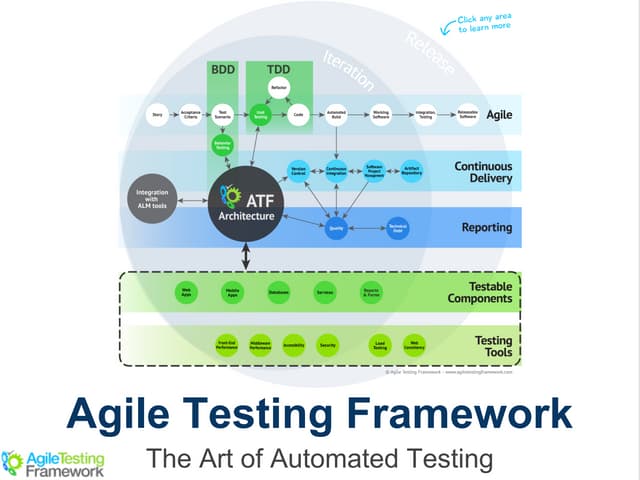
Download as PDF, PPTX












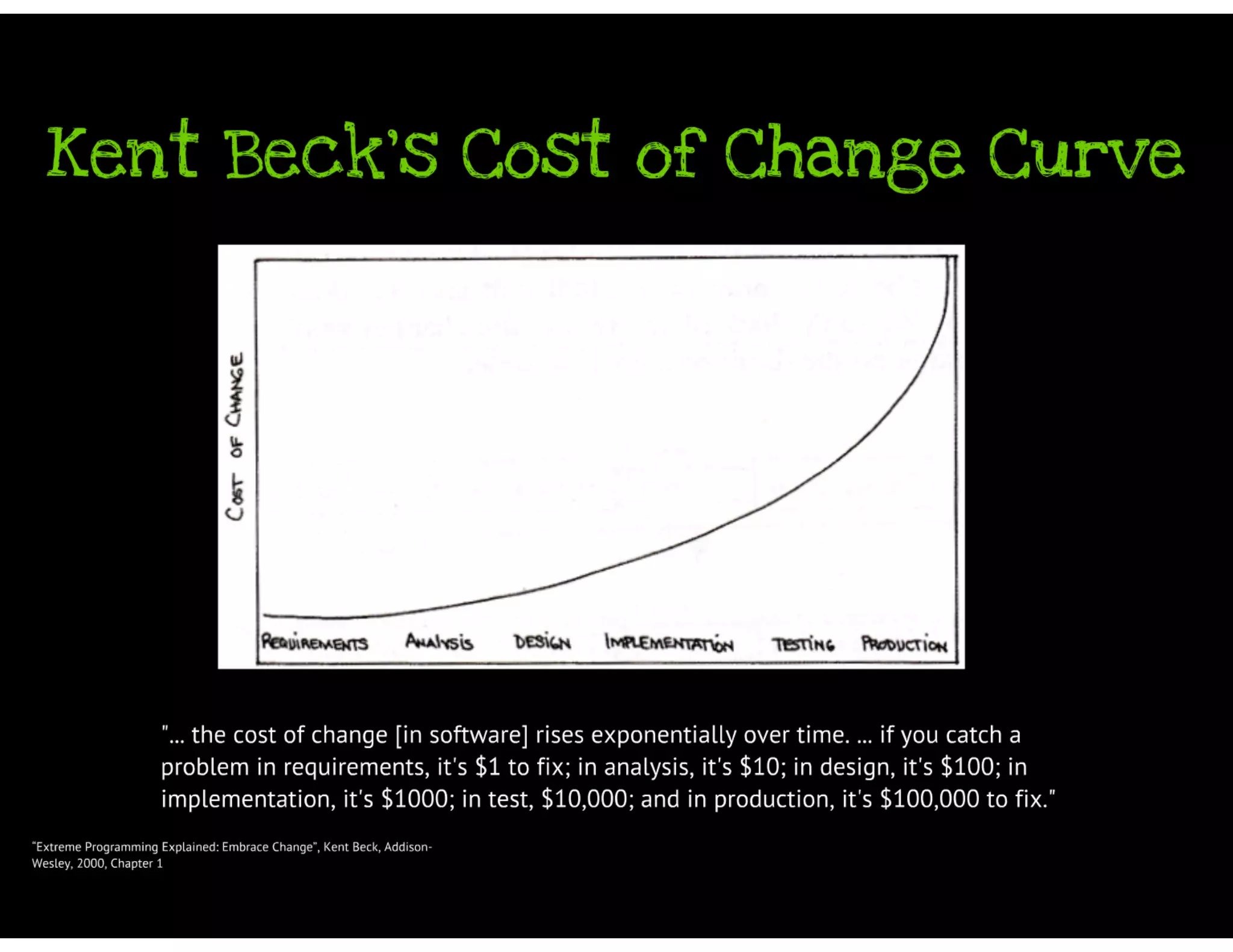

























































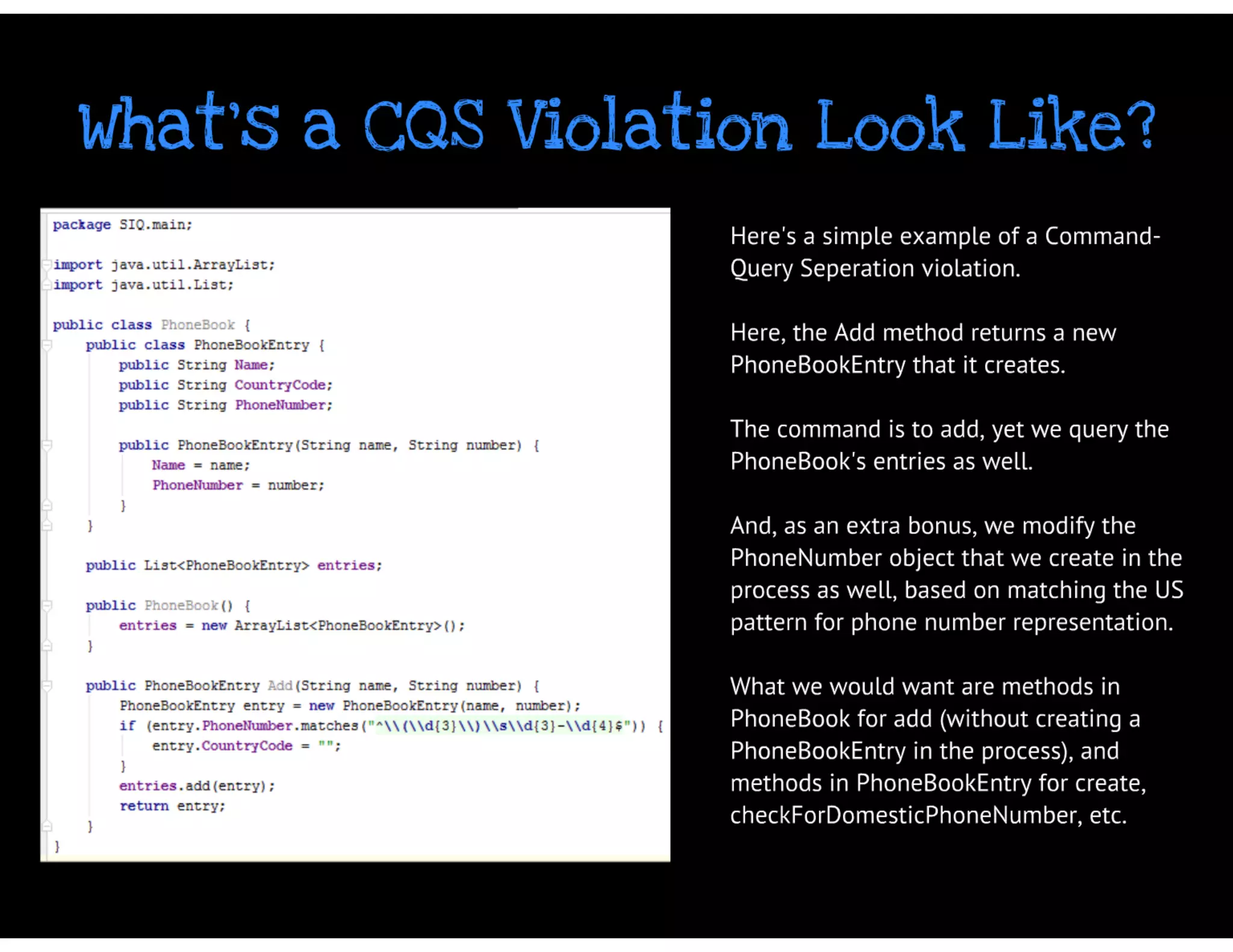


























Back in 1955, Rudolf Flesch wrote his seminal book “Why Johnny Can’t Read”. The book became a flash point about how American education was depriving children of the joys of knowledge by not properly training them in the correct way to learn to read, by phonics, rather than the "whole word” guessing that was popular at the time. The book was a bellwether about the “crisis in education” at the time. Today’s session will not be about education, reading, or whether phonics are desirable or not. But the session today does address a serious problem that just about everyone in the IT industry faces. We suffer because our legacy code is not unit tested. Actually, lack of unit testing in legacy code (which is really a tautology) is just an easily observed symptom of the real issue, which is lack of quality and lack of knowledge in the code that we depend on, day after day. When the code shows a defect, most organisations expect a quick resolution to the problem and hope for the best. The same tack is taken when the code needs to be extended. This technique, called “code and pray”, rarely ends well. Organizations that try to do the right thing will give their development team the additional responsibility to unit test their code. Everyone knows that unit testing will go a long way in addressing the quality issue. The bet is that the time and effort taken to unit test the code will fix the quality problem. And they’re right. There are many studies that show this result. But there is one fatal flaw in these best intentions. Unit testing legacy code is hard. Really hard. And many times, this one fact torpedoes the entire effort that was supposed to make things better. This is the first part of a two part series on Johnny (the other being “Why Johnny STILL Can’t Unit Test His Legacy Code”). In this session, we will look at the technical issues surrounding refactoring legacy code.