
Download to read offline


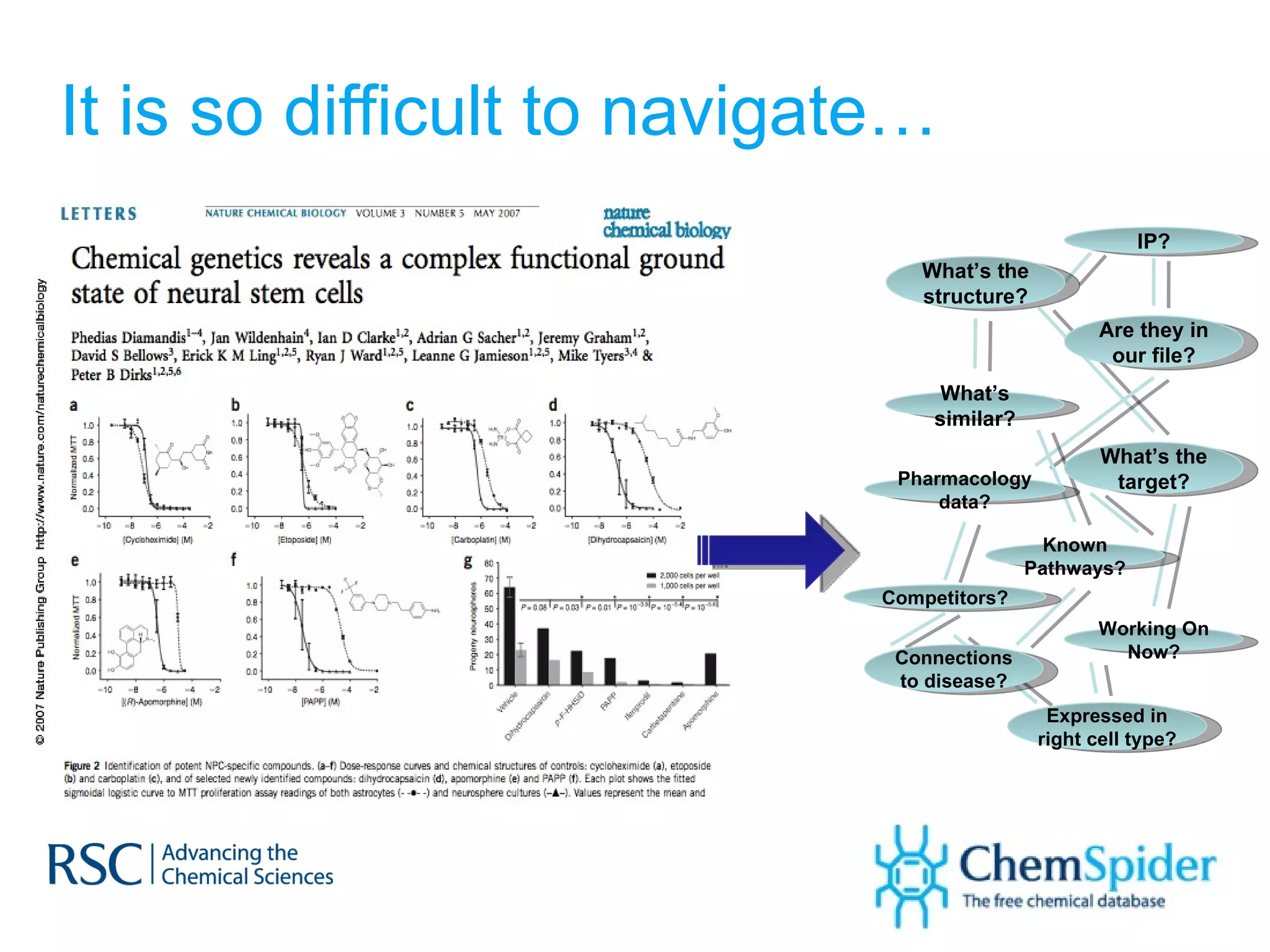


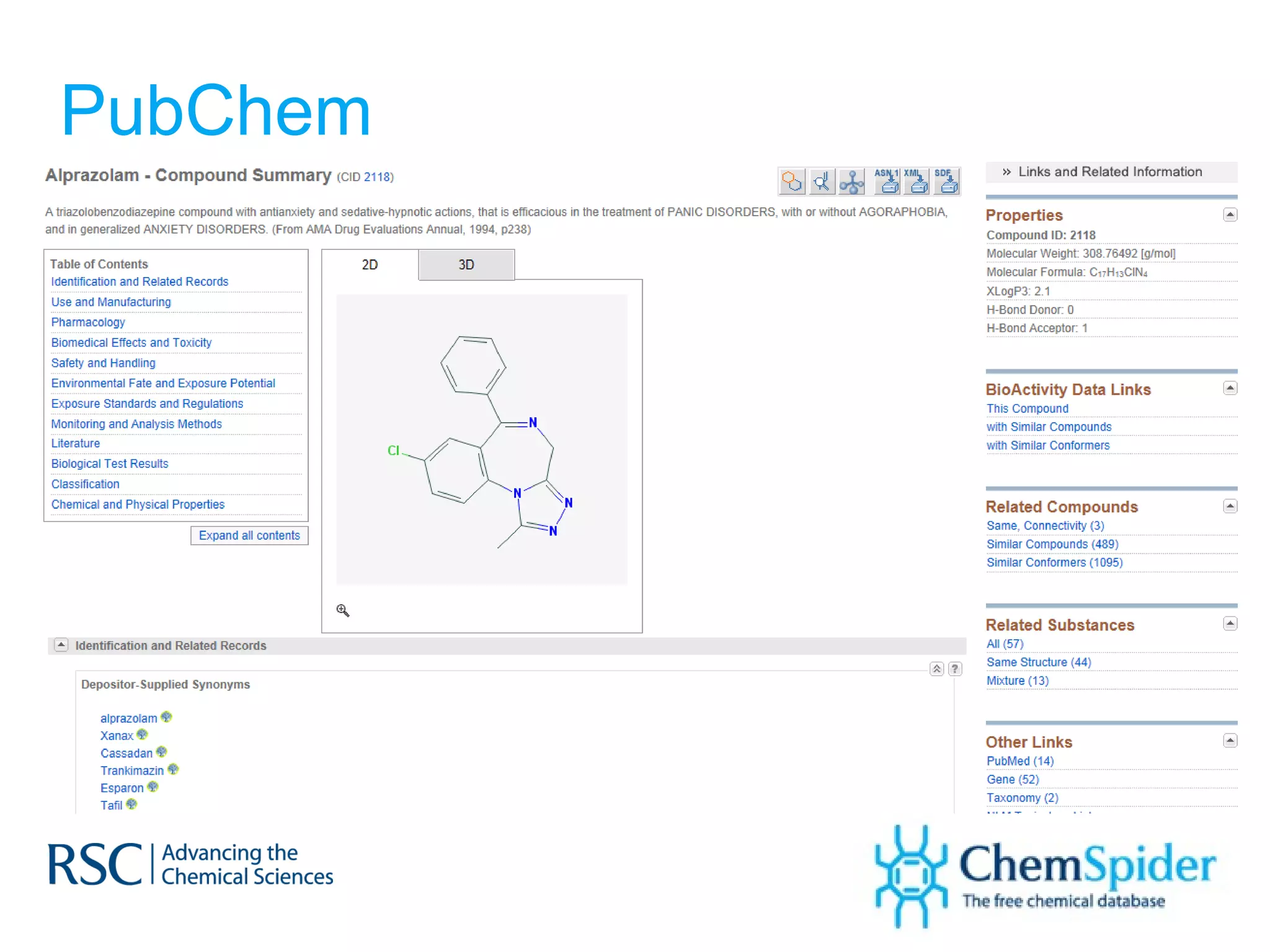
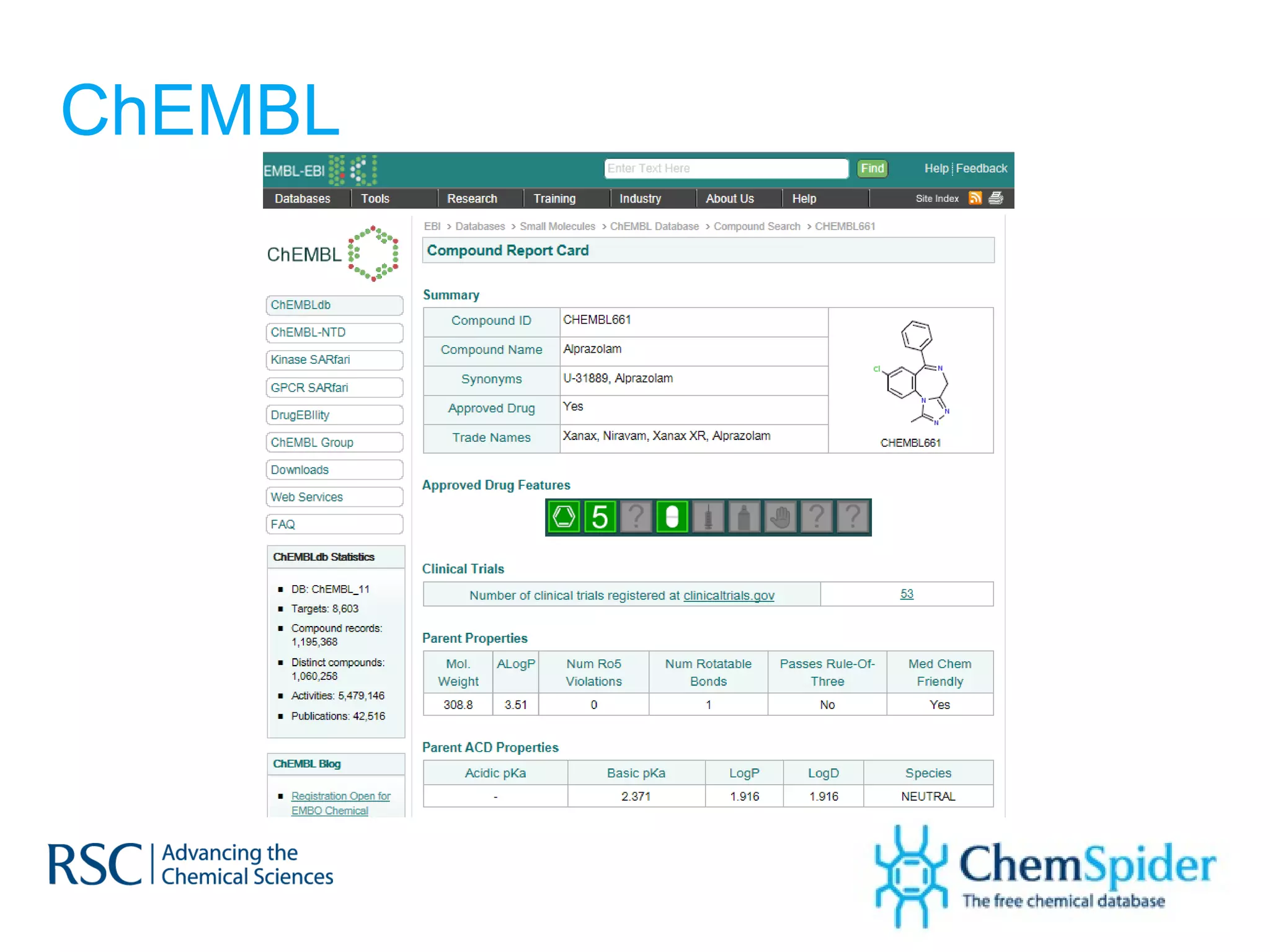
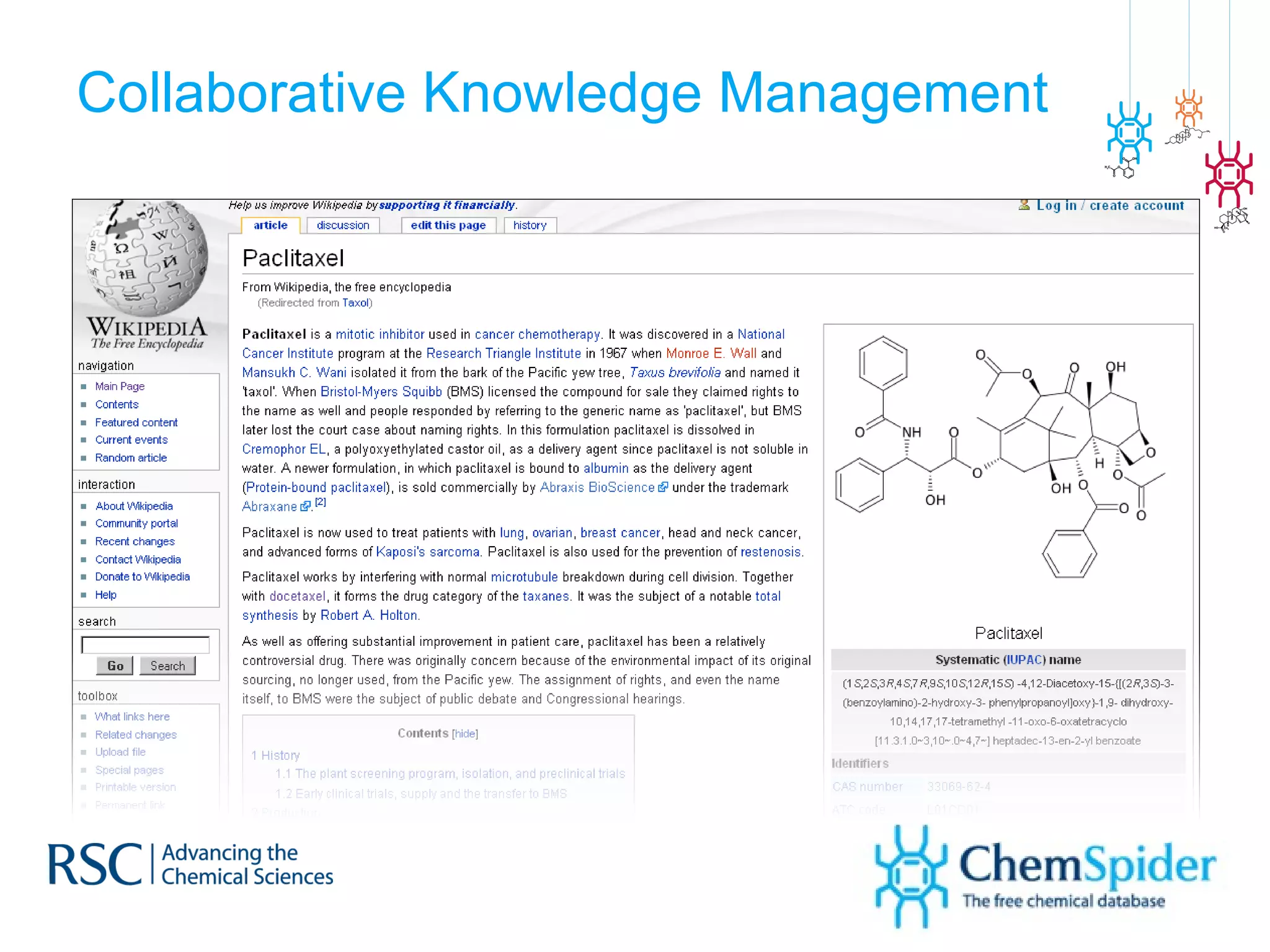









![What could create change? Harvard Business Review (2010) “ One change would make a substantial difference [ to drug R&D ] : the creation of agreed-upon standards for digitally representing drug assets. ” Consider drug structures ONLY…](https://image.slidesharecdn.com/improvingonlinechemistryonestructureatatime-120213075420-phpapp02/75/Improving-online-chemistry-one-structure-at-a-time-22-2048.jpg)



