Download as PDF, PPTX








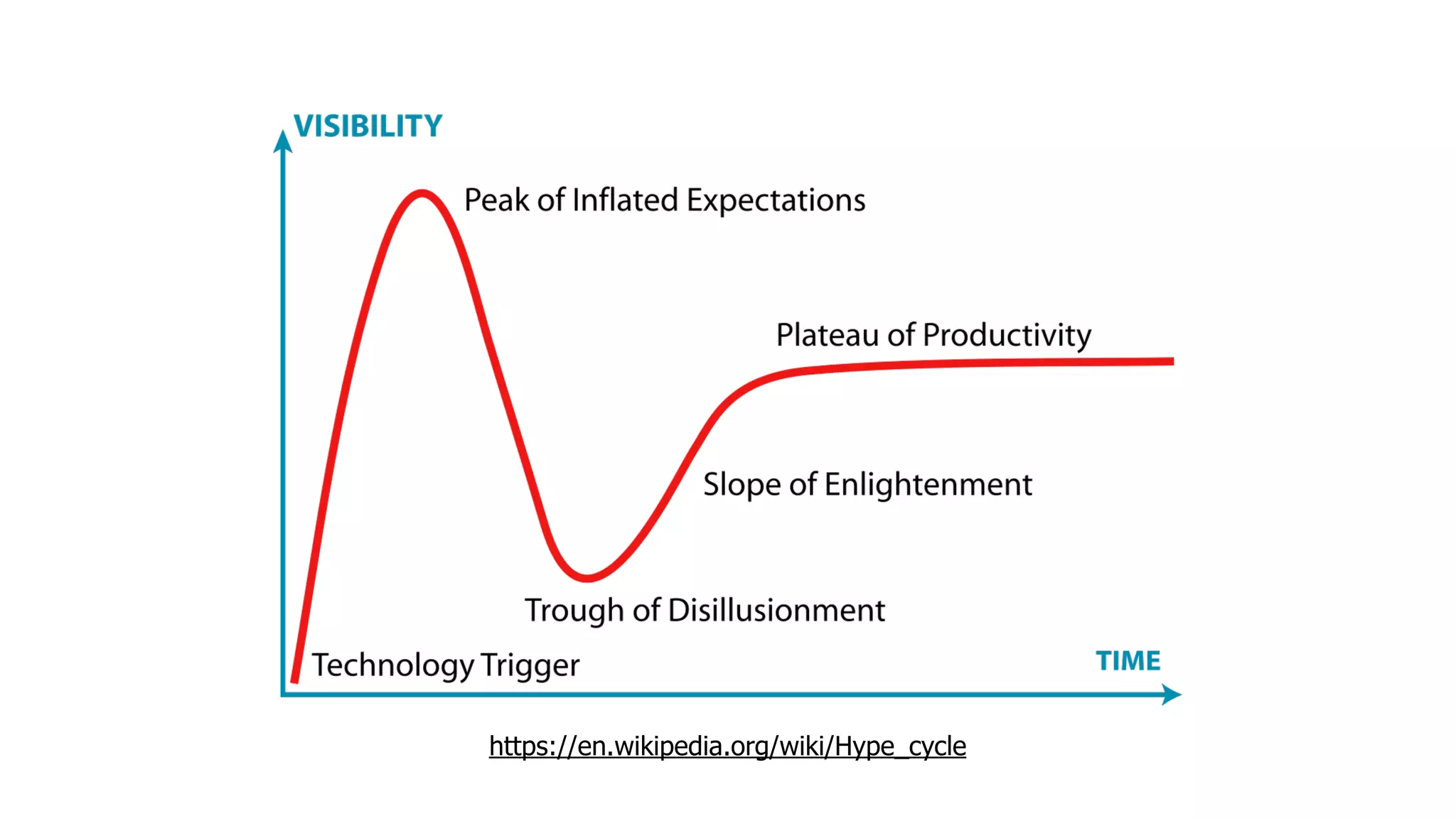
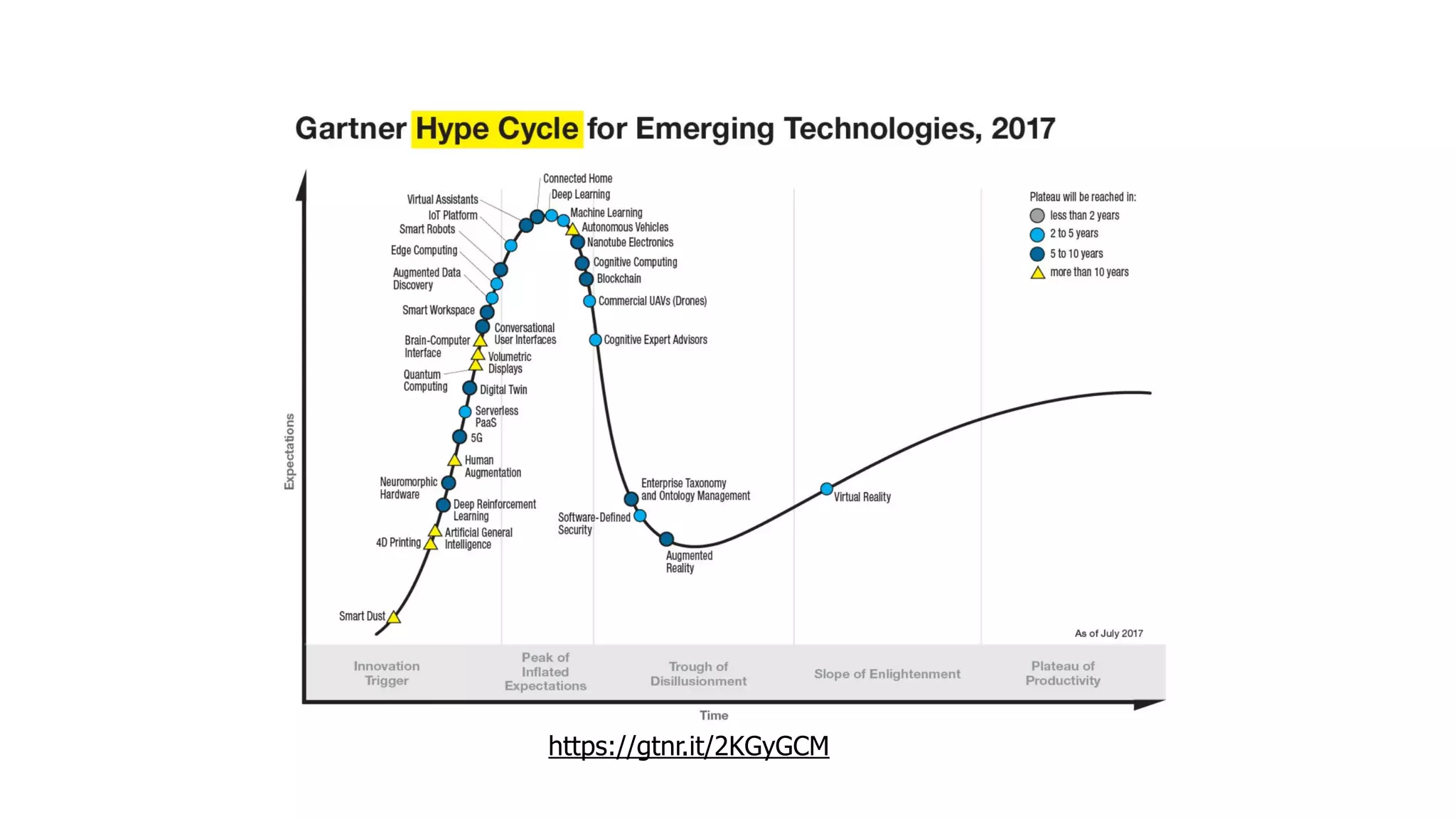
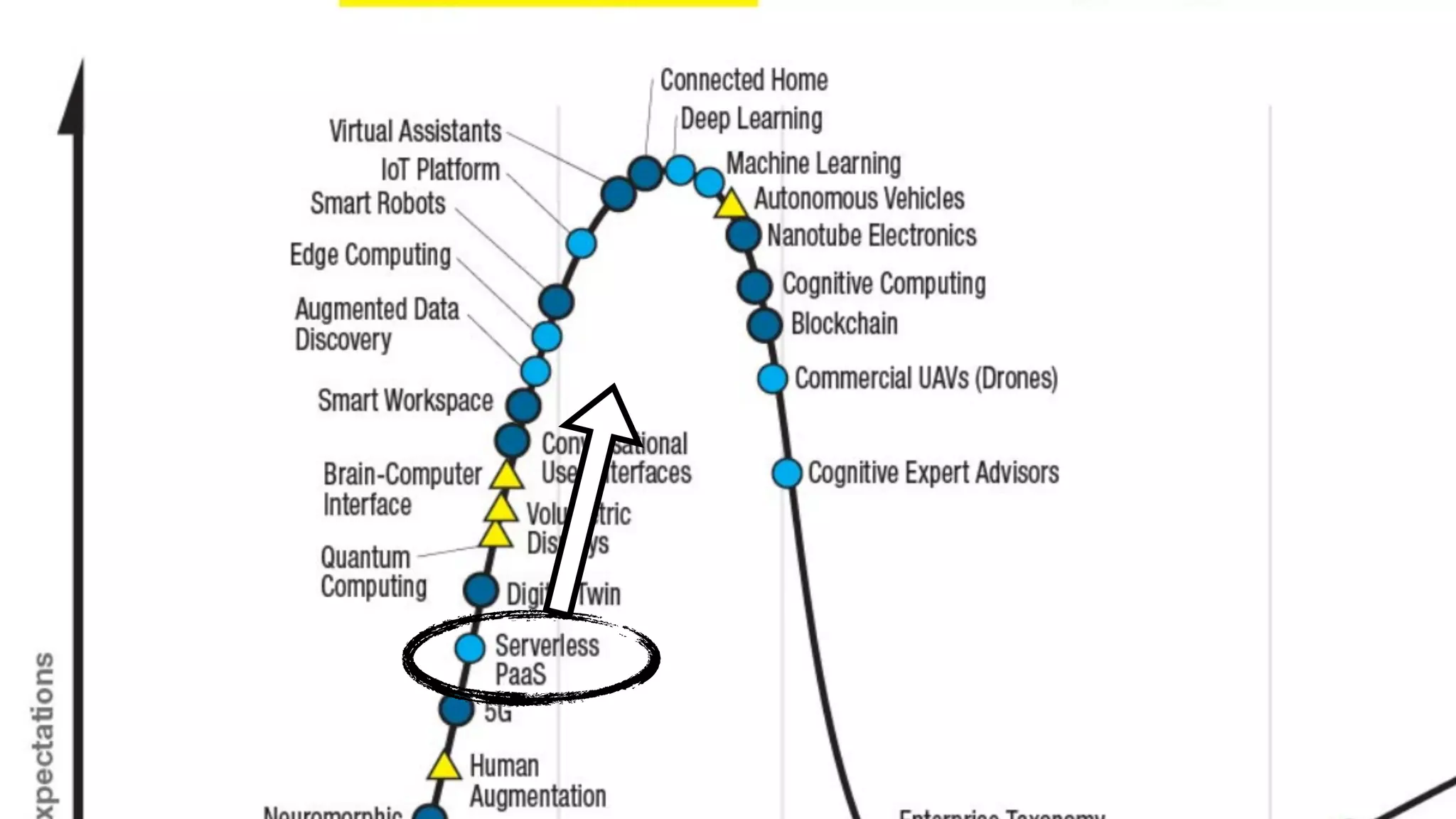
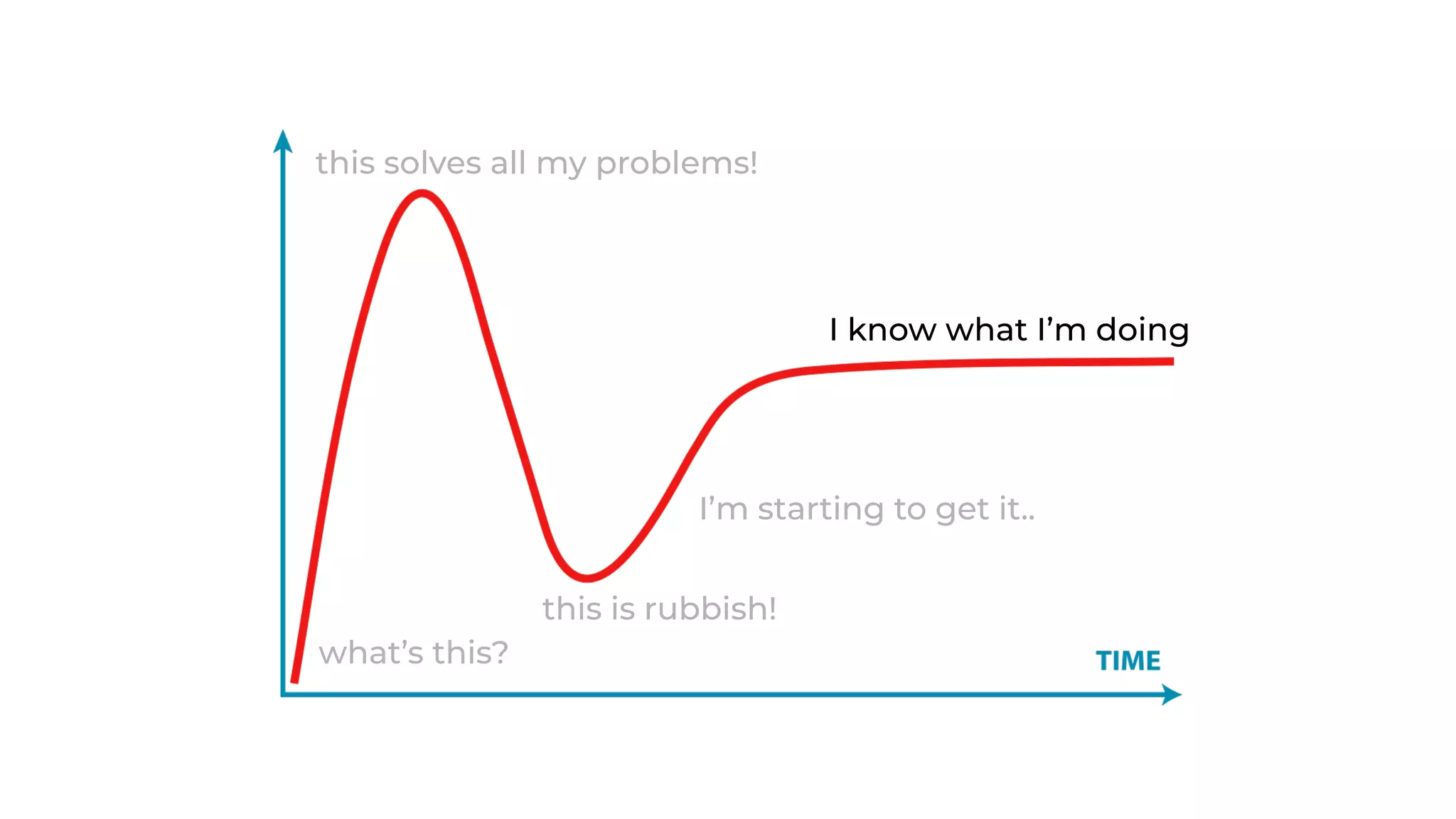
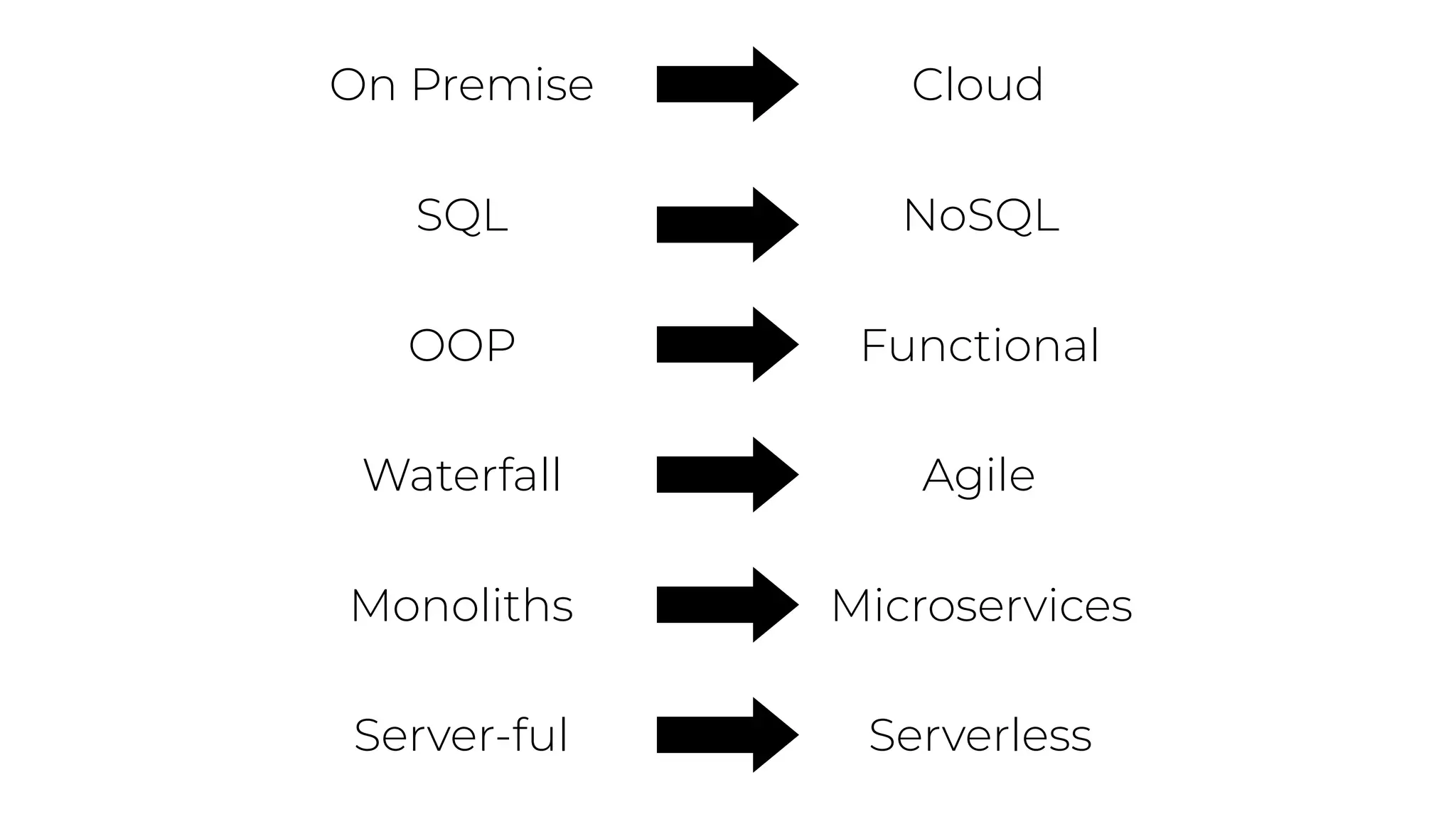

