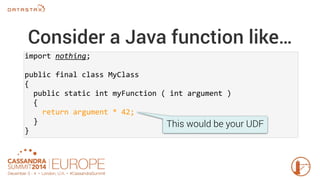
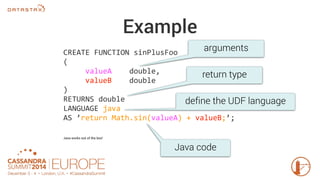
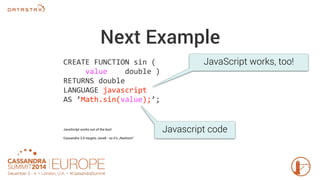
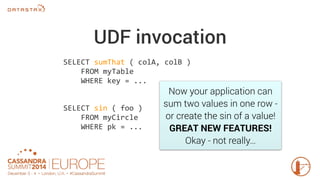
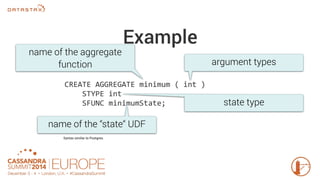
Apache Cassandra 3.0 introduces user-defined functions (UDFs) allowing users to execute custom code on Cassandra nodes, enhancing functionality without requiring new releases. UDFs can be written in Java and JavaScript, with capabilities to create user-defined aggregates for complex calculations across multiple rows. Permissions for UDF creation and execution are implemented to maintain security, emphasizing the importance of testing and performance optimization.










































![Multithreading and Parallelism on iOS [MobOS 2013]](https://cdn.slidesharecdn.com/ss_thumbnails/mobos2013-131122085438-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




















