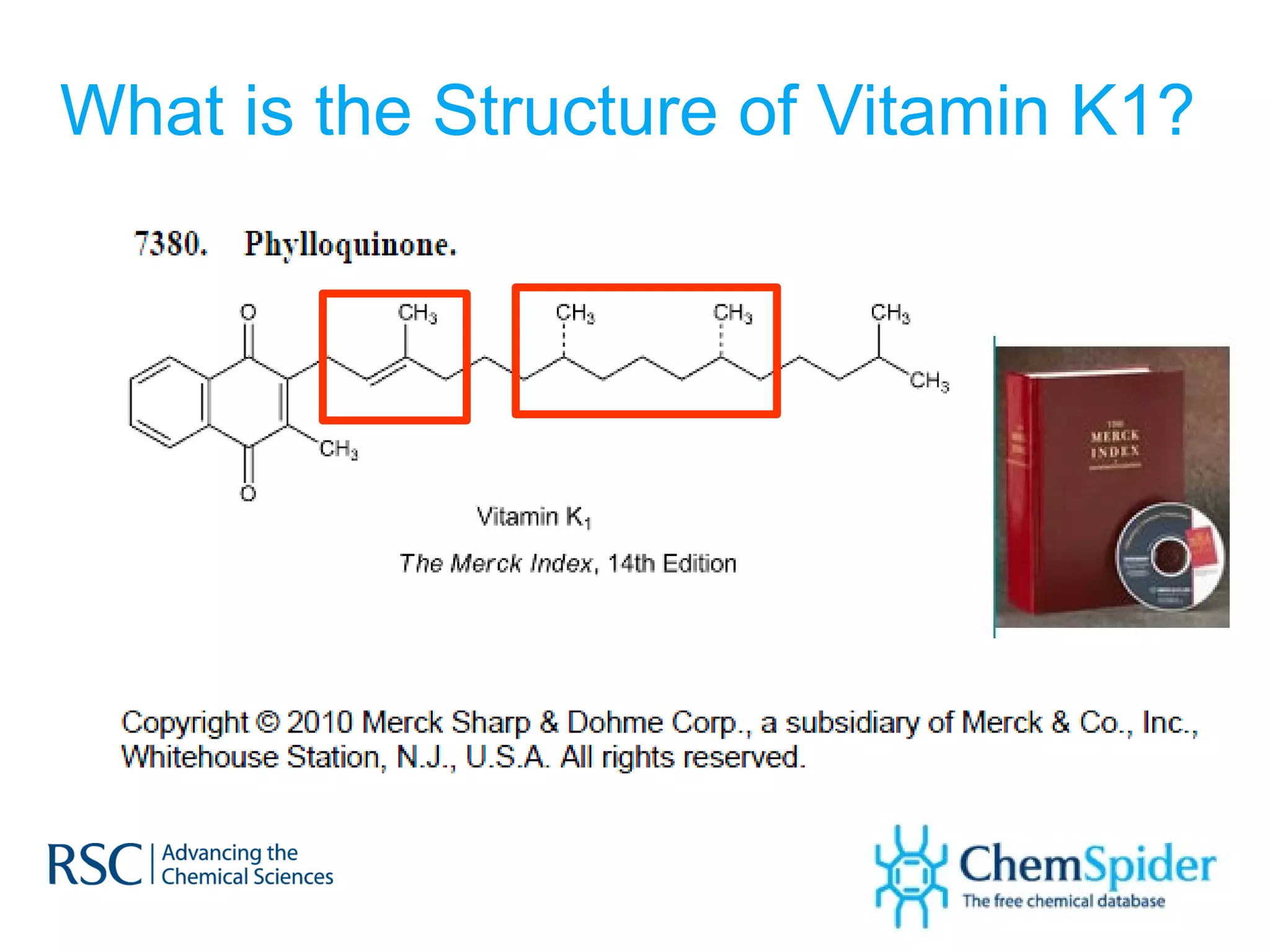

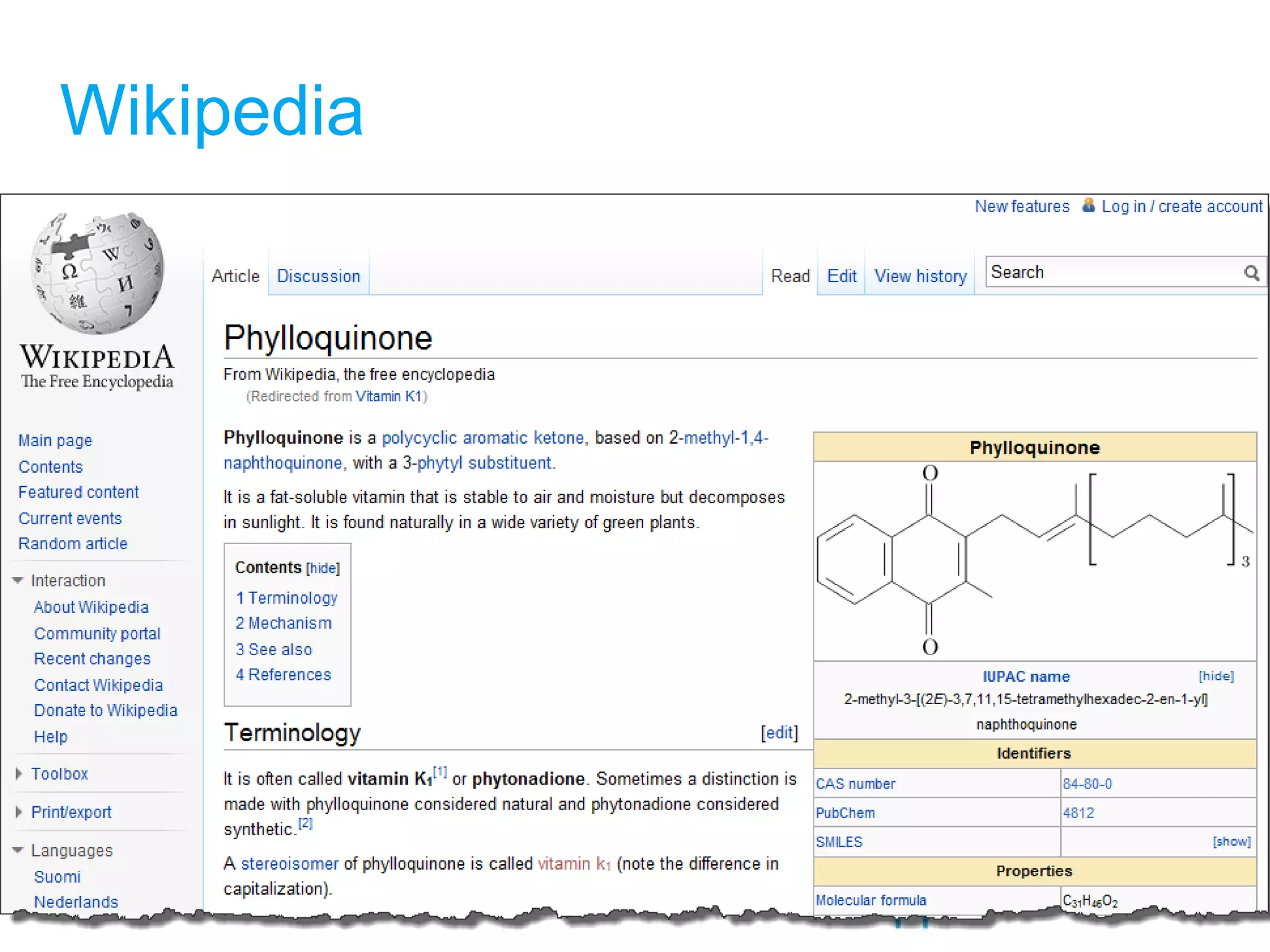
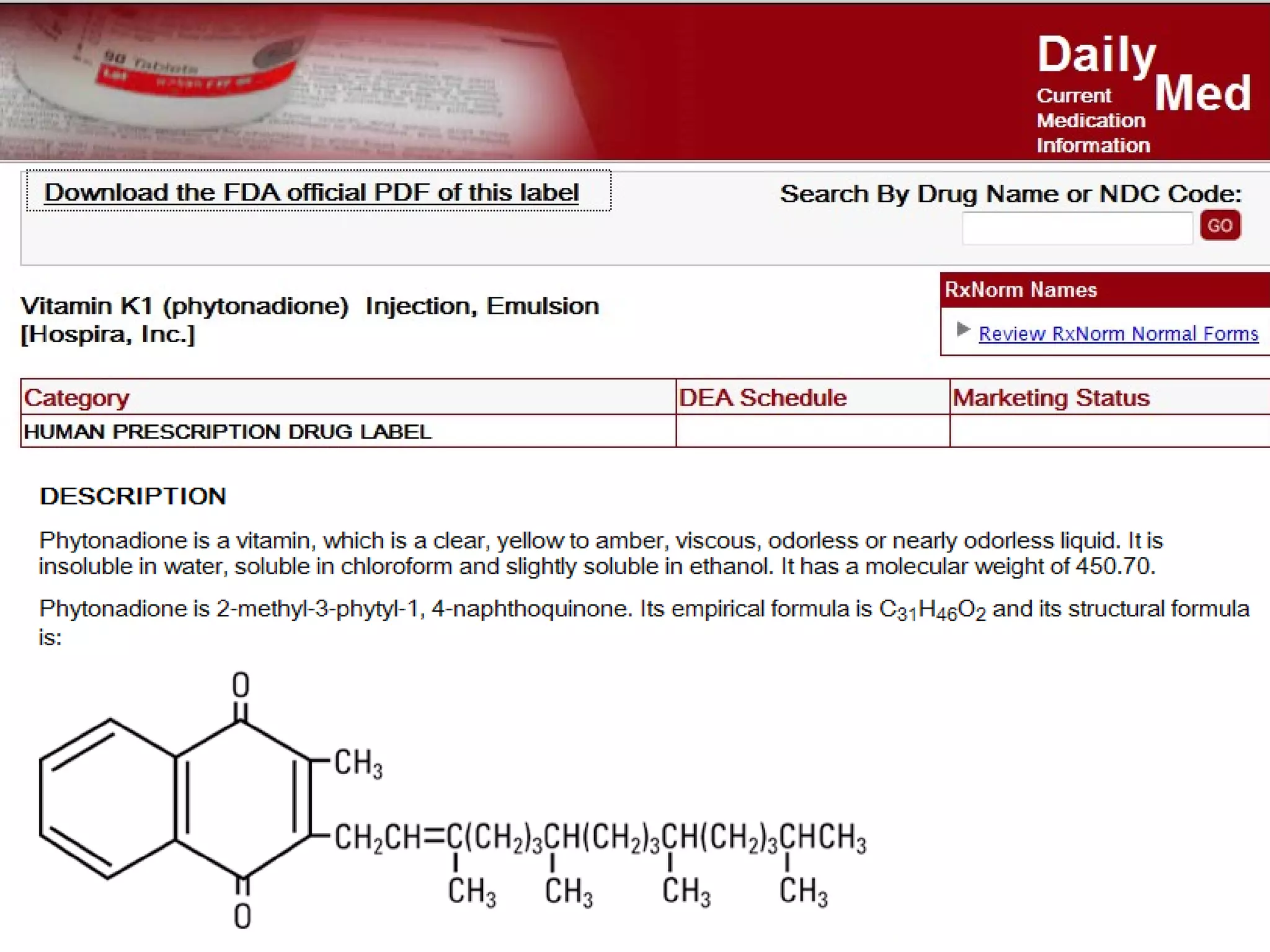
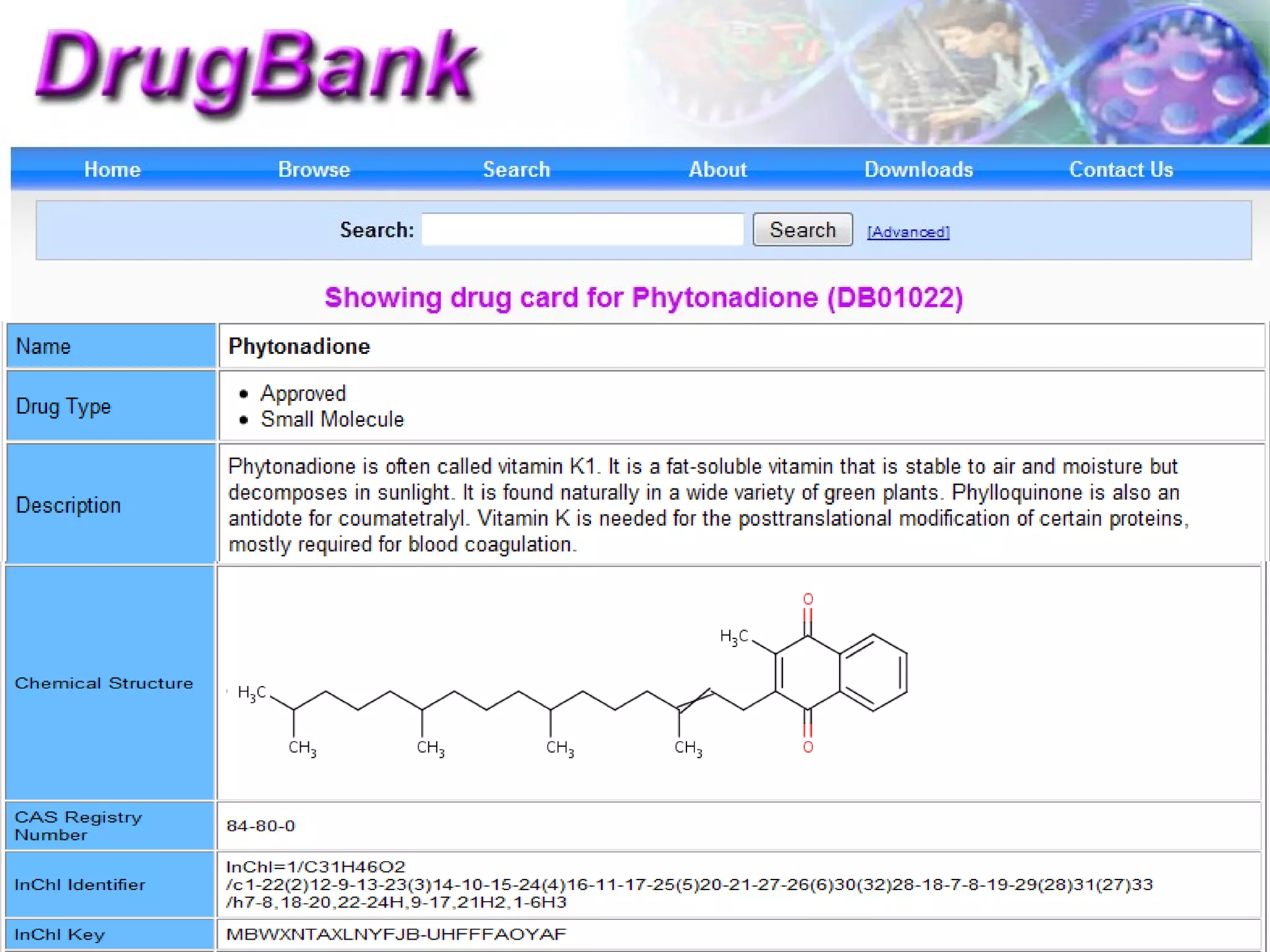
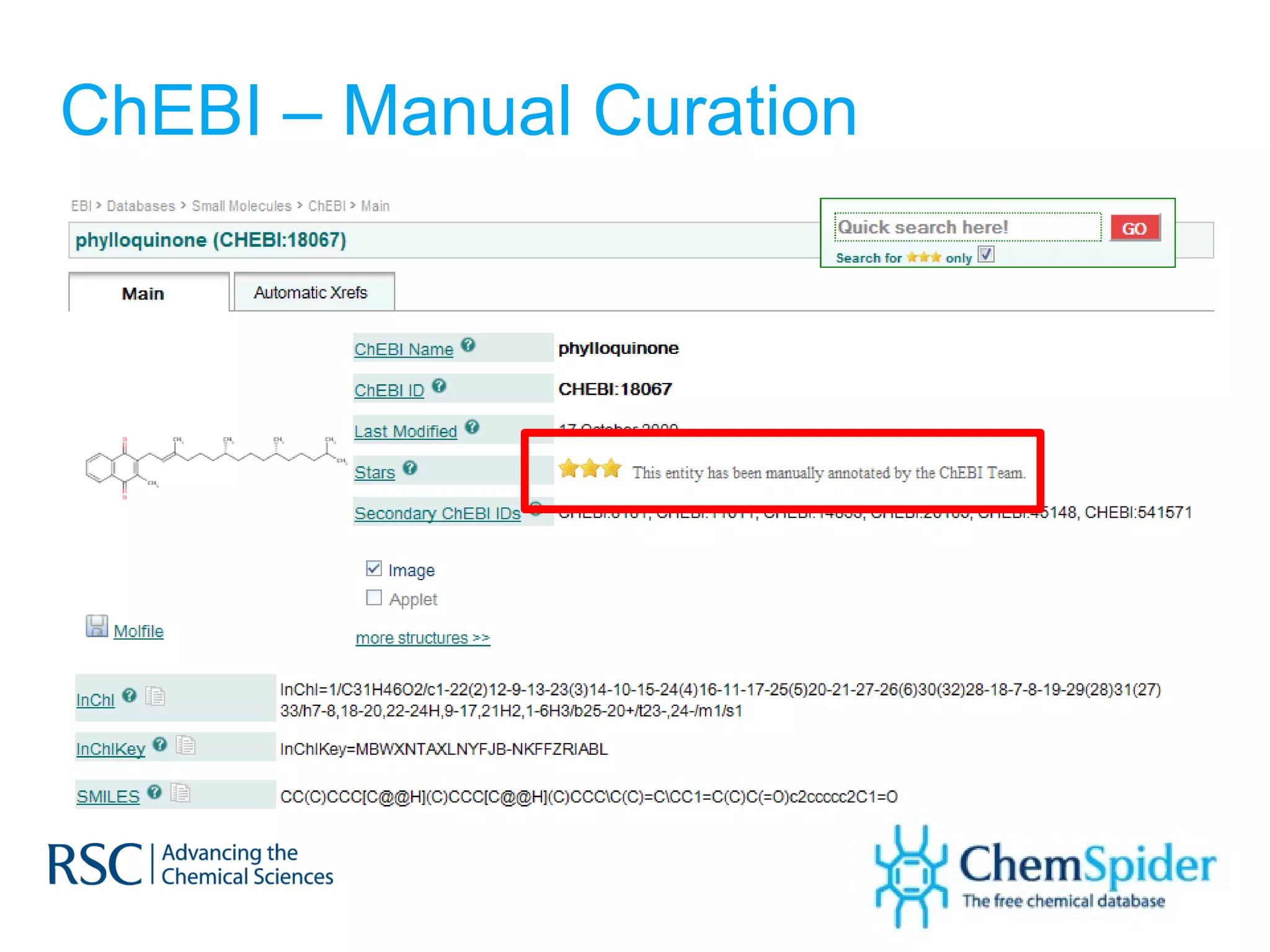
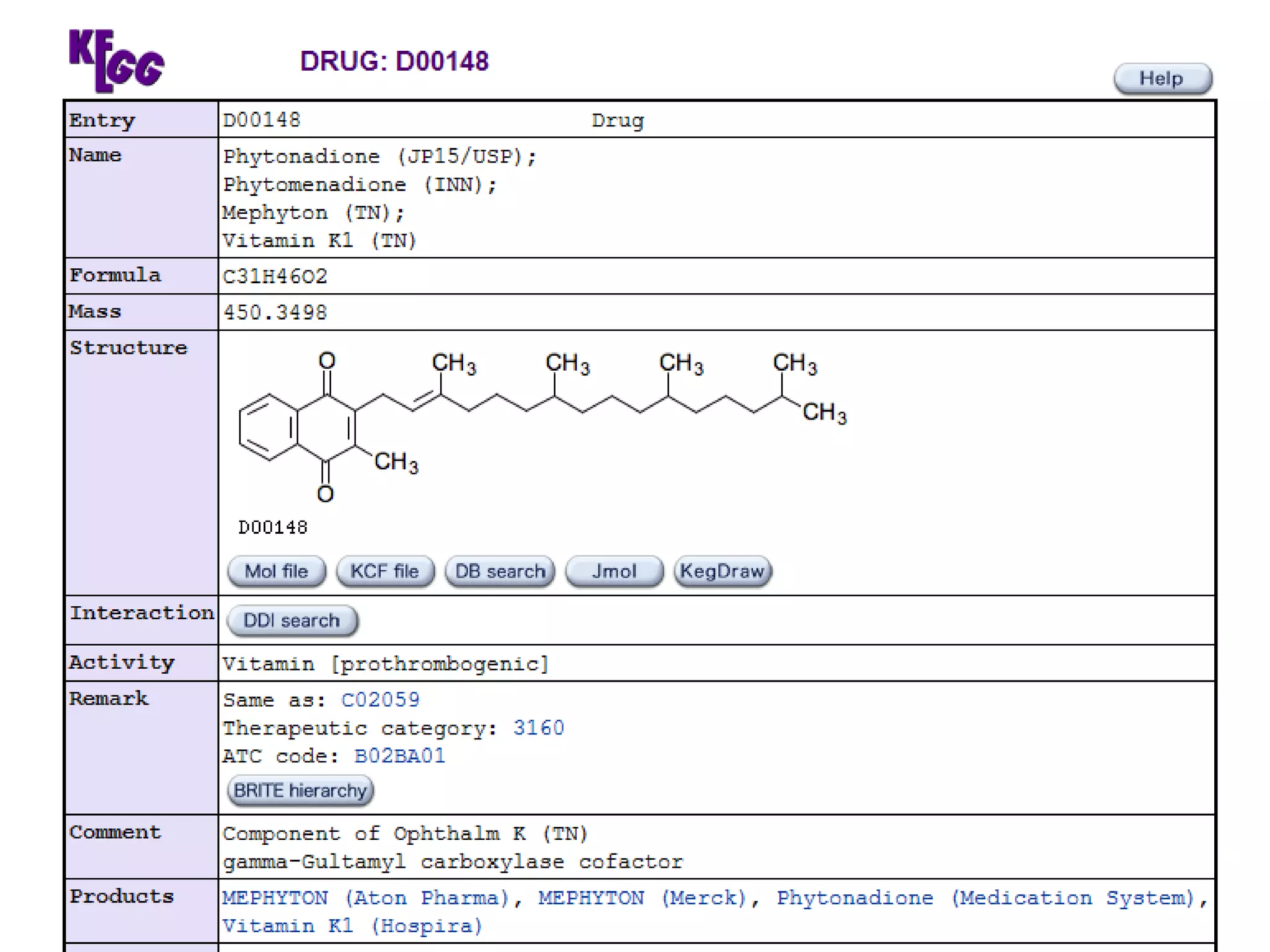




