Статья представляет библиотеку анализа кода vivacore, описывая ее возможности, структуру и области применения. Vivacore предназначена для поддержки работы с языками Си и Си++, предлагая функциональность для рефакторинга, статического и динамического анализа кода. Библиотека отличается от своей предшествующей версии openc++, включая современные улучшения и поддержку новых стандартов языка.
![Сущность библиотеки анализа кода
VivaCore
Авторы: Андрей Карпов, Евгений Рыжков
Дата: 09.01.2008
Аннотация
Статья знакомит разработчиков с библиотекой VivaCore, предпосылками ее создания,
возможностями, структурой и областями применения. Данная статья была написана параллельно
с разработкой библиотеки VivaCore, и поэтому отдельные детали ее конечной реализации могут
отличаться от описанных здесь свойств. Но это не помешает разработчикам познакомиться с
общими принципами работы библиотеки, механизмами анализа и обработки текстов программ
на языке Си и Си++.
Введение
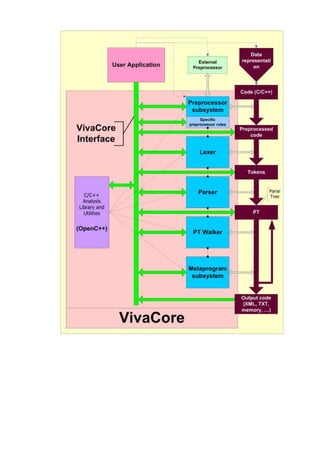
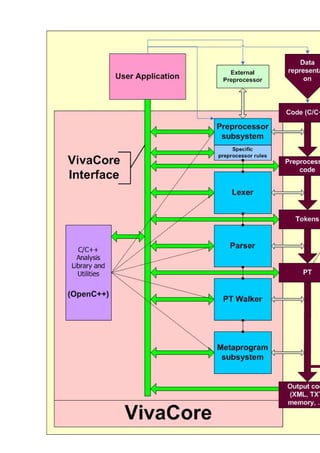
VivaCore - это открытая библиотека для работы с Си и Си++ кодом. Библиотека предназначена для
реализации на ее основе систем рефакторинга кода, систем статического и динамического
анализа, систем трансформации или оптимизации кода, расширений языка, подсистем подсветки
синтаксиса, систем построения документации по коду и других аналогичных инструментов.
Идея разработки библиотеки возникла в процессе создания нашей командой статического
анализатора кода Viva64 [1]. Инструмент Viva64 предназначен для диагностирования ошибок в
программах на Си/Си++, связанных с особенностями переноса кода под 64-битные Windows-
системы.
В процессе разработки Viva64 наша команда столкнулась с отсутствием открытых библиотек,
удобных для реализации подобных проектов. В качестве основы была выбрана библиотека
OpenC++ [2], и в целом мы остались довольны своим выбором. Но в ходе разработки статического
анализатора наша команда внесла довольно большое количество исправлений и
усовершенствований в библиотеку OpenC++. И теперь, когда разработка первых версий продукта
Viva64 закончена, мы хотим предложить сторонним разработчикам наш переработанный вариант
библиотеки OpenC++, которую мы назвали VivaCore. Мы считаем, что внесенные нами изменения
могут существенно облегчить жизнь разработчикам, собирающимся приступить к разработке
продуктов в области анализа или обработки Си/Си++ кода.
Лицензия на библиотеку VivaCore позволяет свободно использовать, копировать, распространять
и модифицировать ее в бинарном виде или в виде исходного кода, как для коммерческого, так и
для некоммерческого использования без каких-либо отчислений авторам библиотеки.
Необходимо лишь указать авторов исходных библиотек (OpenC++ и VivaCore).
Вы можете скачать библиотеку VivaCore по адресу - http://www.viva64.com/vivacore-download.php.](https://image.slidesharecdn.com/essencevivacorelibraryru-110712053736-phpapp02/85/VivaCore-1-320.jpg)


![16. форматирование кода (Ochre SourceStyler).
