Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
syou6162
7,540 views
はてなにおける機械学習の取り組み
HACKER TACKLE2018での登壇資料です。
Engineering
◦
Read more
4
Save
Share
Embed
Embed presentation
Download
Downloaded 12 times
1
/ 51
2
/ 51
3
/ 51
4
/ 51
5
/ 51
6
/ 51
7
/ 51
8
/ 51
9
/ 51
10
/ 51
11
/ 51
12
/ 51
13
/ 51
14
/ 51
15
/ 51
16
/ 51
17
/ 51
18
/ 51
19
/ 51
20
/ 51
21
/ 51
22
/ 51
23
/ 51
24
/ 51
25
/ 51
26
/ 51
27
/ 51
28
/ 51
29
/ 51
30
/ 51
31
/ 51
32
/ 51
33
/ 51
34
/ 51
35
/ 51
36
/ 51
37
/ 51
38
/ 51
39
/ 51
40
/ 51
41
/ 51
42
/ 51
43
/ 51
44
/ 51
45
/ 51
46
/ 51
47
/ 51
48
/ 51
49
/ 51
50
/ 51
51
/ 51
More Related Content
PDF
Mackerel Anomaly Detection at PyCon mini Osaka
by
syou6162
PDF
(道具としての)データサイエンティストのつかい方
by
Shohei Hido
PPTX
機械学習 / Deep Learning 大全 (1) 機械学習基礎編
by
Daiyu Hatakeyama
PPTX
早稲田大学 理工メディアセンター 機械学習とAI セミナー: 機械学習入門
by
Daiyu Hatakeyama
PDF
はてなにおける機械学習の取り組み
by
syou6162
PDF
正確な意思決定を阻む 問題・障害との向き合い方
by
syou6162
PDF
Jubatusが目指すインテリジェンス基盤
by
Shohei Hido
PDF
Jubatusにおける大規模分散オンライン機械学習@先端金融テクノロジー研究会
by
Yuya Unno
Mackerel Anomaly Detection at PyCon mini Osaka
by
syou6162
(道具としての)データサイエンティストのつかい方
by
Shohei Hido
機械学習 / Deep Learning 大全 (1) 機械学習基礎編
by
Daiyu Hatakeyama
早稲田大学 理工メディアセンター 機械学習とAI セミナー: 機械学習入門
by
Daiyu Hatakeyama
はてなにおける機械学習の取り組み
by
syou6162
正確な意思決定を阻む 問題・障害との向き合い方
by
syou6162
Jubatusが目指すインテリジェンス基盤
by
Shohei Hido
Jubatusにおける大規模分散オンライン機械学習@先端金融テクノロジー研究会
by
Yuya Unno
More from syou6162
PDF
半教師あり学習
by
syou6162
PDF
今日から始める機械学習〜はてなの事例〜
by
syou6162
PDF
自分の目的に合った統計量と そのバラ付きを計算しよう ~NPSを例に~(統計学勉強会)
by
syou6162
PDF
カスタマーサクセスのためのデータ整備人の活動記録
by
syou6162
PDF
機械学習を使った趣味サービスにおける工夫紹介
by
syou6162
PDF
Optimization In R
by
syou6162
PDF
機械学習を用いたMackerelの異常検知機能について
by
syou6162
PDF
教師なし学習によるMackerelの異常検知機能について 〜設計/運用/評価の観点から〜
by
syou6162
PDF
今日からできる構造学習(主に構造化パーセプトロンについて)
by
syou6162
PDF
異常検知ナイト LT登壇資料 はてな id:syou6162
by
syou6162
PDF
機械学習を活用したサービスにおける工夫紹介
by
syou6162
PDF
Mackerelのロール内異常検知の設計と運用
by
syou6162
PDF
オープンセミナー岡山 これから始めるデータ活用
by
syou6162
PDF
Mackerel Drink Up #9 ロール内異常検知の正式化
by
syou6162
PDF
Tsukuba
by
syou6162
PDF
Duolingo.pptx
by
syou6162
PDF
Syou6162 Dbcls
by
syou6162
PDF
Short Essay
by
syou6162
PDF
Kernel20110619
by
syou6162
PDF
R User Group 2009 Yoshida
by
syou6162
半教師あり学習
by
syou6162
今日から始める機械学習〜はてなの事例〜
by
syou6162
自分の目的に合った統計量と そのバラ付きを計算しよう ~NPSを例に~(統計学勉強会)
by
syou6162
カスタマーサクセスのためのデータ整備人の活動記録
by
syou6162
機械学習を使った趣味サービスにおける工夫紹介
by
syou6162
Optimization In R
by
syou6162
機械学習を用いたMackerelの異常検知機能について
by
syou6162
教師なし学習によるMackerelの異常検知機能について 〜設計/運用/評価の観点から〜
by
syou6162
今日からできる構造学習(主に構造化パーセプトロンについて)
by
syou6162
異常検知ナイト LT登壇資料 はてな id:syou6162
by
syou6162
機械学習を活用したサービスにおける工夫紹介
by
syou6162
Mackerelのロール内異常検知の設計と運用
by
syou6162
オープンセミナー岡山 これから始めるデータ活用
by
syou6162
Mackerel Drink Up #9 ロール内異常検知の正式化
by
syou6162
Tsukuba
by
syou6162
Duolingo.pptx
by
syou6162
Syou6162 Dbcls
by
syou6162
Short Essay
by
syou6162
Kernel20110619
by
syou6162
R User Group 2009 Yoshida
by
syou6162
はてなにおける機械学習の取り組み
1.