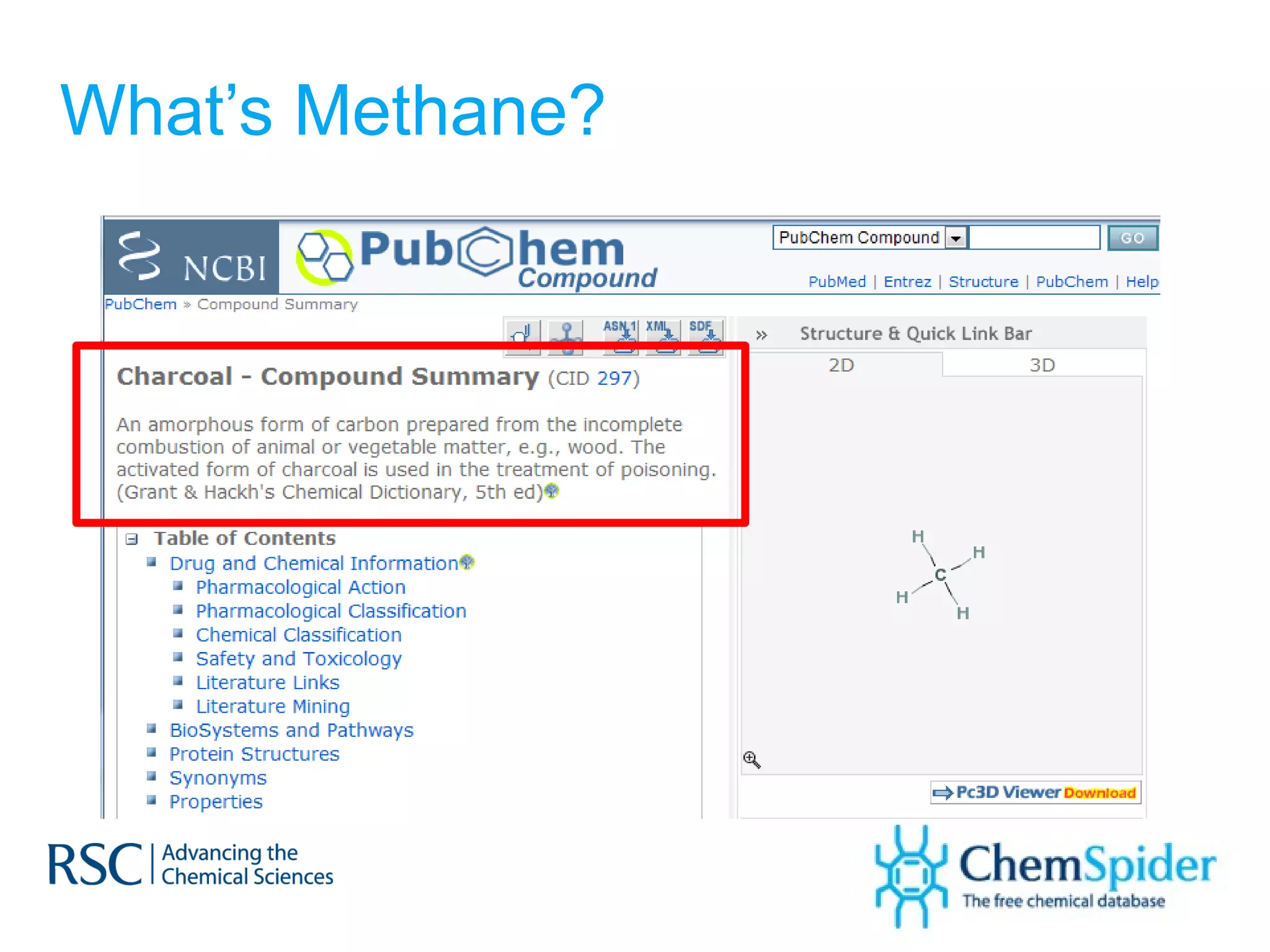

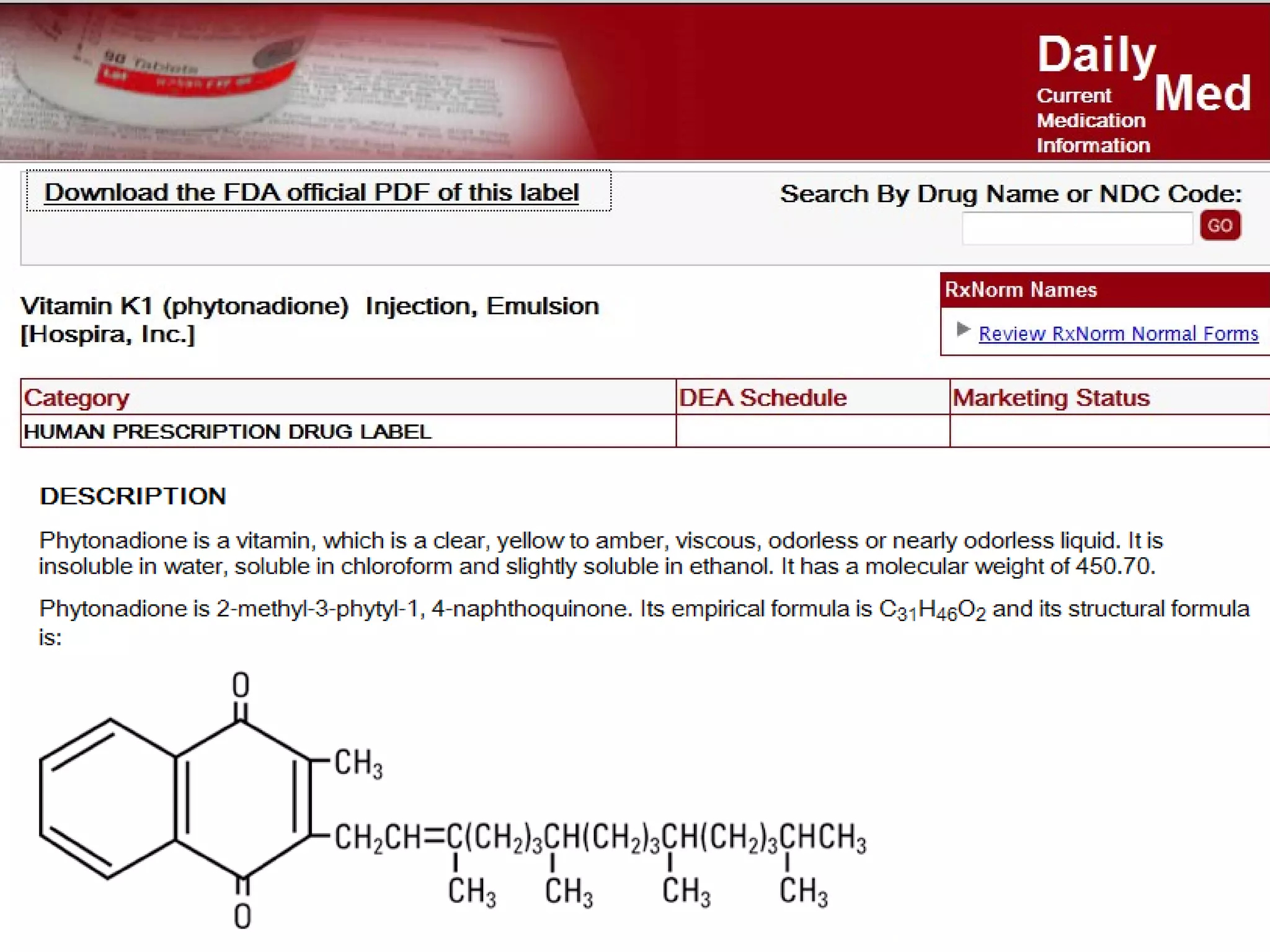
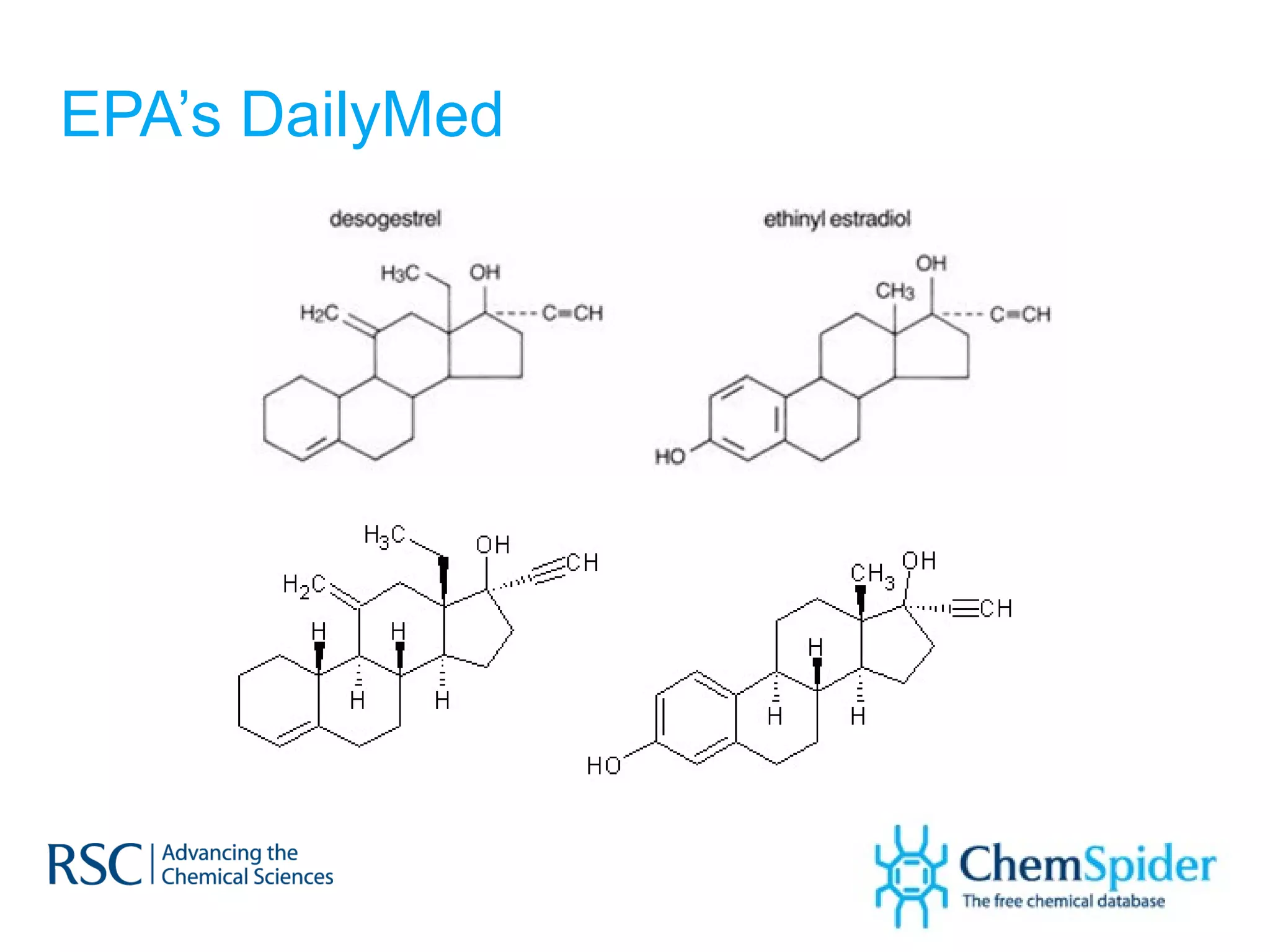
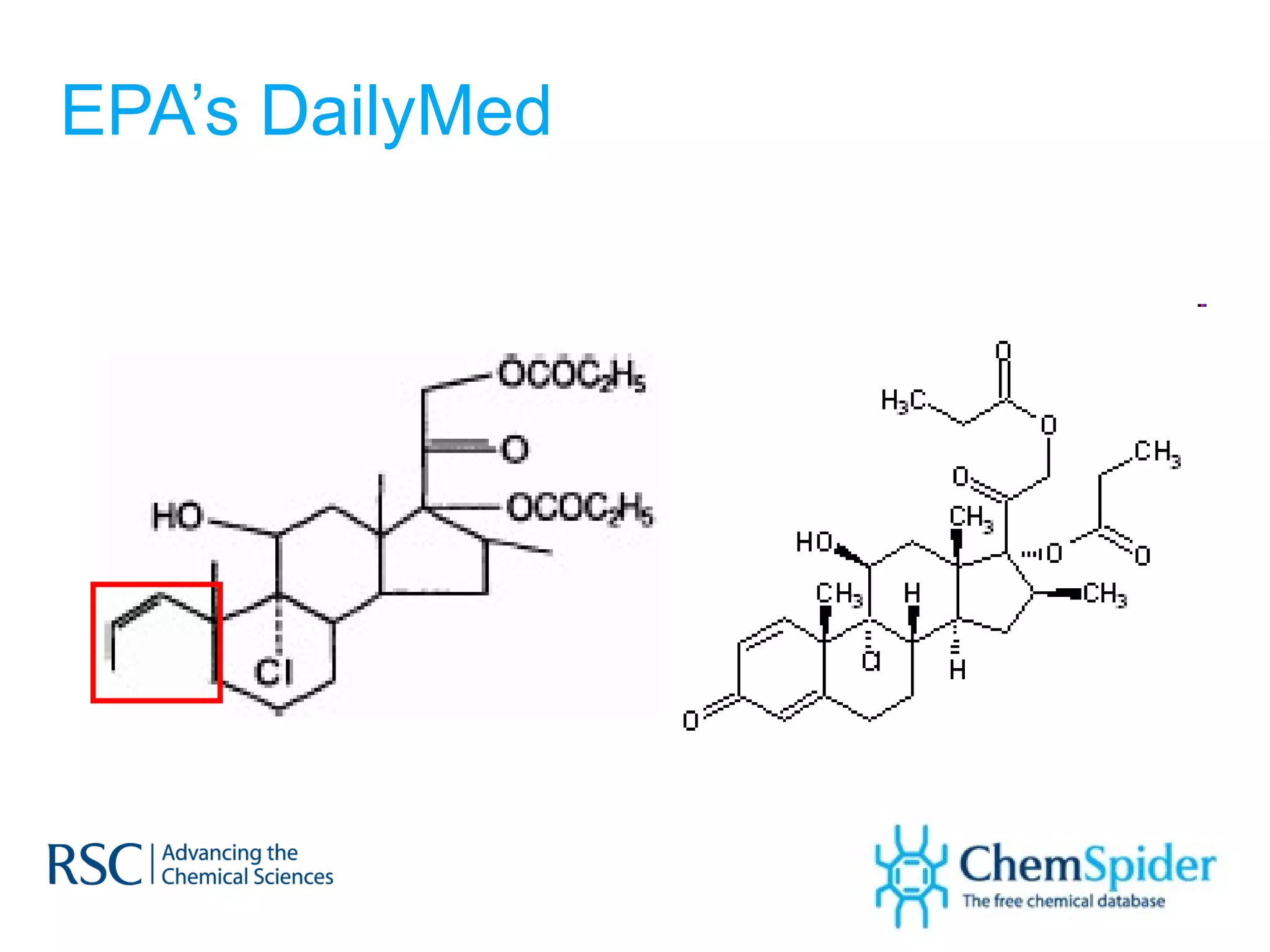
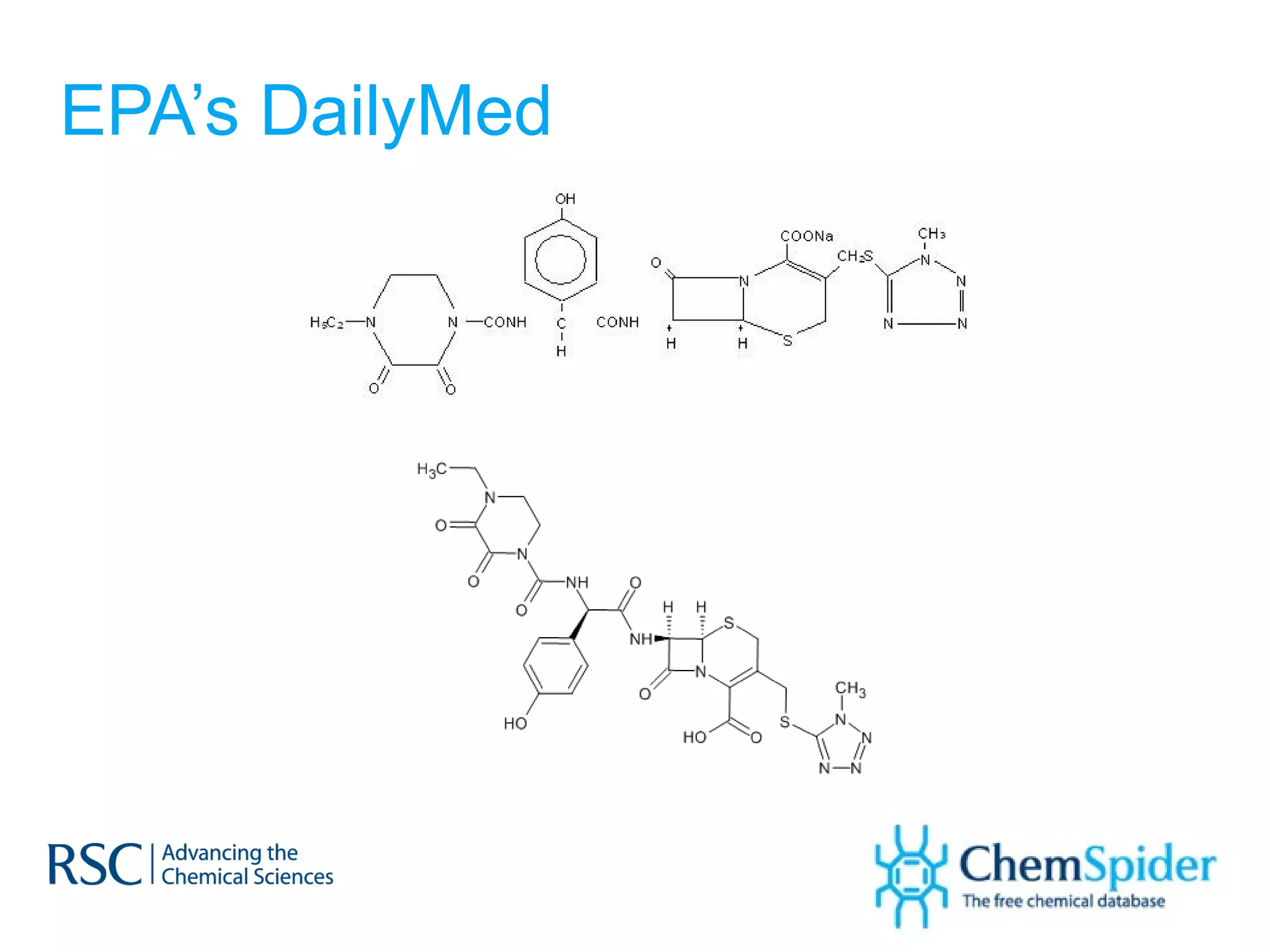