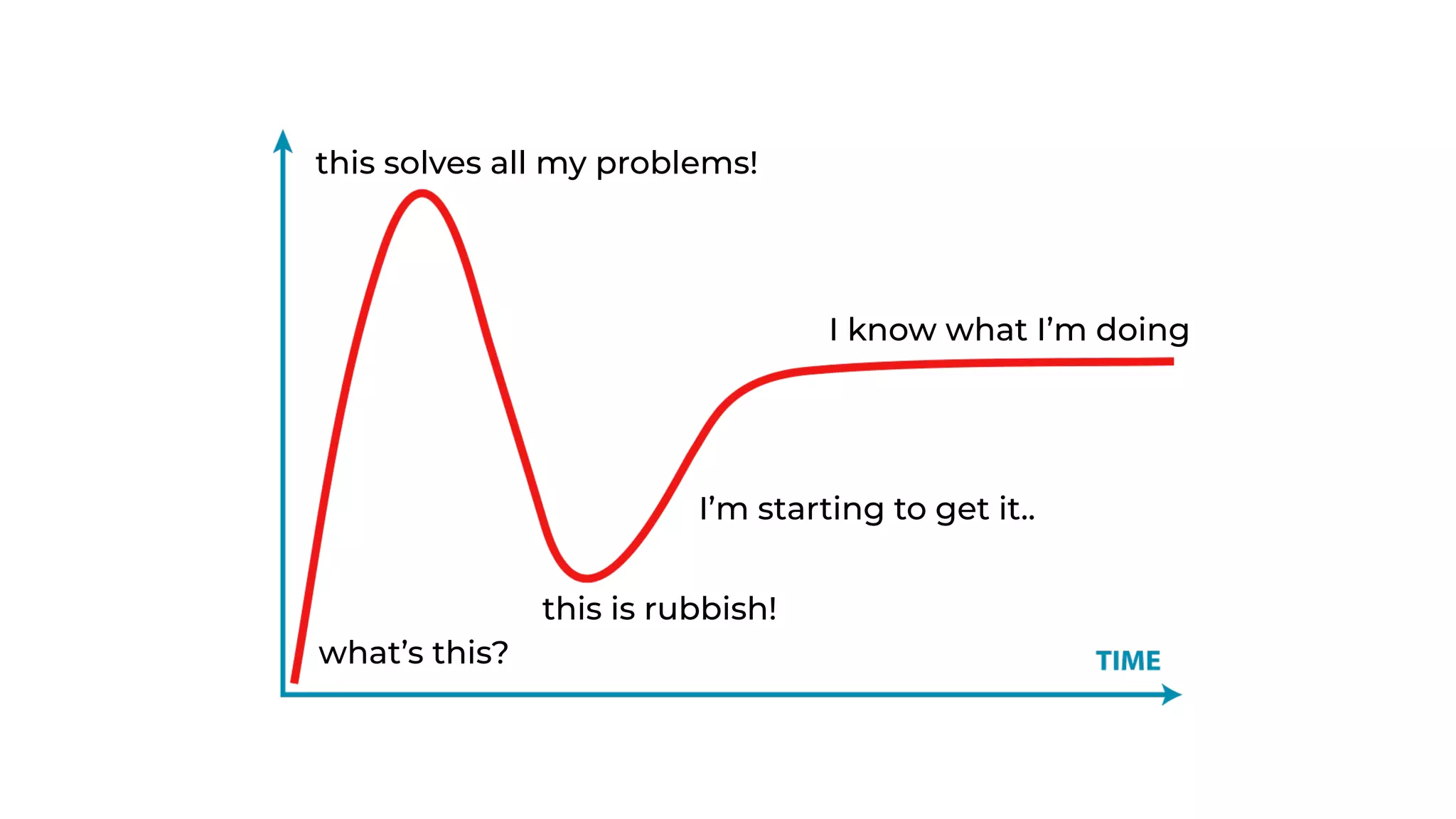



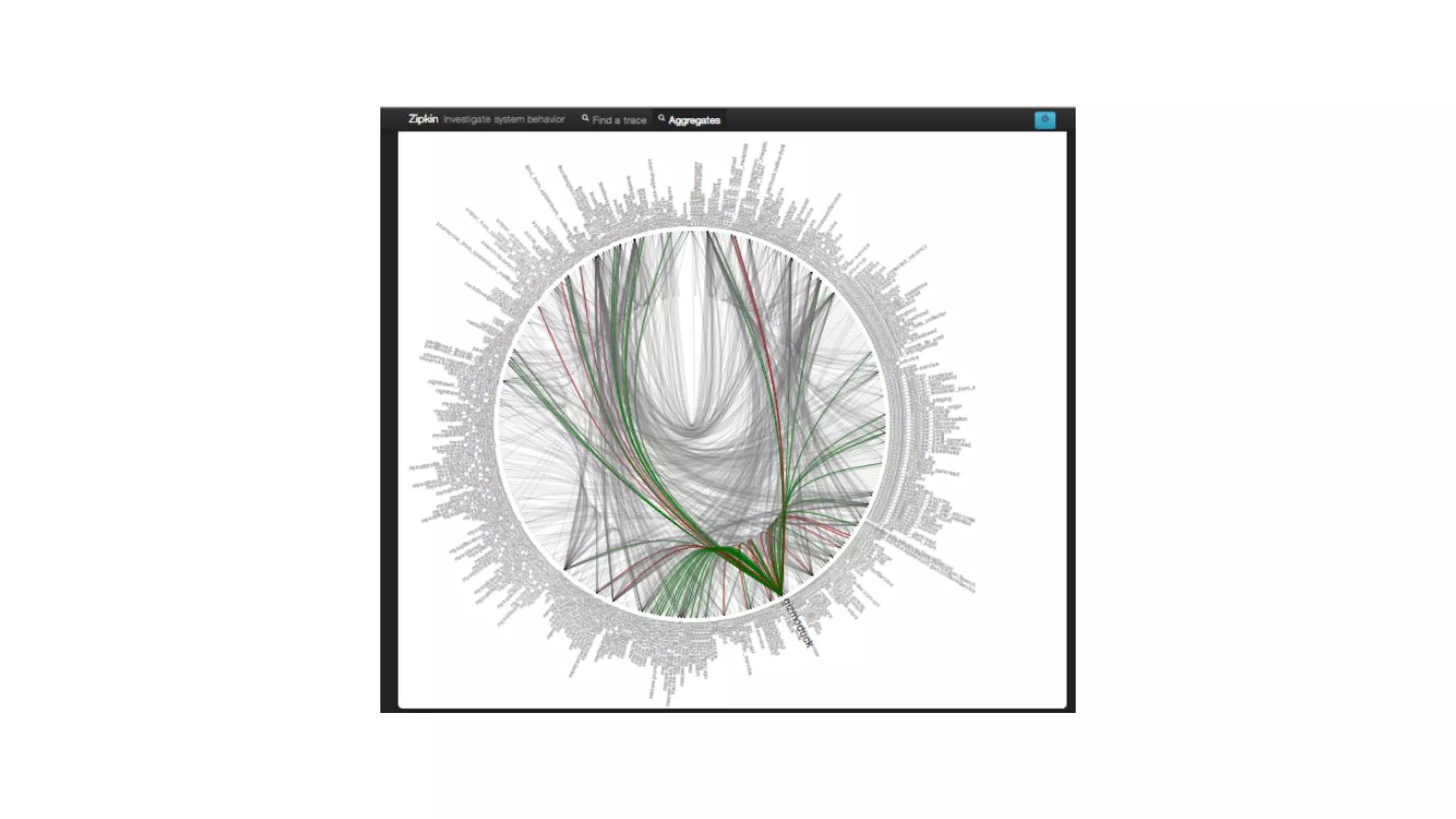



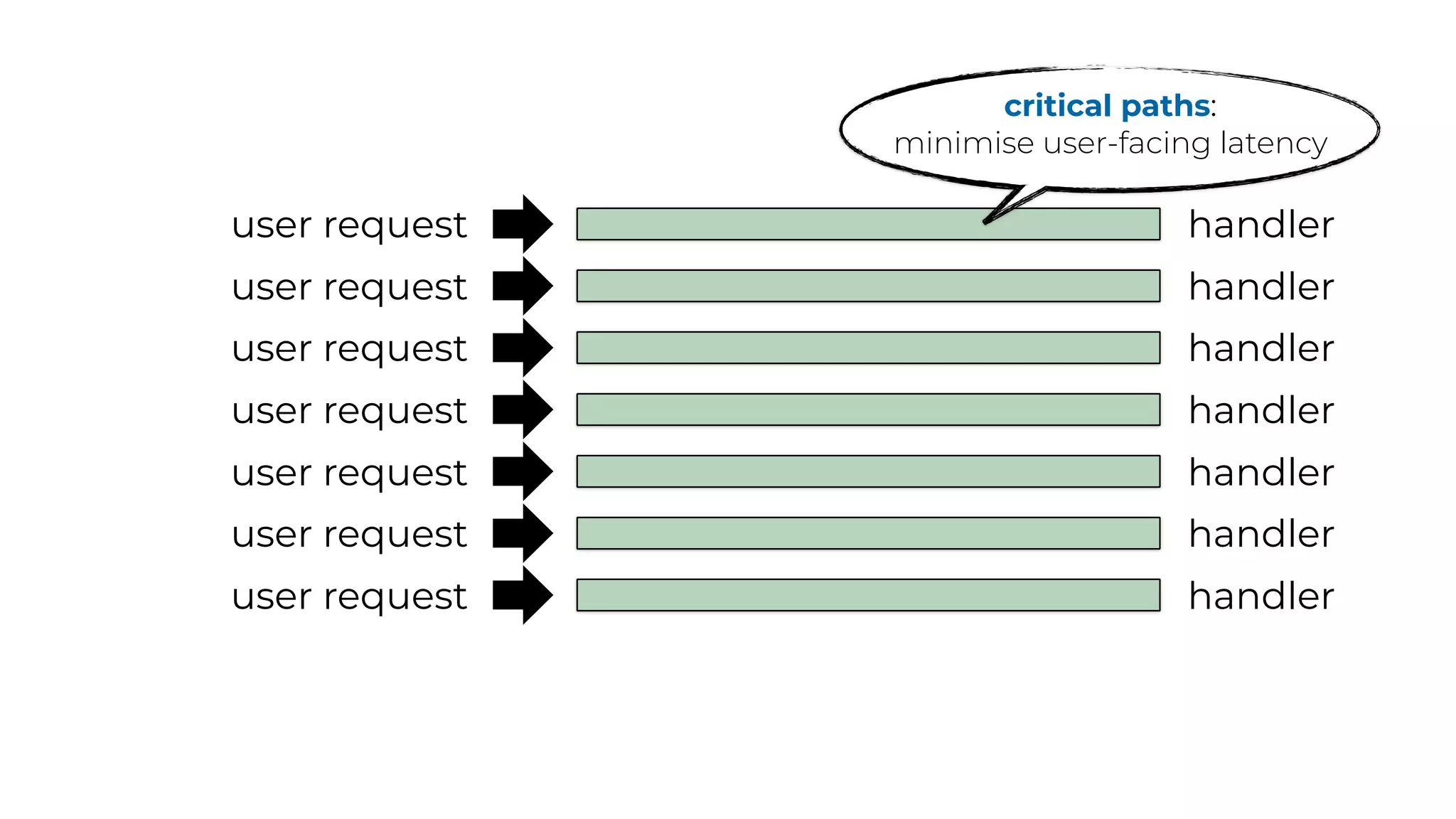
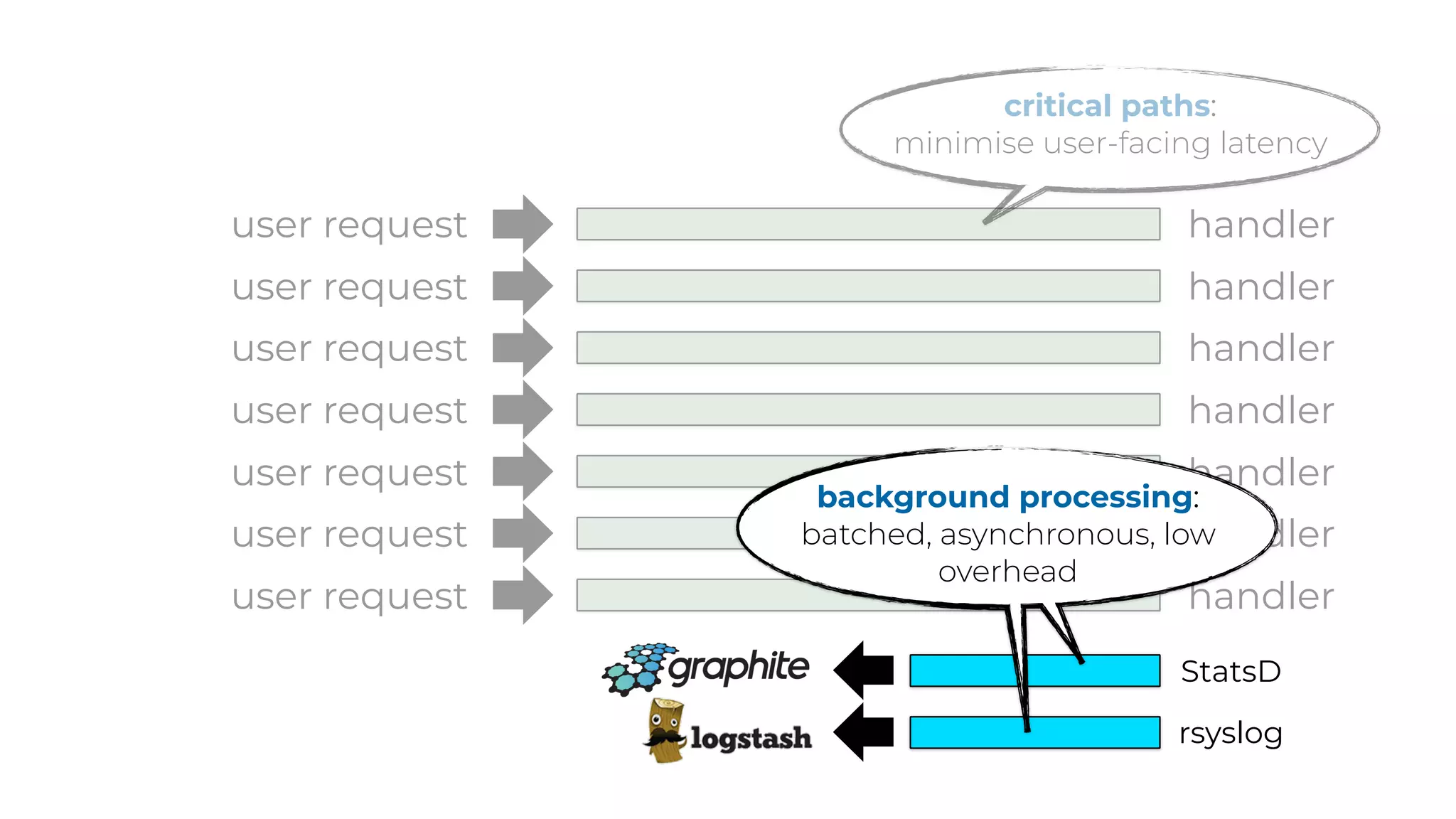
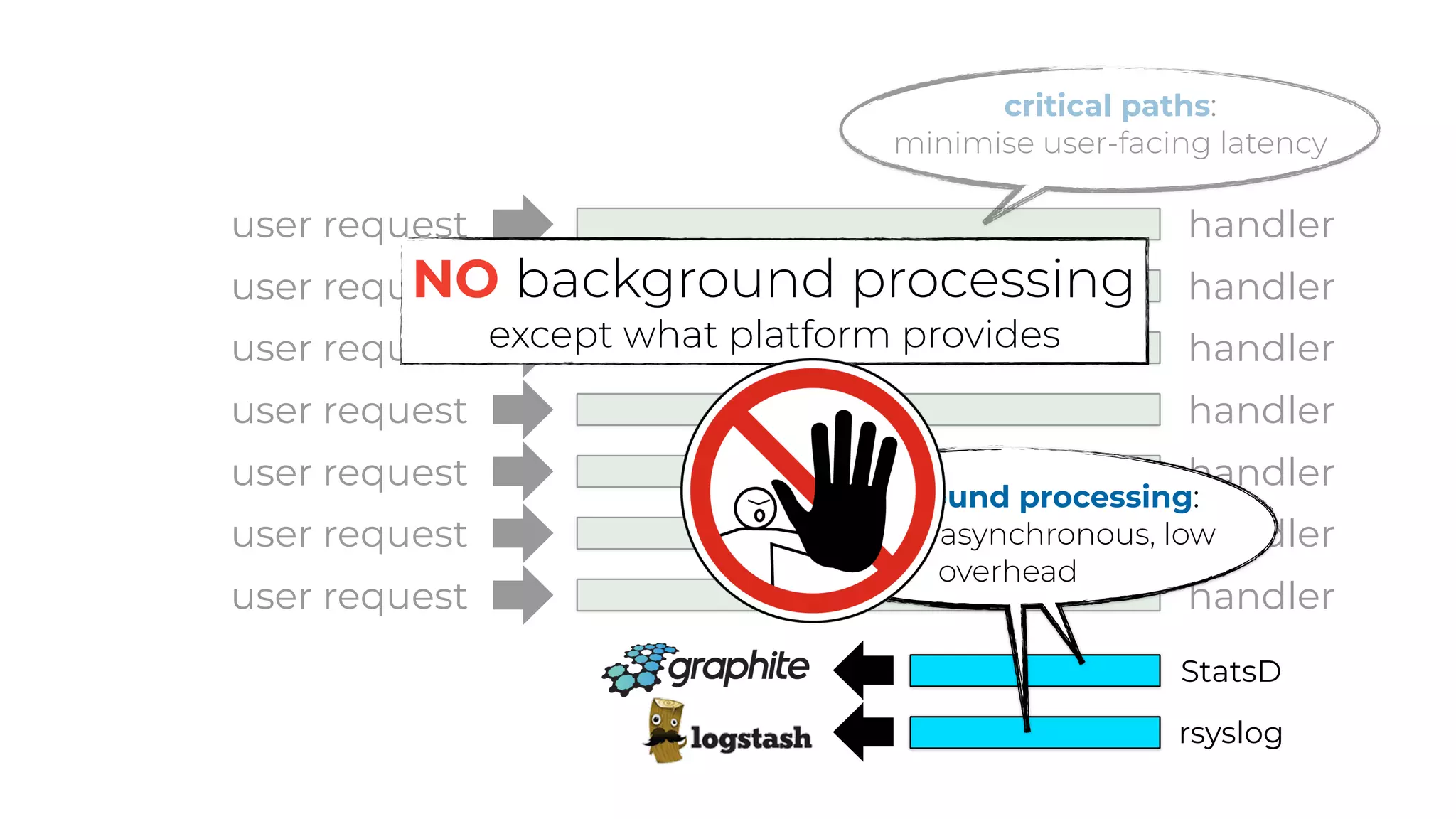
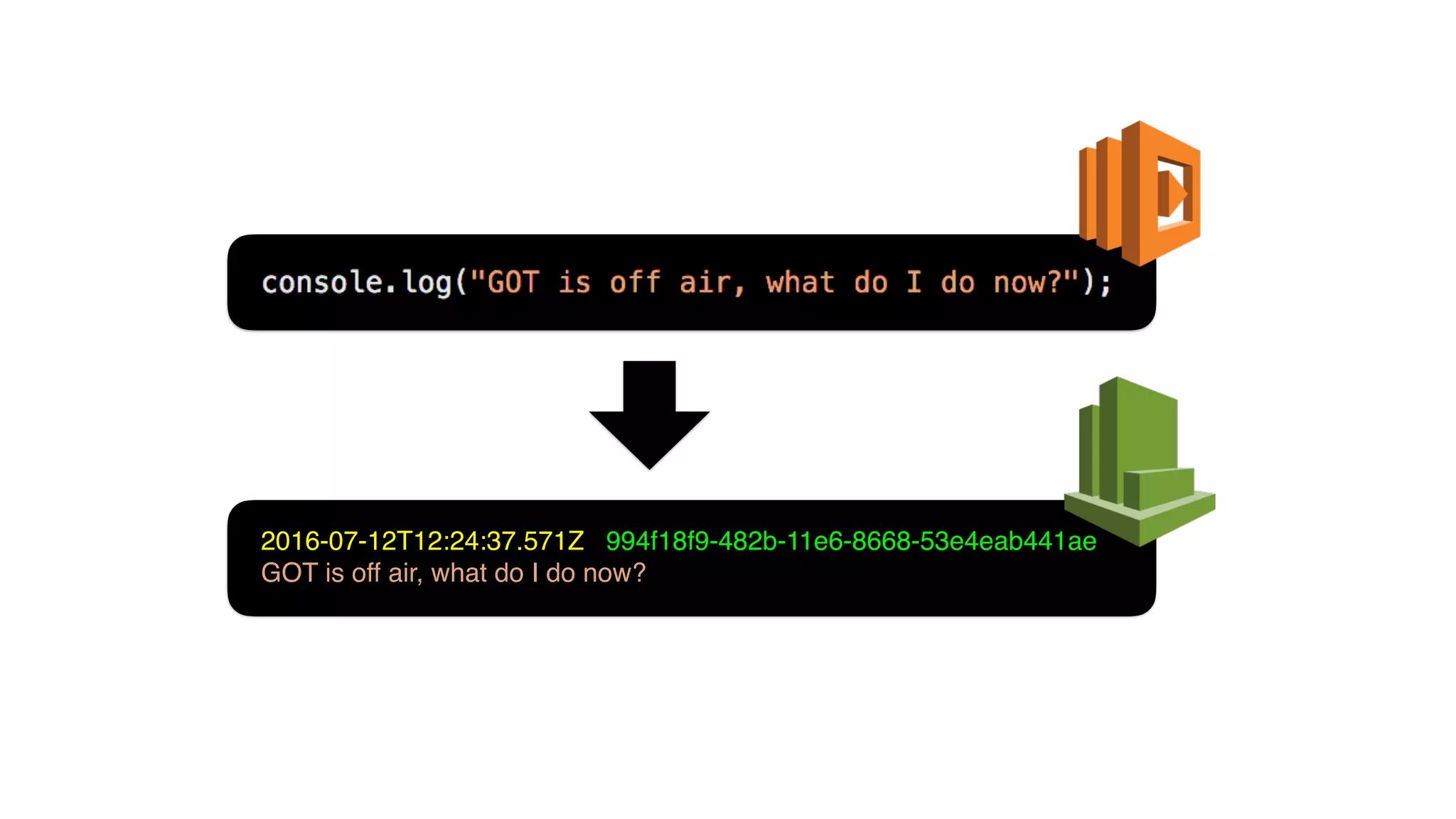
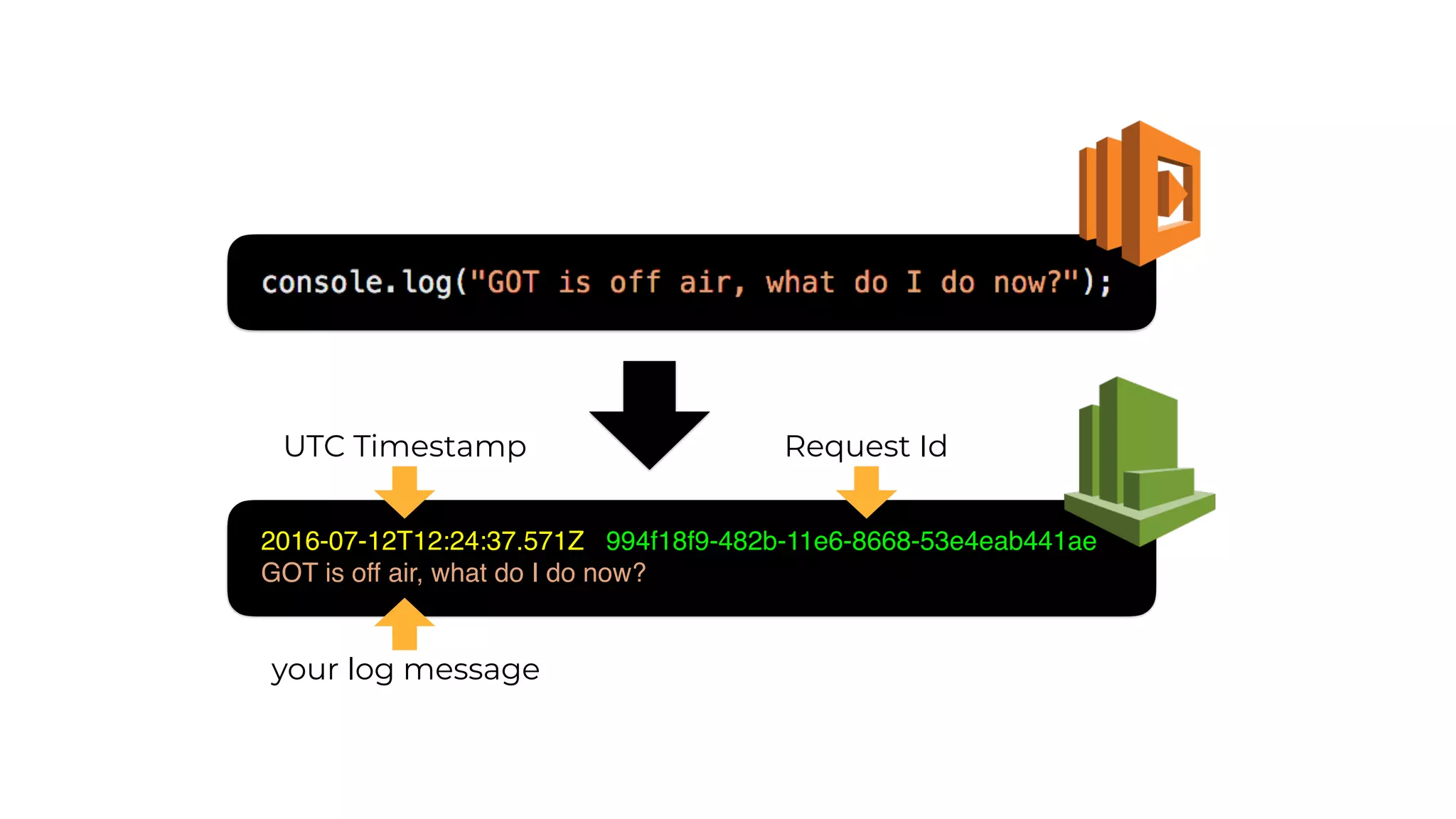
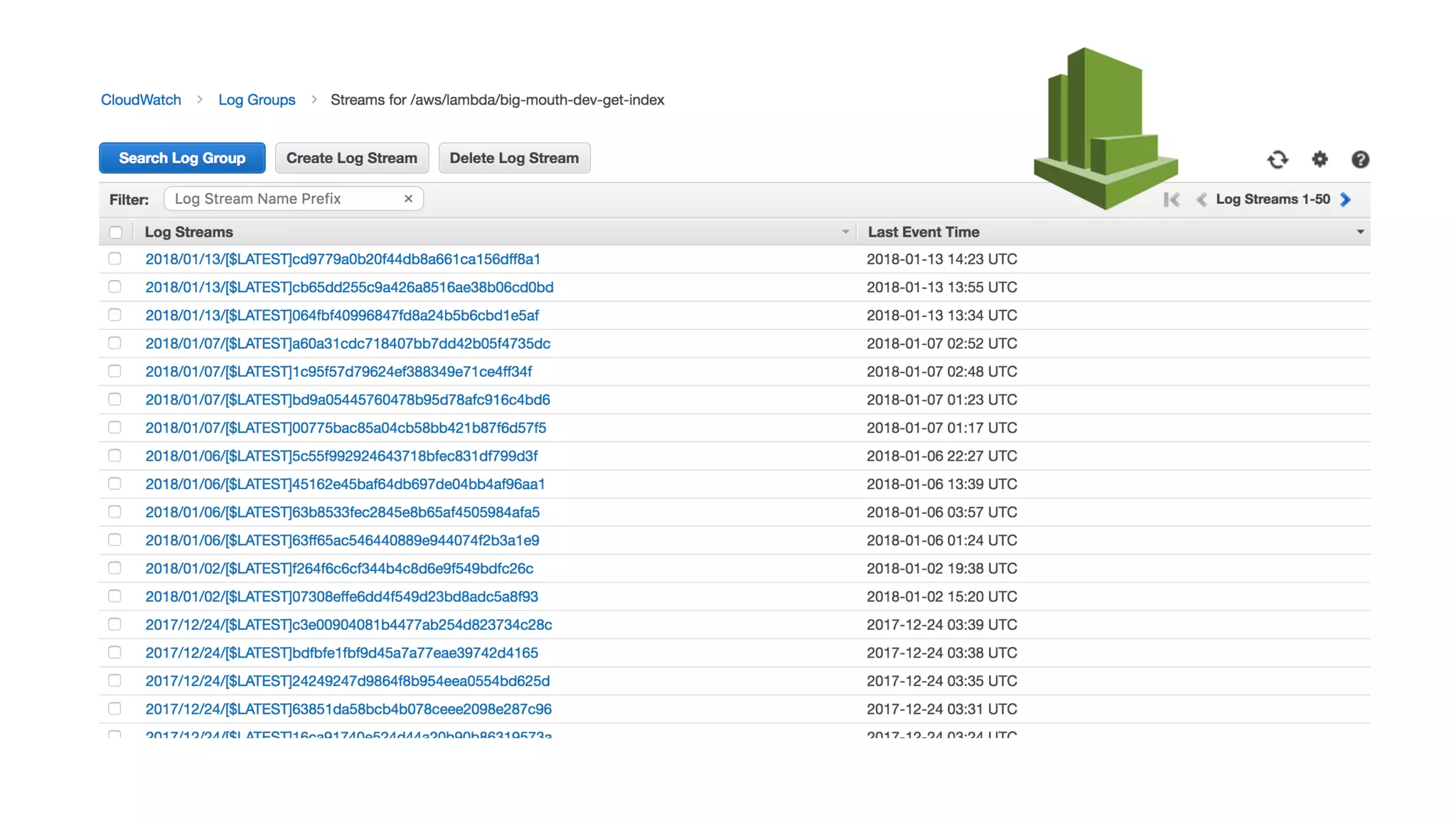
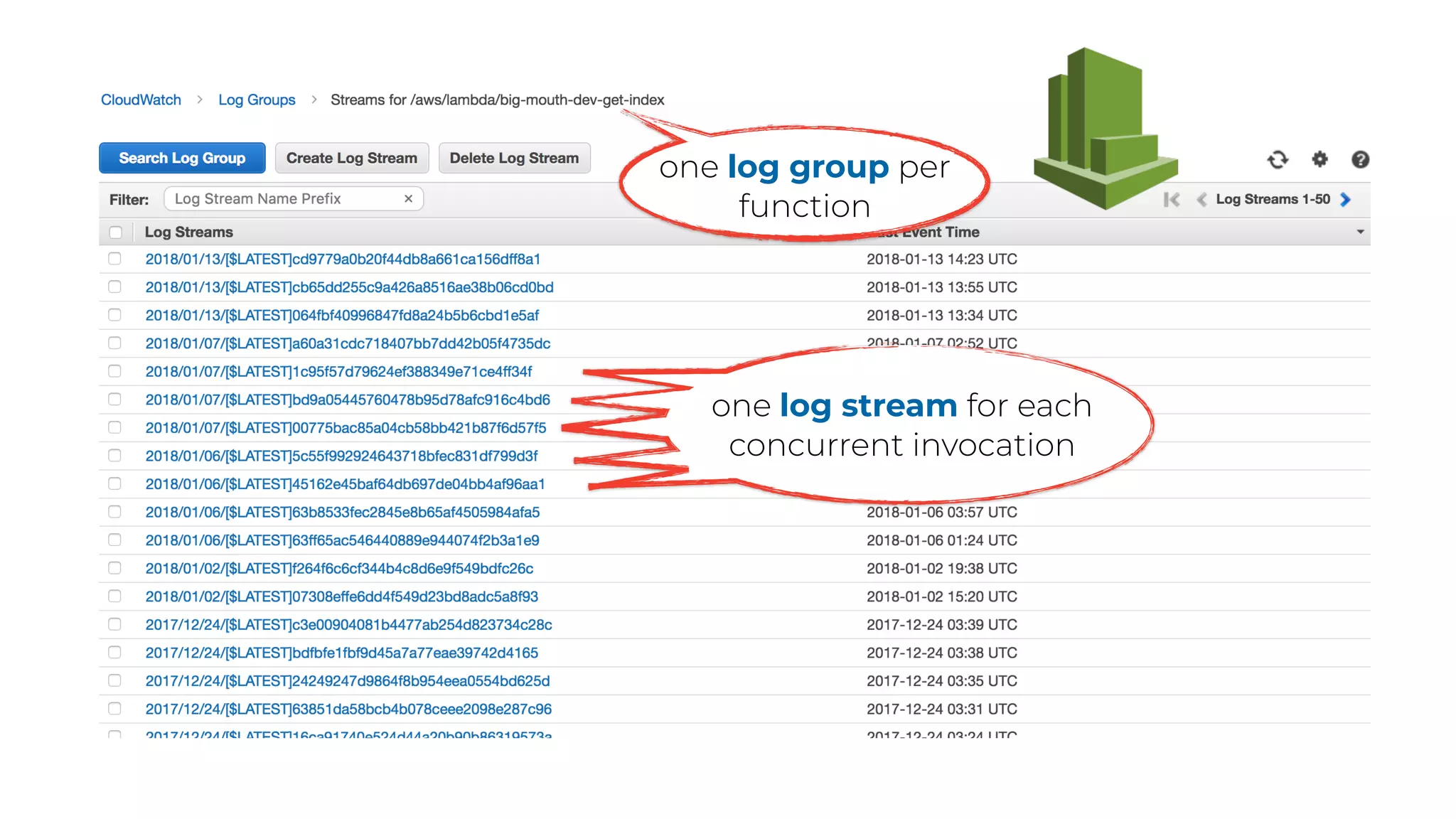