Более подробно о применении технологии разбора кода можно узнать из фундаментальной книги
по компиляторам [3]. Также рекомендуем ознакомиться с принципами анализа программ [4].
Не следует путать VivaCore с профессиональными многофункциональными парсерами Си/Си++
кода. Если пользователю нужен front-end парсер кода, полностью поддерживающий
современный стандарт языка Си++ и позволяющий создавать свой компилятор под
специфическую платформу, то ему стоит обратить свое внимание на GCC или дорогие
коммерческие решения. Например, такие решения предоставляет Semantic Designs [5].
Но если компания разрабатывает инструмент, требующий классического анализа Си/Си++ кода, то
рациональным решением будет являться использование удобной и открытой библиотеки кода,
которой и является VivaCore.
Основные термины
Прежде чем перейти к более подробному рассмотрению библиотеки VivaCore напомним
некоторые термины, которые будут использоваться в процессе описания.
Препроцессирование - механизм, просматривающий входной ".c/.cpp" файл, исполняющий в нём
директивы препроцессора, включающий в него содержимое других файлов, указанных в
директивах #include и прочее. В результате получается файл, который не содержит директив
препроцессора, все используемые макросы раскрыты, вместо директив #include подставлено
содержимое соответствующих файлов. Файл с результатом препроцессирования обычно имеет
суффикс ".i". Результат препроцессирования называется единицей трансляции.
Синтаксический анализ (парсинг) - это процесс анализа входной последовательности символов, с
целью разбора грамматической структуры. Обычно синтаксический анализ делится на два уровня:
лексический анализ и грамматический анализ.
Лексический анализ - процесс обработки входной последовательности символов с целью
получения на выходе последовательности символов, называемых лексемами (или "токенами").
Каждую лексему условно можно представить в виде структуры, содержащей тип лексемы и, если
нужно, соответствующее значение.
Грамматический анализ (грамматический разбор) - это процесс сопоставления линейной
последовательности лексем (слов, лексем) языка с его формальной грамматикой. Результатом
обычно является дерево разбора или абстрактное синтаксическое дерево.
Абстрактное синтаксическое дерево (Abstract Syntax Tree - AST) — конечное, помеченное,
ориентированное дерево, в котором внутренние вершины сопоставлены с операторами языка
программирования, а листья с соответствующими операндами. Таким образом, листья являются
пустыми операторами и представляют только переменные и константы. Абстрактное
синтаксическое дерево отличается от дерева разбора (derivation tree - DT, parse tree - PT) тем, что в
нём отсутствуют узлы для тех синтаксических правил, которые не влияют на семантику
программы. Классическим примером такого отсутствия являются группирующие скобки, так как в
AST группировка операндов явно задаётся структурой дерева.](https://image.slidesharecdn.com/essencevivacorelibraryru-110712053736-phpapp02/85/VivaCore-4-320.jpg)





![Лексический анализатор VivaCore разбирает текст программы на набор объектов типа Token (см.
файл Token.h), которые содержат информацию о типе лексемы, ее местонахождении в тексте
программы и длину. Типы лексем перечислены в файле tokennames.h. Примеры типов лексем:
CLASS - ключевое слово языка "class"
WCHAR - ключевое слово языка "wchar_t"
В случае необходимости пользователь может расширить набор лексем. Это может быть
востребовано в случае поддержки специфического синтаксиса конкретной реализации языка или
при разработке своего языкового расширения.
При добавлении лексем необходимо объявить их в файле tokennames.h и добавить в таблицы
"table" или "tableC" в файле Lex.cc. Первая таблица предназначена для обработки Си++ файлов, а
вторая - для Си файлов. Это естественно, так как набор лексем в языке Си и Си++ различен.
Например, в языке Си отсутствует лексема CLASS, так как в Си слово "class" не является ключевым
и может обозначать имя переменной.