はてなにおける 機械学習の取り組み id:syou6162 HACKER TACKLE 2018@博多 1
2.
自己紹介 • id:syou6162(本名: 吉田康久) • 前職: NTTコミュニケーション科学基礎研究所 – 自然言語処理や機械学習の研究に従事(4年) •
2年前にはてなに転職 – はてなブックマーク – サーバー管理/監視システムMackerel • Web開発:機械学習関連の開発 = 8:2 2
3.
自己紹介 • id:syou6162(本名: 吉田康久) • 前職: NTTコミュニケーション科学基礎研究所 – 自然言語処理や機械学習の研究に従事(4年) •
2年前にはてなに転職 – はてなブックマーク – サーバー管理/監視システムMackerel • Web開発:機械学習関連の開発 = 8:2 3 R&D部門がない組織で機械学習を 使ったサービス開発の参考になると幸いです
4.
発表のゴール • はてなの事例を通じて – 機械学習を使ったサービス開発の 難しさ – その難しさを乗り越えていくための 技術的/組織的な取り組み方 • が見えてくる 4
5.
はてなって機械学習使ってるの? 5
6.
はてなでの機械学習の利用事例 • はてなブックマークのカテゴリ判定 • はてなブックマークのスパム判定 •
はてなブックマークのトピックページ • BrandSafe はてな • エリアガイド • Mackerelの異常検知 6 表には出てこないものも 多いけど、色々なところで 機械学習使っています!
7.
はてなブックマークのカテゴリ判定 7
8.
エリアガイド 8 hNp://area.b.hatena.ne.jp/ 博多のお土産情報を チェック!
9.
Mackerelの異常検知 • 一定期間を学習データとし、確率密度の低い 点を異常として検知 • 教師なし学習の問題設定 9 デスクで作業中
ランニングしている時間 異常と判定されるケース1 => ルールでもできそう? 参考: hNps://speakerdeck.com/sugiyama88/mackerel-meetup-number-11 hNp://www.yasuhisay.info/entry/2018/02/16/001000 活動量 心拍数 異常と判定されるケース2 => 今の自分
10.
Mackerelの異常検知 • 一定期間を学習データとし、確率密度の低い 点を異常として検知 • 教師なし学習の問題設定 10 休日や夜間等比較的 負荷の低いケース 平日を中心とした比較的 負荷の高いケース 異常と判定されるケース1 参考: hNps://speakerdeck.com/sugiyama88/mackerel-meetup-number-11 hNp://www.yasuhisay.info/entry/2018/02/16/001000 異常と判定されるケース2
11.
発表のゴール • 機械学習を使ったサービス開発の 難しさ • その難しさを乗り越えていくための技術 的な取り組み – 古典的な問題設定 – R&D要素の強い問題設定 •
組織的な取り組み方 11
12.
機械学習アプリケーションの難しさ • 挙動の把握が難しい • 属人性が高くなりやすい •
再現性が低くなりやすい • 継続的な開発がしにくい 12
13.
挙動の把握が困難 • 機械学習を利用しないアプリケーション – コードを見れば挙動の把握は大体できる • 機械学習を利用するアプリケーション – コードのみからは挙動の把握ができない – コード×データがあれば挙動の推測は不可能では ないが、知識と経験が必須 – Deep Learningはさらに把握が難しい – 誤判定でユーザーに説明が必要な場面も 13
14.