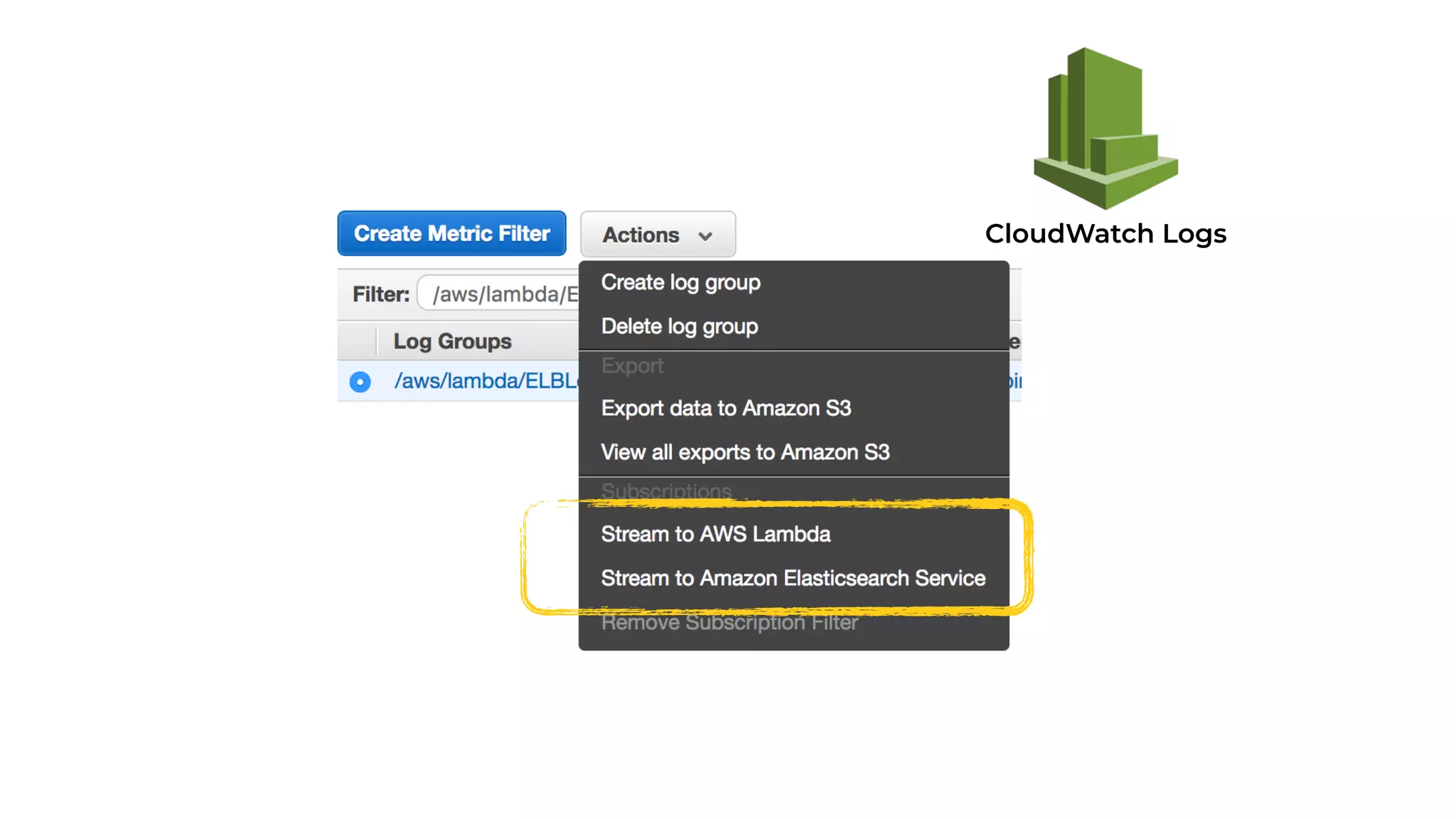
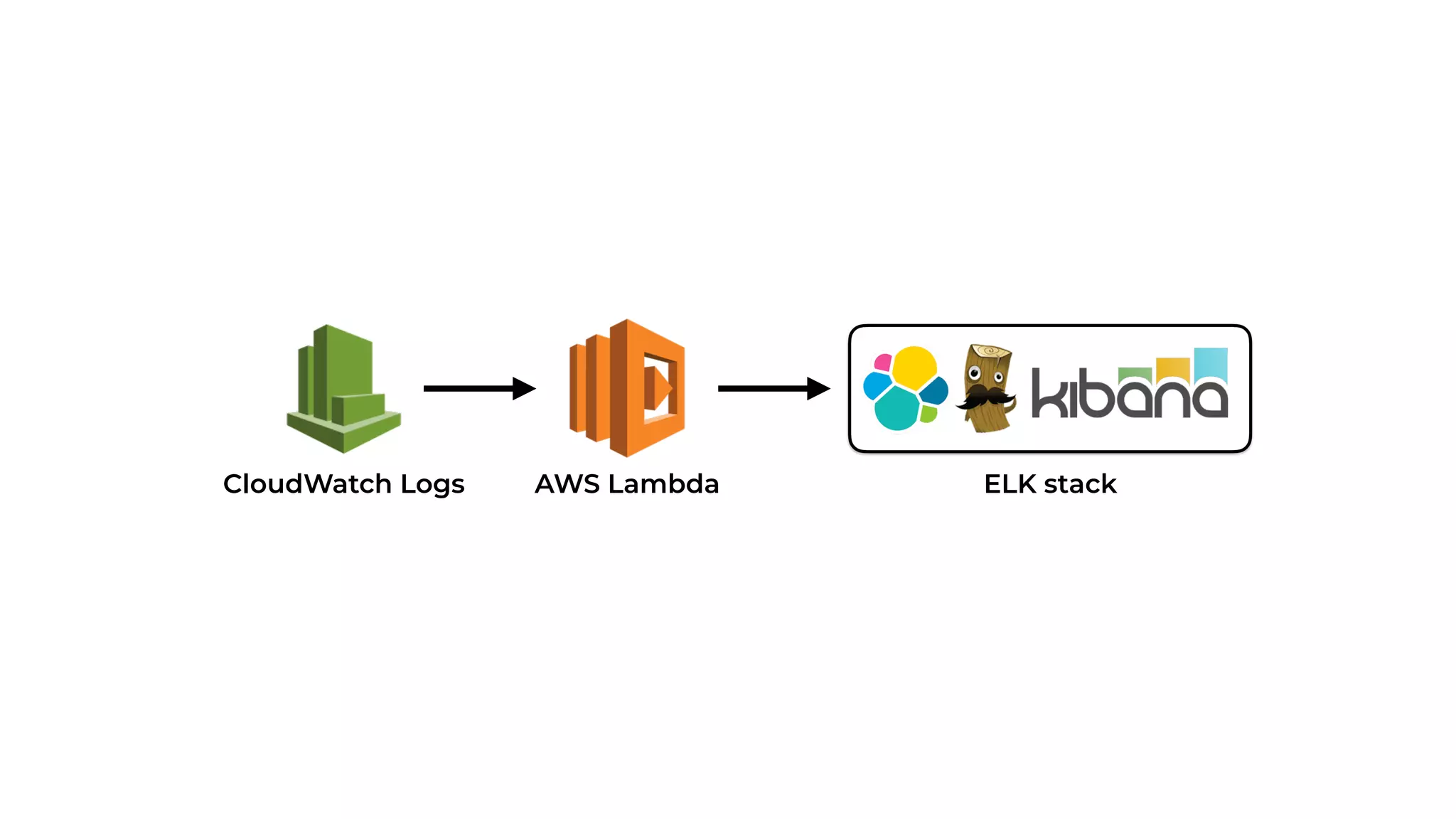

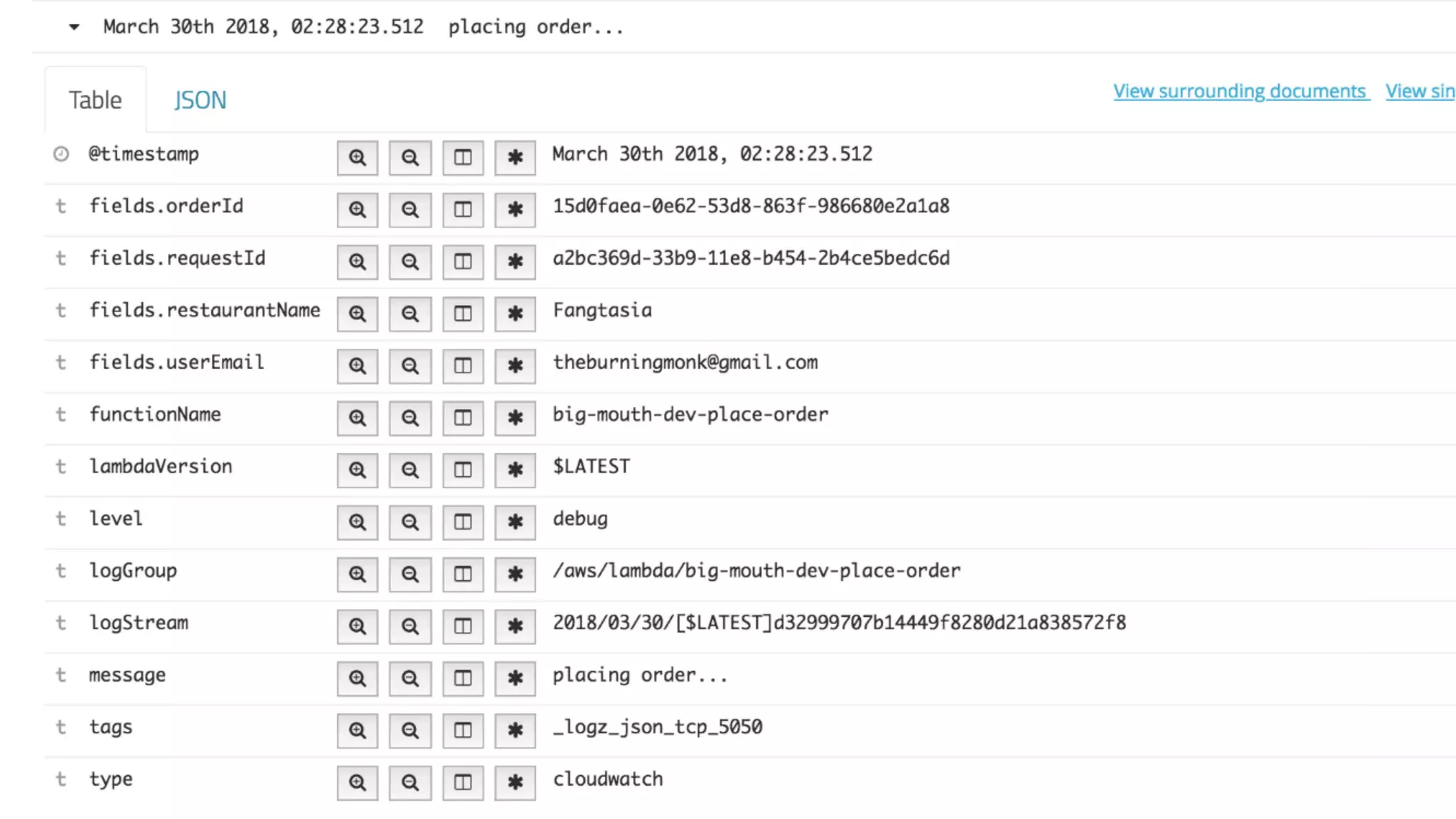

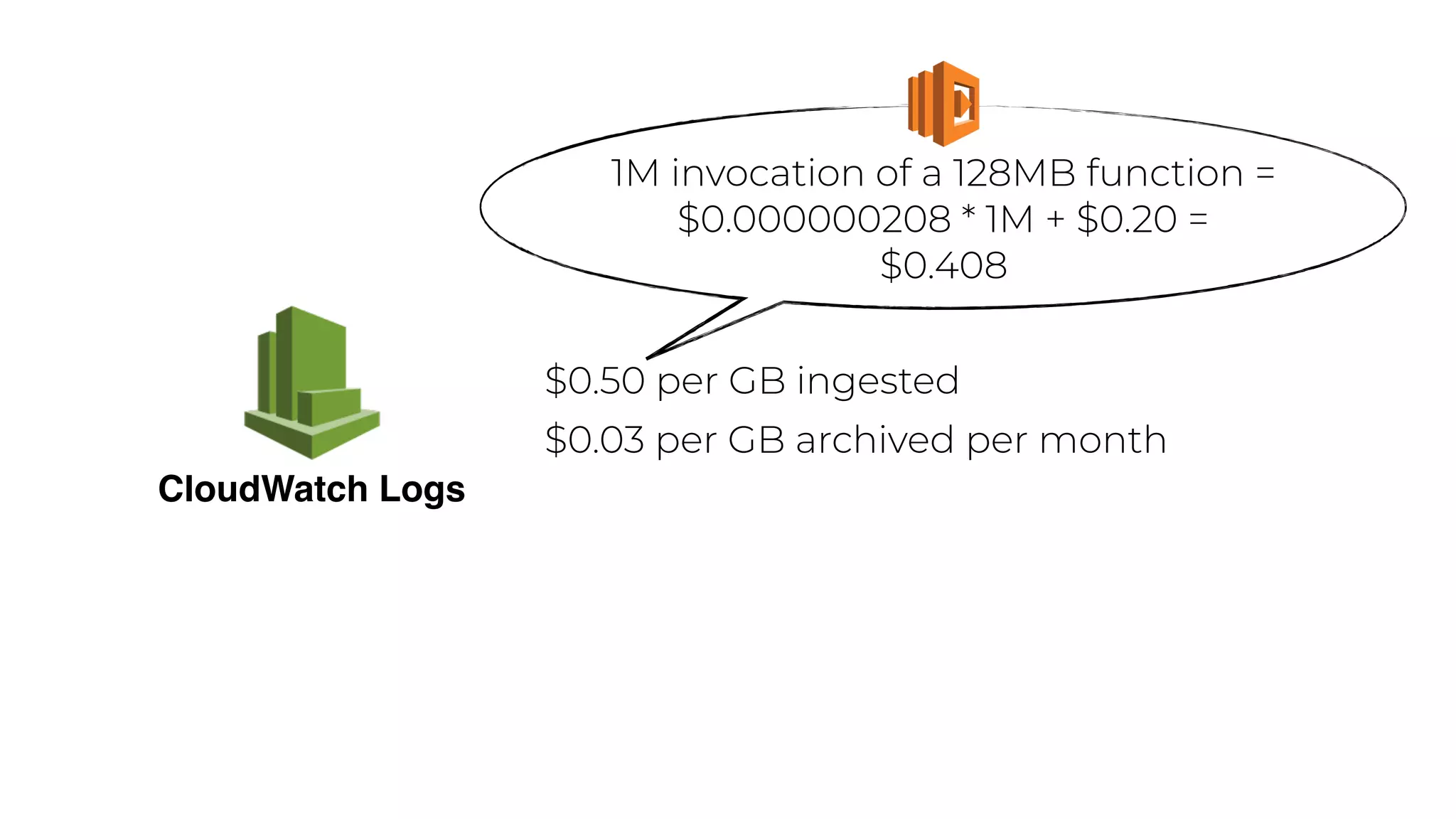


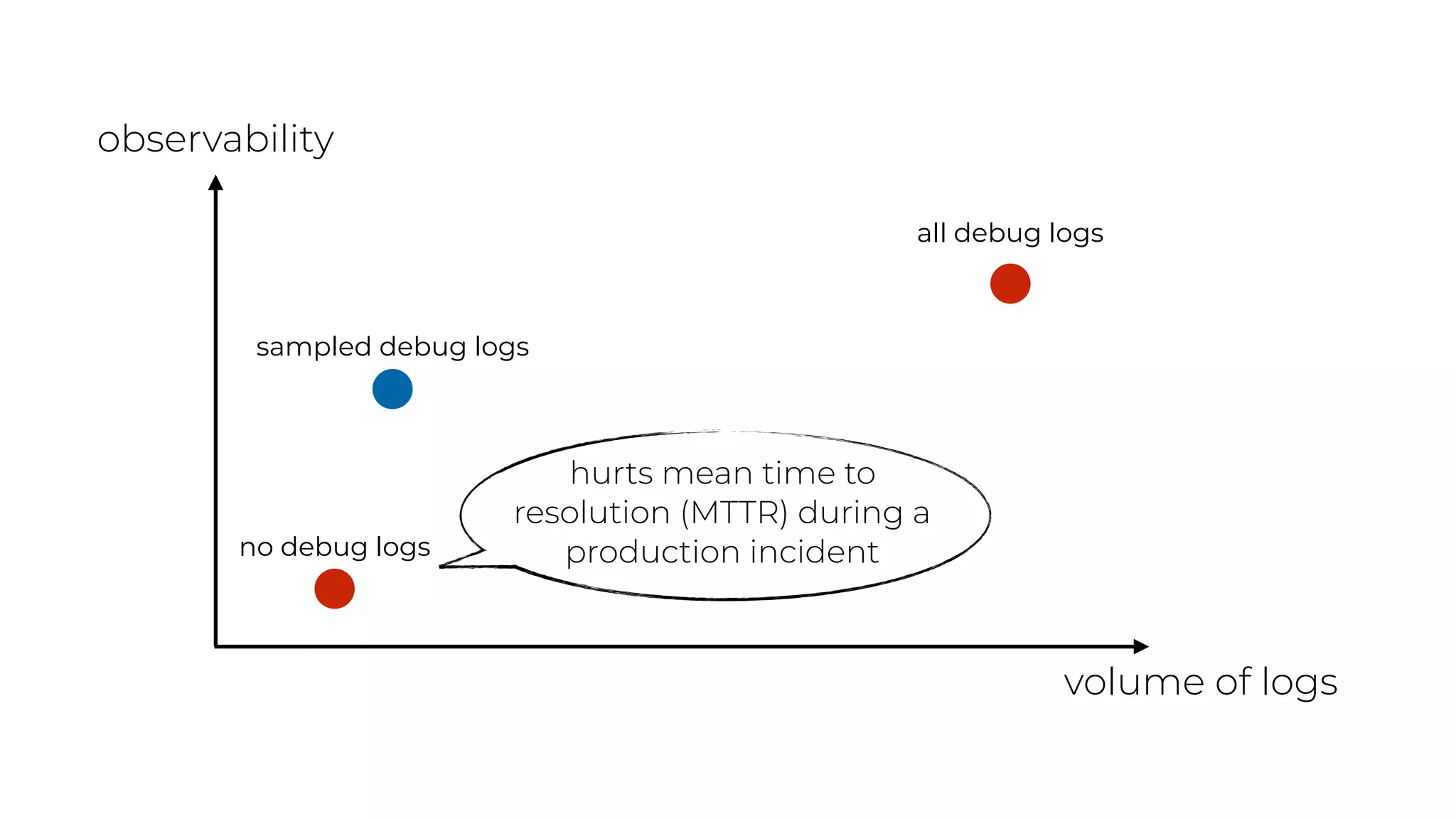
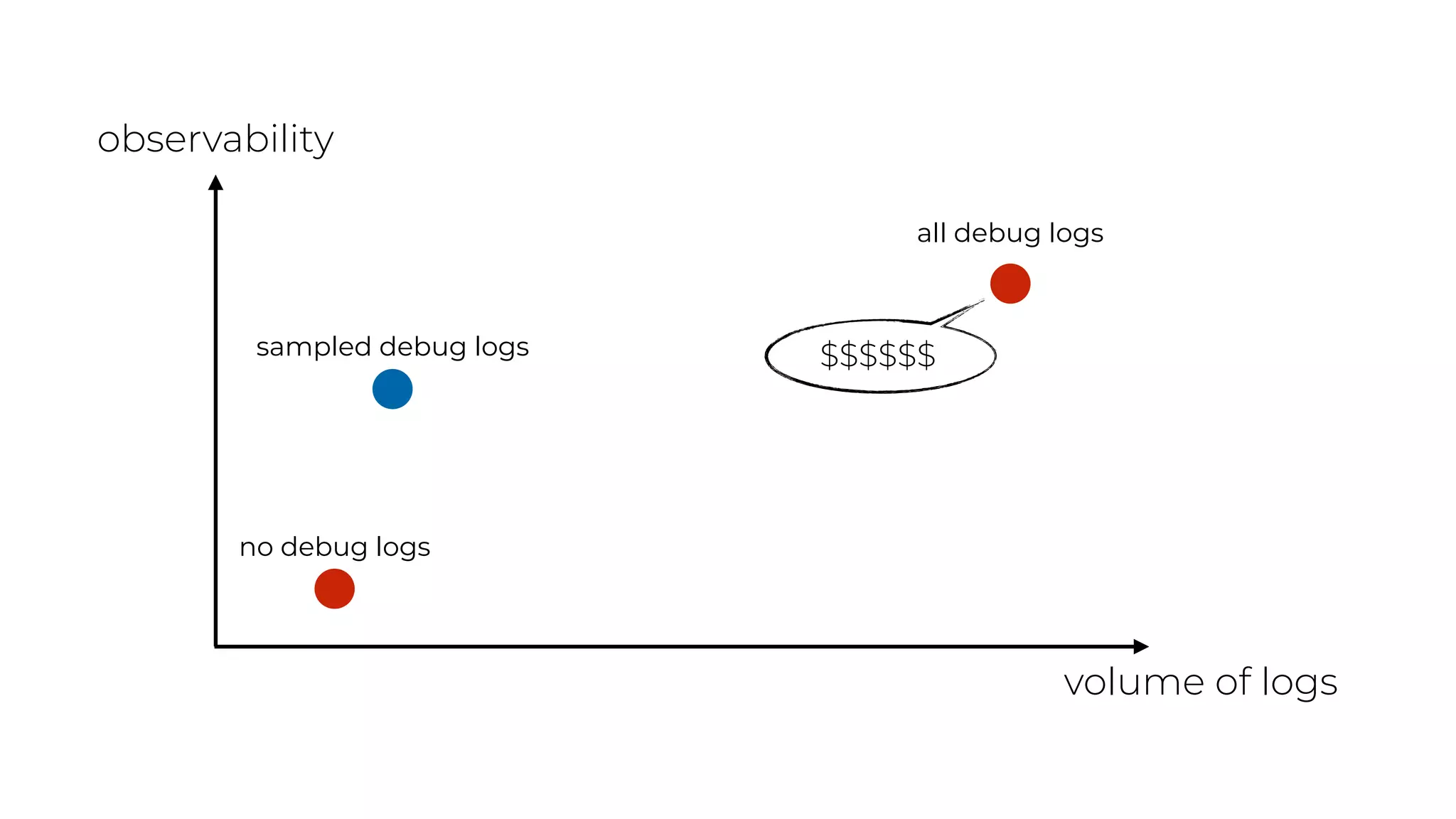


