Download to read offline










![Applying DRY
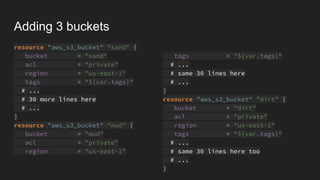
variable "buckets" {
type = "list"
default = ["sand", "mud", "dirt"]
}
resource "aws_s3_bucket" "bucket" {
count = "${length(var.buckets)}"
bucket = "${var.buckets[count.index]}"
acl = "private"
region = "us-east-1"
tags = "${var.tags}"
# ...
# 30 more lines here
# ...
}](https://image.slidesharecdn.com/naticohen-wat-190106092133/85/Wat-tf-Nati-Cohen-DevOpsDays-Tel-Aviv-2018-11-320.jpg)
![Destroying a single (?) bucket
variable "buckets" {
type = "list"
default = ["sand", "mud", "dirt"]
}
resource "aws_s3_bucket" "bucket" {
count = "${length(var.buckets)}"
bucket = "${var.buckets[count.index]}"
acl = "private"
region = "us-east-1"
tags = "${var.tags}"
# ...
# 30 more lines here
# ...
}](https://image.slidesharecdn.com/naticohen-wat-190106092133/85/Wat-tf-Nati-Cohen-DevOpsDays-Tel-Aviv-2018-12-320.jpg)




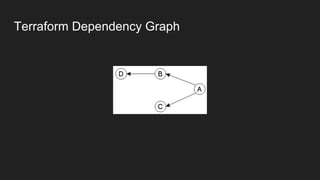













The document discusses the concept of 'infrastructure as code' with a focus on creating and managing AWS S3 buckets using Terraform. It includes code snippets for defining various S3 bucket resources and managing them through a list variable, along with references to self-hosted database modules and user data templates for EC2 instances. The author also expresses the opinion that 'infrastructure as code' is not genuinely code.
![Some Examples in R- [Data Visualization--R graphics]](https://cdn.slidesharecdn.com/ss_thumbnails/rchart-160729210112-thumbnail.jpg?width=640&height=640&fit=bounds)














