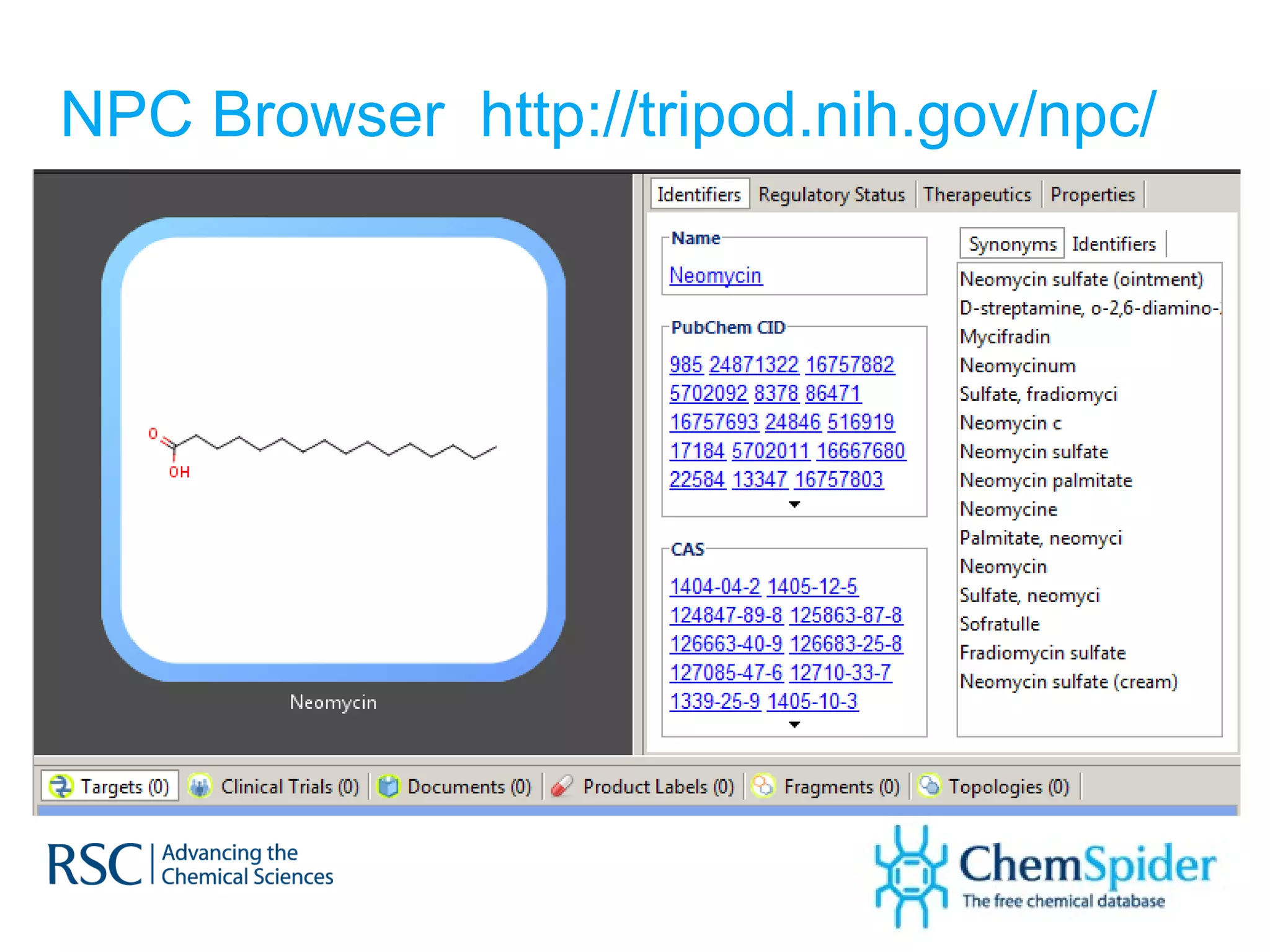
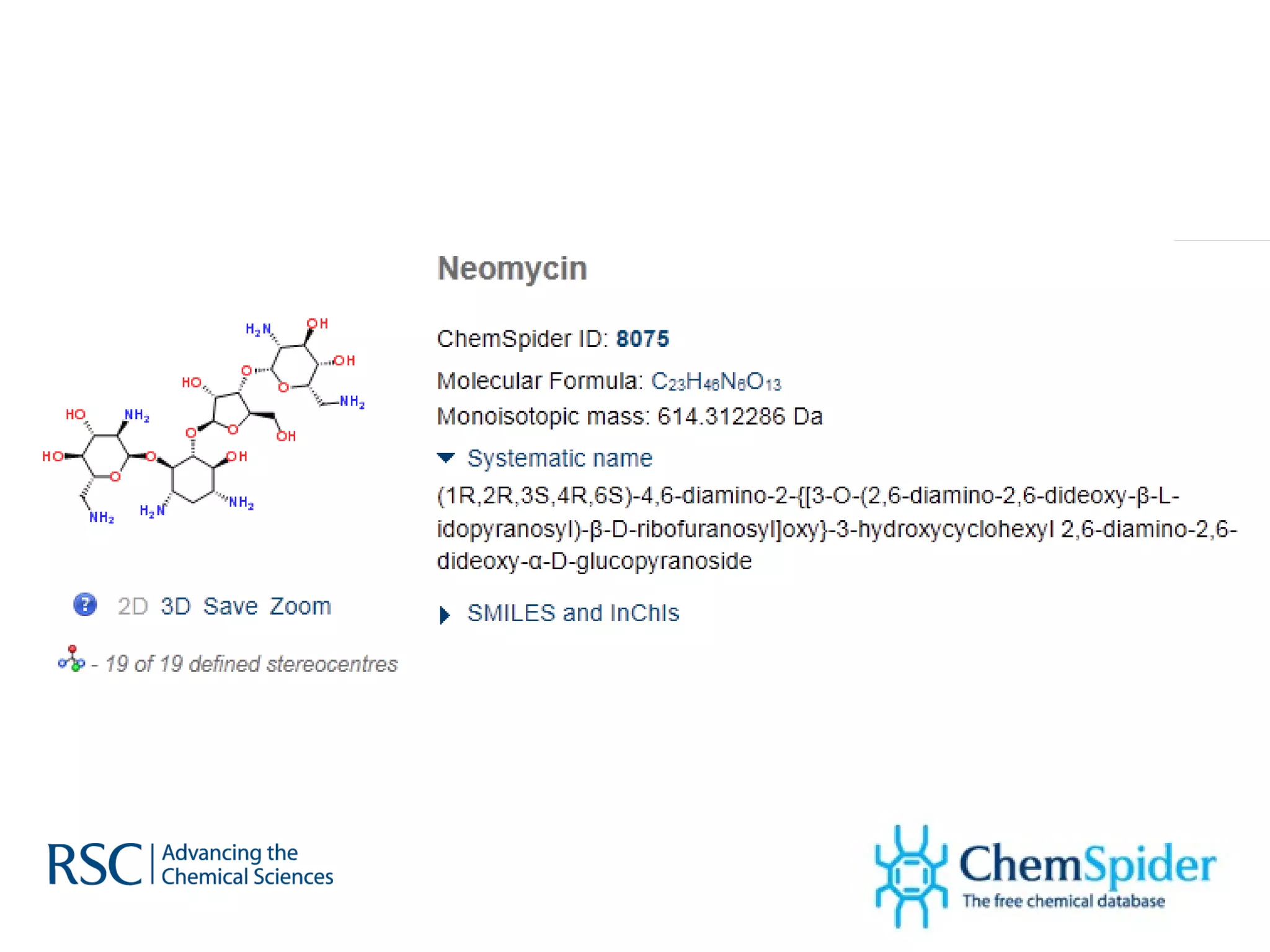



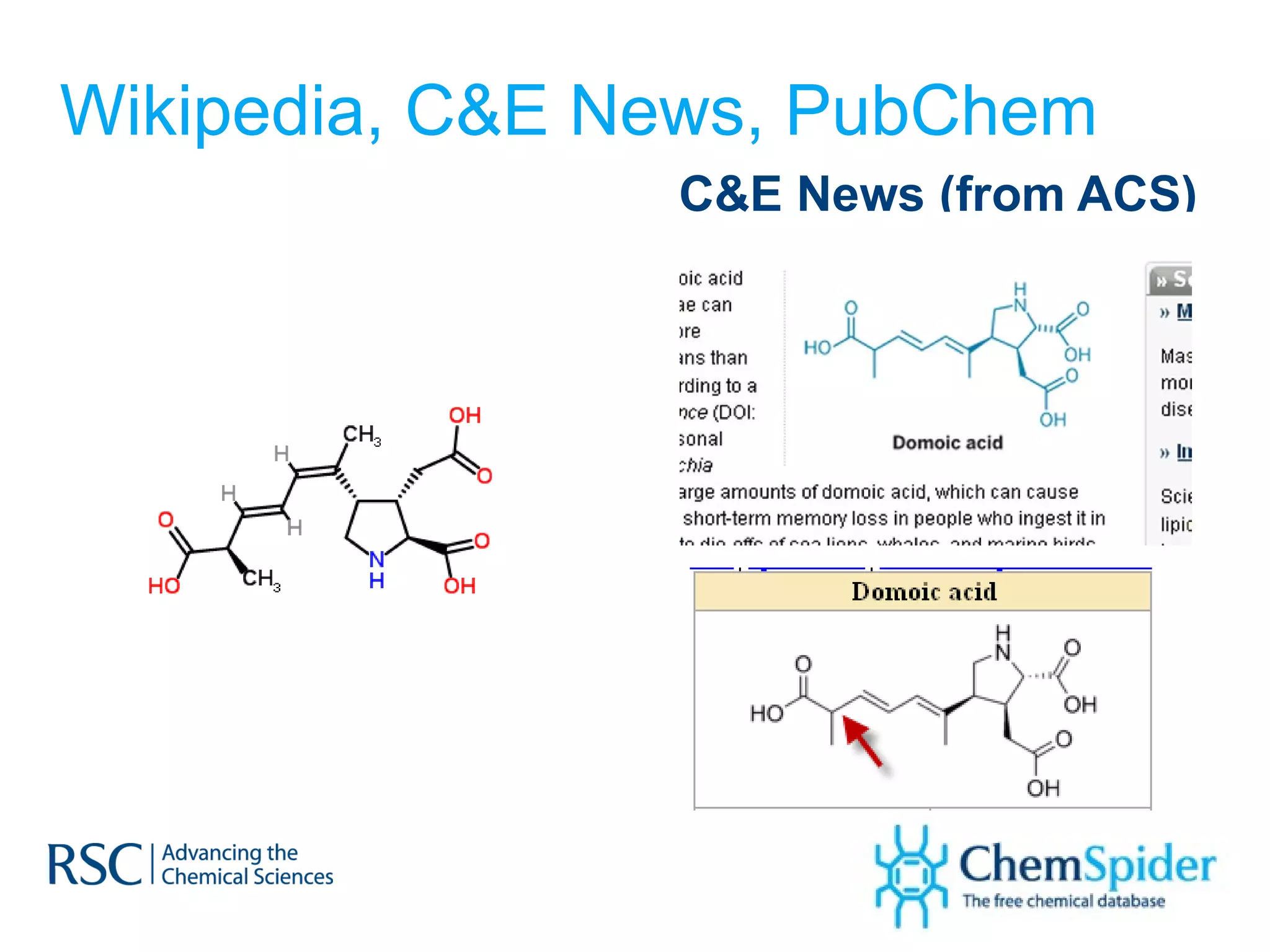






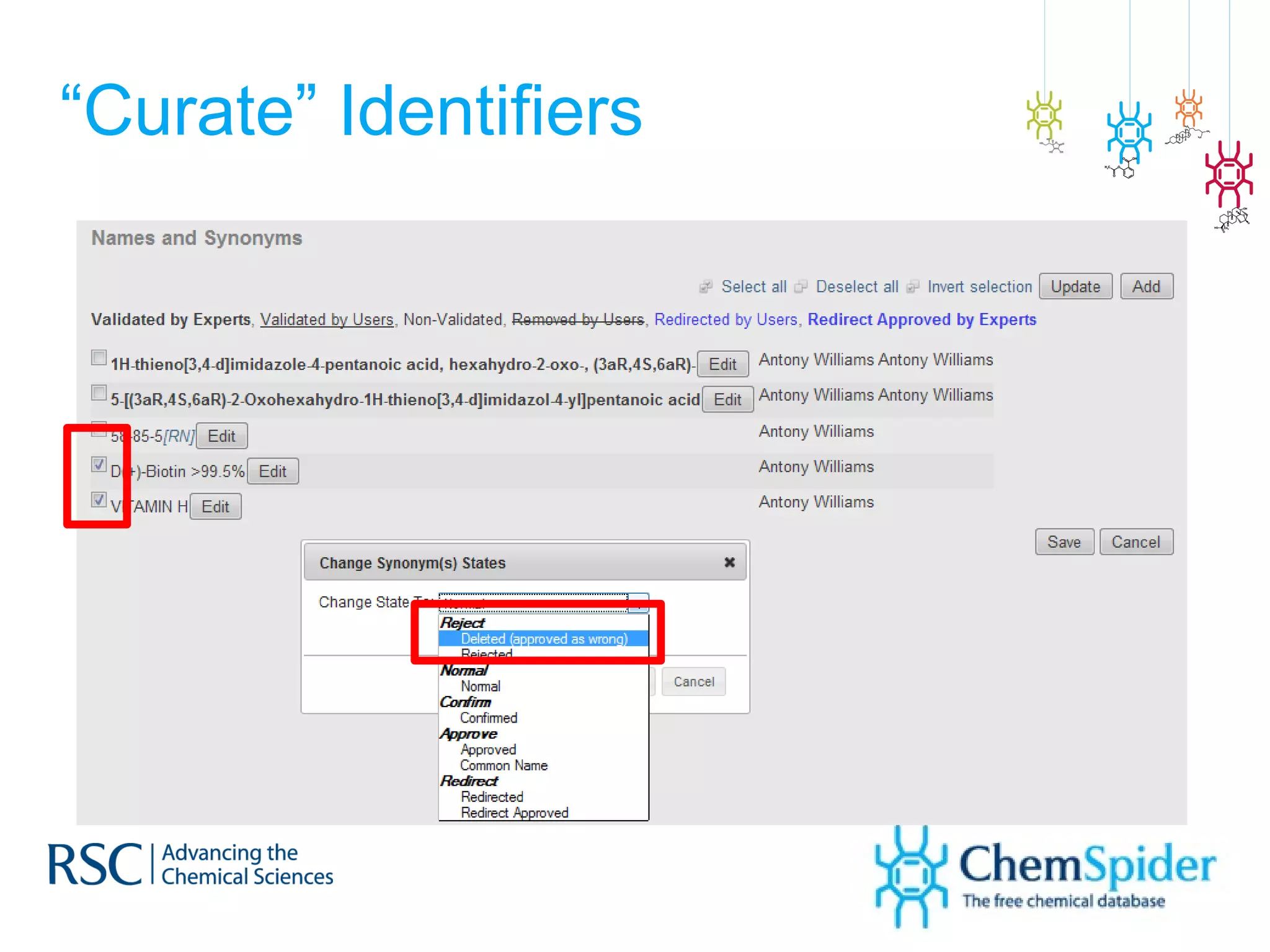
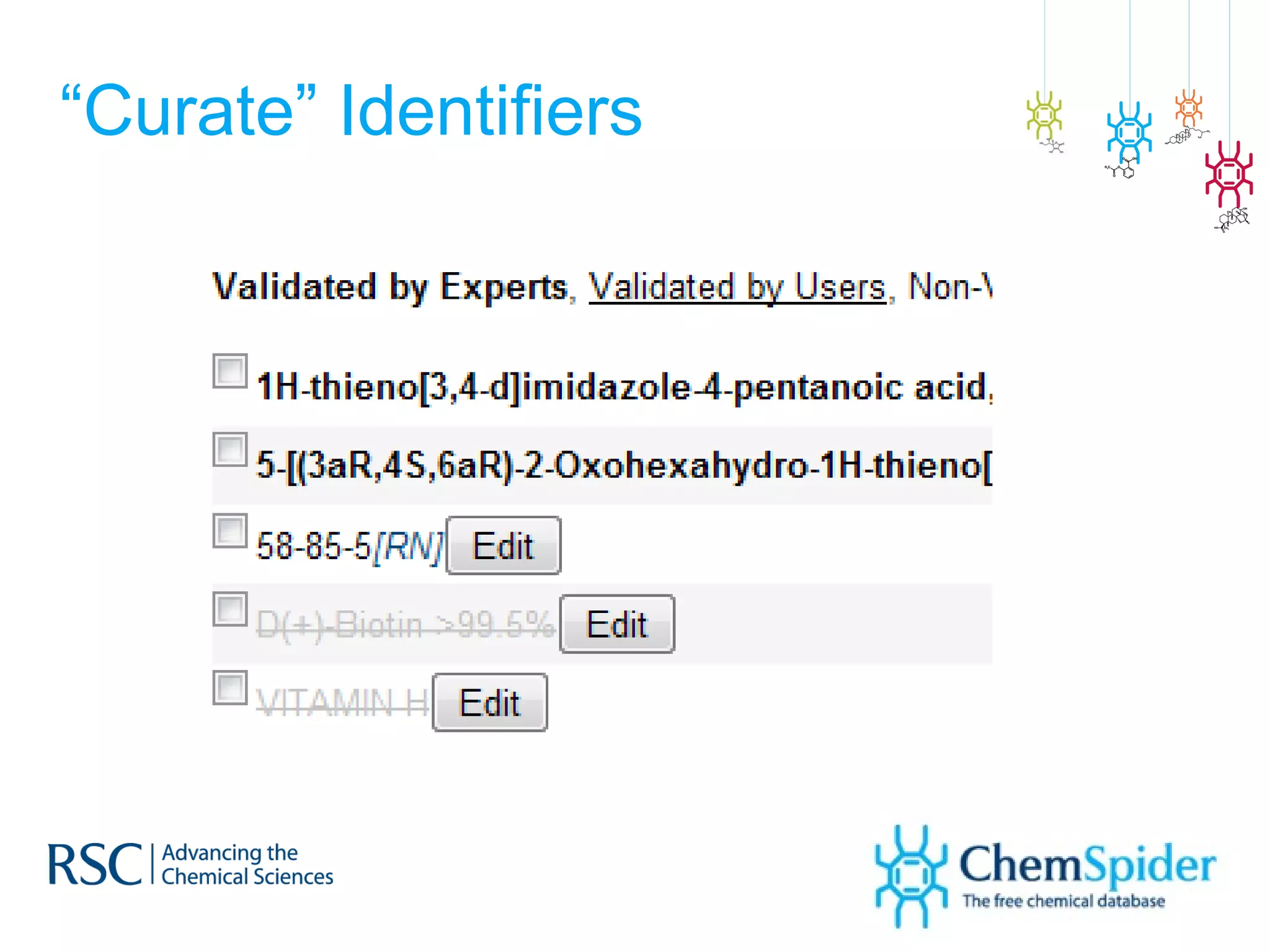