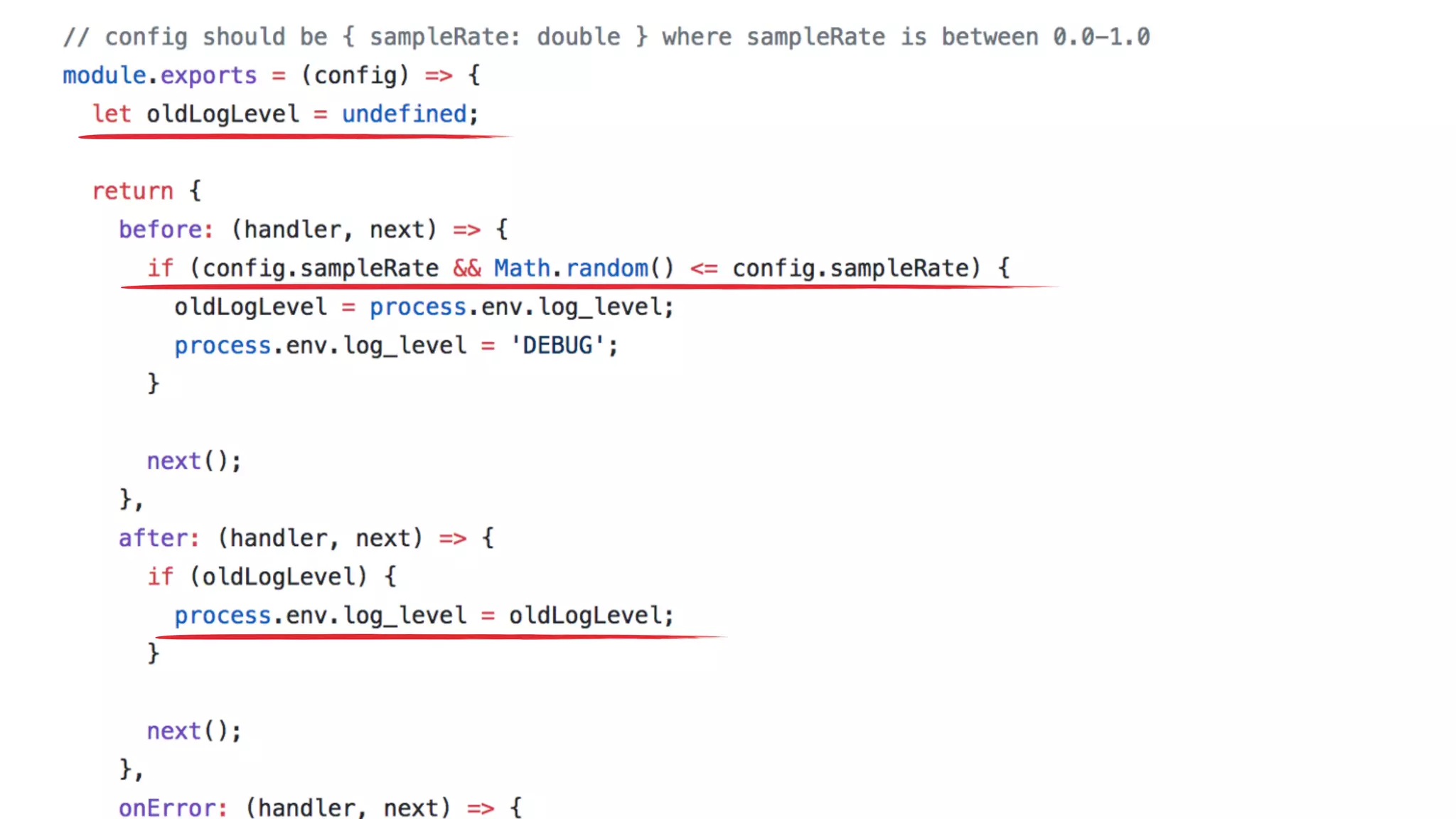

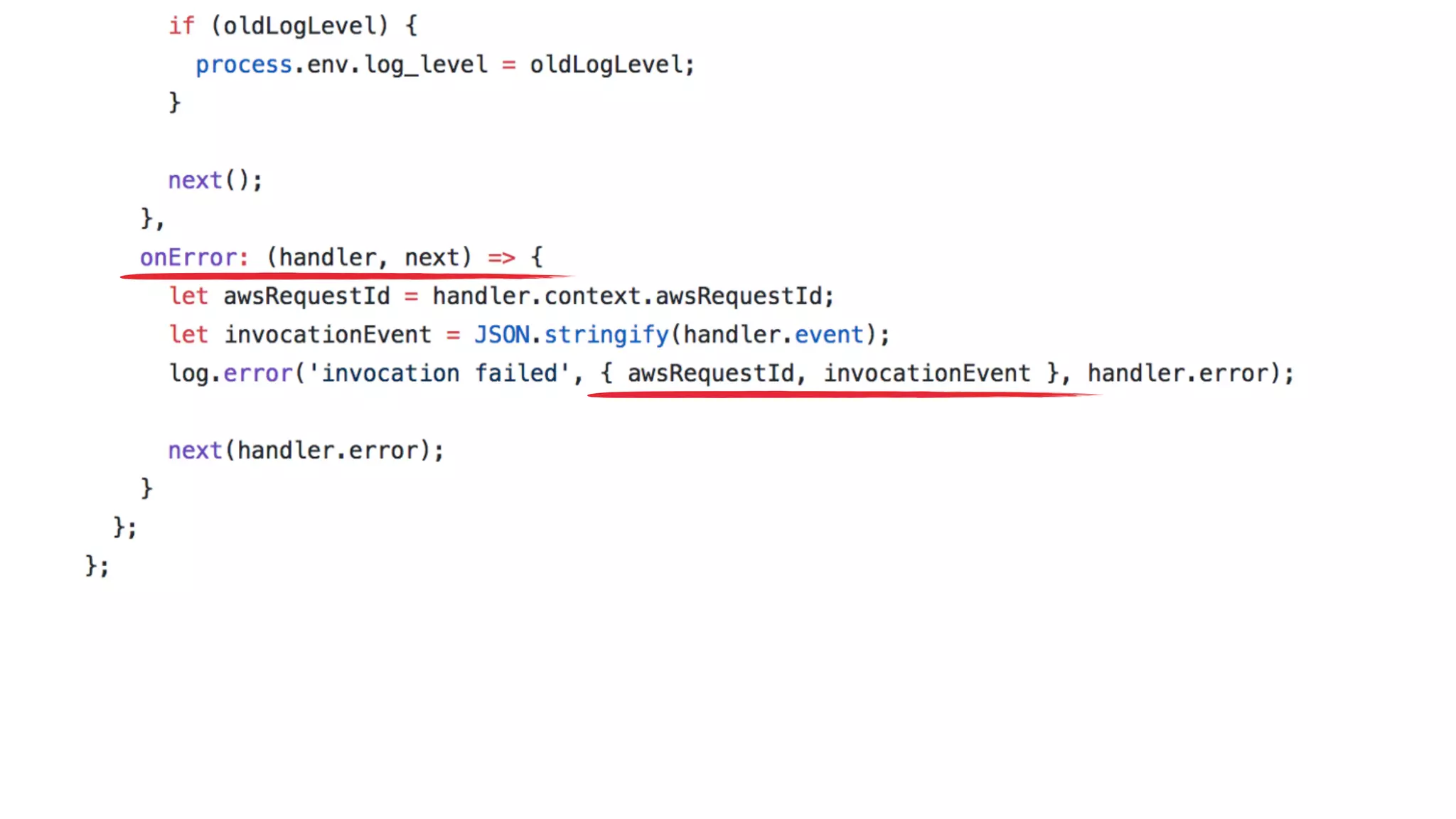



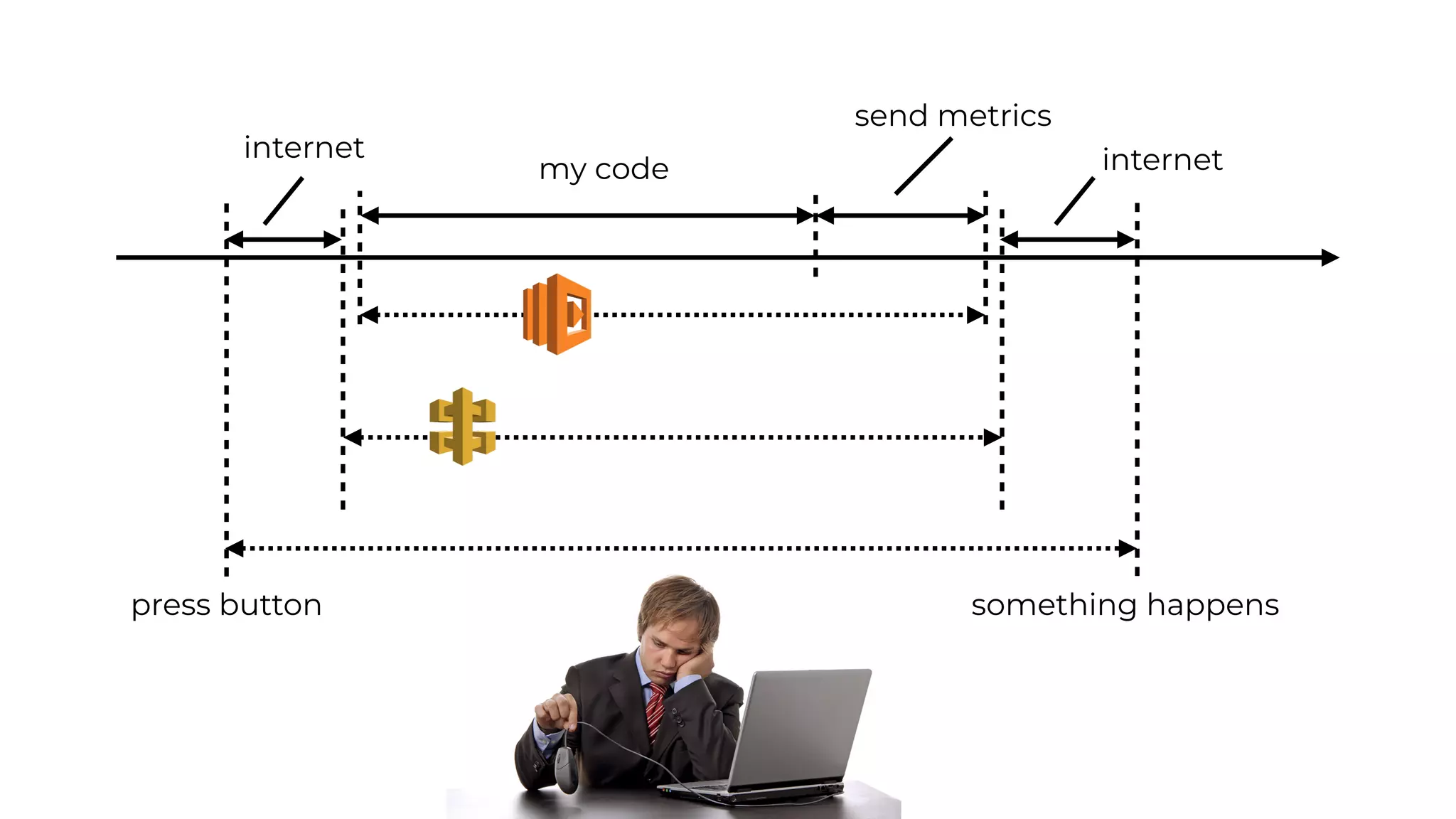


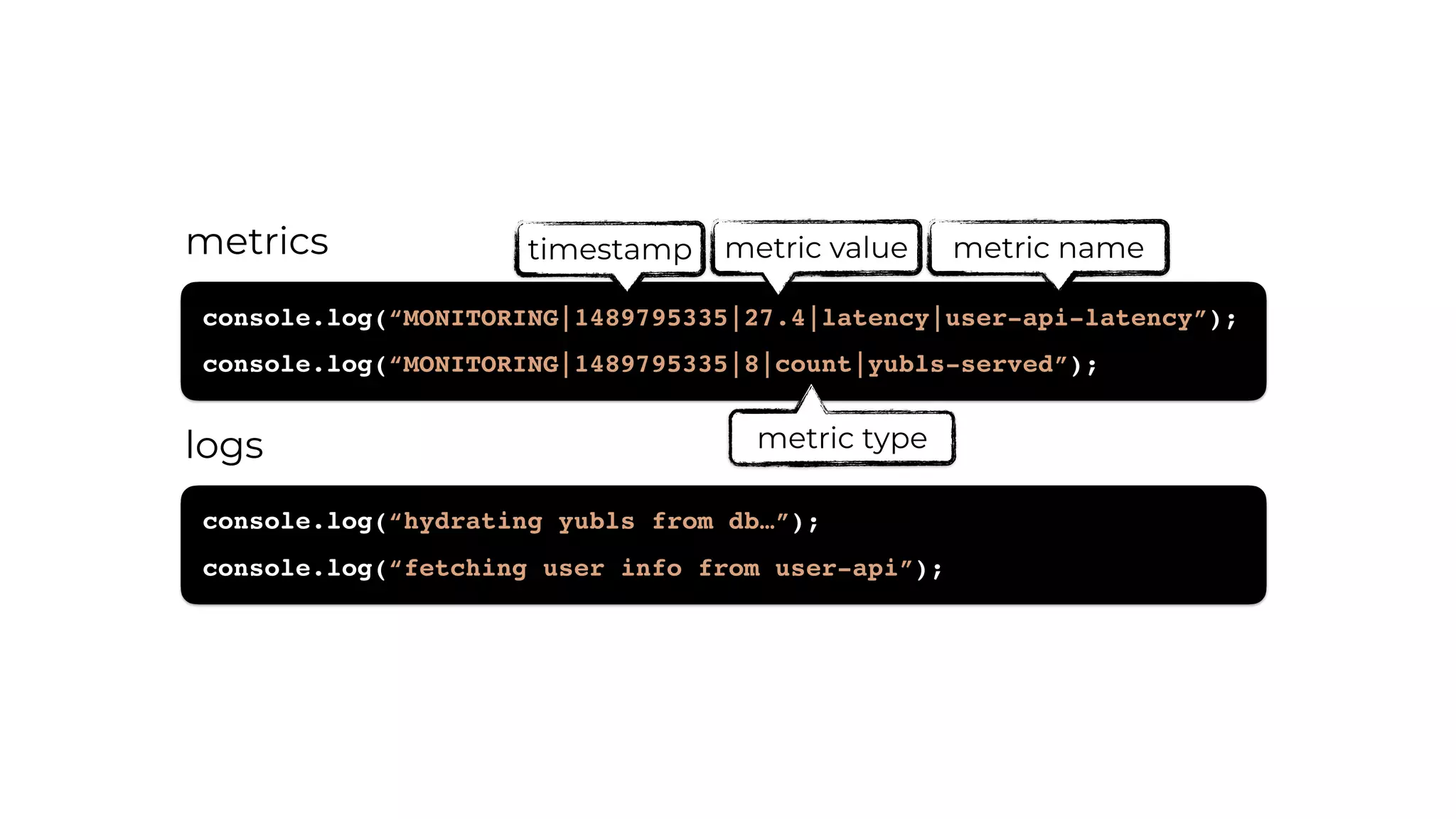
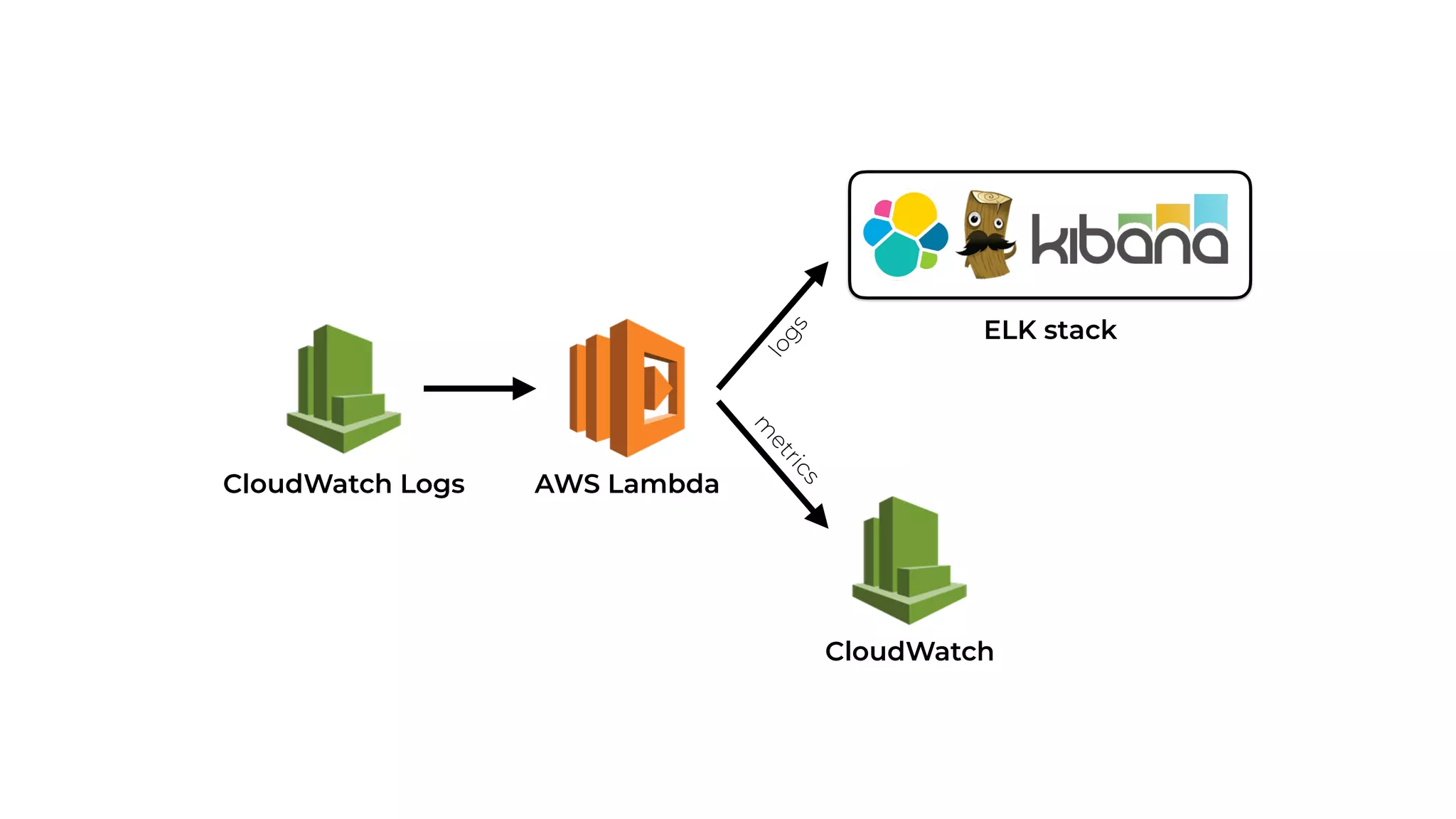


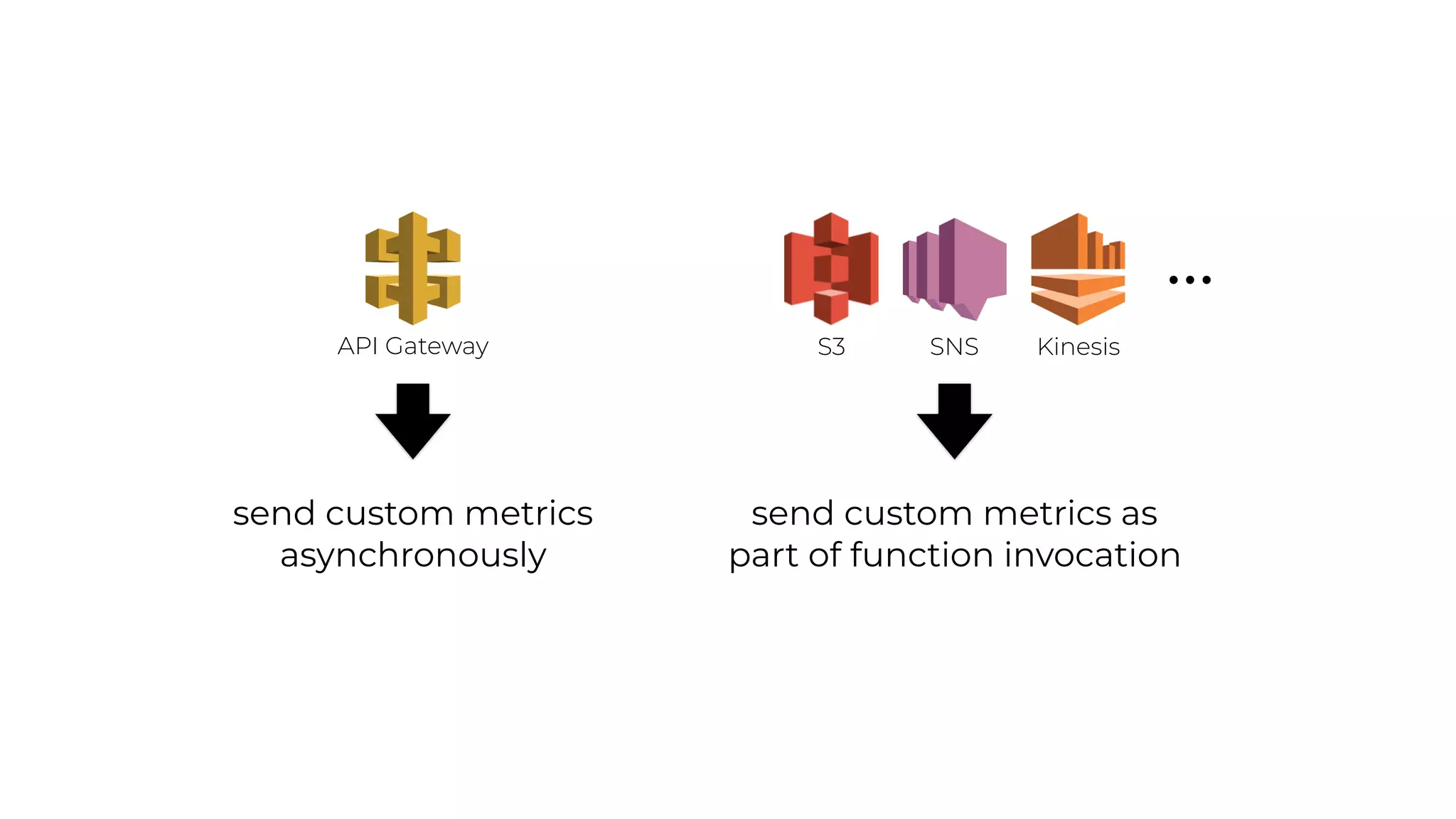
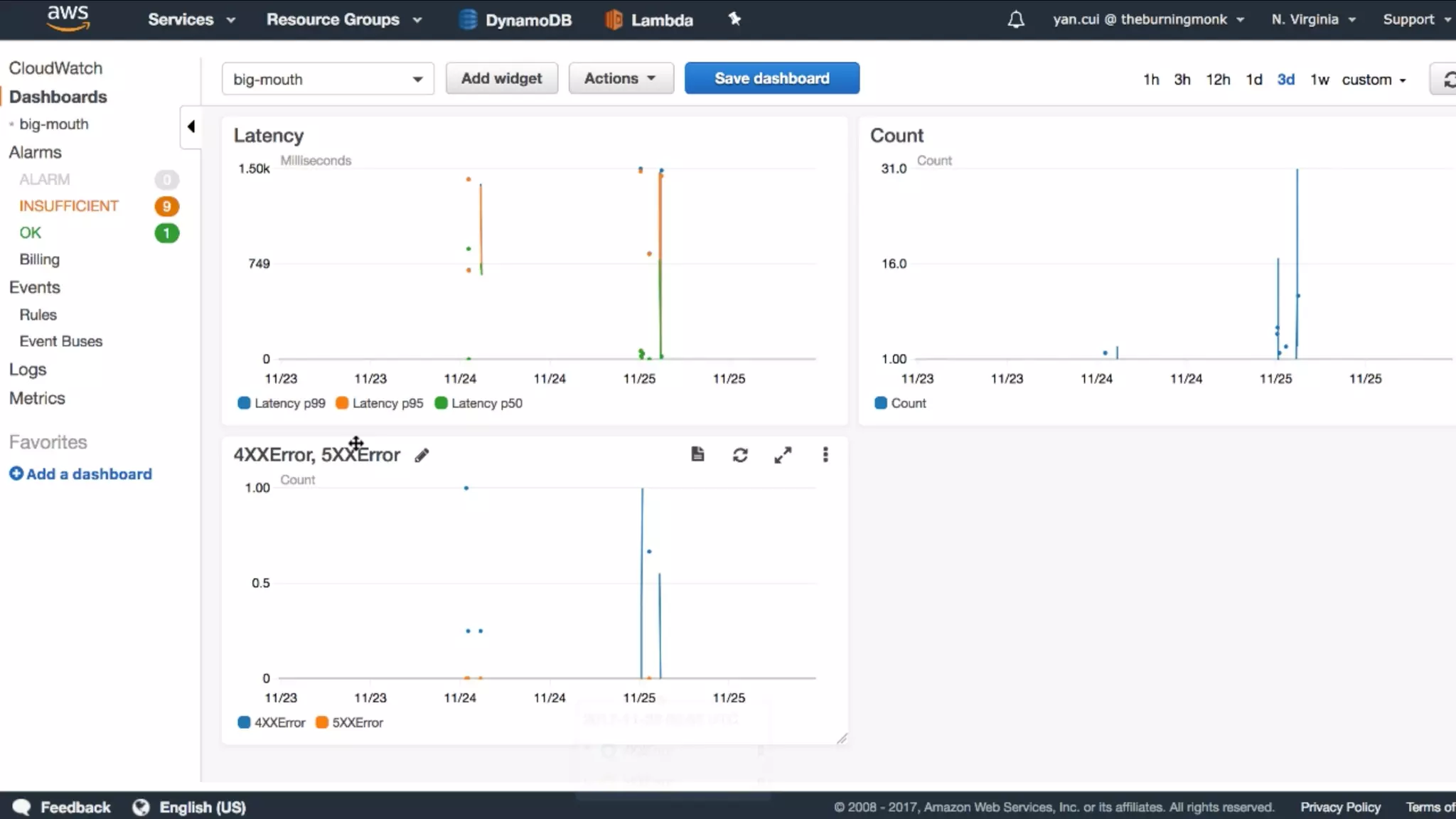
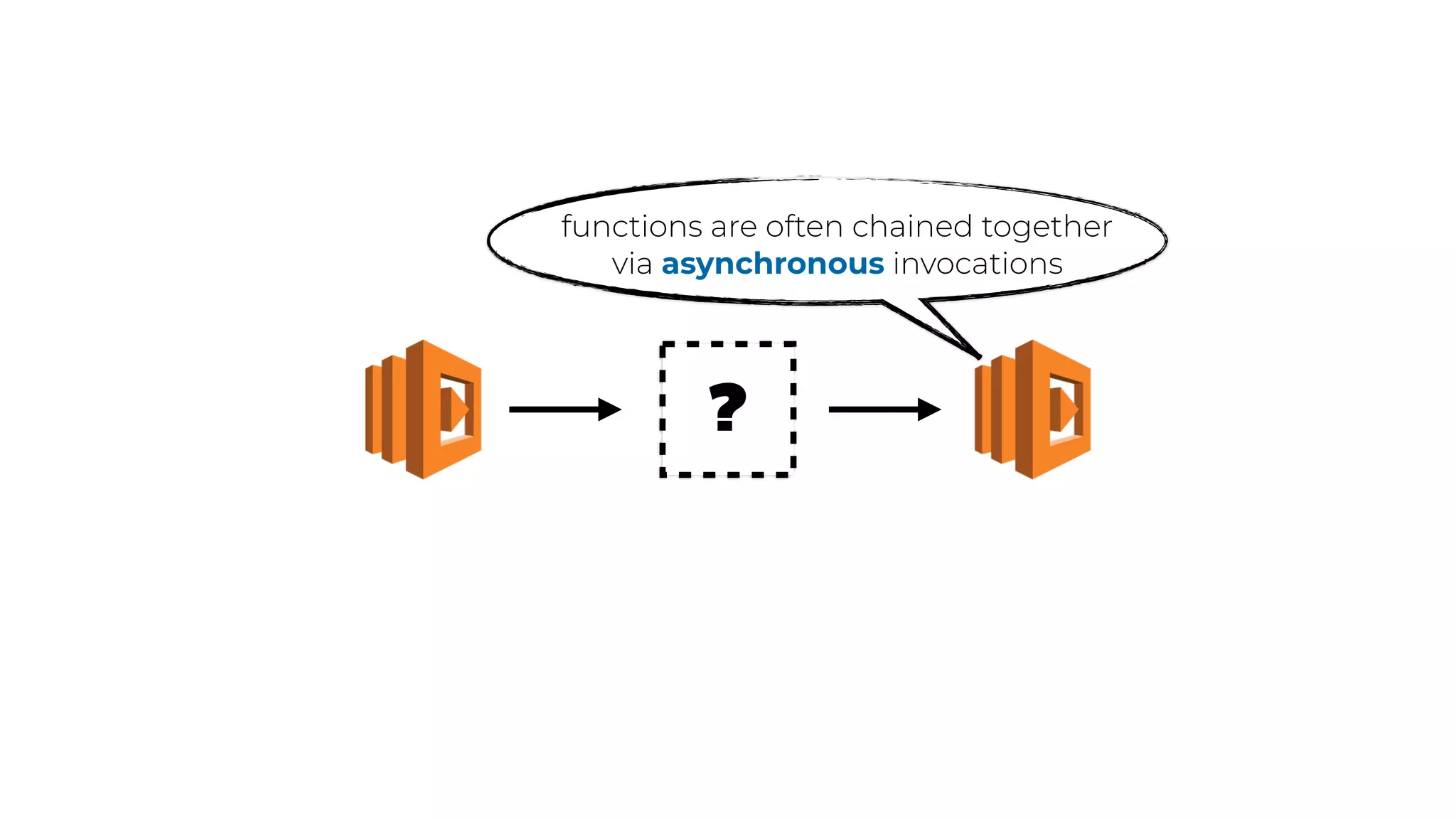
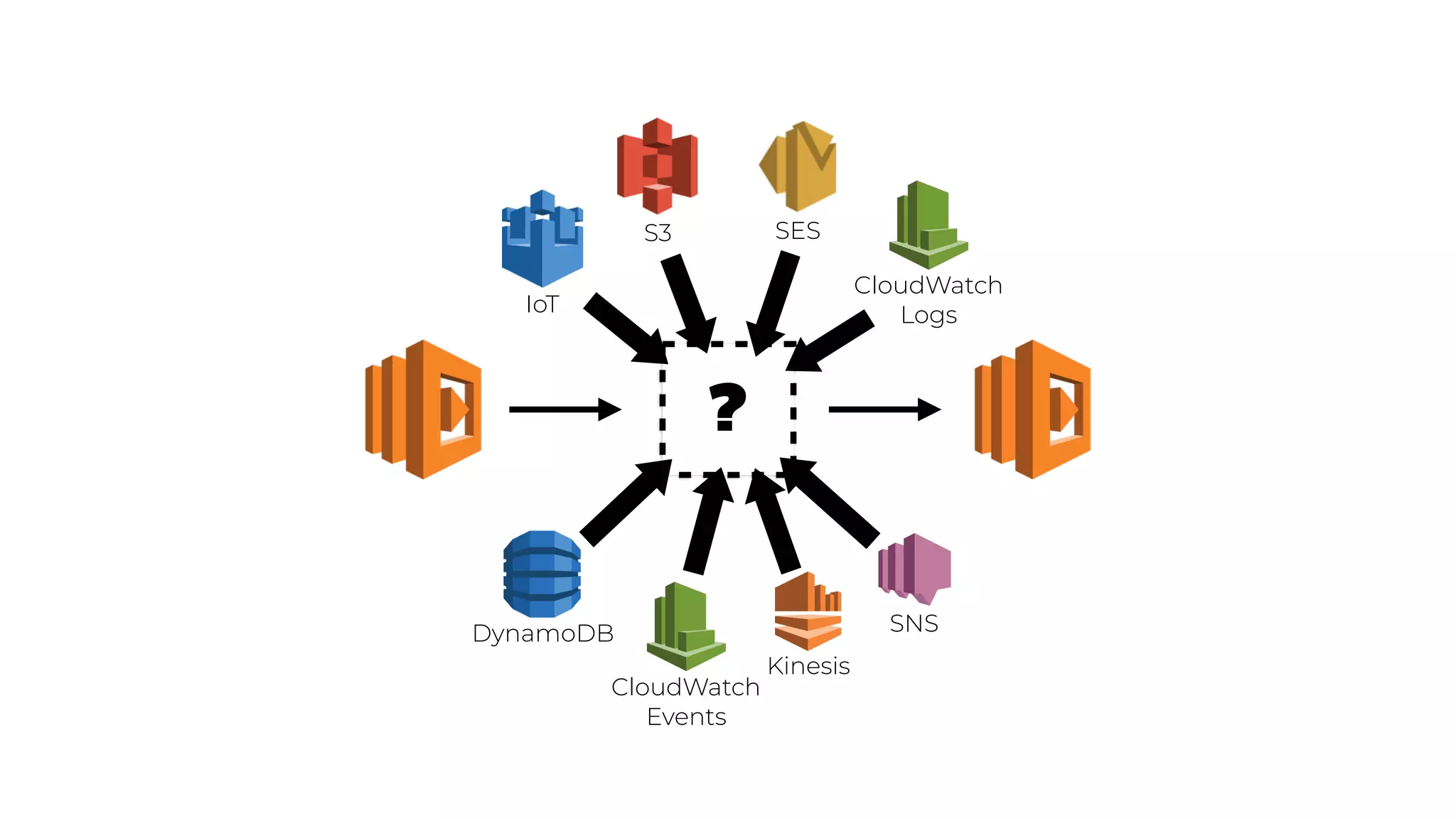

