Download to read offline











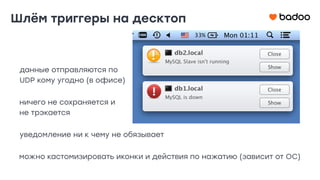


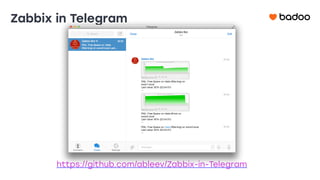









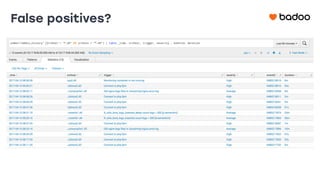



Документ обсуждает использование Zabbix для мониторинга систем в компании Badoo, с акцентом на эффективность настройки и автоматизации уведомлений о проблемах. Основные задачи отдела мониторинга включают проверку систем, отображение статуса и отправку уведомлений, с отдельными инструментами для управления триггерами и дашбордами. Также рассматриваются плюсы и минусы различных методов уведомления, такие как SMS и Telegram, и подчеркивается важность анализа ложных срабатываний триггеров.






















































