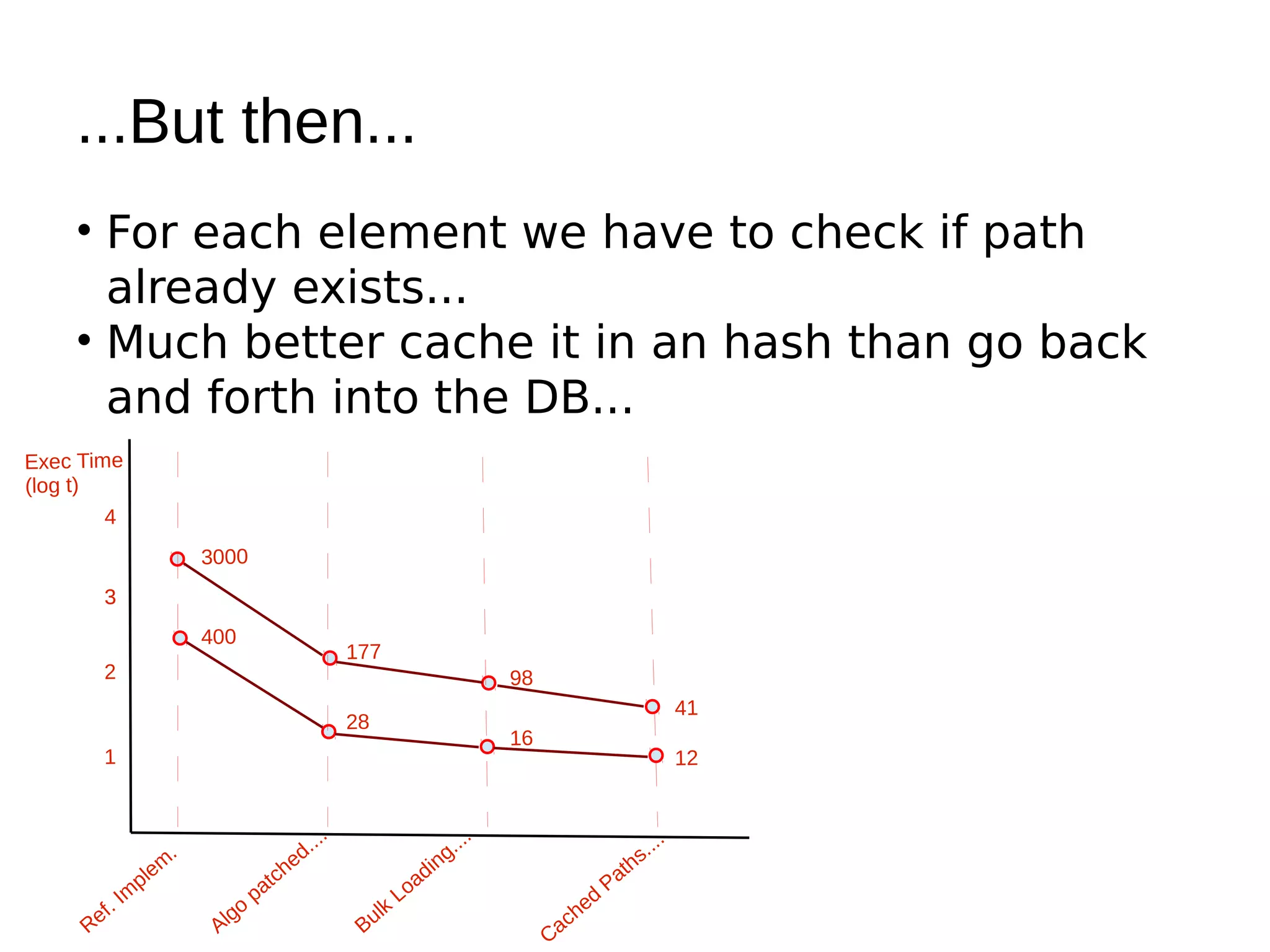
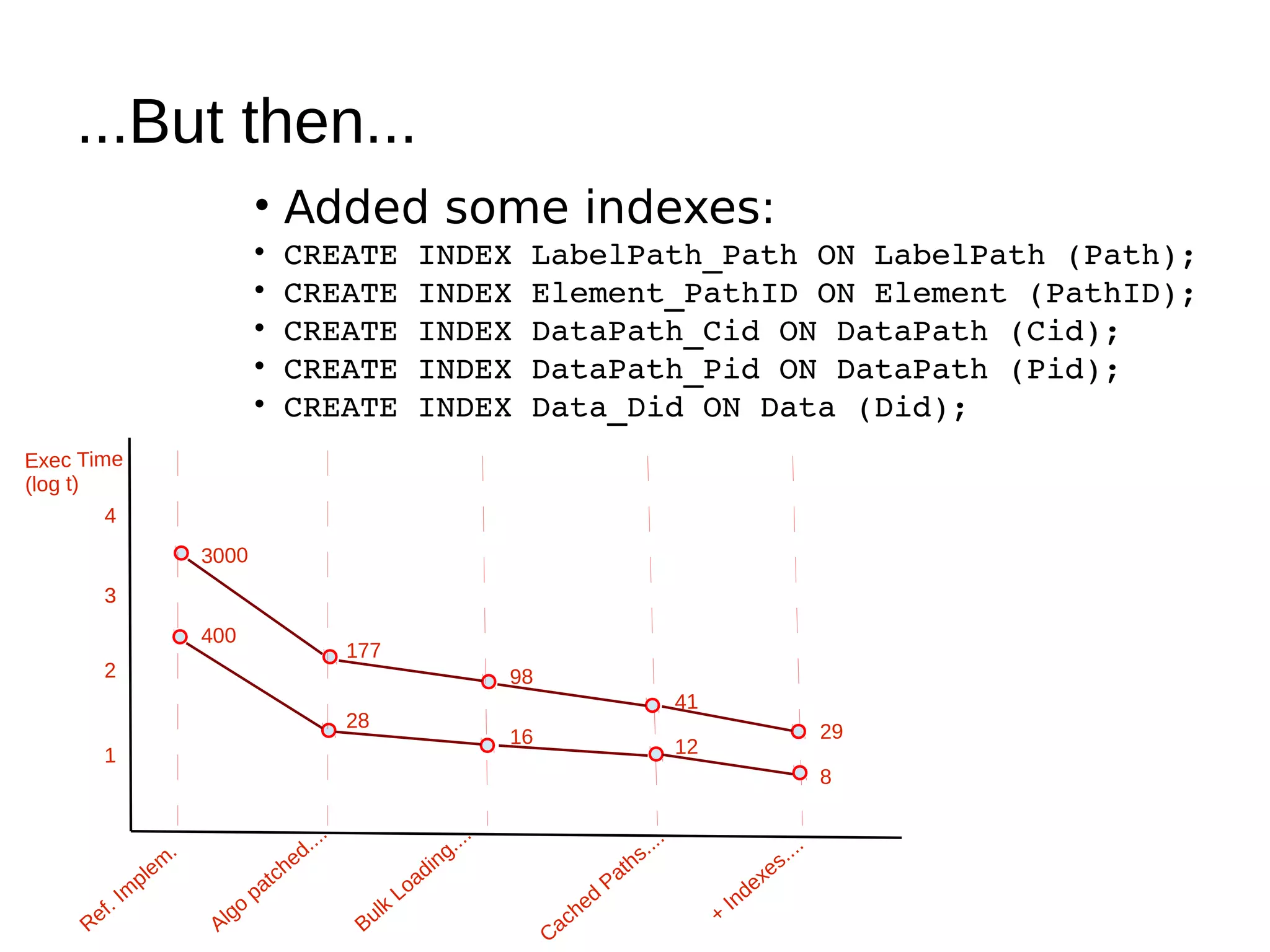
The document discusses various methods for storing XML elements, highlighting the strengths and weaknesses of each approach, such as plain files, DBMS with XML support, and native XML databases. It introduces the 'xml::xparent' Perl module, which allows for schema-oblivious storage of XML elements in a highly normalized format, and compares performance between different drivers and loading techniques. Finally, it outlines utilities for loading, querying, and cleaning the xparent data store, encouraging contributions to the project.



