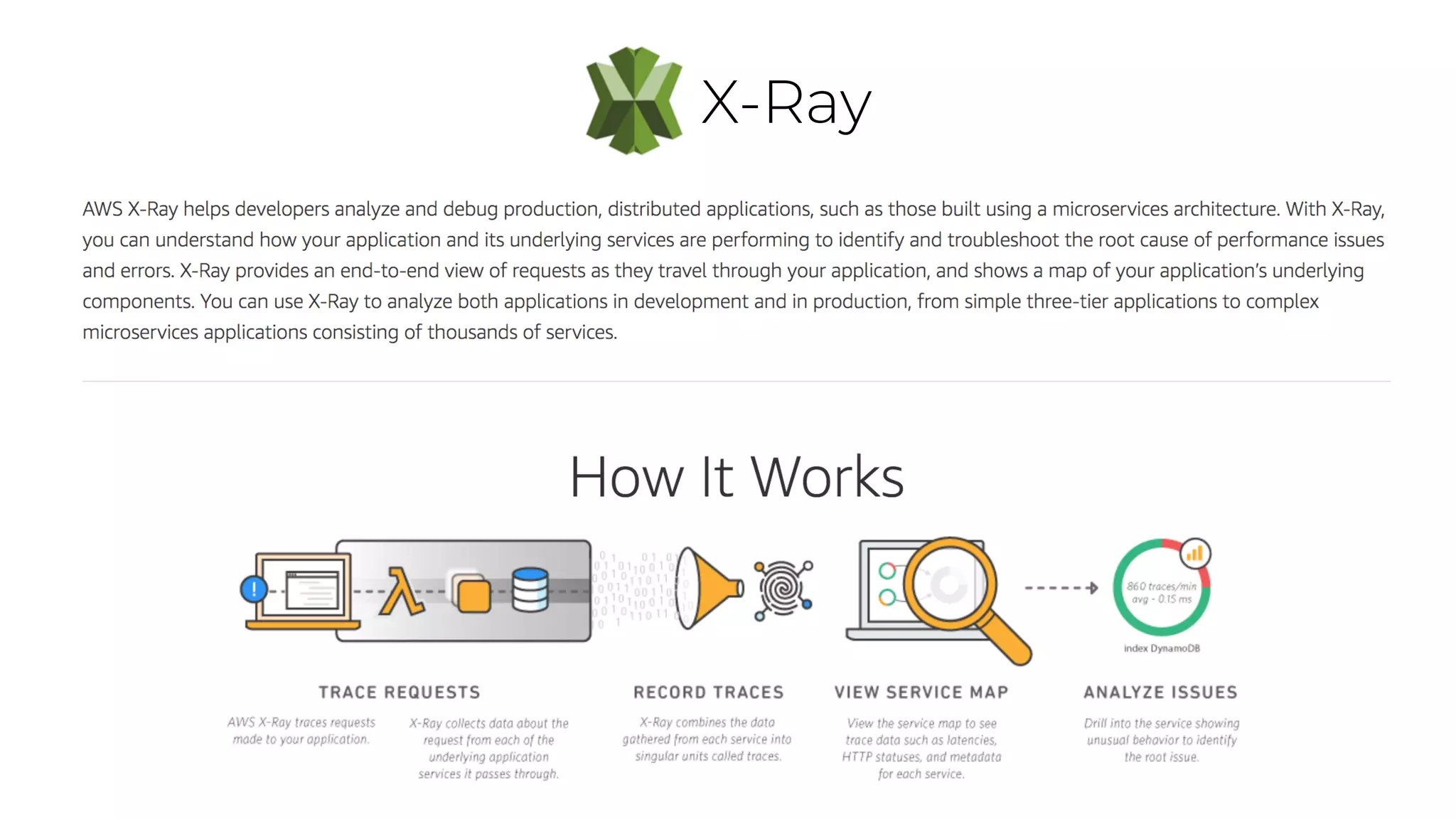
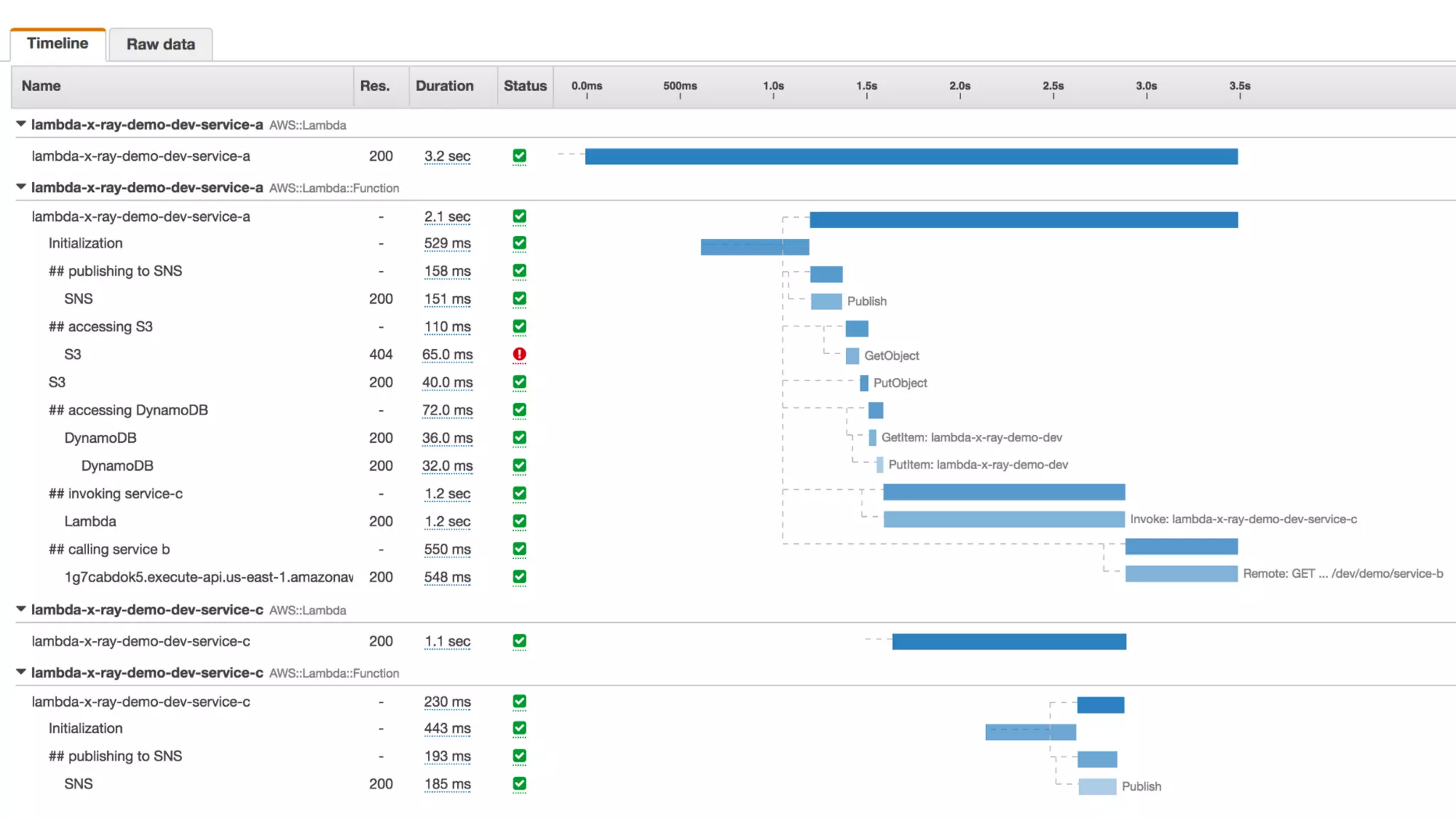
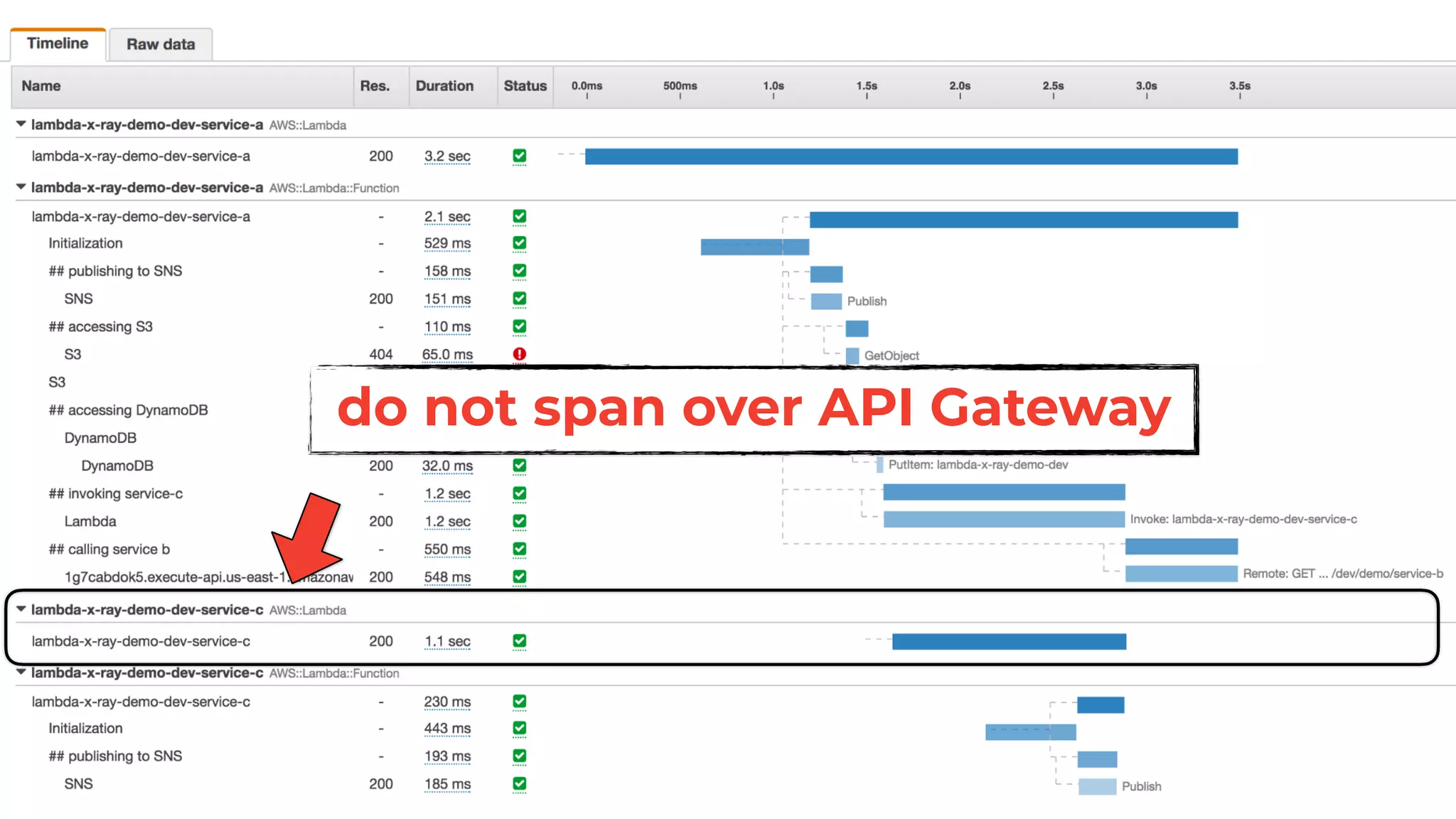

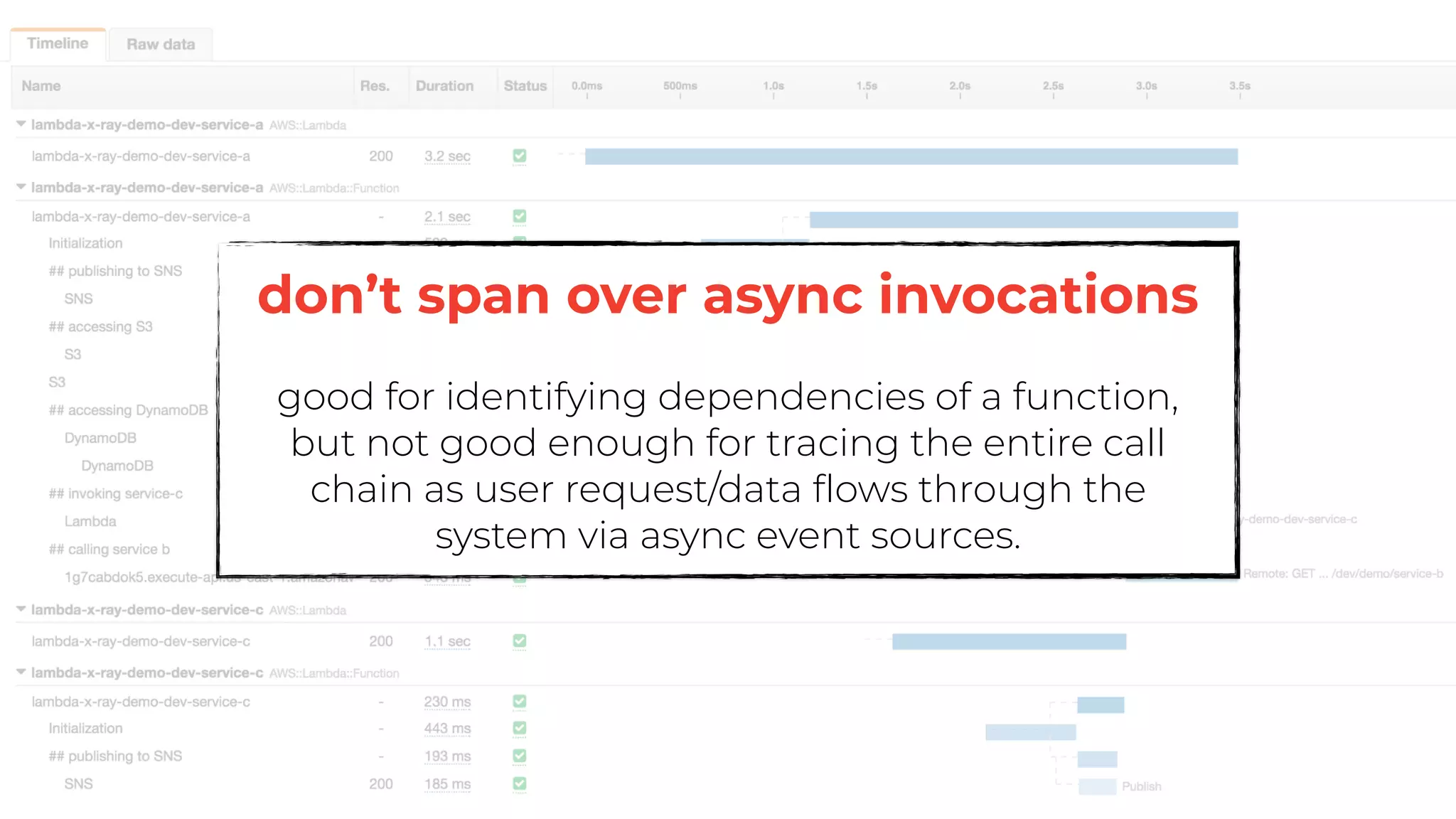
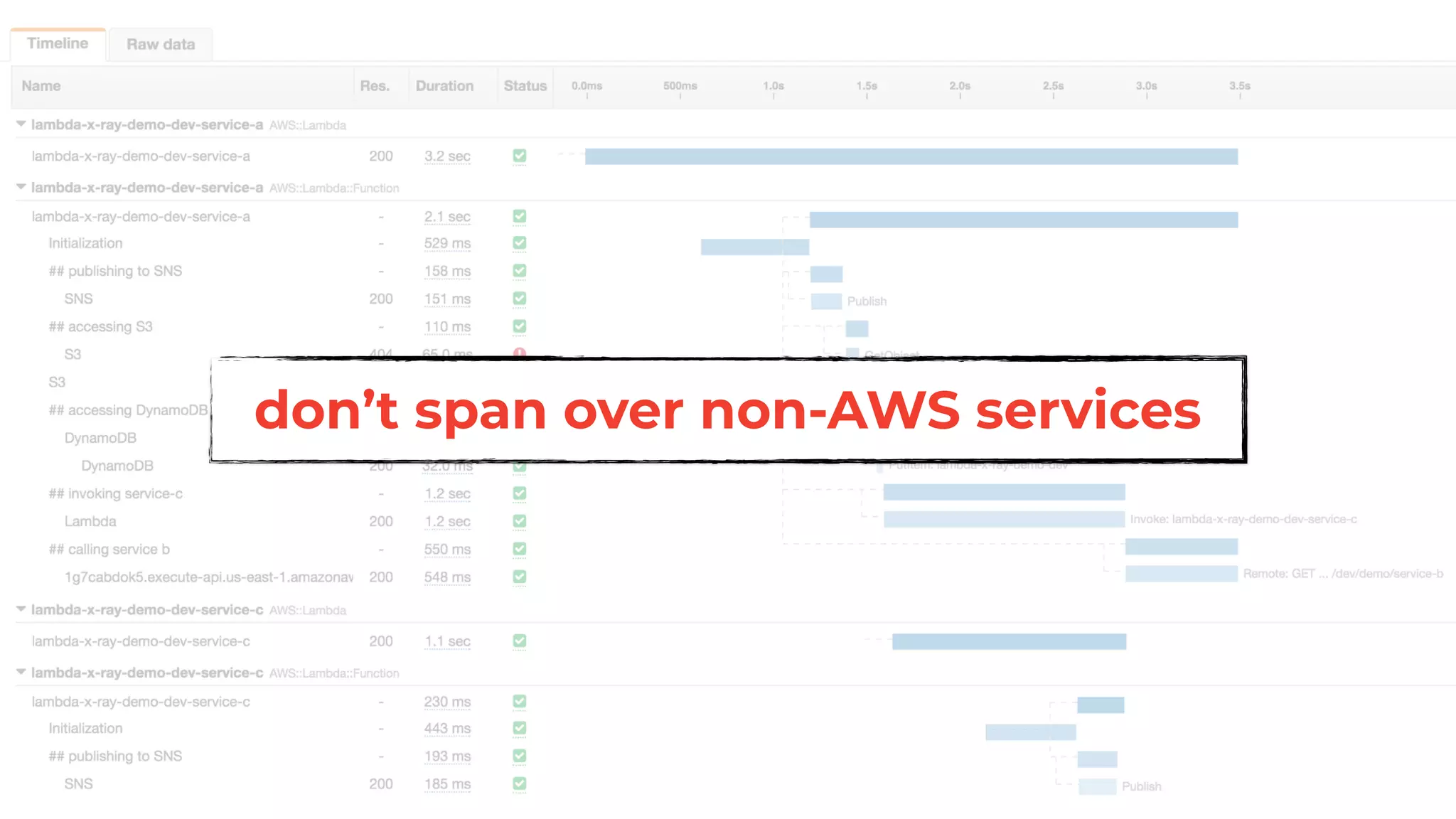