属人性 / 再現性 • 属人性が高い –
機械学習タスクは実験を通じた試行錯誤が必要 – 普段のサービス開発と異なり、レビューが難しい • 問題設定、実験方法、本番投入などで段階的にレビューが 必要 • 再現性が低い – コードだけでなくモデルやデータの管理が不十分 – 管理ノウハウが発展途上 • 何をどうやって管理すればよいのか – 実験を行なった人でも再現できないことも… 14
15.
継続的開発 • 機械学習システムも継続的な開発が必要 – Webアプリケーション開発と一緒 • 継続的開発のためには有効性を示す – モデル改善の有効性をきちんと計測できるように •
実験上はもちろん、本番環境でも – APIのバージョニング • 複数のバージョンのモデルを同時に動かせるように 15
16.
発表のゴール • 機械学習を使ったサービス開発の 難しさ • その難しさを乗り越えていくための技術 的な取り組み – 古典的な問題設定 – R&D要素の強い問題設定 •
組織的な取り組み方 16
17.
BrandSafeはてなリニューアル • BrandSafeはてなとは? – URL単位でWebページを解析、アダルトサイトや 2chまとめサイトか判定する仕組み – 自社広告を出したくないサイトへの出稿を防ぎ、 ブランドイメージを安全に保つ • Pythonでリニューアル – 元々Perlで書かれていた – はてなブックマークとの密結合を解消 – 機械学習部分も見直し 17 技術的詳細: hNps://www.slideshare.net/oarat/brand-42816575
18.
BrandSafeはてなの問題設定と目的 • 問題設定 – 教師あり機械学習 – 対象はテキストデータ • 目的 – 属人性を低く、再現性を高くする •
何をどこをどのように管理するのか明確に – 継続的な開発ができるように • きちんとコード/モデル/データのバージョン管理をする • 性能のトラッキング 18
19.
教師あり機械学習の開発フロー 元データ 学習データ 特徴ベクトル
モデル テストデータ 特徴ベクトル 判定結果 アノテーション 前処理 特徴量抽出 機械学習アルゴリズム 19 学習時 テスト時
20.
前処理、特徴量抽出、アルゴリズム、 モデル(リニューアル前) • 基本的にコードでバージョン管理できる部分 • 基本的にはPerlのコードをGitで管理 •
一部のモデルパラメータはDBで保存 – バージョン管理はされていないので、巻き戻しで きない 20
21.
前処理、特徴量抽出、アルゴリズム、 モデル(リニューアル後) • scikit-learnを利用、pythonのエコシステムに乗る • モデルファイルもバージョン管理 •
挙動が把握しやすい/解釈性の比較的高い線形 モデル(SVM、ロジステック回帰)を使うことが多い • LSTMやCNNも試したが、複雑性の割に性能がほ ぼ変わらず現段階では不採用 – 教師データ数もそれほど多くないことも関係している かも 21
22.
学習データ管理(リニューアル前) • 決まった管理方法はなかった – 基本はGoogle Driveに置く – 個人PC上あり、危うく消えるところだったものも… • データはURLとラベルを保存、本文はDBから 取得 – 本文に変更があれば、再現性は担保できない… 22
23.
学習データの管理(リニューアル後) • 置き場所を決める – Google Driveはそのまま – 現状はそこまでサイズが大きくない – DBでもよいが、リニューアル前はDBアクセスがボ トルネックになり、実験の試行錯誤がやりづらい • データの固定 – データに本文、前処理の結果などを含める – バージョン毎に管理 •
データを変えたら、一括してバージョンを変更 23
24.
データ収集方法とアノテーション基準(1) • 機械学習においてデータは最重要 – 「データを増やす」はモデル改善の主要なアプ ローチ – データが悪ければよいモデルでもうまくいかない • 集めた元データとアノテーション結果、だけで はなく「データ収集方法」と「アノテーション基 準」も記録 24
25.
データ収集方法とアノテーション基準(2) • データ収集方法 – 収集方法でデータの性質も異なってくる • 例1: はてなブックマークの特定タグが付いた記事 •
例2: 特定の単語でGoogle検索して出てきた記事 – 気を付けないとバイアスがかかり性能が悪化 • テスト時のデータと性質が違うデータ – なぜそのアプローチも取ったか分かるとよい – 特徴量へのヒントにもなる 25
26.