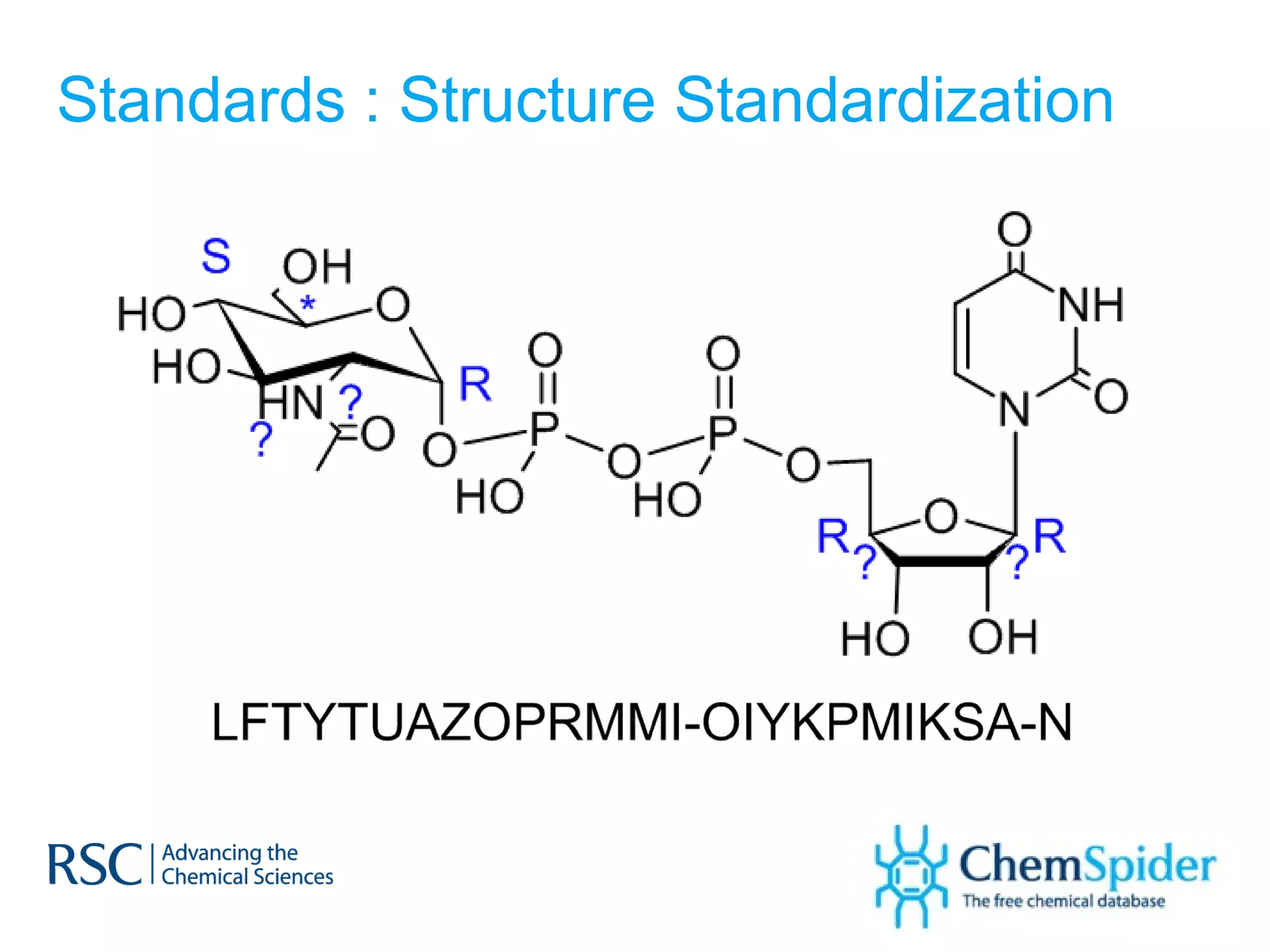
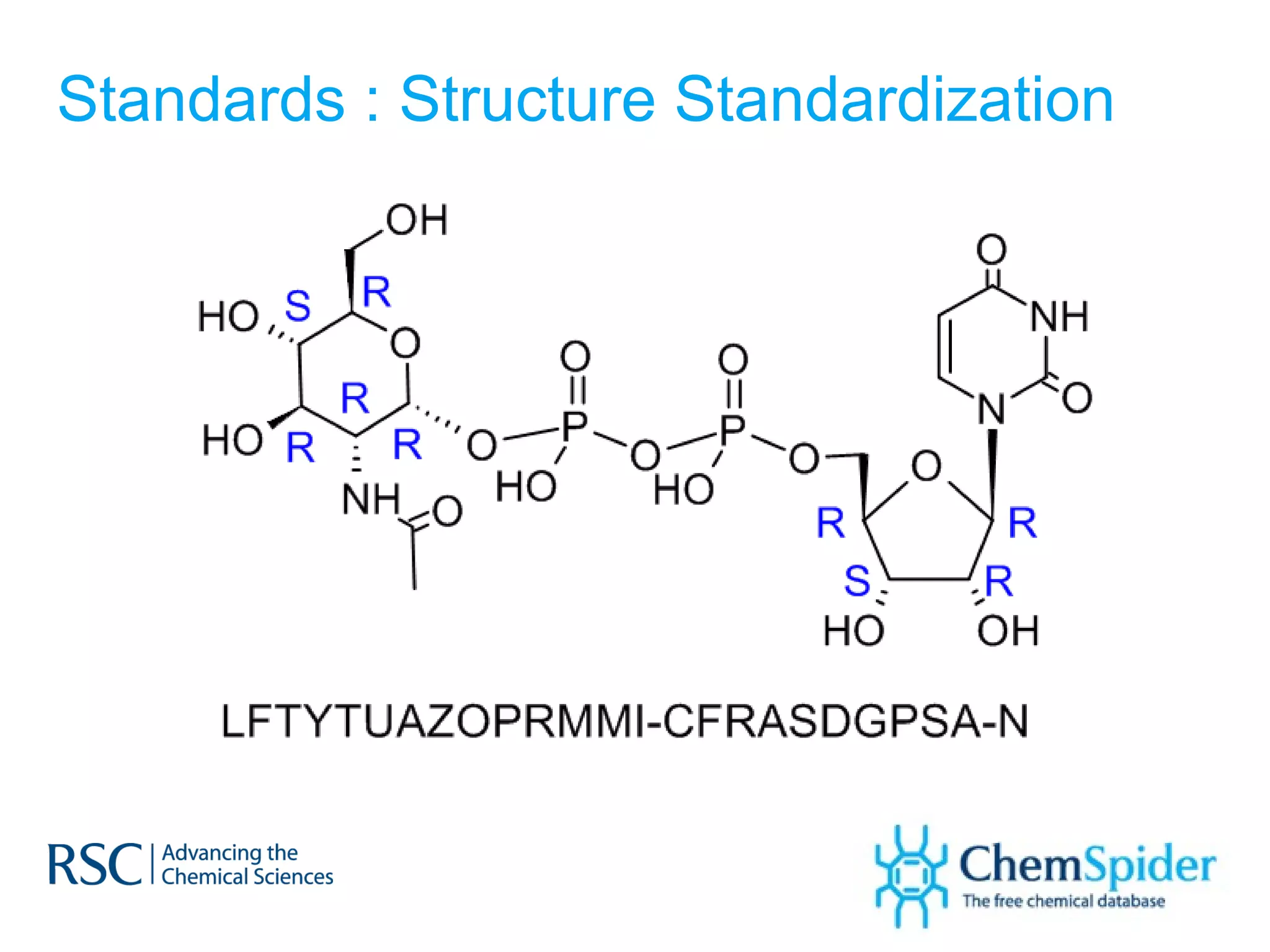


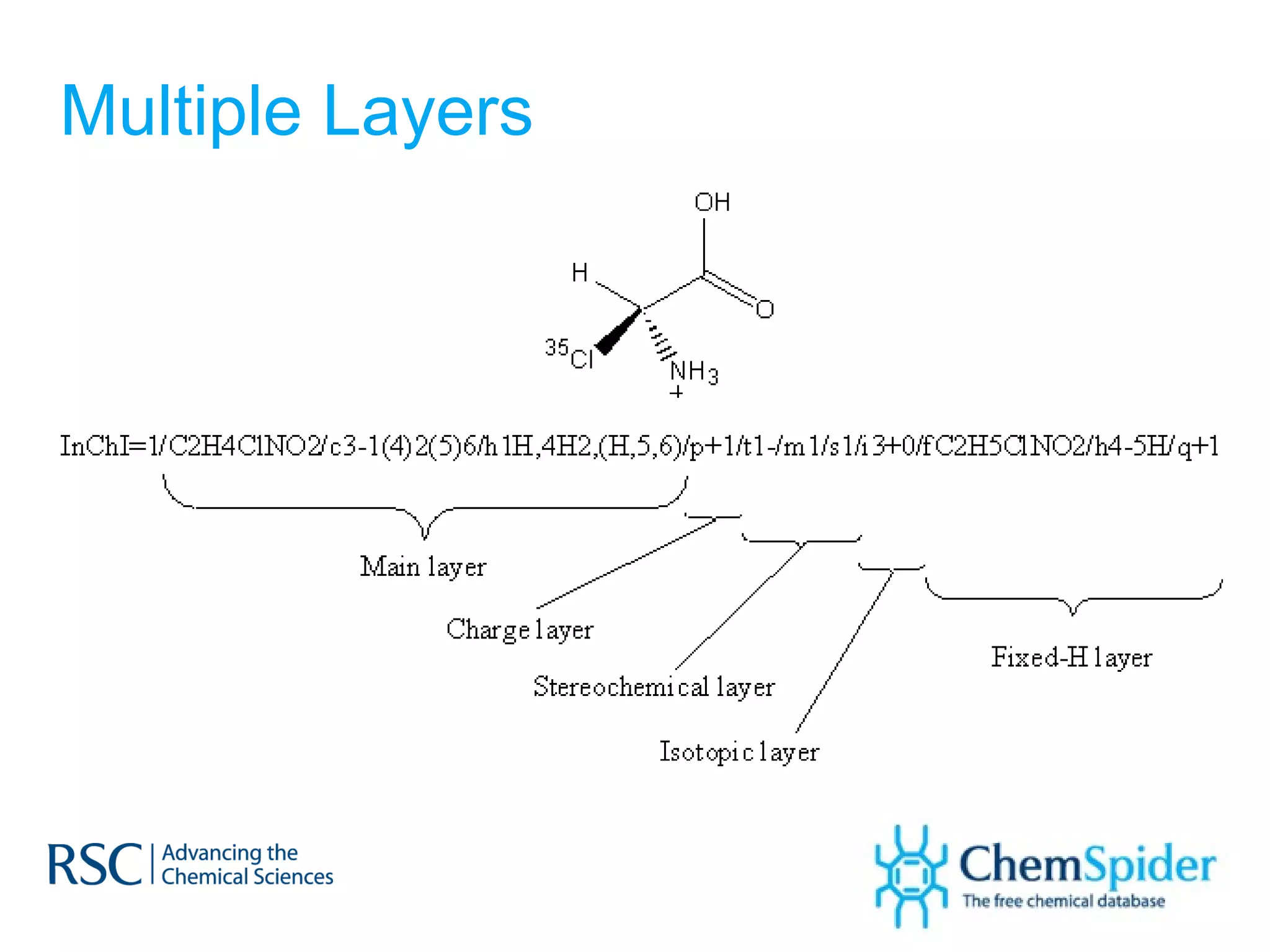
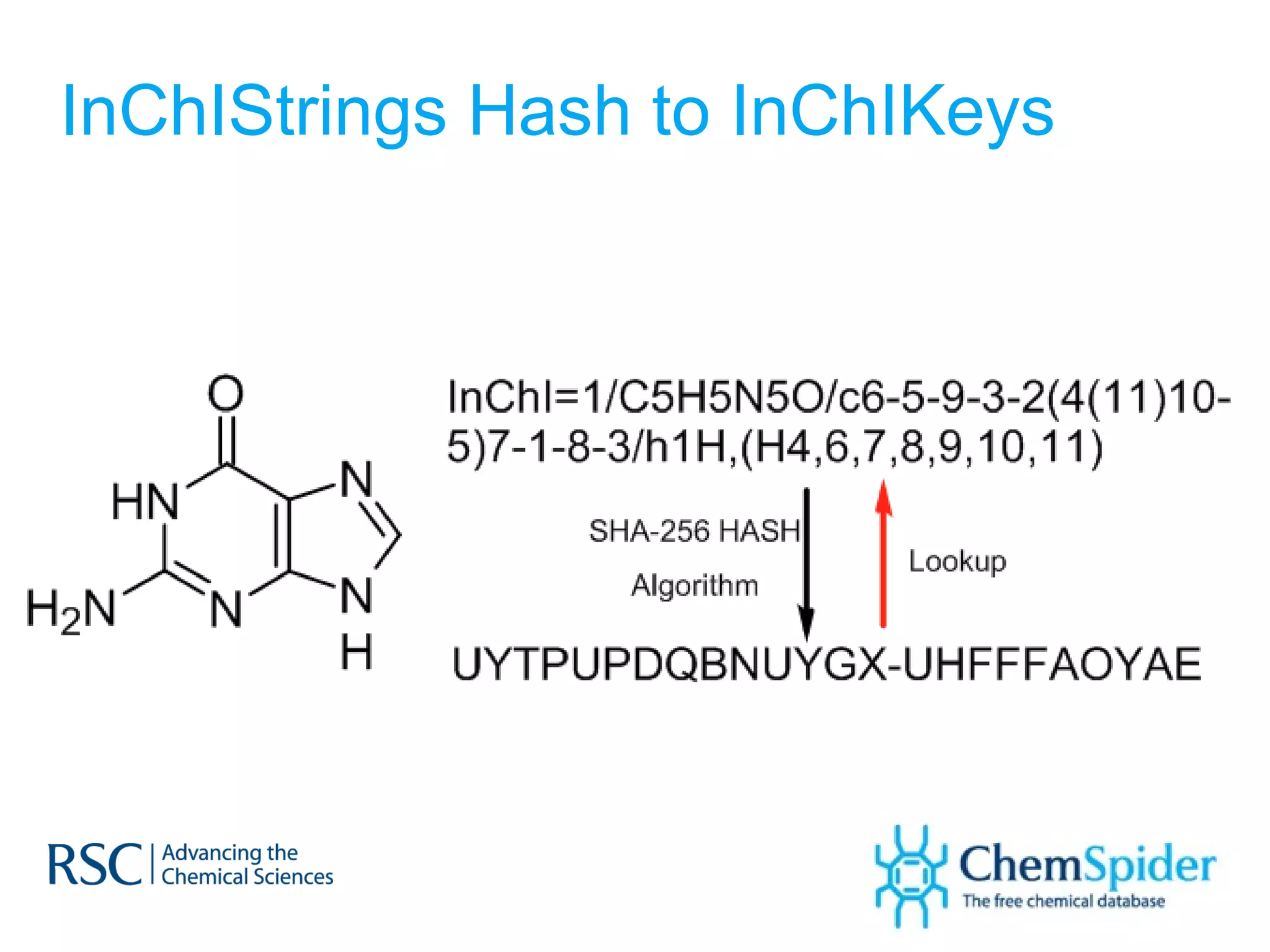
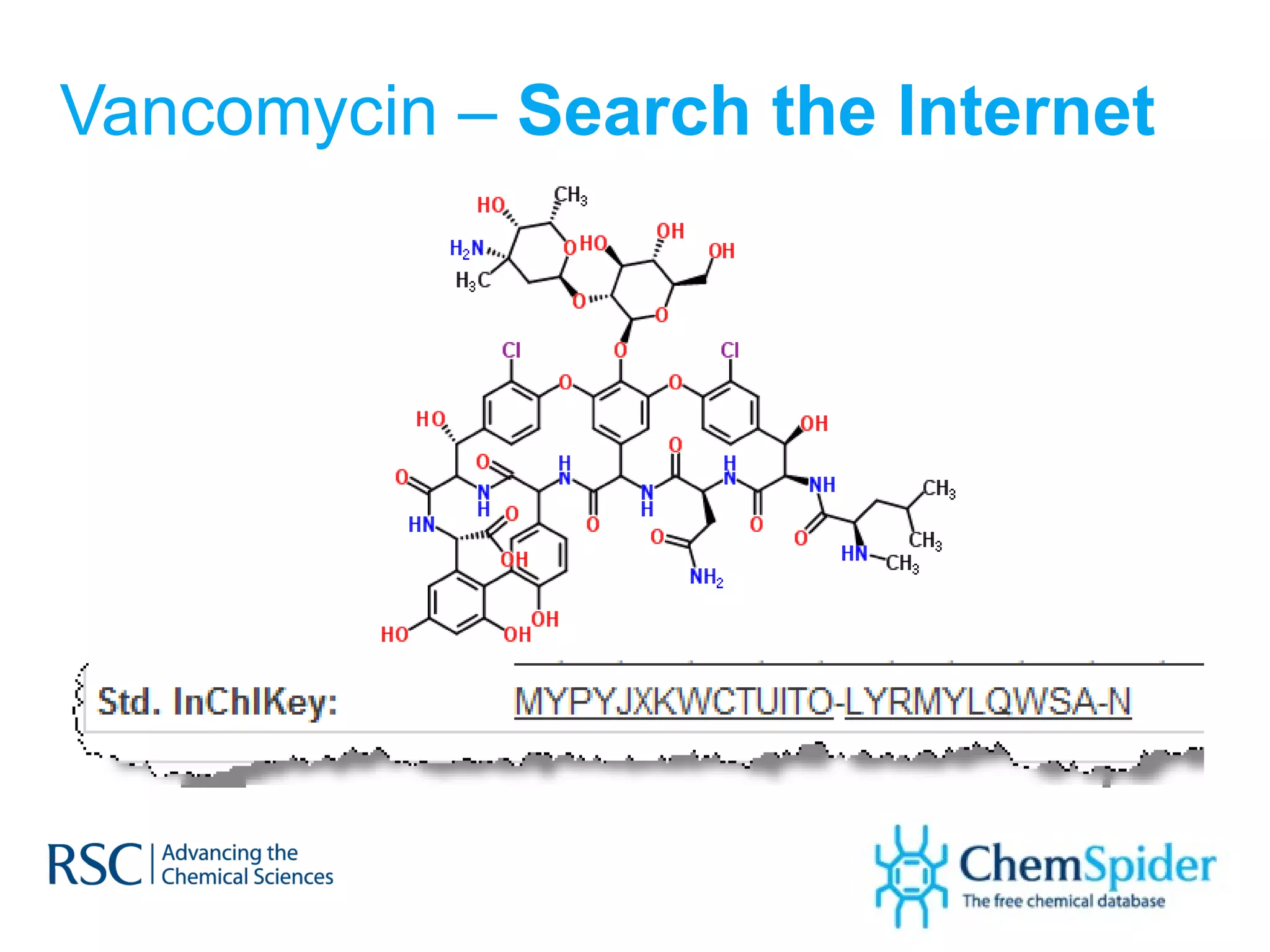
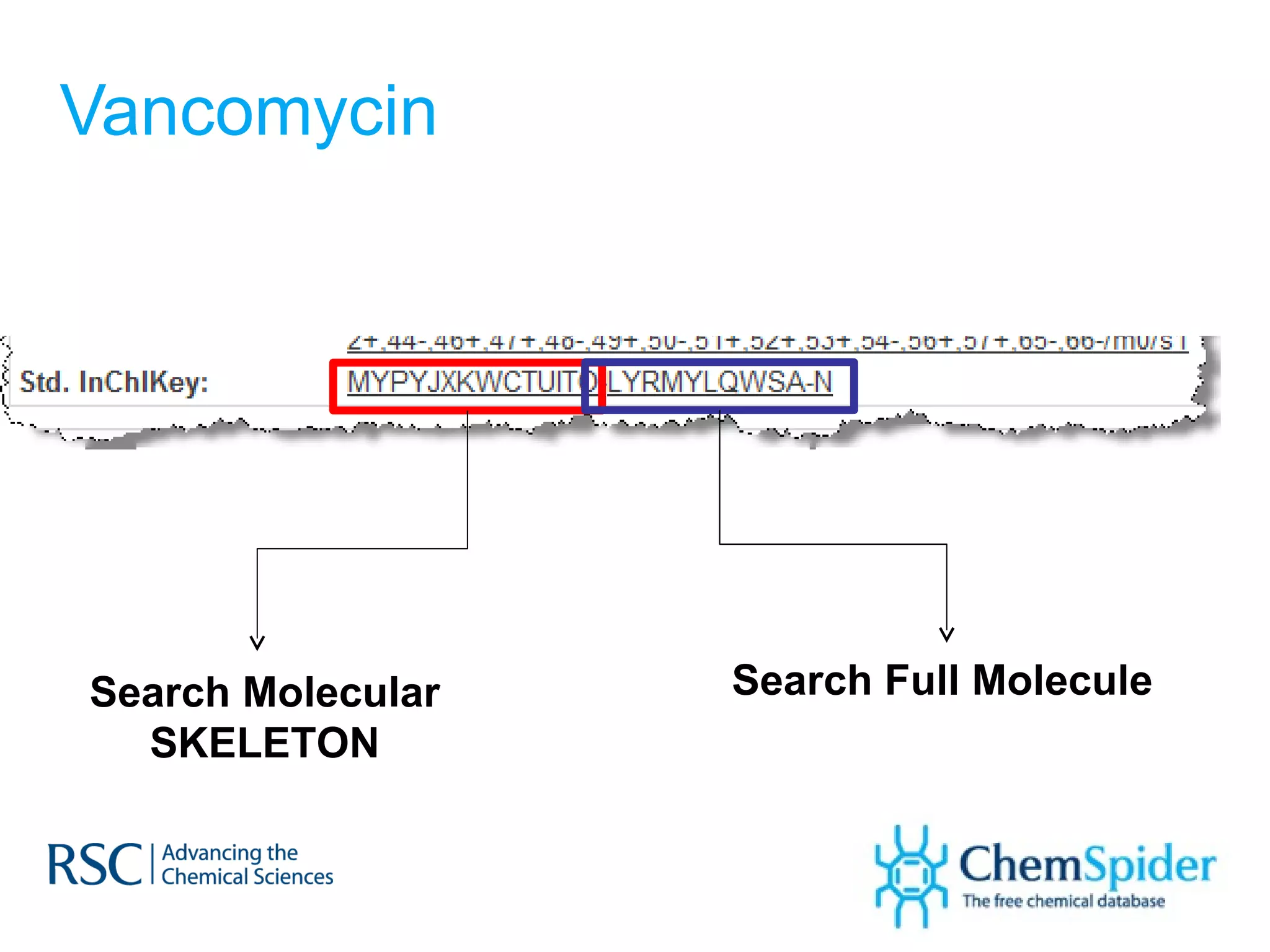