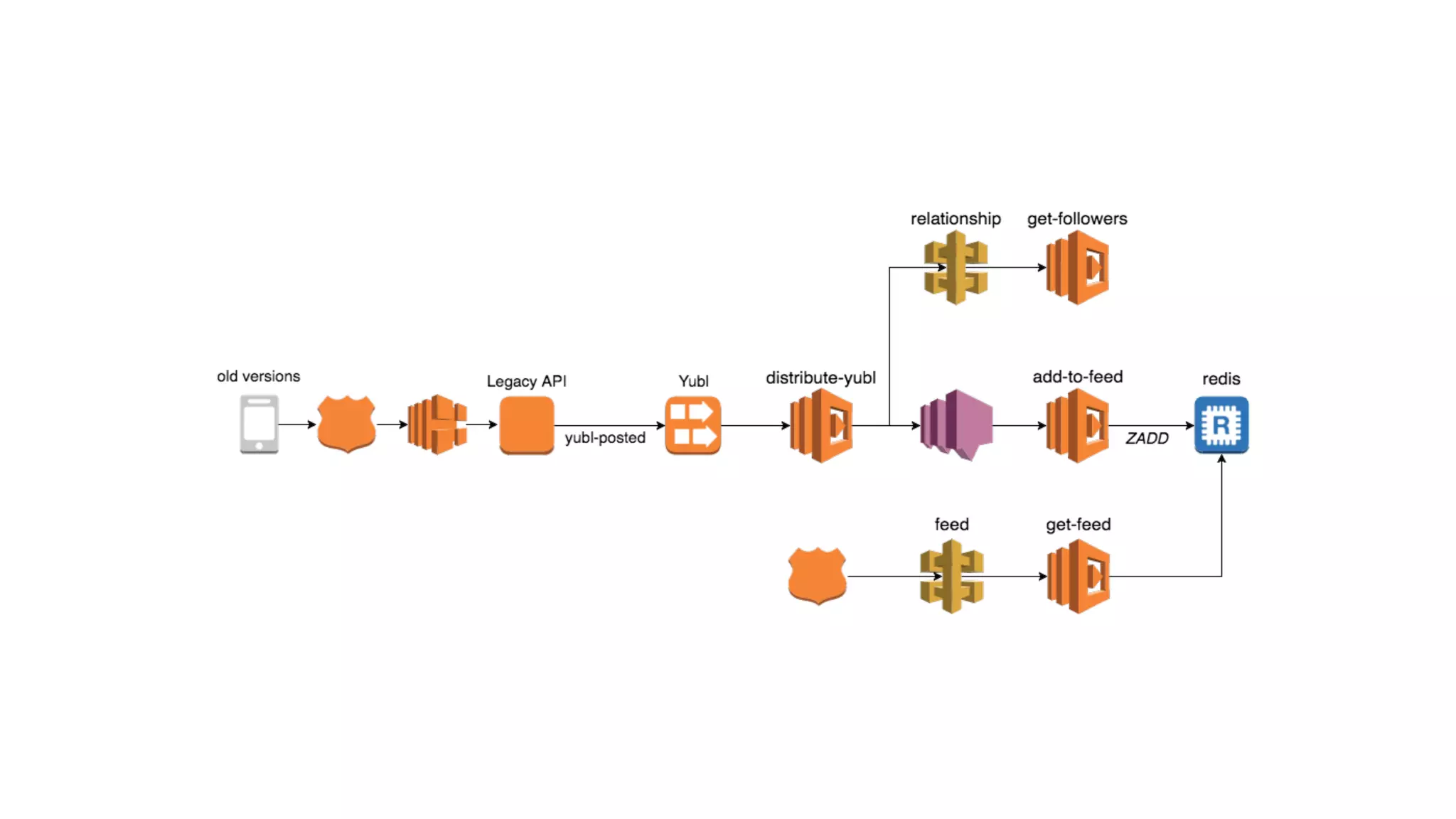
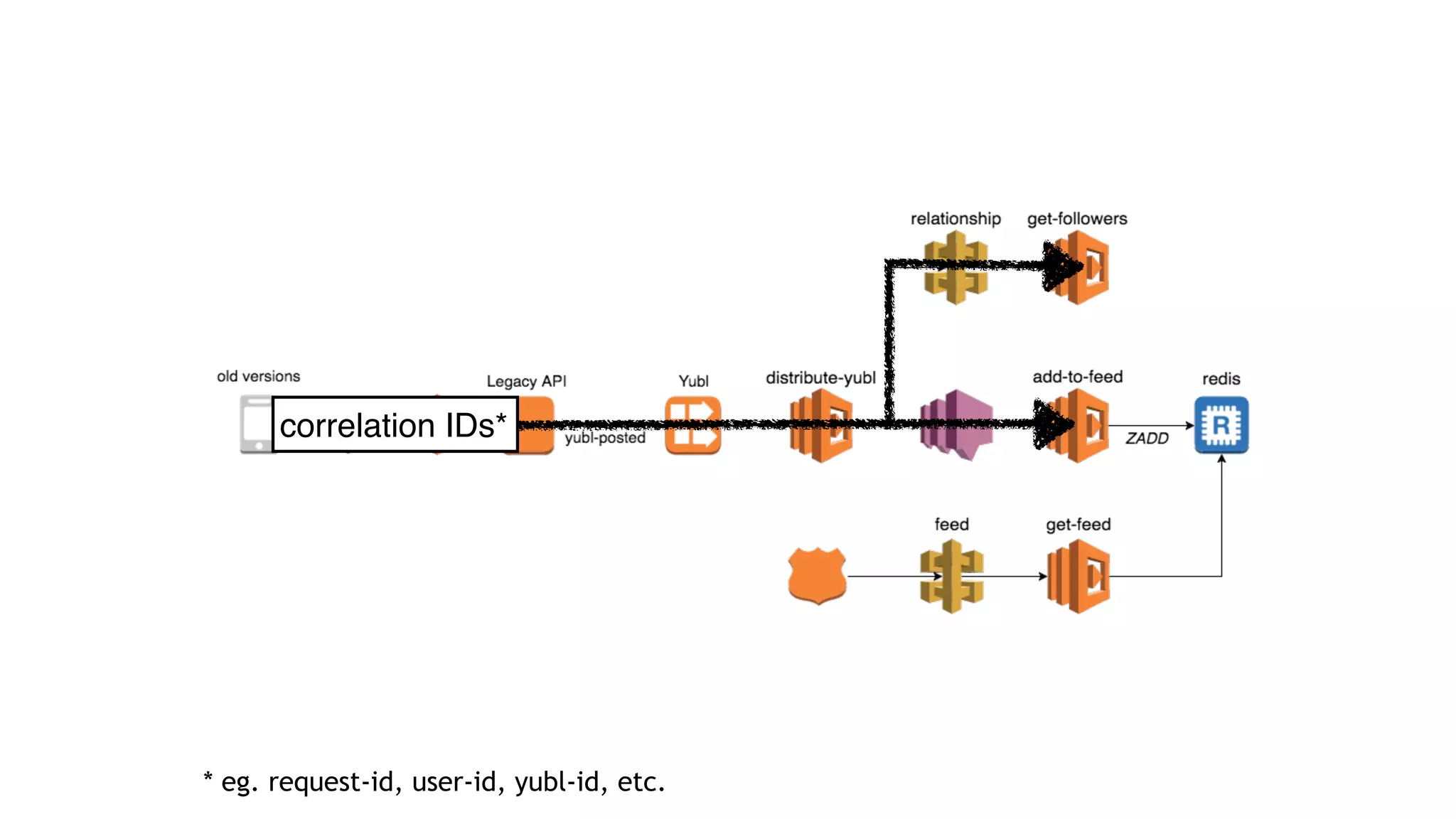
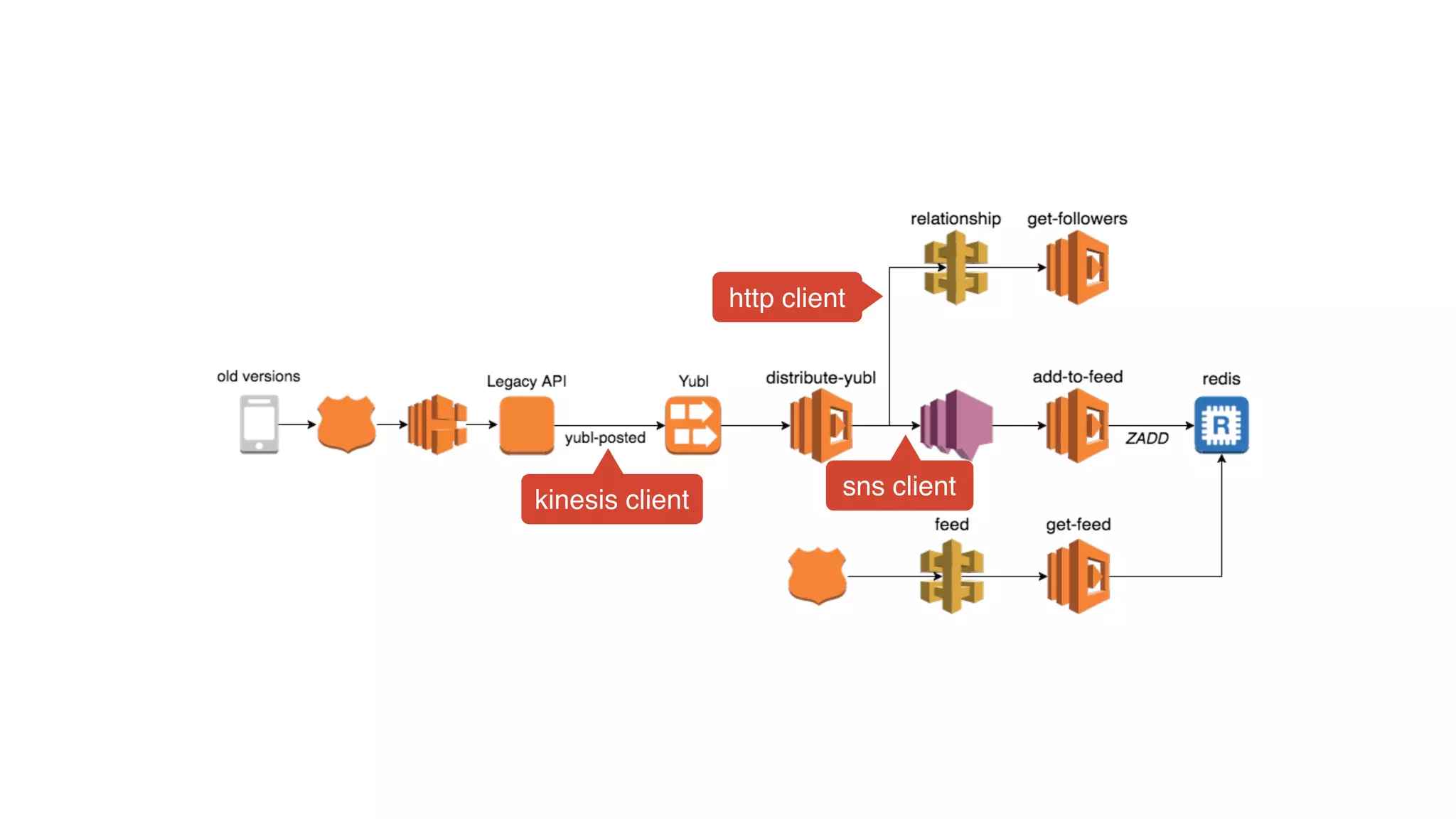




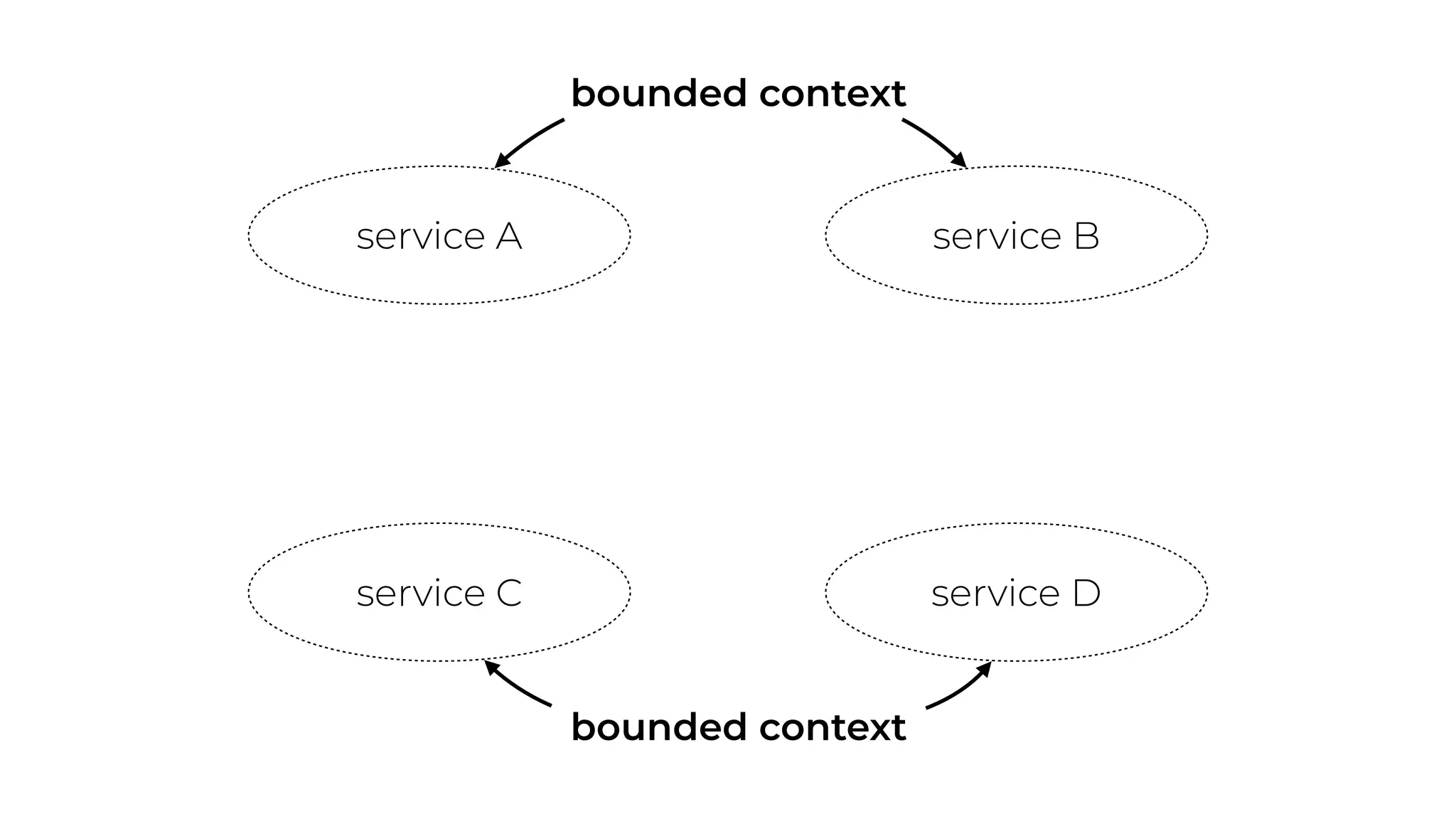
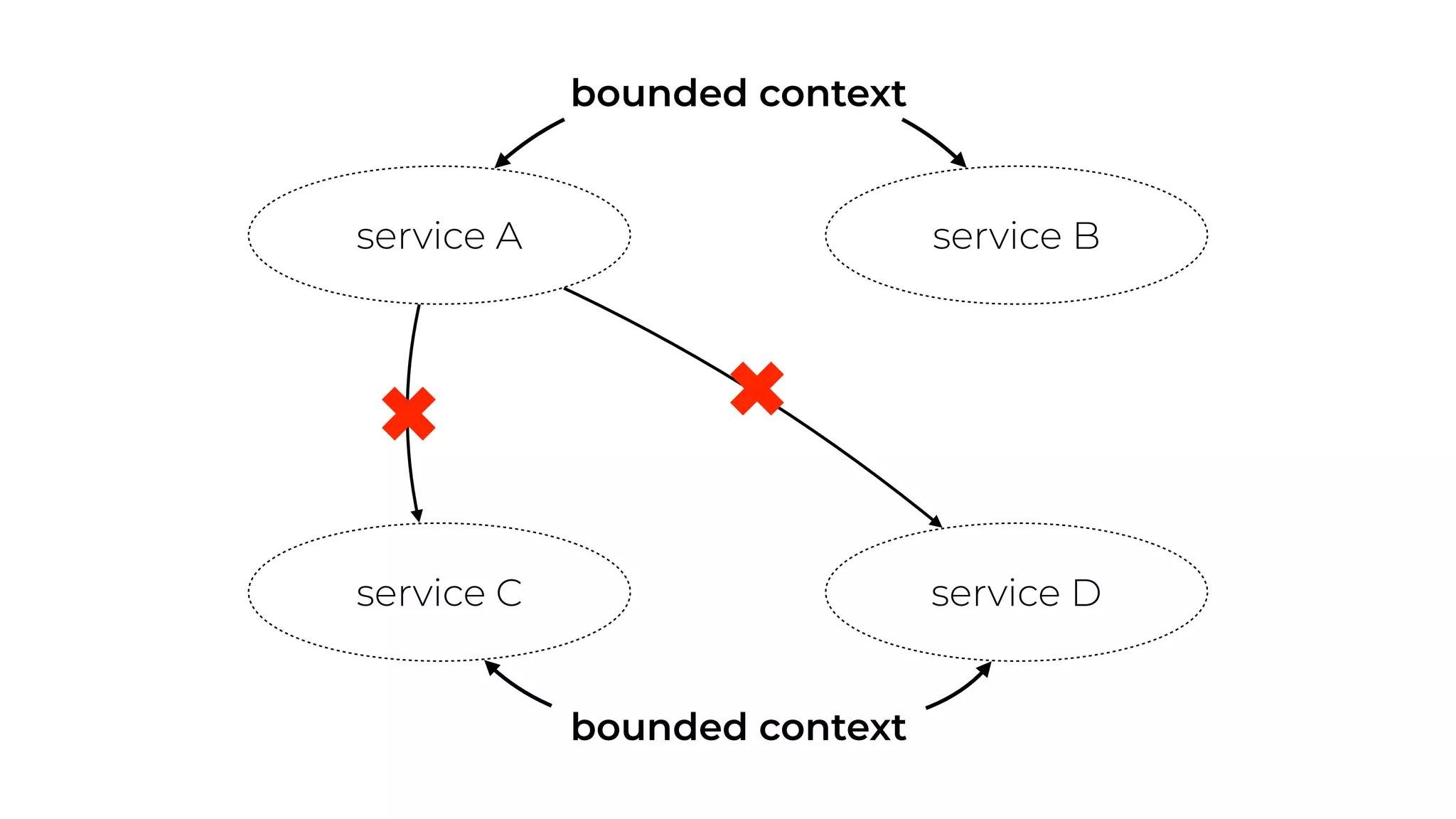