При добавлении новых лексем следует проявить аккуратность и не забыть скорректировать
функции isTypeSpecifier, optIntegralTypeOrClassSpec и так далее. Чтобы не пропустить важное
место, лучше всего взять близкое по значению ключевое слово и найти все места, где в VivaCore
используется соответствующая лексема.
Получить набор лексем можно как в виде простого массива, так и выгрузив их в файл. Лексемы
хранятся в массиве tokens_ в классе Lex. Возможно получить как массив целиком, так и перебрать
лексемы по отдельности, используя функции GetToken, LookAhead, CanLookAhead.
Пользователь может получить лексемы в виде неструктурированного текста или используя
функцию DumpEx в следующем отформатированном виде:
258 LC_ID 5
258 lc_id 5
91 [ 1
262 6 1
93 ] 1
59 ; 1
303 struct 6
123 { 1
282 char 4
42 * 1
258 locale 6
Пользователь также может экспортировать лексемы в формате XML файла.
См. в коде: Token, Lex, TokenContainer.
4) Грамматический анализатор (Parser)
Грамматический анализатор предназначен для построения дерева разбора (derivation tree - DT),
которое в дальнейшем может быть подвергнуто анализу и трансформации. Обратите внимание,
что грамматический анализатор библиотеки VivaCore строит не абстрактное синтаксическое
дерево (АST), а именно дерево разбора. Это позволяет более просто осуществить поддержку
метапрограммных конструкций, которые могут быть добавлены пользователем в язык Си или](https://image.slidesharecdn.com/essencevivacorelibraryru-110712053736-phpapp02/85/VivaCore-12-320.jpg)




![модифицировать ее. Например, используя такие функции как IsFunction, IsPointerType,
IsBuiltInType можно легко идентифицировать тип обрабатываемого элемента.
Описание подходов к добавлению новых типов узлов или листьев является нетривиальной
задачей и не может быть изложено в этой обзорной статье. Рациональным решением будет
выбор одного из классов, например PtreeExprStatement и просмотр всех мест в коде, где
происходит создание объектов данного класса, работа с ними и так далее.
Полученное по завершению дерево разбора может быть сохранено в формате ".с/.cpp" файла,
что, впрочем, имеет мало смысла. Эта возможность обретет смысл после изменения дерева
разбора, которое может произойти на следующих этапах. Сохранив дерево сейчас в виде кода
программы, мы получим ровно то, что получили на входе. Впрочем, это может быть вполне
полезно для тестирования изменений, внесенных в лексер и парсер.
Больший интерес представляет возможность сохранить дерево для дальнейшей обработки в
произвольном формате, реализованном пользователем. Примером может служить следующее
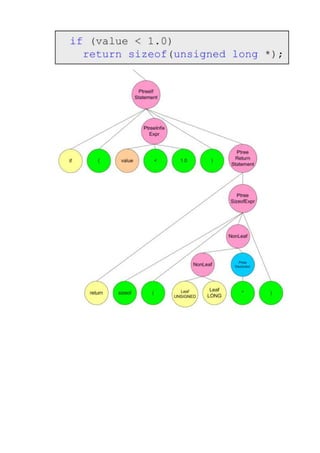
текстовое представление кода, который был приведен ранее:
PtreeDeclaration:[
0
NonLeaf:[
LeafINT:int
]
PtreeDeclarator:[
Leaf:MyFoo
Leaf:(
NonLeaf:[
NonLeaf:[
NonLeaf:[
LeafCONST:const
NonLeaf:[
LeafFLOAT:float
]
]
PtreeDeclarator:[
Leaf:value
]](https://image.slidesharecdn.com/essencevivacorelibraryru-110712053736-phpapp02/85/VivaCore-20-320.jpg)