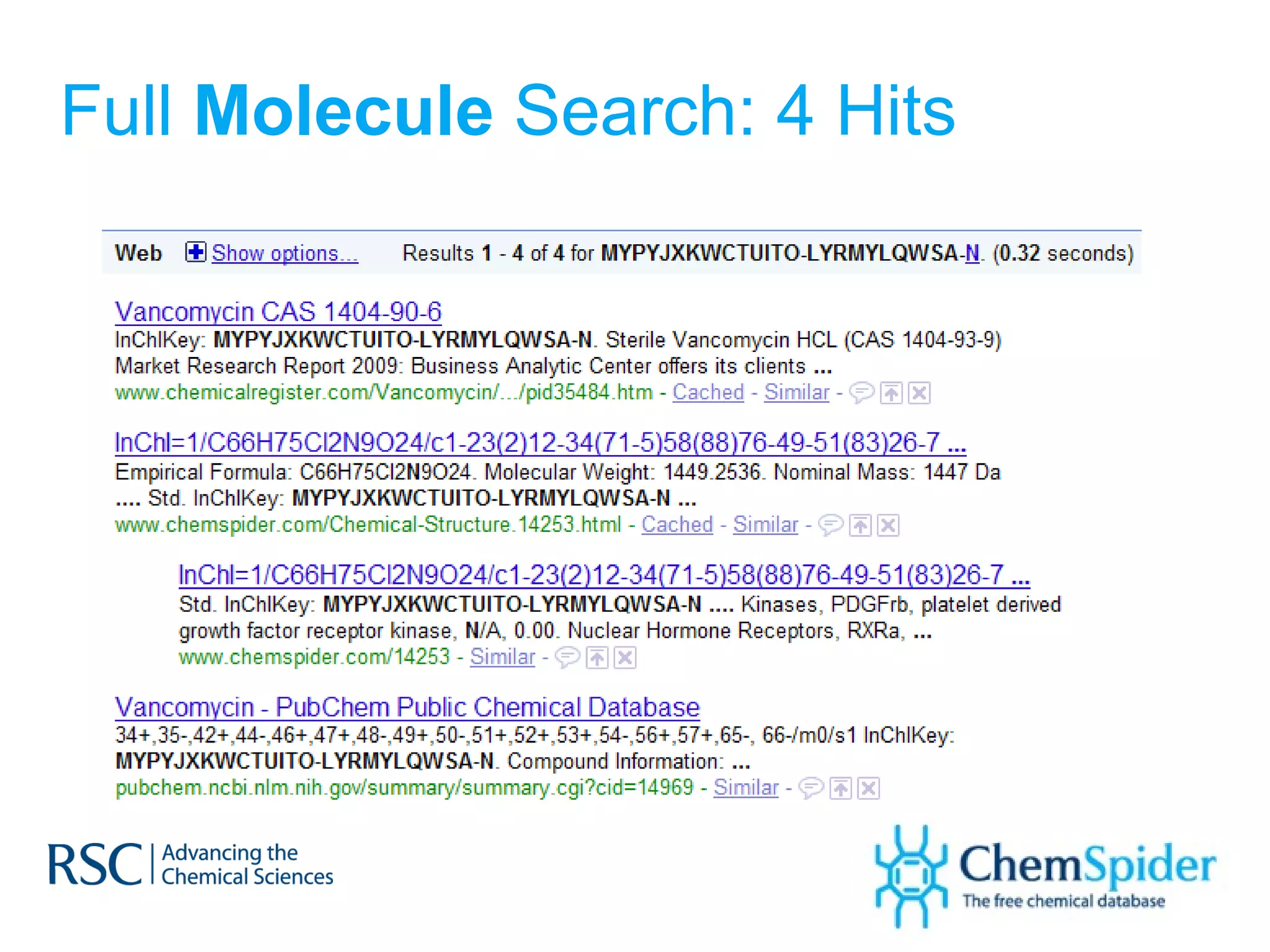






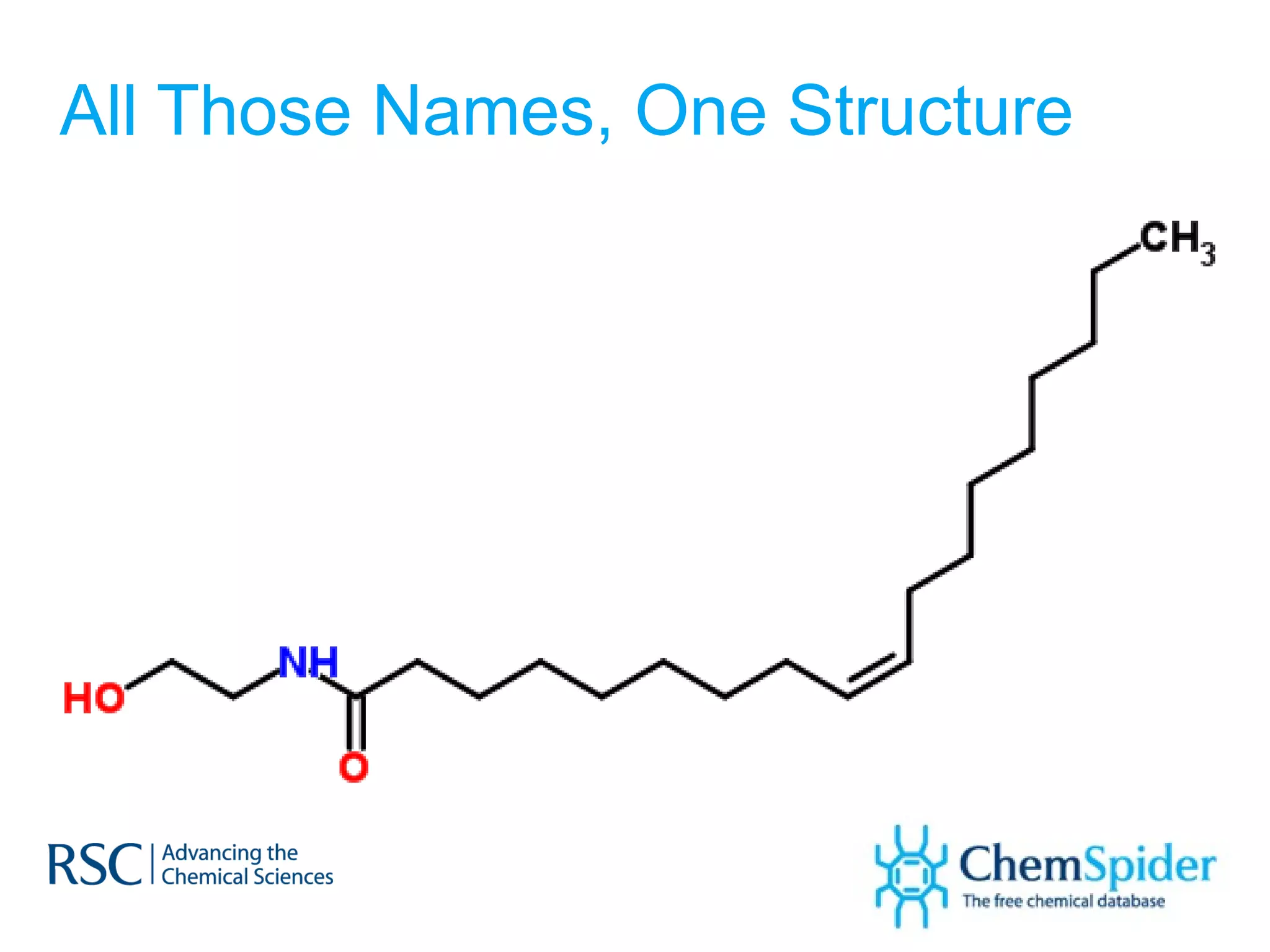




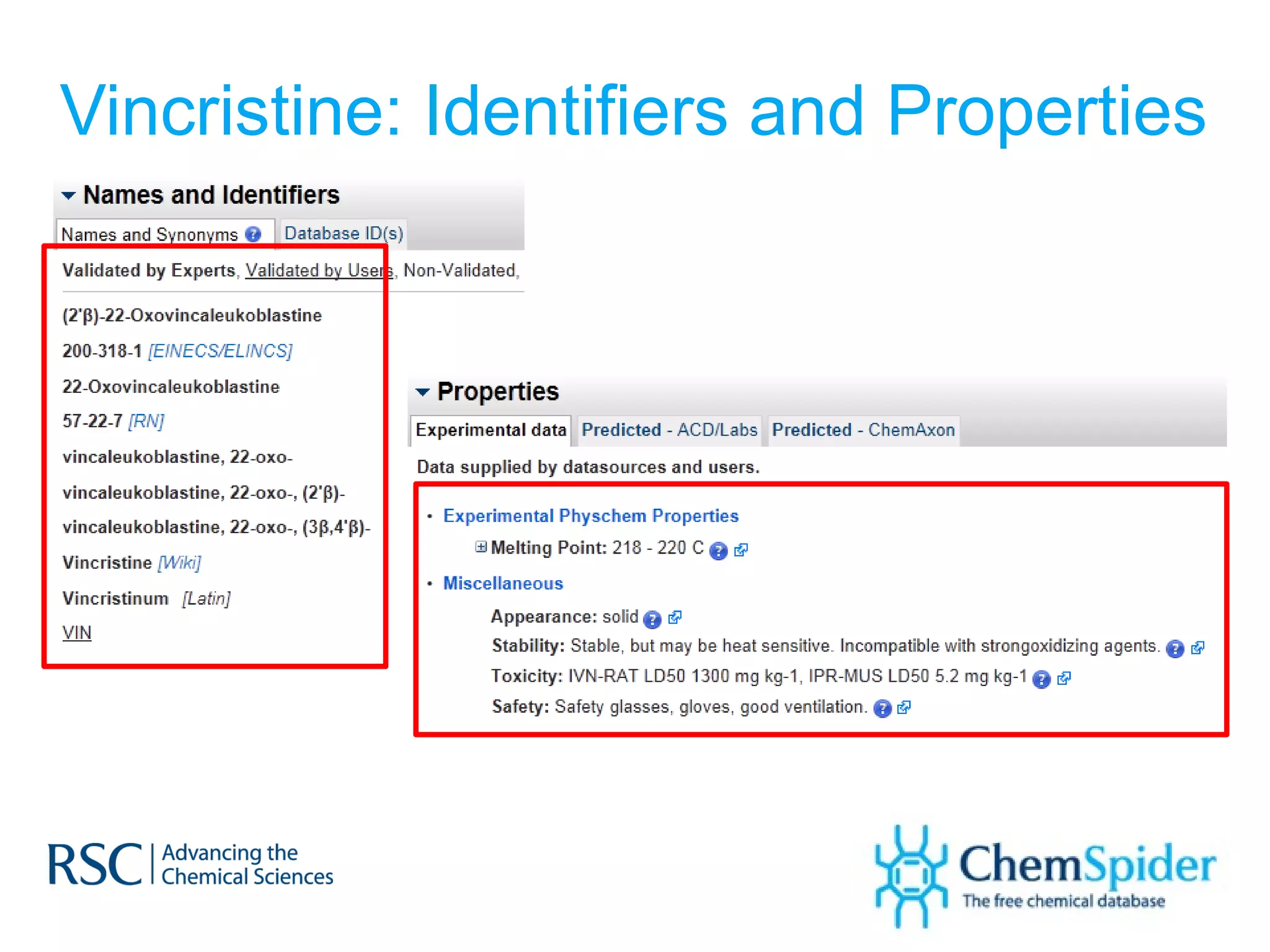
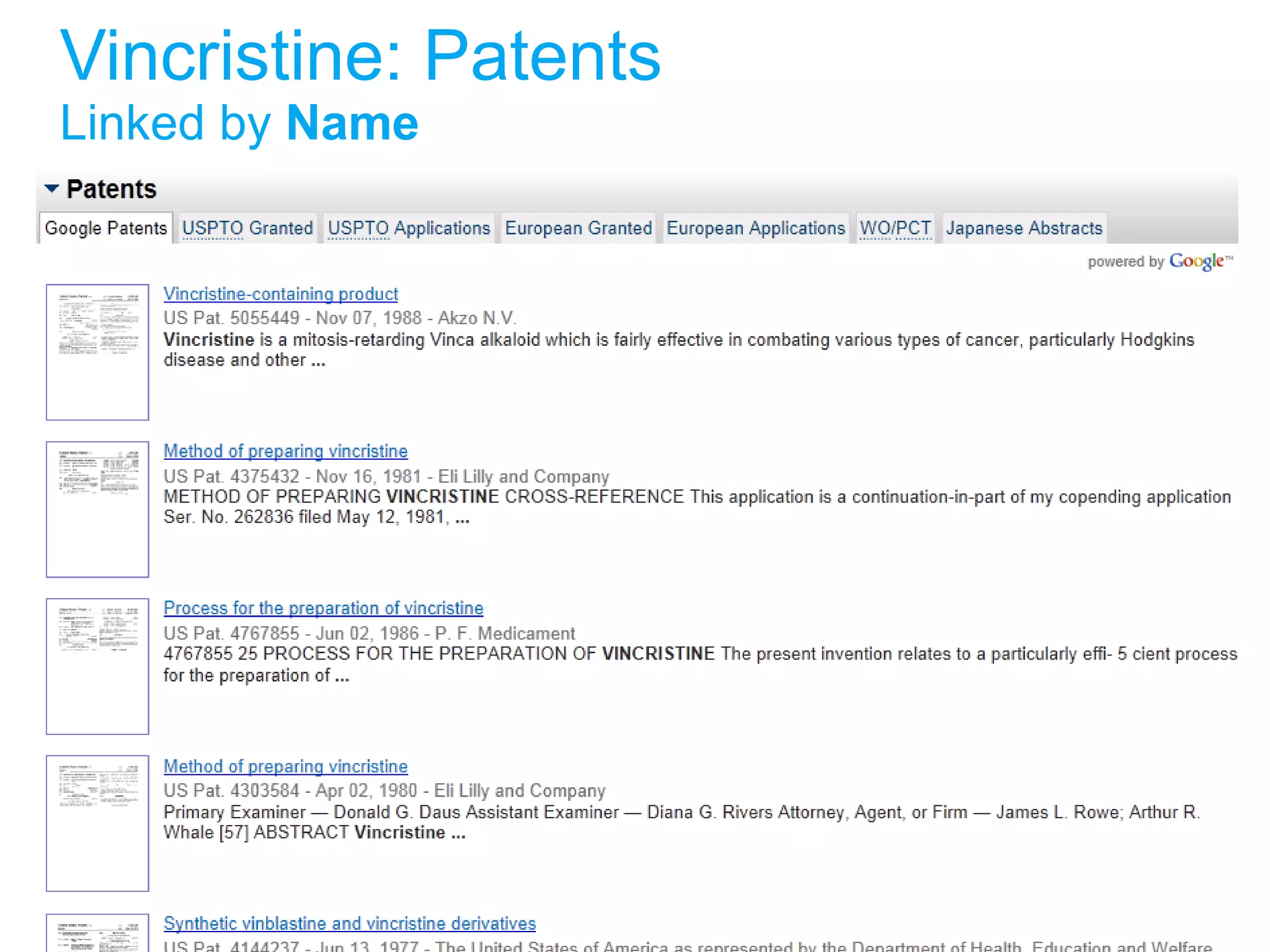