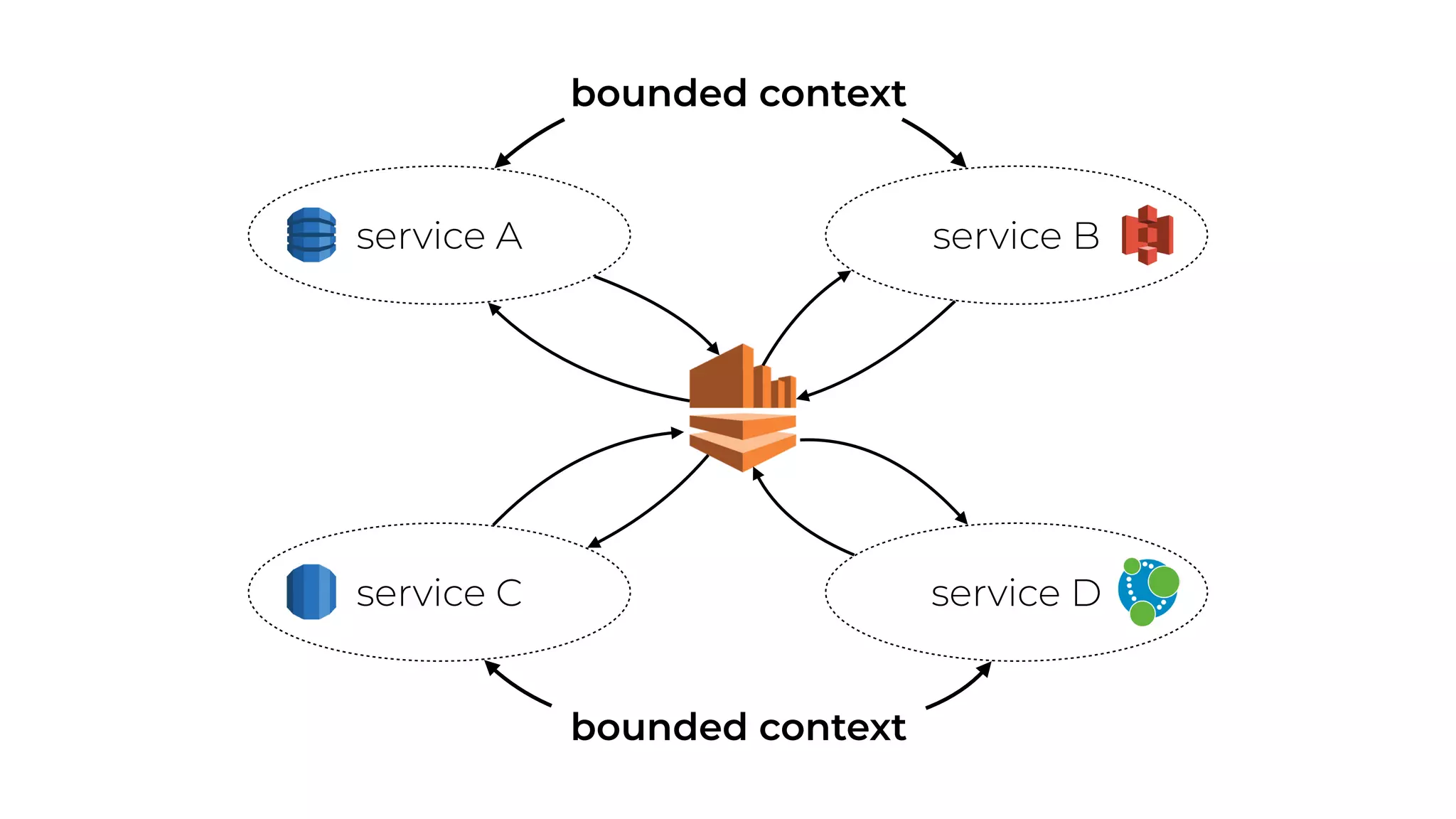


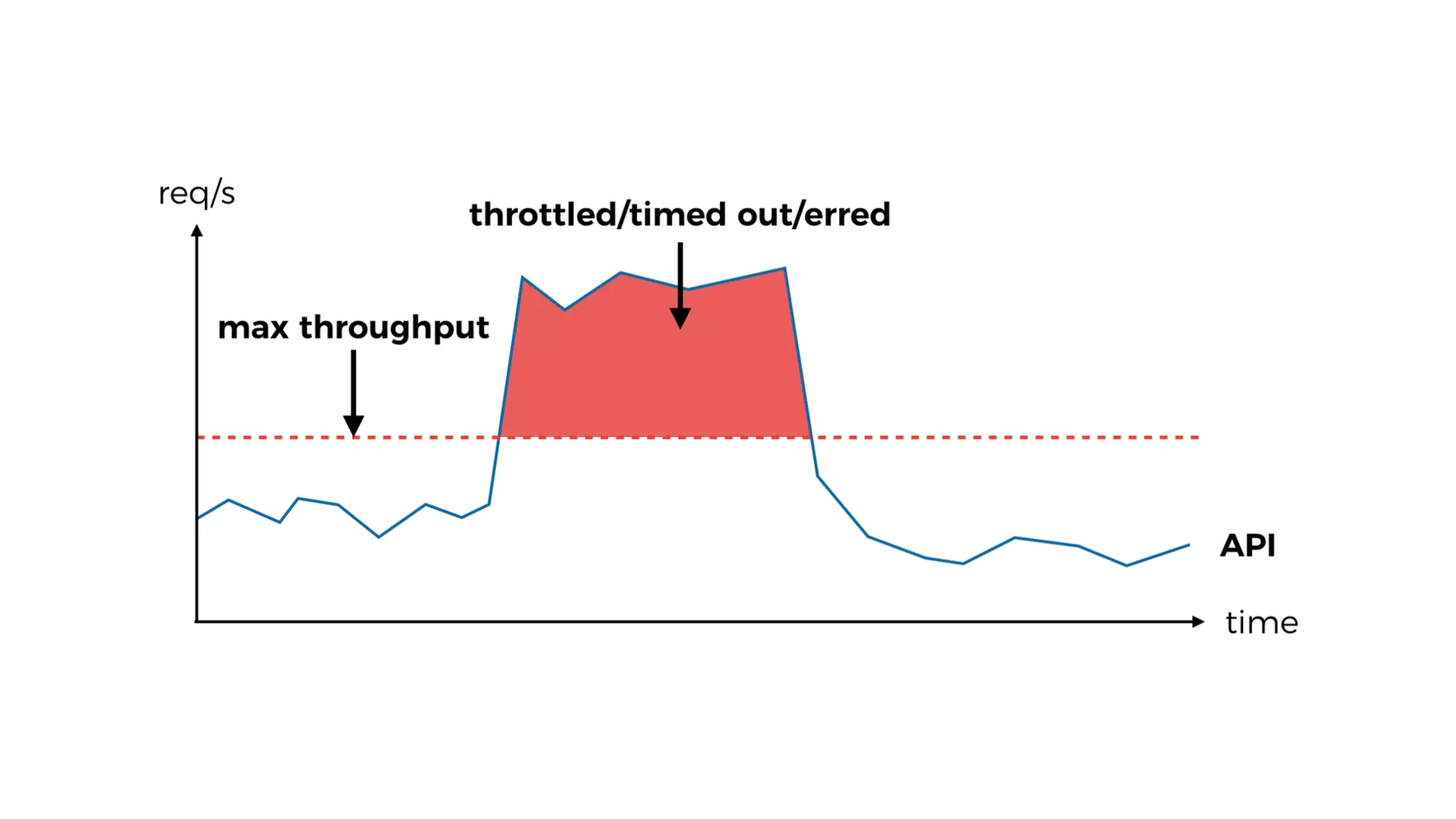
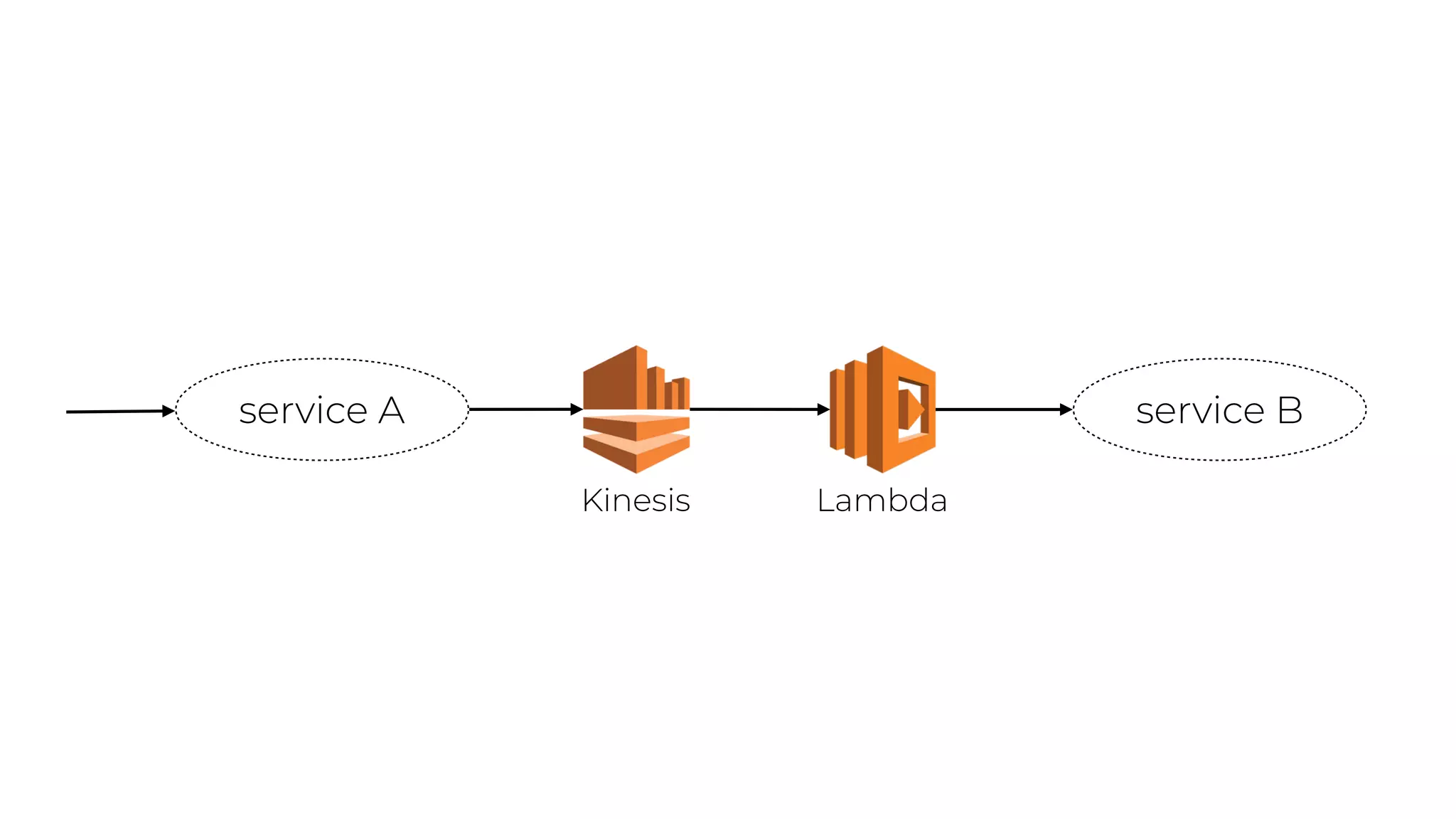
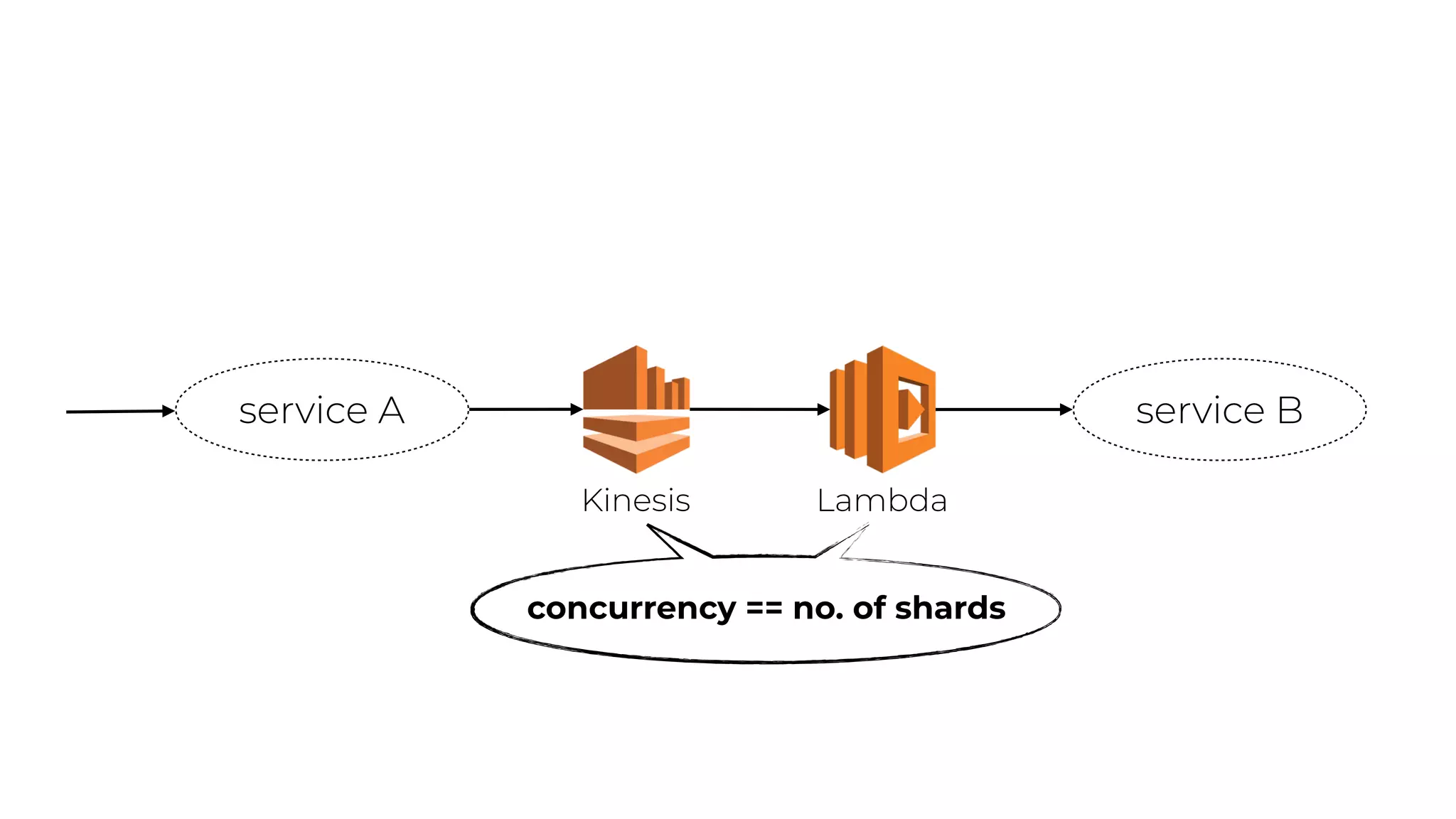
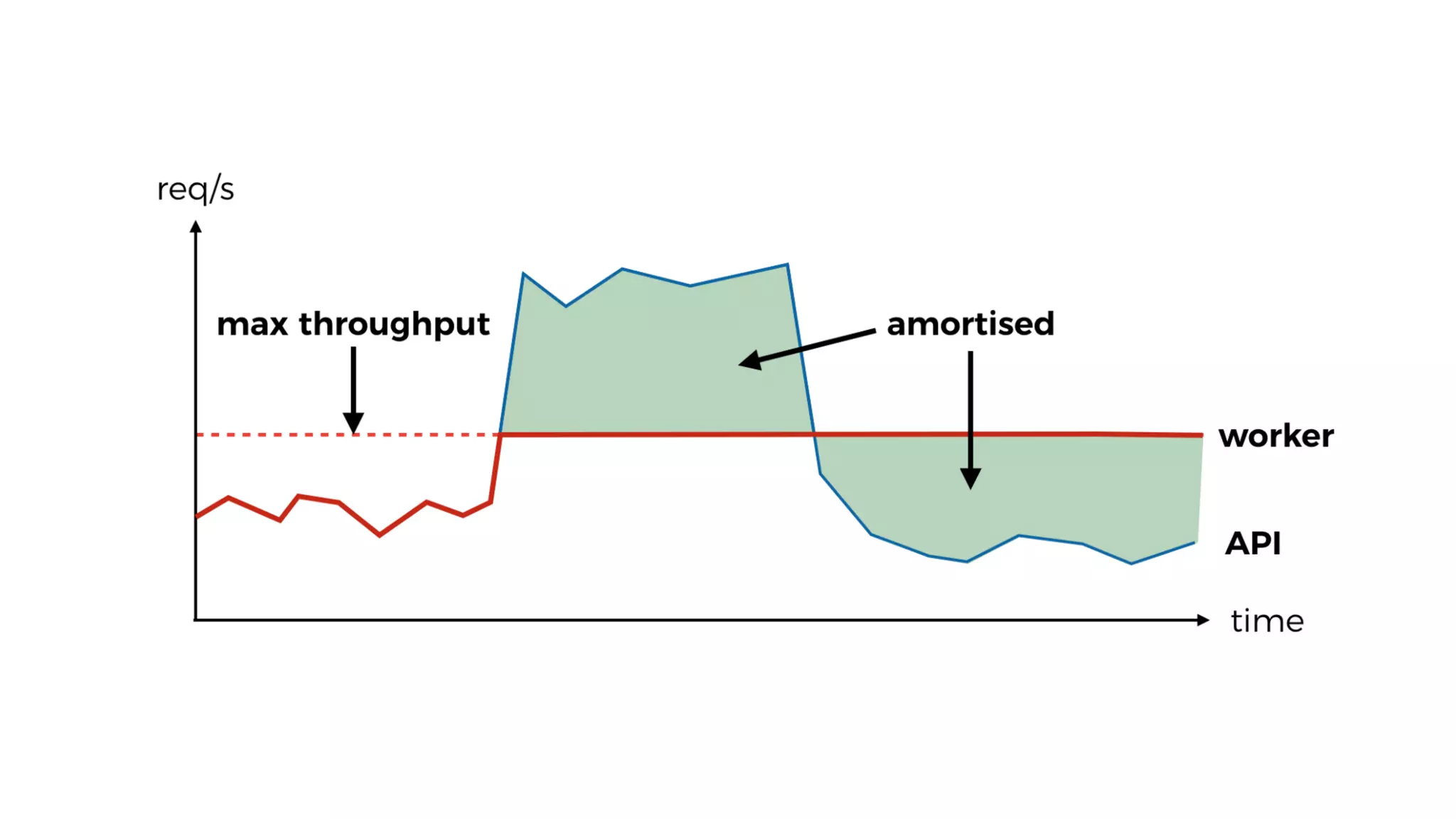
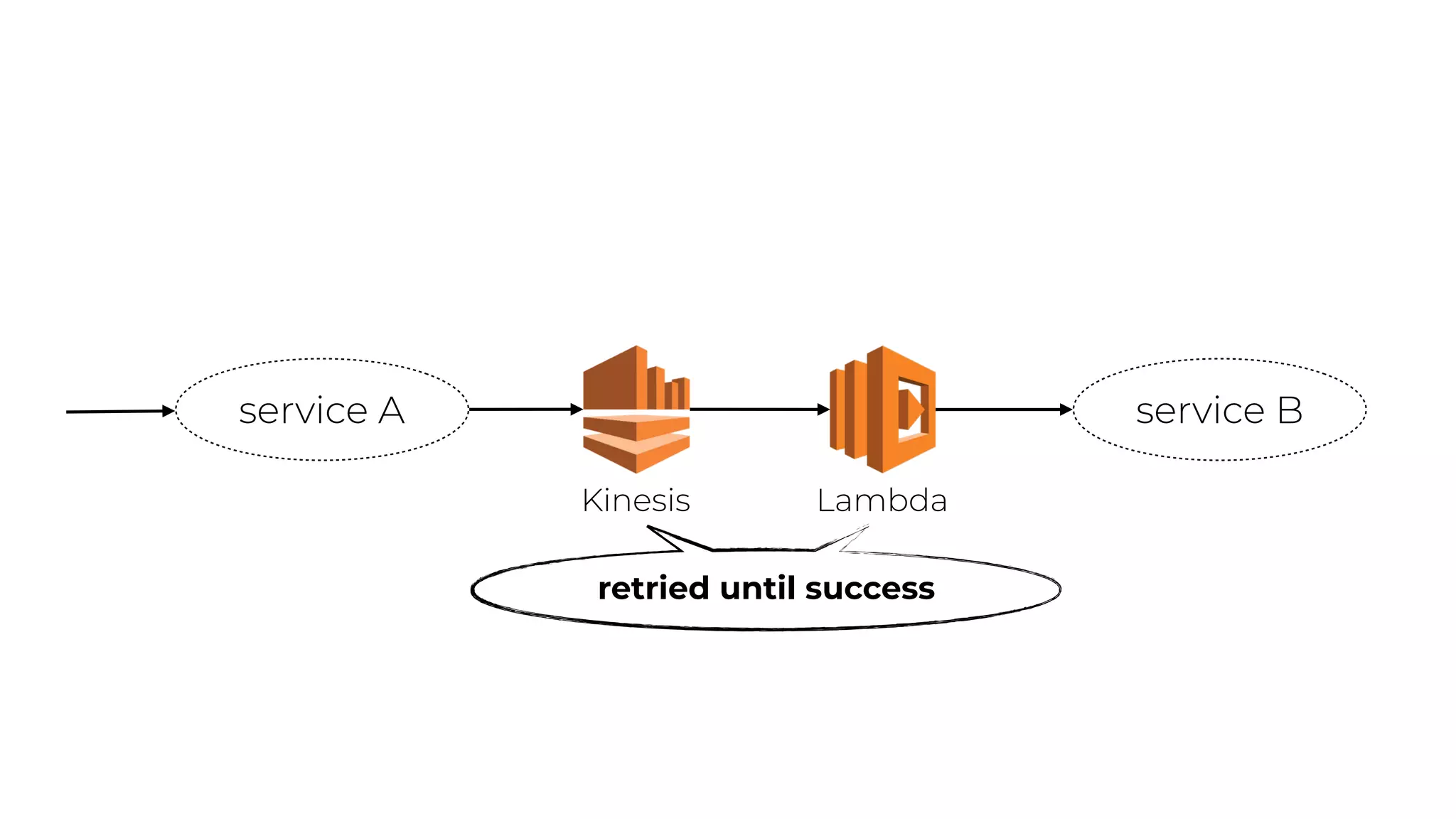






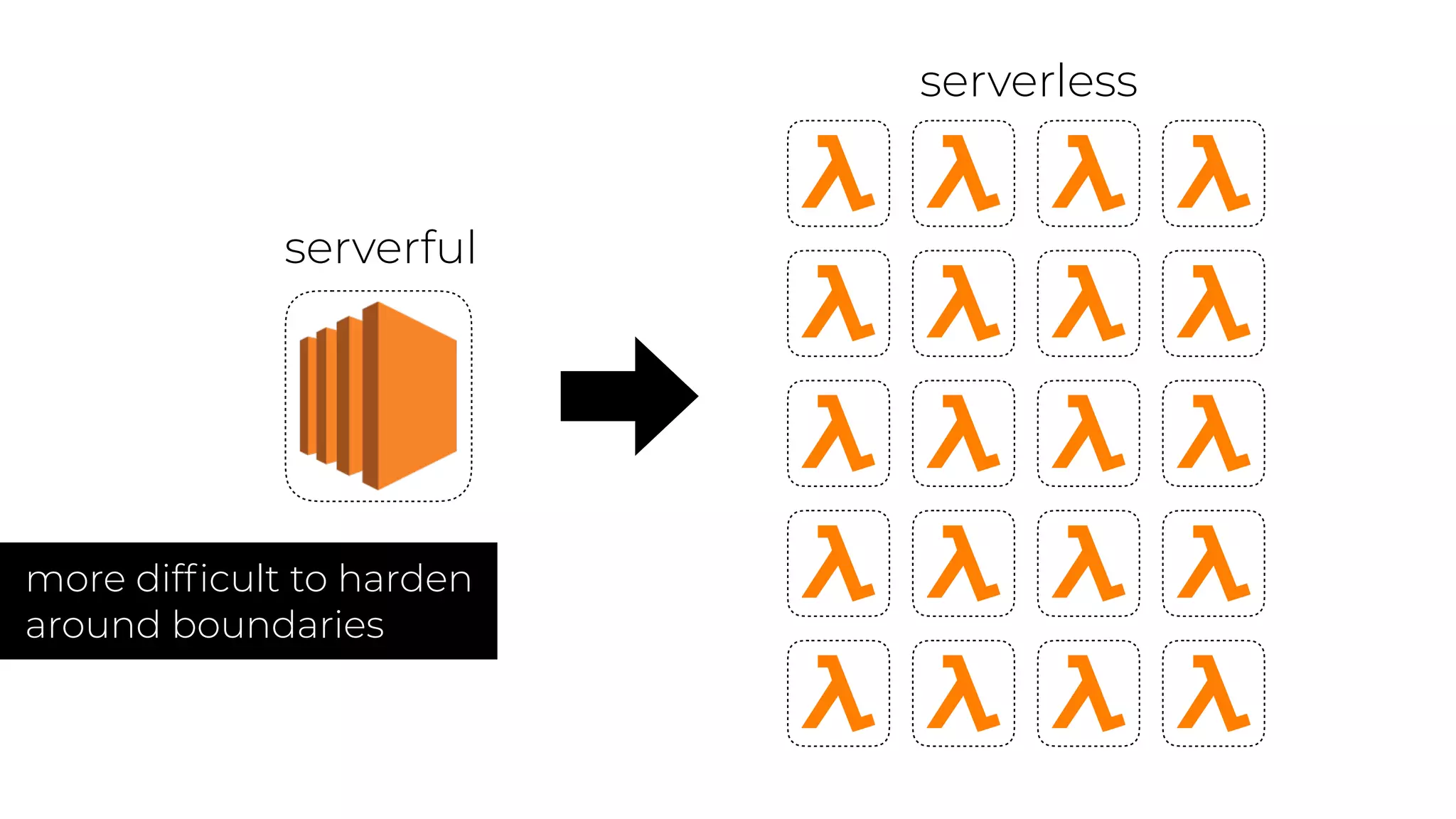
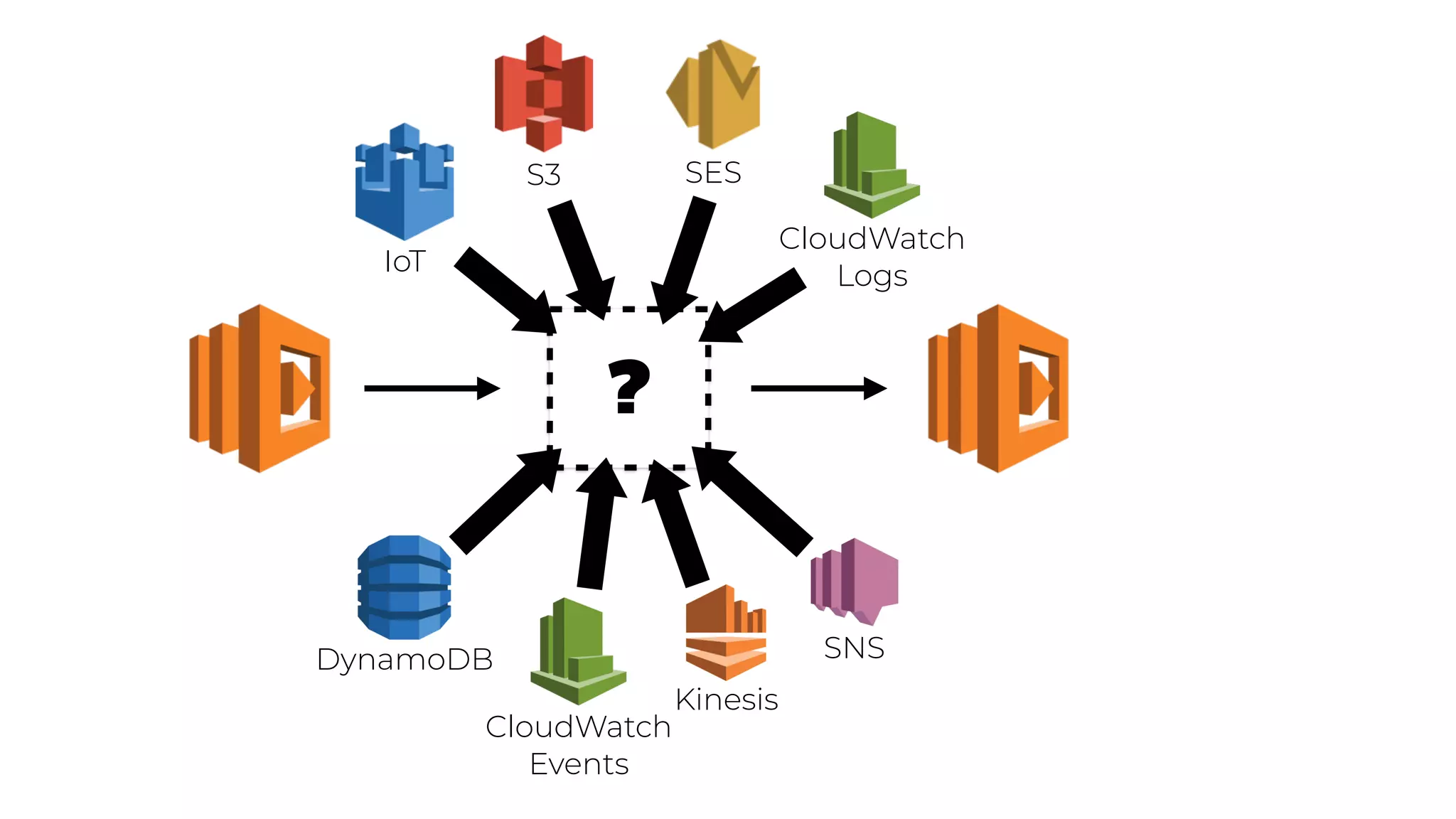
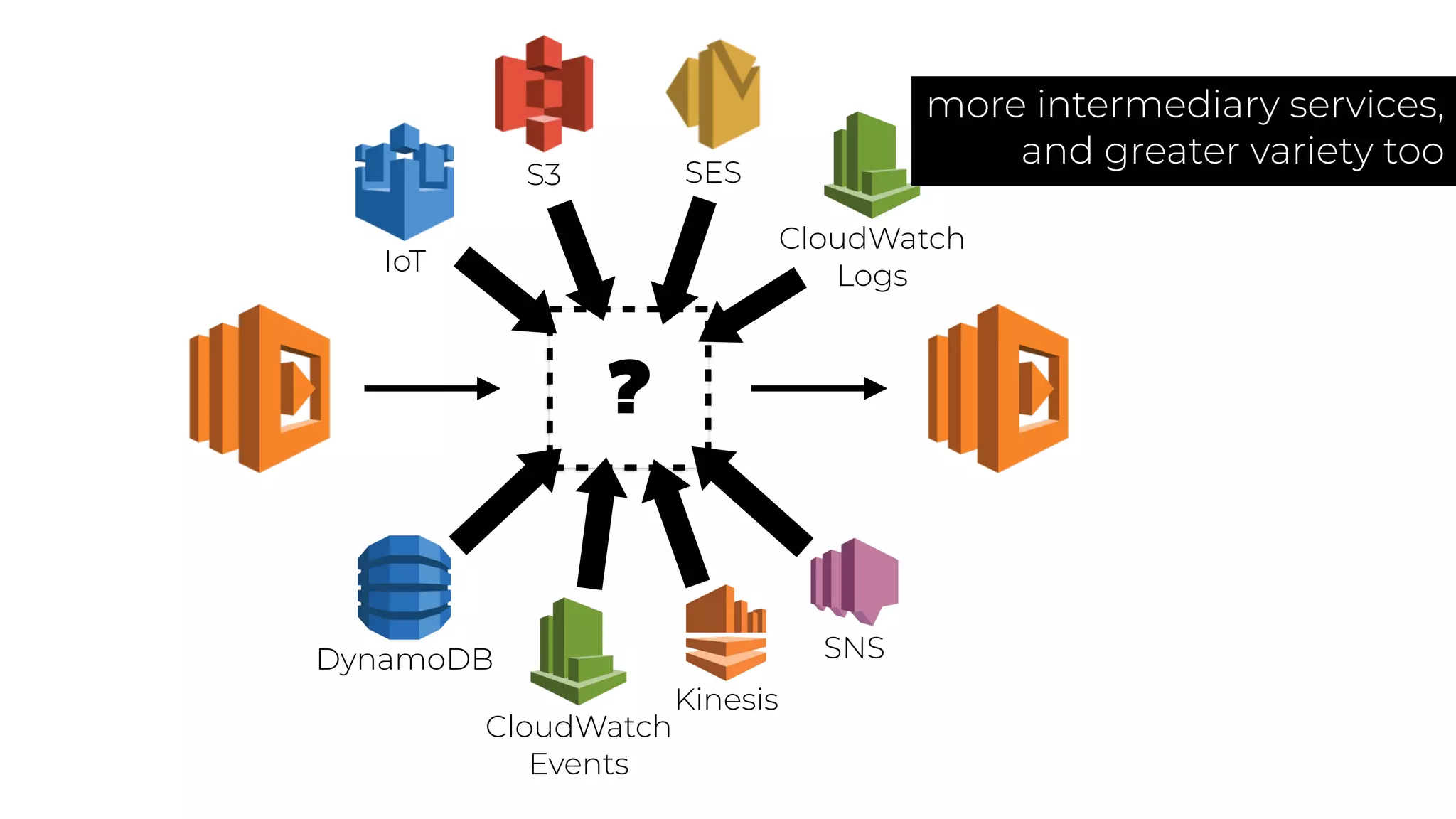
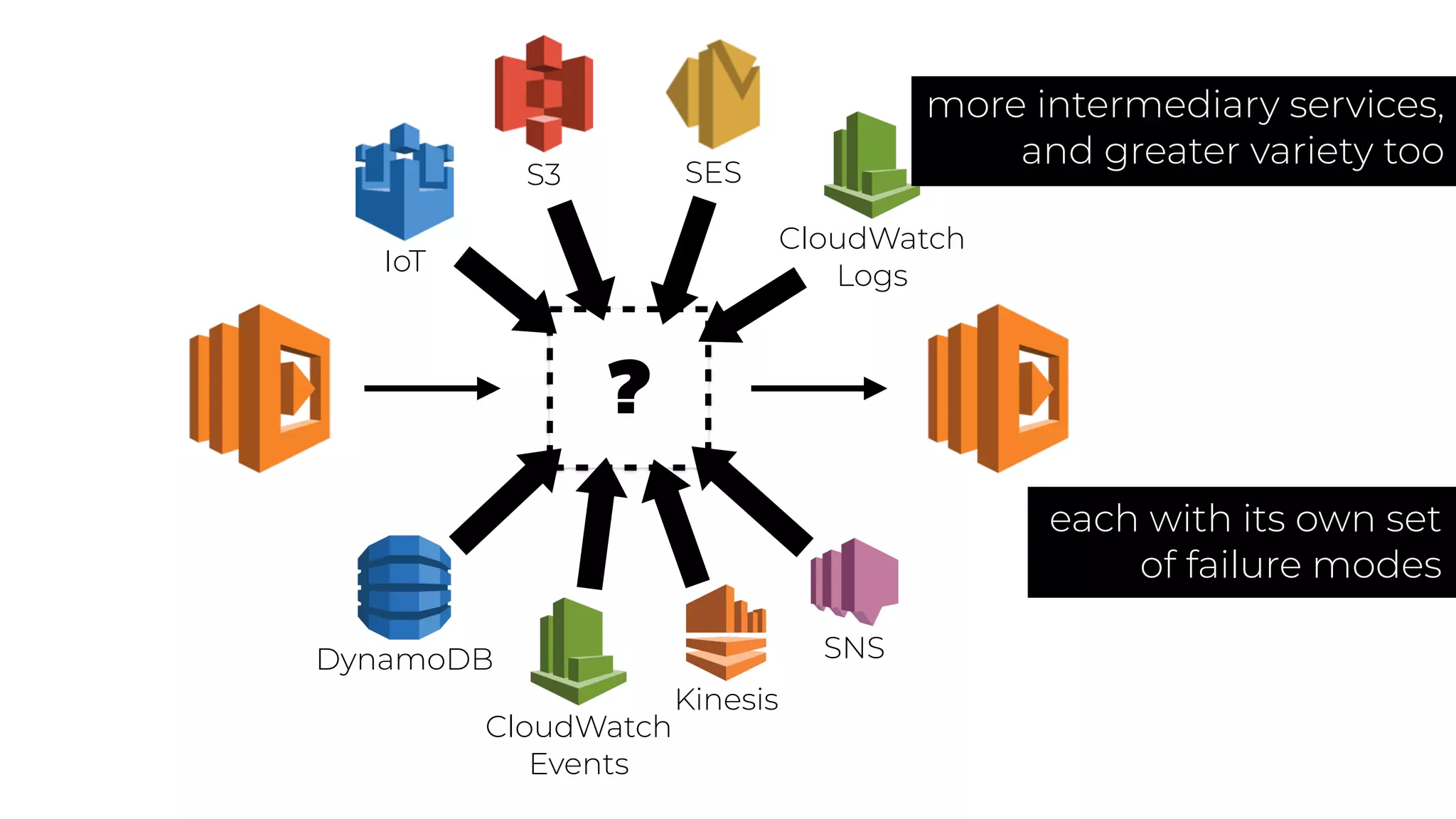
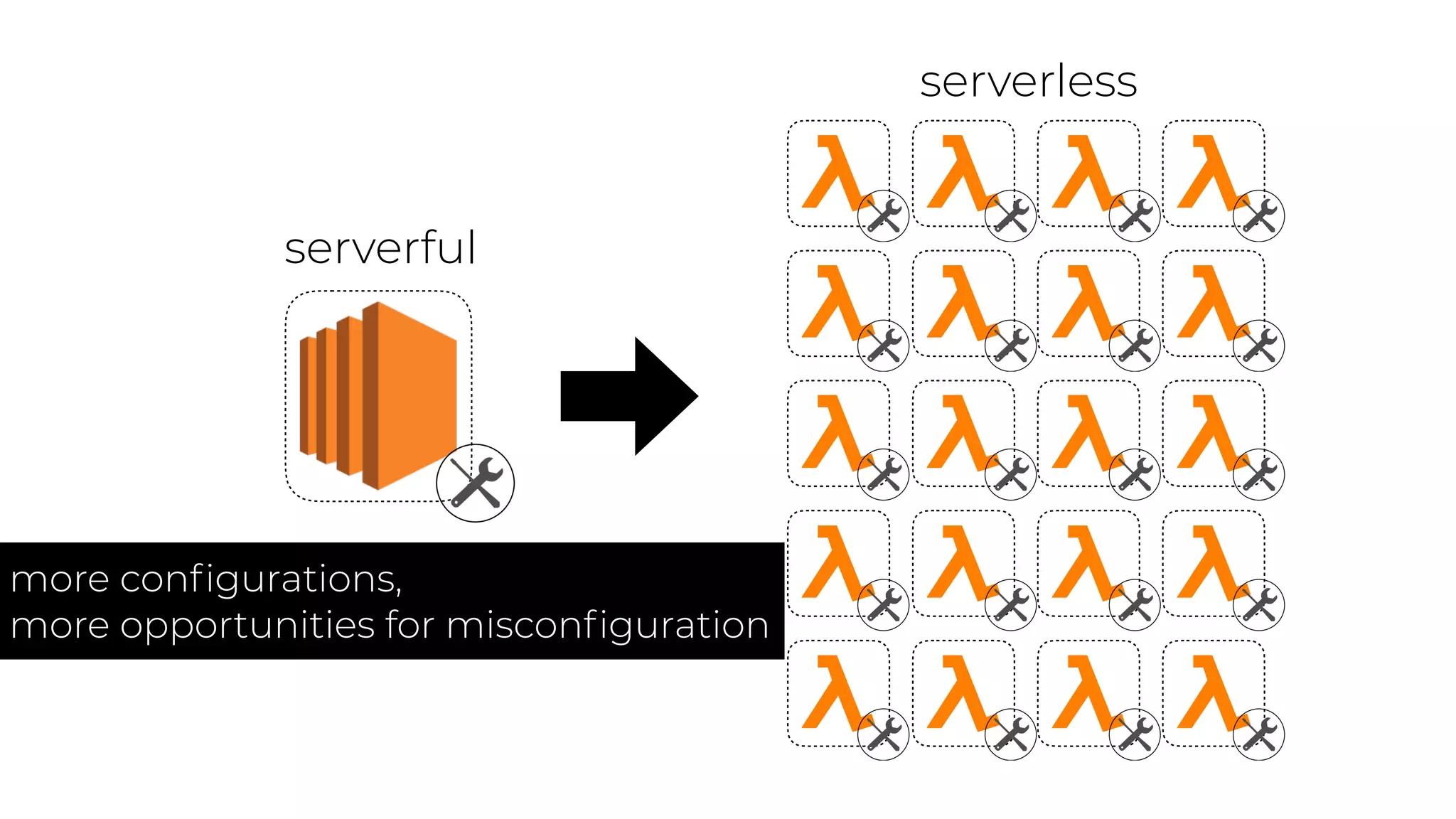