データ収集方法とアノテーション基準(3) • アノテーション基準 – 基準が揺れると作ったデータやモデルは無駄になる –
例: アダルト判定の基準 • サイドバーの内容は考慮するのか • アダルト広告は考慮するのか – 例: スパム判定 • 過去記事は考慮するのか • ドメイン知識を持っていない場合は特に綿密に – 例: 営業担当とアノテーション基準について議論 26
27.
データ収集方法とアノテーション基準(4) • 文書化 – 試行錯誤していると後回しになりがち – まとめたものをGoogle Docsやリポジトリにcommit – 最近ならJupyter Notebookでもよいですね • 今回は使わなかった特徴量集合の試行錯誤 の様子が分かると、改善時の手間が減らせる 27
28.
発表のゴール • 機械学習を使ったサービス開発の 難しさ • その難しさを乗り越えていくための技術 的な取り組み – 古典的な問題設定 – R&D要素の強い問題設定 •
組織的な取り組み方 28
29.
29 hNps://mackerel.io/ja/ Mackerel: SaaS型の サーバー監視/管理 サービス サービス(例: はてなブログ)/ ロール(例: DB、Proxy)で 分かりやすくグルーピング 静的な閾値による アラートの発砲、Slack などへの通知をサポート Agentがサーバーの メトリックを収集、 グラフで可視化
30.
監視における課題と 機械学習の活用 • 監視における課題 – ミドルウェアなどの知識が必要 – 監視ルールのメンテナンスは手間がかかる • 機械学習を用いた異常検知の利点 – データから学習、自動的に監視ルールを決めて アラートできる – 知識がなくても、何かが異常であることが分かる 30
31.
再掲: Mackerelの異常検知 • 一定期間を学習データとし、確率密度の低い 点を異常として検知 • 教師なし学習の問題設定 31 休日や夜間等比較的 負荷の低いケース 平日を中心とした比較的 負荷の高いケース 異常と判定されるケース 参考: hNps://speakerdeck.com/sugiyama88/mackerel-meetup-number-11 hNp://www.yasuhisay.info/entry/2018/02/16/001000 どのように試行錯誤したか紹介します
32.
タスク着手時の障壁 • 社内で機械学習を使った異常検知の知見を 持っている人がゼロ • 教科書は読んだが、実データに対してどれだ けうまくいくか分からない – 検知漏れがないか/誤検知がないか – うまく行かない例も説明可能/人間が納得できそ うなものか 32
33.
調査フェイズ • 課題の性質を明らかにすることが目的 • 社内の過去の障害事例を分析 – 絶対数の多い障害パターンは? – 障害の要因は? – どういった特徴量であれば捉えられる? •
生の事例と向き合う 33
34.
プロトタイプフェイズ • 典型事例だった障害に対して様々な方法を ひたすら試す – ライブラリの使用/自前、手段は問わない – 既存のツールでは異常を捉えられるのか試す • 手法の得手不得意や計算量の肌感覚を掴む •
進め方についてサブ担当が適宜レビュー • 手元だけでは誤検知の多さが分かりにくい – 実際のデータを定常的に流してみる 34 http://www.yasuhisay.info/entry/2017/11/06/163000
35.
アルゴリズム決定フェイズ • 学習時/予測時の計算機コスト • 挙動が人間に説明可能か(サポート対応必須) •
機械学習に詳しくないチーム内のエンジニアが レビュー可能か/引き継ぎ可能か – 直感的に理解可能か – チューニングを頑張らないと精度が出ない、だとダメ • 手元で過去のモデルを使って再現が容易に行な えるか 35
36.
実装フェイズ • アルゴリズムがfixされたらチーム内外で輪講 • 機械学習に詳しくないエンジニアにもレビュー やサブタスクを担当してもらい知見を共有 •
社内の実際のデータも使ってテストを動かす 36
37.
発表のゴール • 機械学習を使ったサービス開発の 難しさ • その難しさを乗り越えていくための技術 的な取り組み – 古典的な問題設定 – R&D要素の強い問題設定 •
組織的な取り組み方 37
38.
組織的な取り組み(1) • 各サービスに機械学習詳しい人物がいても1 人か2人。いないときもある – 専門的なレビューを受けるのはなかなか難しい… • サービス横断の機械学習会を設立、知見を 集約 •
各サービスで機械学習案件が必要なときは 機械学習会が専門的観点でレビュー • 半月に一度、定例会で近況をまとめる 38 hNp://developer.hatenastaff.com/entry/2018/01/11/081000
39.