![]
]
Leaf:)
]
[{
NonLeaf:[
PtreeIfStatement:[
LeafReserved:if
Leaf:(
PtreeInfixExpr:[
LeafName:value
Leaf:<
Leaf:1.0
]
Leaf:)
PtreeReturnStatement:[
LeafReserved:return
PtreeSizeofExpr:[
Leaf:sizeof
Leaf:(
NonLeaf:[
NonLeaf:[
LeafUNSIGNED:unsigned
LeafLONG:long
]
PtreeDeclarator:[
Leaf:*
]
]
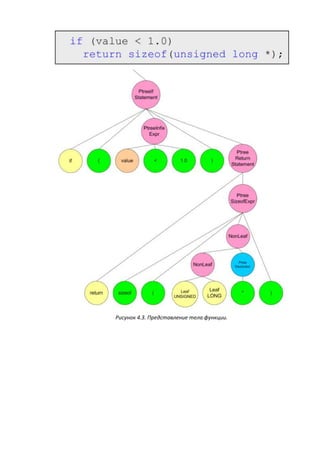
Leaf:)](https://image.slidesharecdn.com/essencevivacorelibraryru-110712053736-phpapp02/85/VivaCore-21-320.jpg)
![]
Leaf:;
]
]
PtreeReturnStatement:[
LeafReserved:return
PtreeCondExpr:[
PtreeInfixExpr:[
PtreeInfixExpr:[
LeafName:value
Leaf:*
Leaf:4.0f
]
Leaf:<
Leaf:10.0f
]
Leaf:?
Leaf:0
Leaf::
Leaf:1
]
Leaf:;
]
]
Leaf:}
}]
]
Данный формат показан просто для примера. На практике, скорее всего, потребуется сохранять
больше информации и в более удобном для обработки формате - например, в формате XML.
См. в коде: Parser, Ptree, Leaf, NonLeaf, Encoding, TypeInfo, Typeof, PtreeUtil.](https://image.slidesharecdn.com/essencevivacorelibraryru-110712053736-phpapp02/85/VivaCore-22-320.jpg)
![5) Обход дерева разбора
Для разработчиков статических анализаторов кода (подробное введение в задачу - книга [6]) или
систем построения документации по коду наибольший интерес должен представлять этап обхода
дерева разбора, осуществляемый с использованием классов Walker, ClassWalker, ClassBodyWalker.
Обход дерева разбора можно осуществлять несколько раз, что позволяет создавать системы,
модифицирующие код за несколько проходов, или проводить анализ, учитывающий уже
накопленные знания при предыдущих обходах дерева.
Класс Walker служит для обхода базовых конструкций языка Си/Си++.
Класс ClassWalker наследуется от класса Walker и добавляет функциональность, связанную со
спецификой классов, присутствующих в языке Си++.
Когда необходимо разобрать тело класса, то временно создаются и используются объекты класса
ClassBodyWalker.
Если не вносить никаких изменений в библиотеку VivaCore, то будет происходить простой проход
по всем элементам дерева. При этом само дерево не будет изменяться.
Если пользователь реализует функциональность, которая будет модифицировать вершины
дерева, библиотека может перестроить дерево. Для примера рассмотрим код, транслирующий
унарные операции:
Ptree* ClassWalker::TranslateUnary(Ptree* exp)
{
using namespace PtreeUtil;
Ptree* unaryop = exp->Car();
Ptree* right = PtreeUtil::Second(exp);
Ptree* right2 = Translate(right);
if(right == right2)
return exp;
else
return
new (GC_QuickAlloc)
PtreeUnaryExpr(unaryop, PtreeUtil::List(right2));
}
Обратите внимание, что если, транслируя выражение, стоящее справа от унарной операции,
полученное дерево будет изменено, то будет изменен (пересоздан) и узел унарной операции. Что
в свою очередь может повлечь перестройку и вышестоящих узлов.
Для наглядности рассмотрим этот пример более подробно.](https://image.slidesharecdn.com/essencevivacorelibraryru-110712053736-phpapp02/85/VivaCore-23-320.jpg)




































