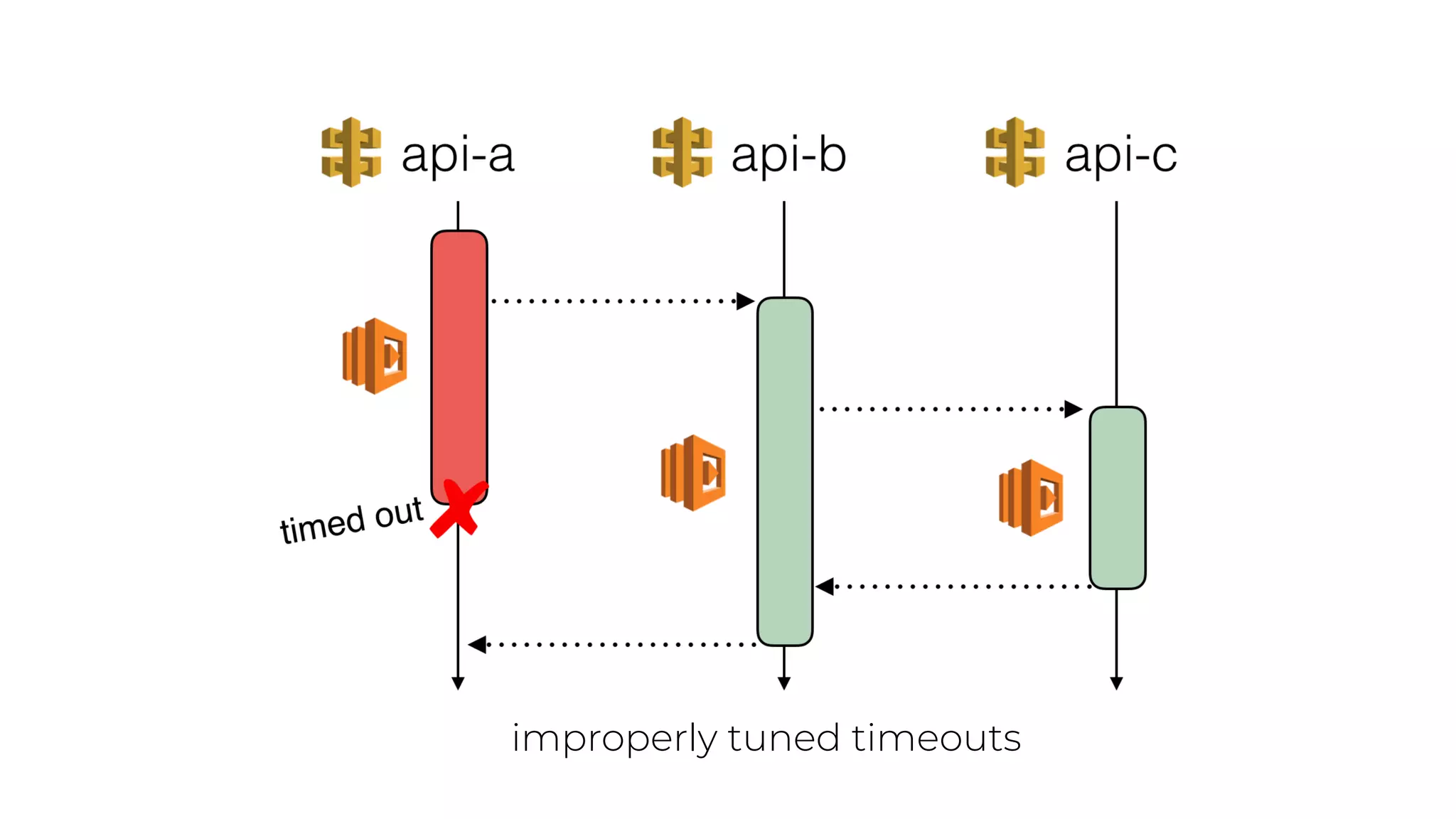
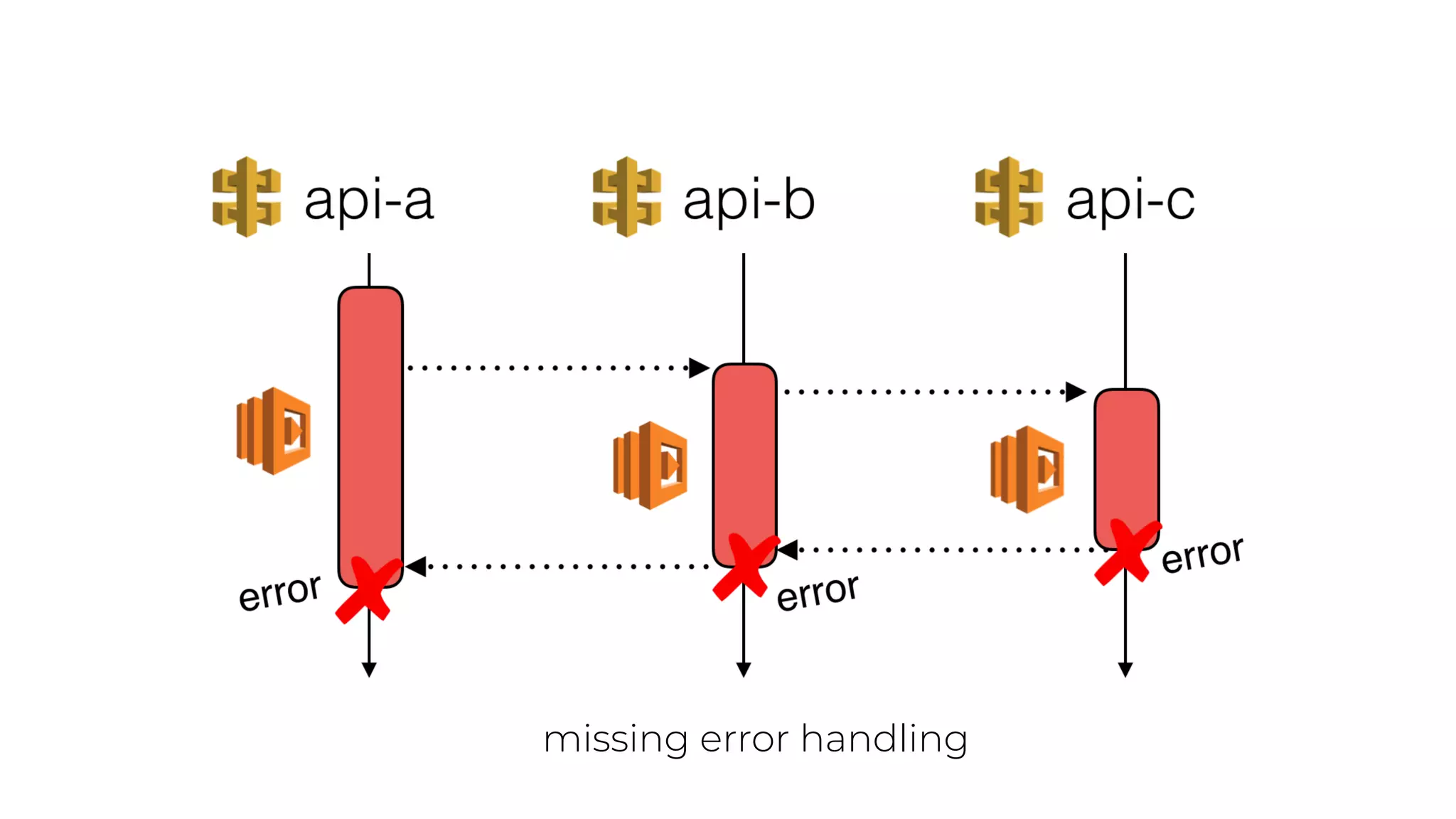


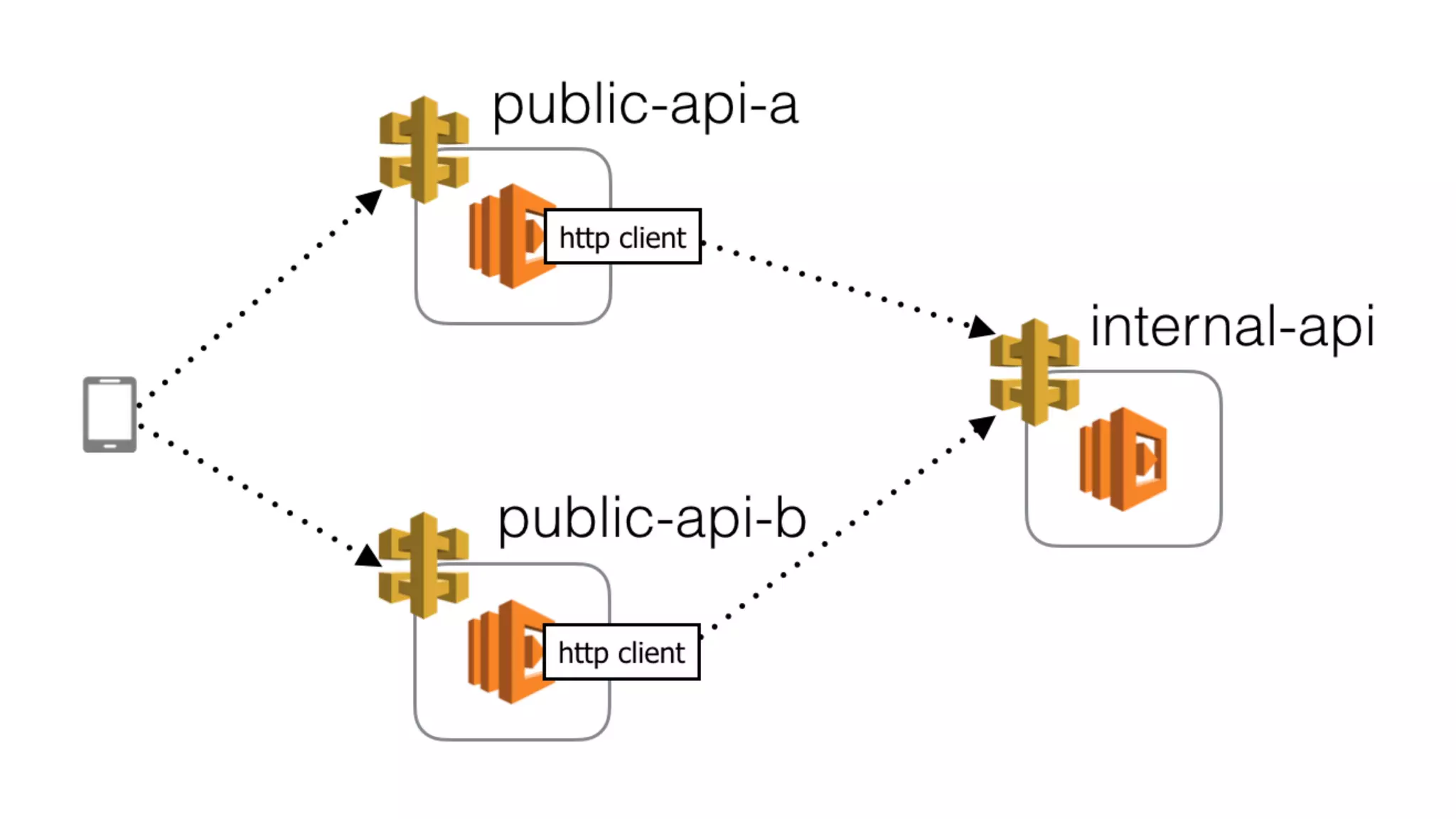
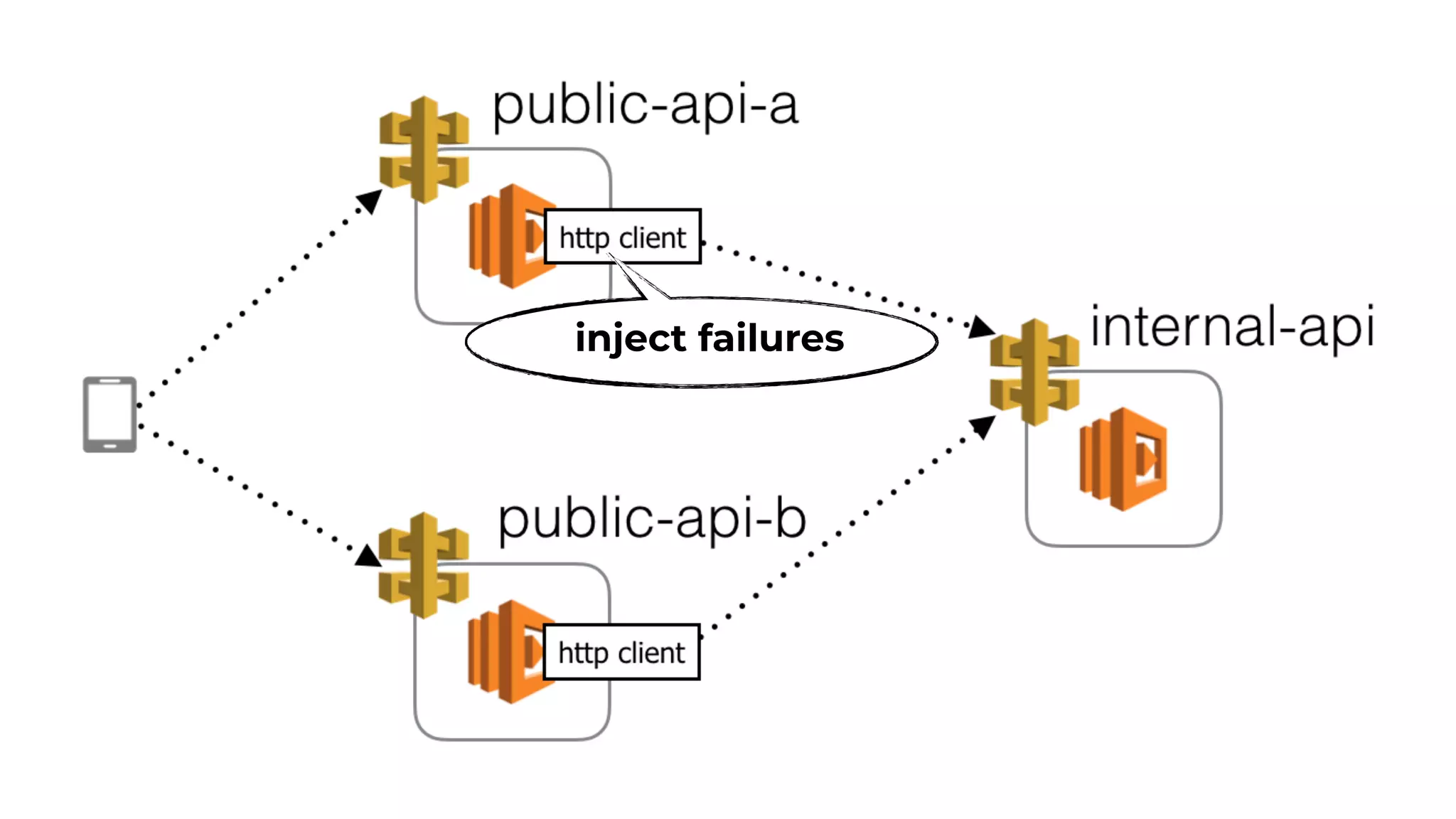
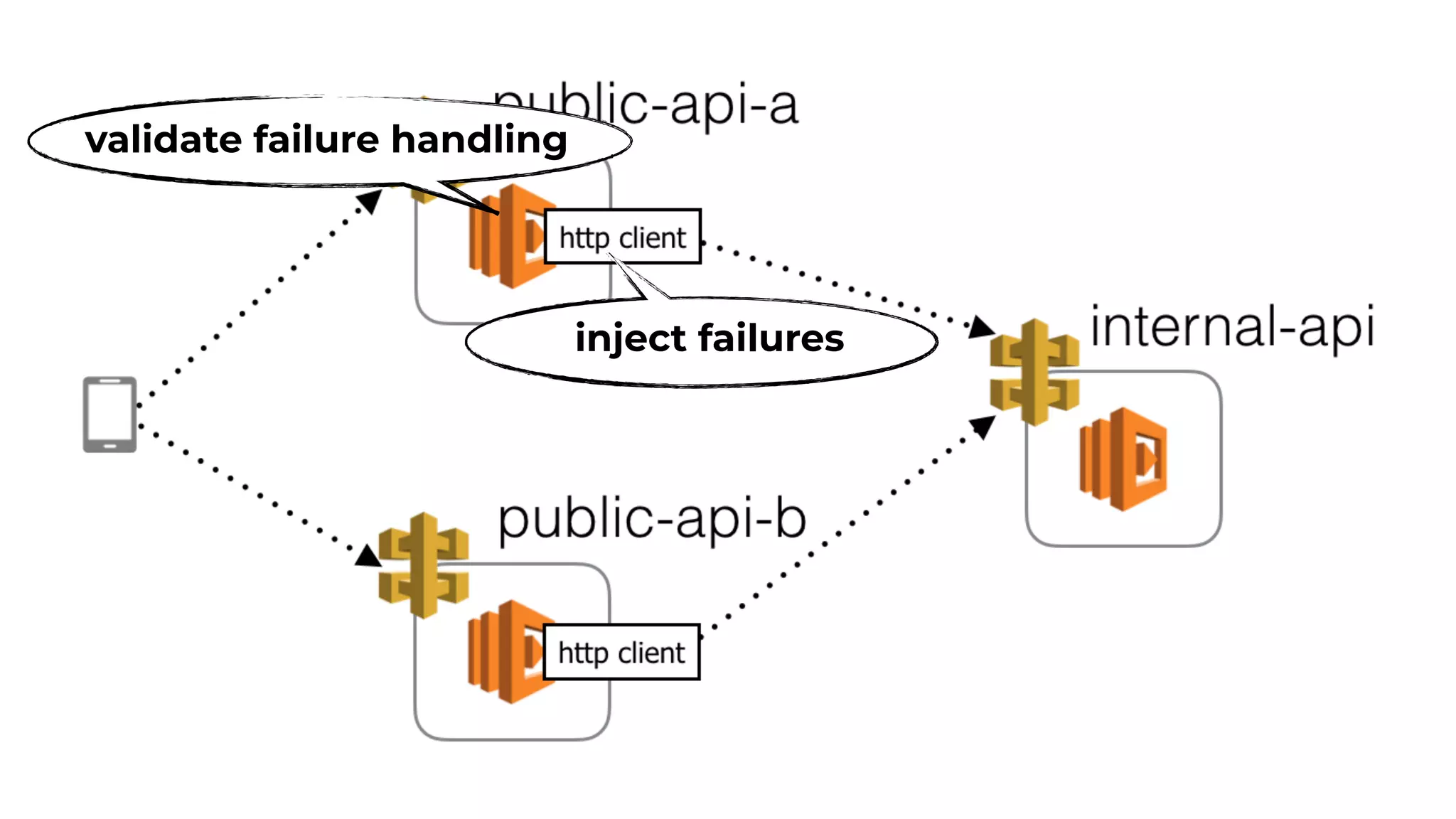
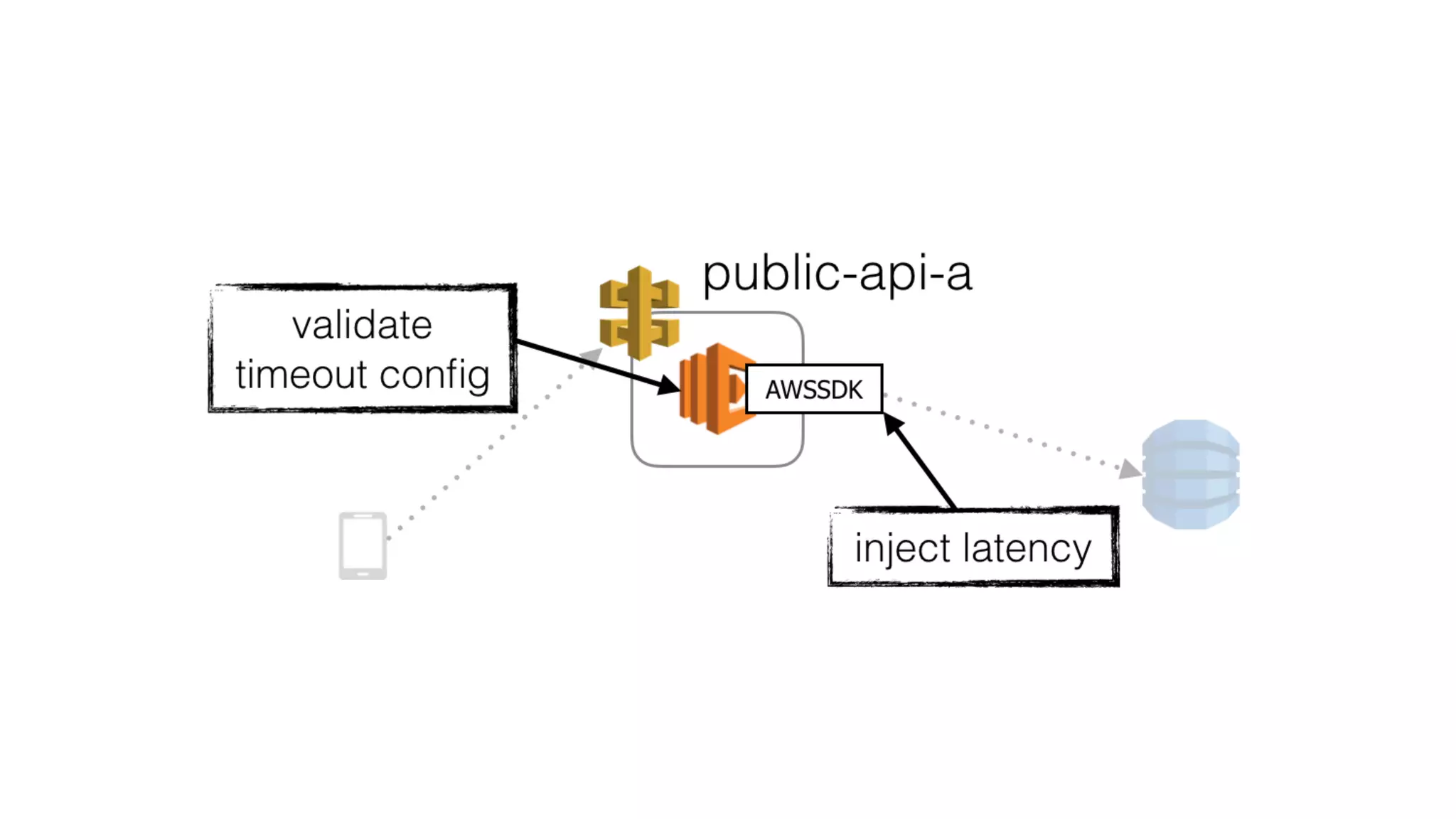








The document discusses the integration of microservices principles into serverless architectures, emphasizing observability and the importance of minimizing latency. It outlines key lessons for designing resilient systems, such as avoiding shared databases, managing spiky loads, and preparing for inevitable failures. The author also highlights best practices for logging and monitoring to improve performance and incident resolution in a serverless environment.























































