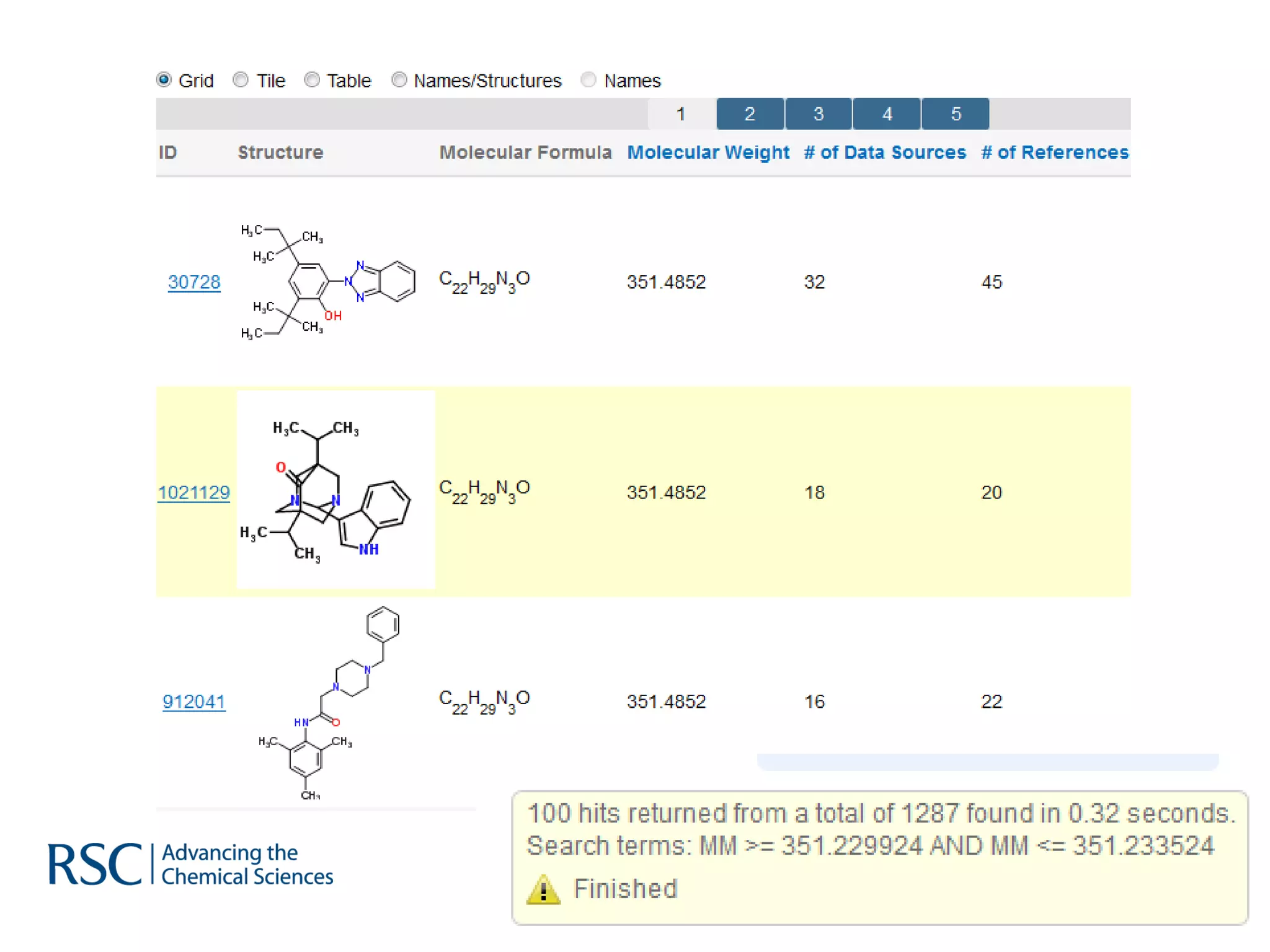
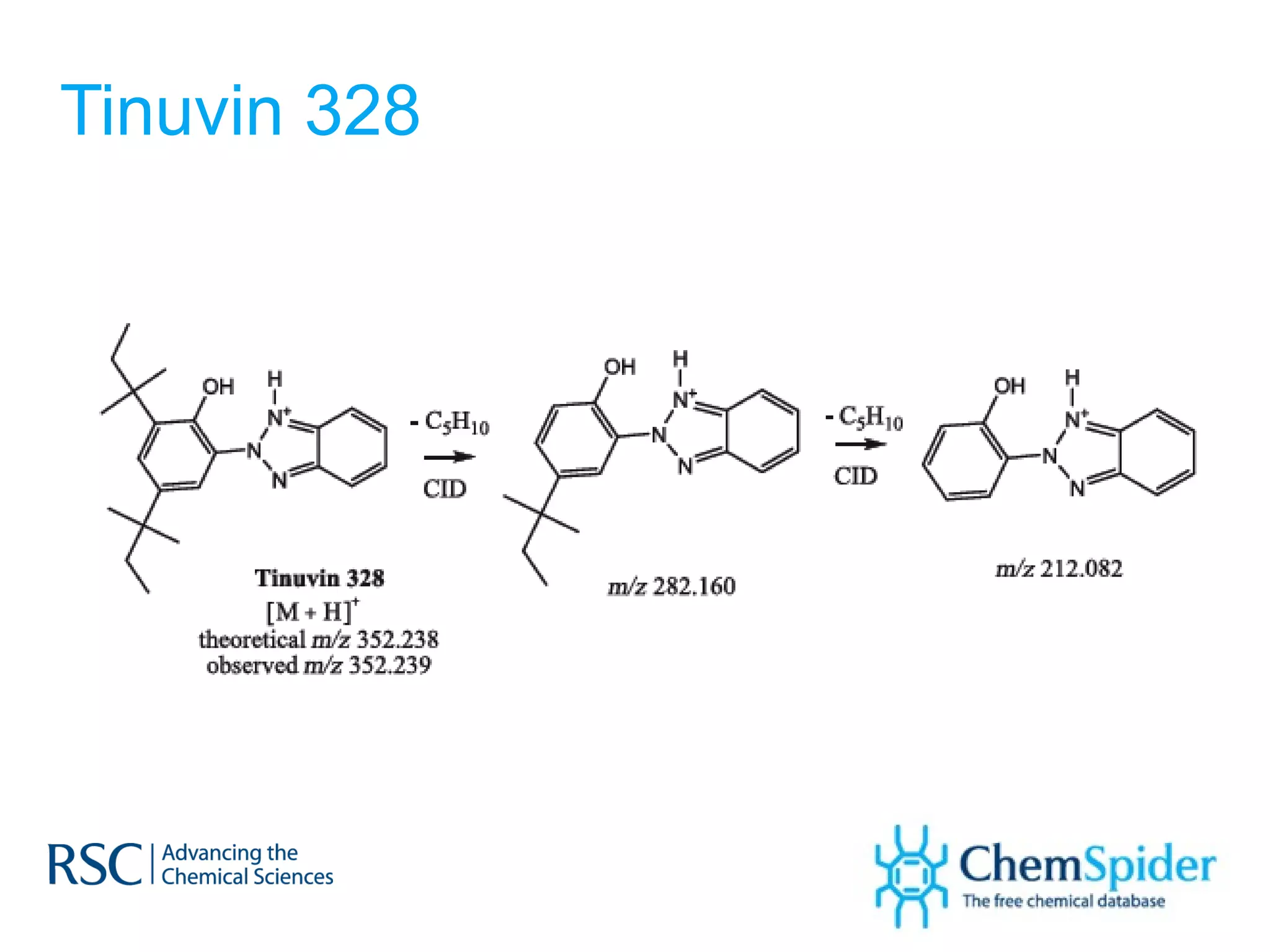
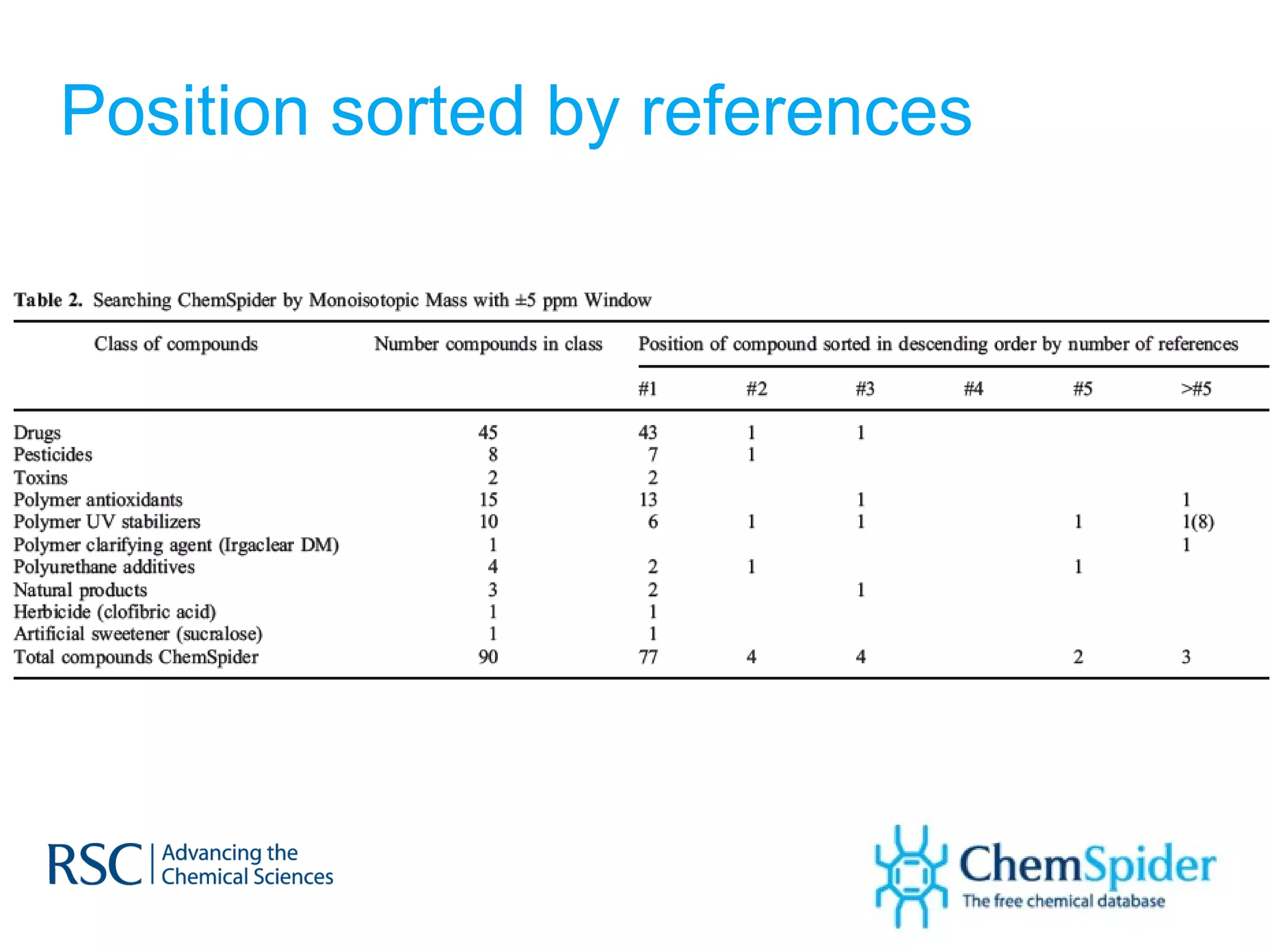
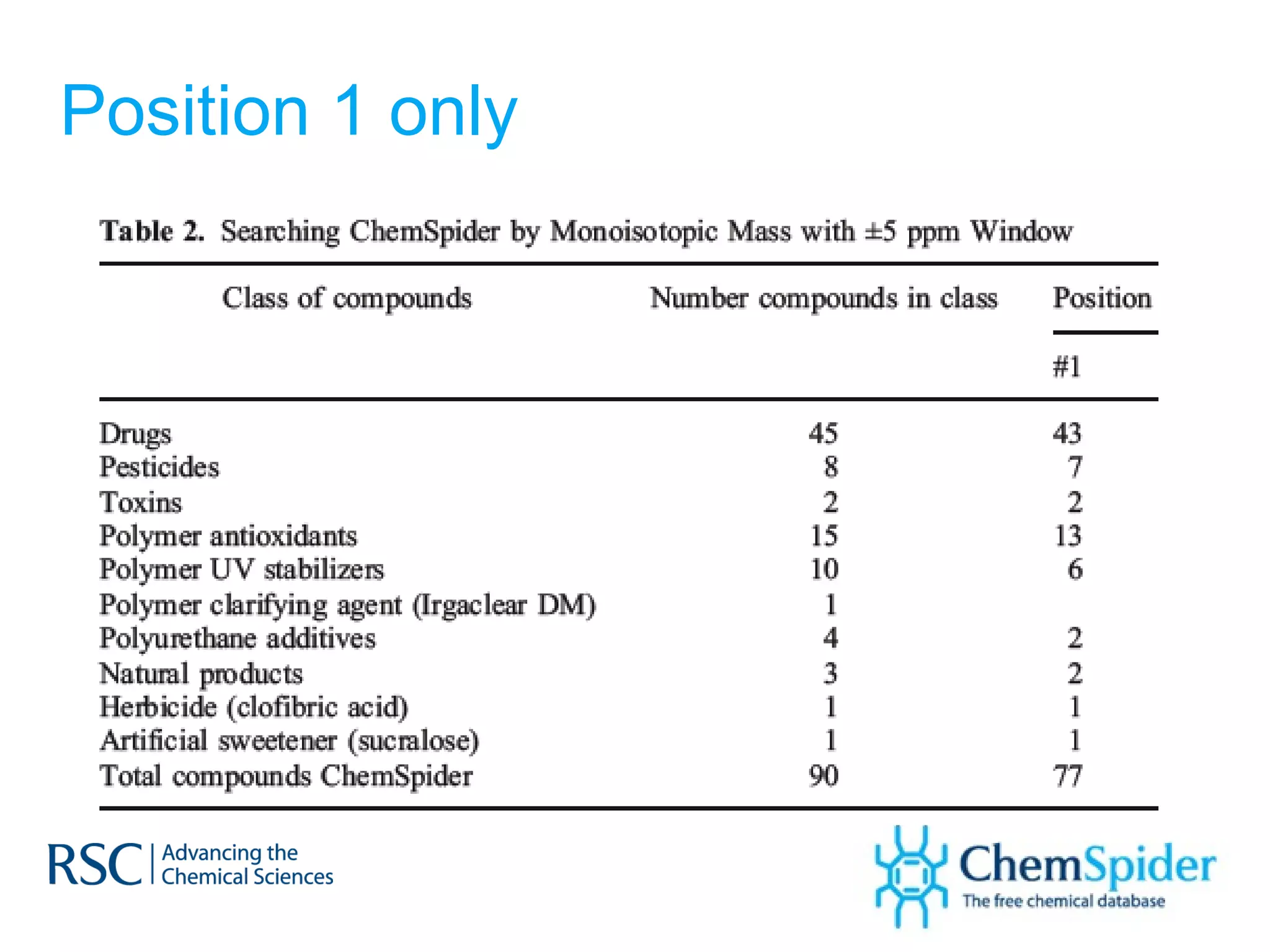