組織的な取り組み(2) • はてなの教科書に機械学習講義を追加、属 人性が下がるように • 実データを使った練習問題も用意 •
Perl/Scala/Pythonによるお手本実装、サブ会 メンバーによる回答レビュー 39 hNp://developer.hatenastaff.com/entry/hatena-textbook-machine-learning-01-2016
40.
組織的な取り組み(3) • そもそもR&Dに近いような案件に取り組める 土壌作り • 論文読み会/輪講会 – 新規性や技術的な正確性よりも着眼点の面白さ や自社サービスにどう生かせそうかを議論 •
機械学習ハッカソン 40 hNp://developer.hatenastaff.com/entry/2017/04/28/130000 hNp://developer.hatenastaff.com/entry/2017/09/27/170000 hNp://developer.hatenastaff.com/entry/2017/09/27/170000
41.
発表のゴール • はてなの事例を通じて – 機械学習を使ったサービス開発の 難しさ – その難しさを乗り越えていくための 技術的/組織的な取り組み方 • が見えてくる 41
42.
42
43.
発表時には使わなかった おまけスライド 43
44.
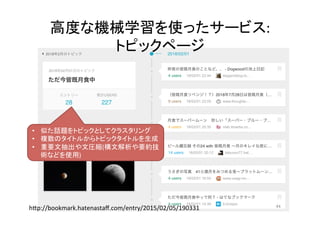
高度な機械学習を使ったサービス: トピックページ 44 • 似た話題をトピックとしてクラスタリング • 複数のタイトルからトピックタイトルを生成 •
重要文抽出や文圧縮(構文解析や要約技 術などを使用) hNp://bookmark.hatenastaff.com/entry/2015/02/05/190331
45.
アダルト まとめサイト Ruby gem Golang GAE 分離平面 iPhone Swih エンジニア 転職 サーバー監視 Mackerel iPhone アプリ おすすめ データ収集方法とアノテーション基準(5) 能動学習による効率的なアノテーション 45 機械学習 Python アフィリエイトサイト
46.
アダルト まとめサイト Ruby gem Golang GAE 分離平面 iPhone Swih エンジニア 転職 サーバー監視 Mackerel iPhone アプリ おすすめ データ収集方法とアノテーション基準(5) 能動学習による効率的なアノテーション 46 機械学習 Python アフィリエイトサイト この辺ばかりアノテーションしていても -
精度は上がらない - 精神は病むので、つらい - しかし、ランダムに選ぶとこの辺がたくさん…
47.
アダルト まとめサイト Ruby gem Golang GAE 分離平面 iPhone Swih エンジニア 転職 サーバー監視 Mackerel iPhone アプリ おすすめ データ収集方法とアノテーション基準(5) 能動学習による効率的なアノテーション 47 機械学習 Python アフィリエイトサイト
分離平面に近い(=分類器があまり自信がない) 事例から優先的にアノテーション
48.
• 同じ400件をアノテーションするならば、より精度 が高い分類器を作れる400件のほうがよい 48 hNp://www.yasuhisay.info/ entry/2017/05/18/080000 hNps://github.com/syou6162/go- acjve-learning データ収集方法とアノテーション基準(5) 能動学習による効率的なアノテーション 注意: 実験結果は趣味プロジェクト の結果であり、社内データを 使ったものではありません。
49.
特徴量抽出での工夫: 共通で使える特徴量抽出器を用意 49 タスクA タスクB タスクC 特徴量抽出A
特徴量抽出B 特徴量抽出C 学習データA 学習データB 学習データC 分類器A 分類器B 分類器C • 各タスクで学習データ作成/特徴量抽出を頑張る必要がある • 少量の教師データではカバーできなかった語は誤判定の要 因
50.
共通で使える特徴量抽出器を用意 50 タスクA タスクB タスクC 特徴量抽出A
特徴量抽出B 特徴量抽出C 学習データA 学習データB 学習データC 分類器A 分類器B 分類器C 共通特徴量抽出
51.
特徴量抽出での工夫: 様々なタスクで使えるリソースを整備 51 タスクA タスクB タスクC 特徴量抽出A
特徴量抽出B 特徴量抽出C 学習データA 学習データB 学習データC 分類器A 分類器B 分類器C 共通特徴量抽出 タスクに依存しないデータセット(wikipediaなど)から 埋め込みベクトルやクラスタリング特徴量を作成。 誤判定が減って、性能も上がる
Download