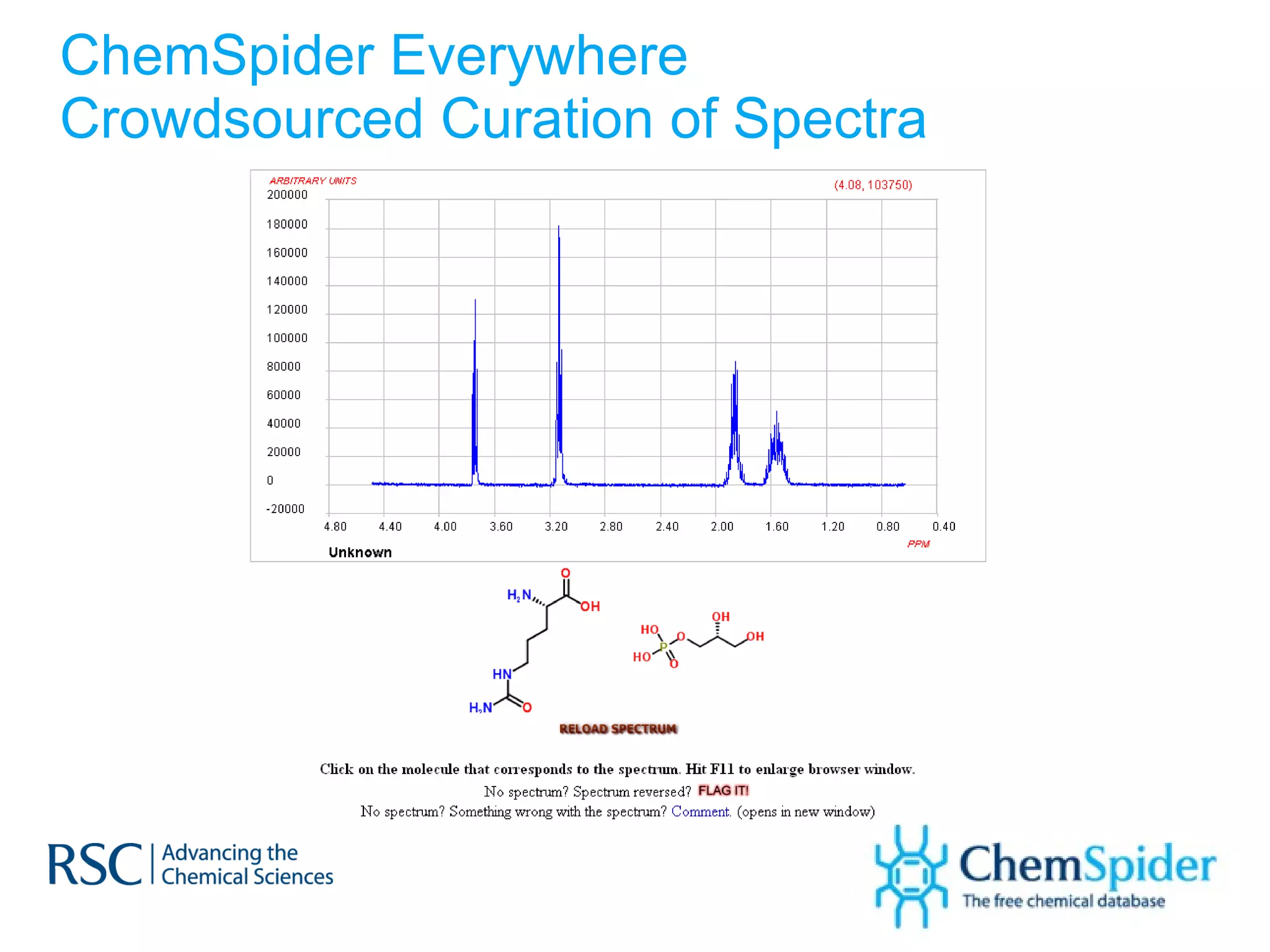

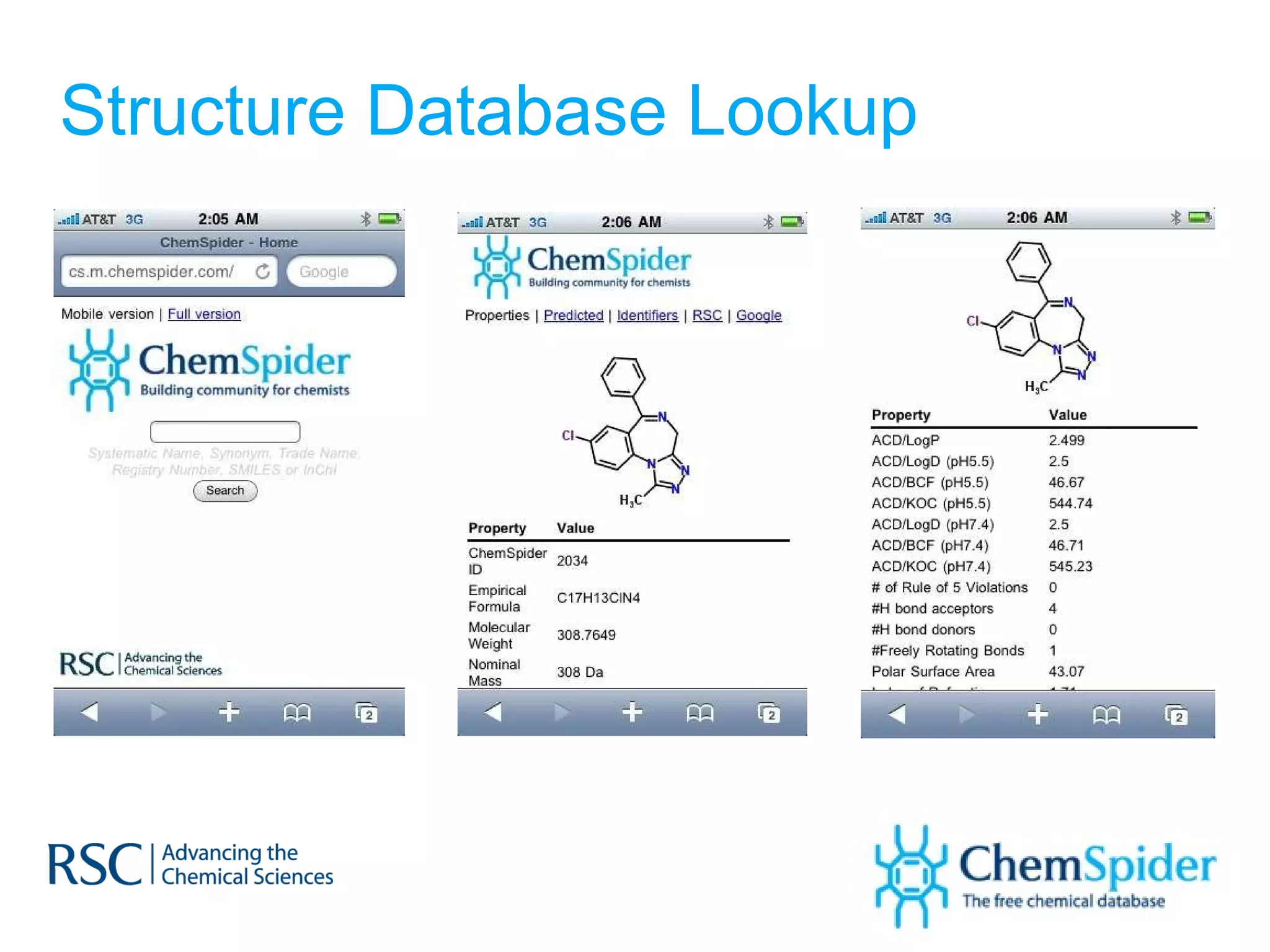

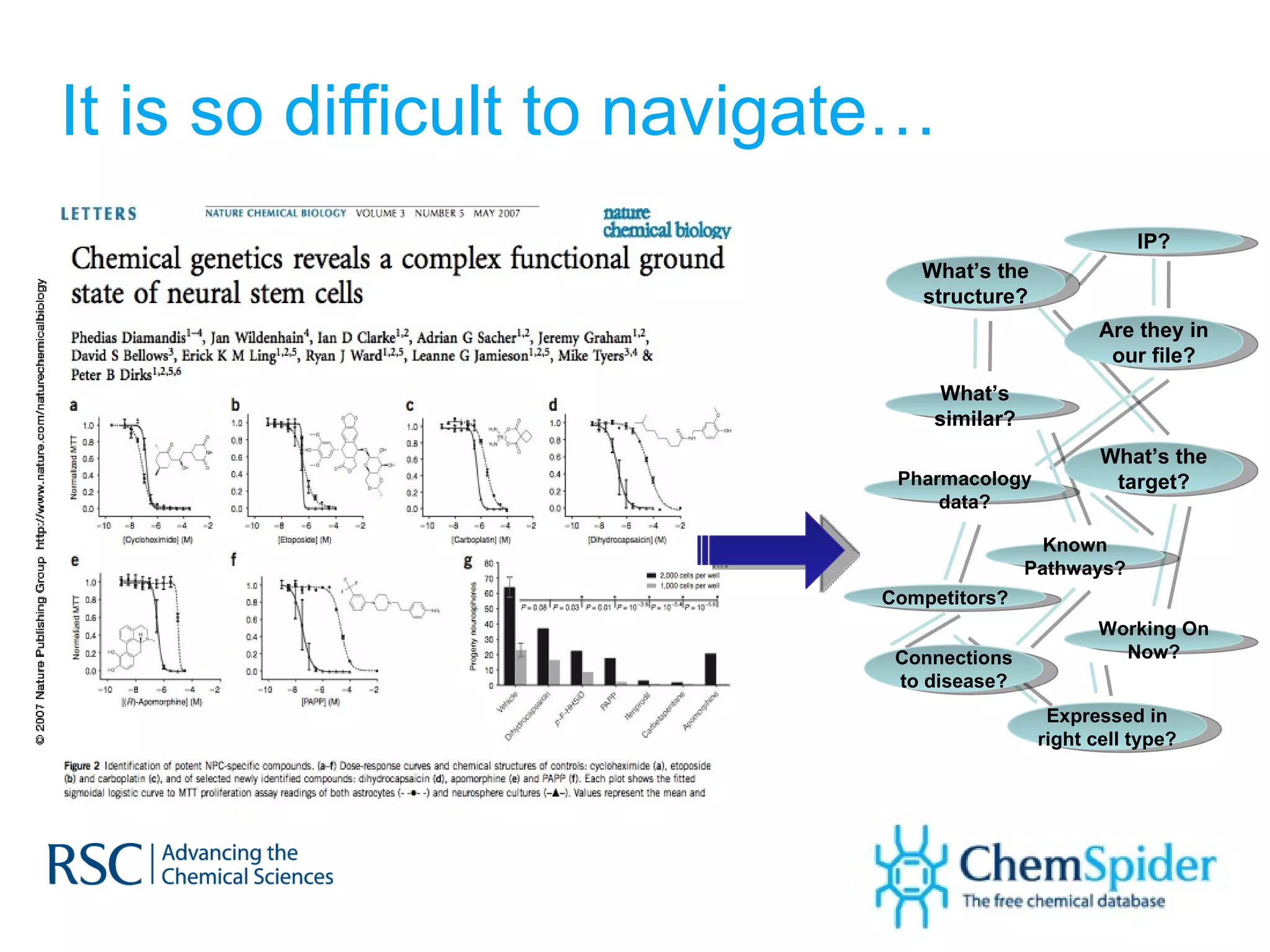


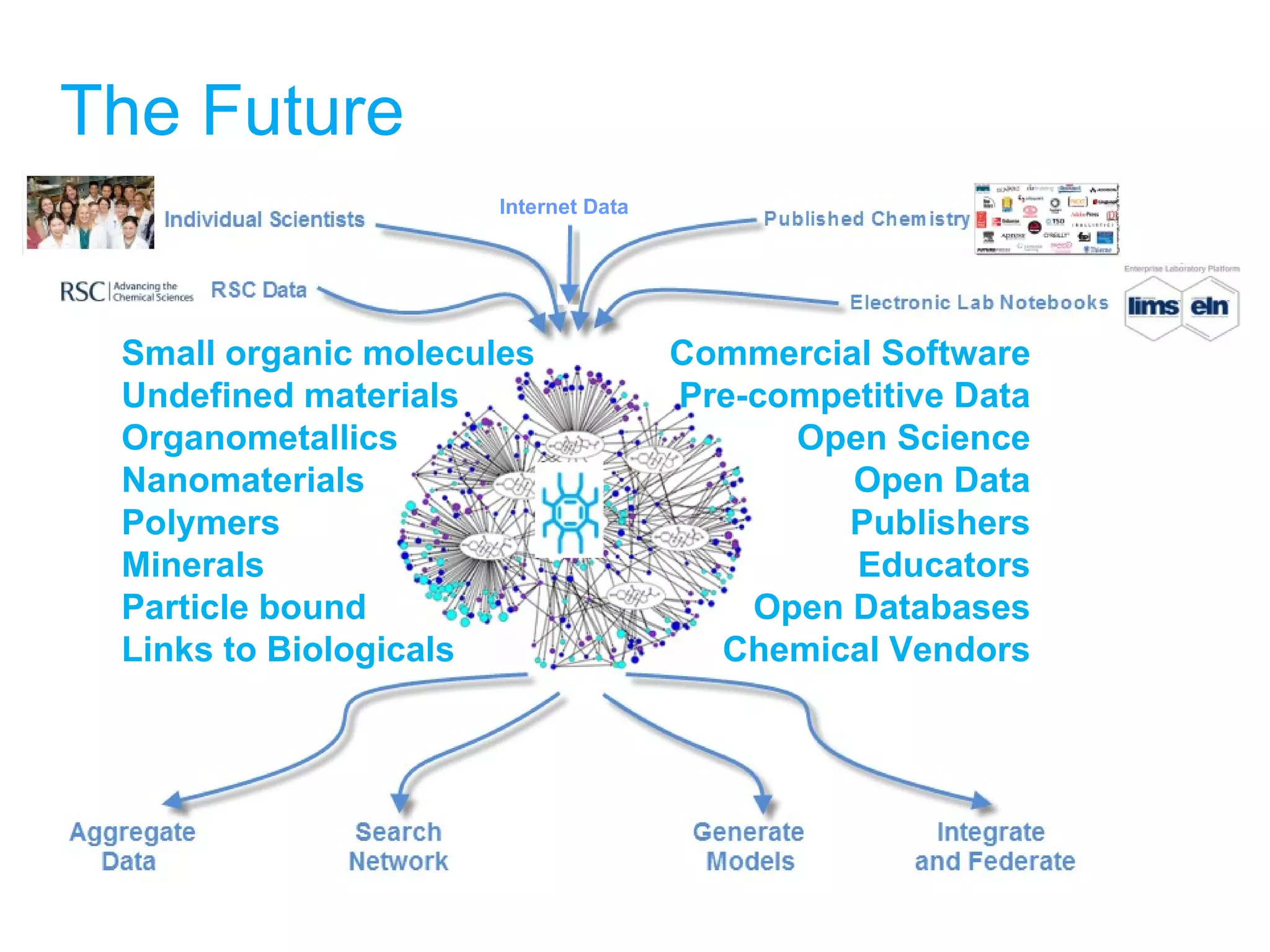



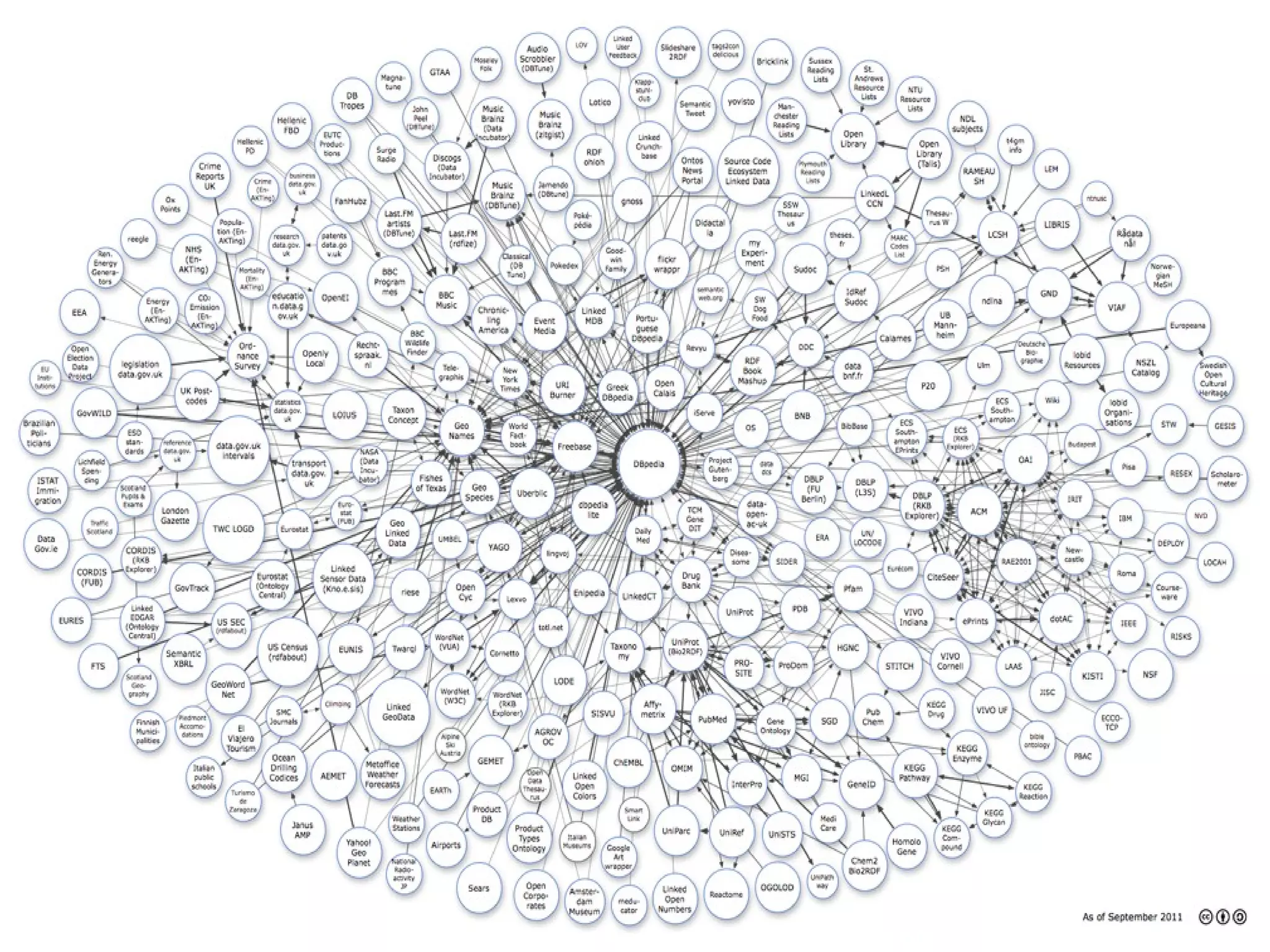
The document discusses the challenges in navigating the vast amounts of data in online chemistry, highlighting the need for better data organization and standards. It emphasizes the importance of crowd-sourced curation and collaboration in improving the accuracy of chemistry databases. The goal is to create a robust semantic integration hub to support drug discovery and enhance access to validated data.


































































