Download to read offline















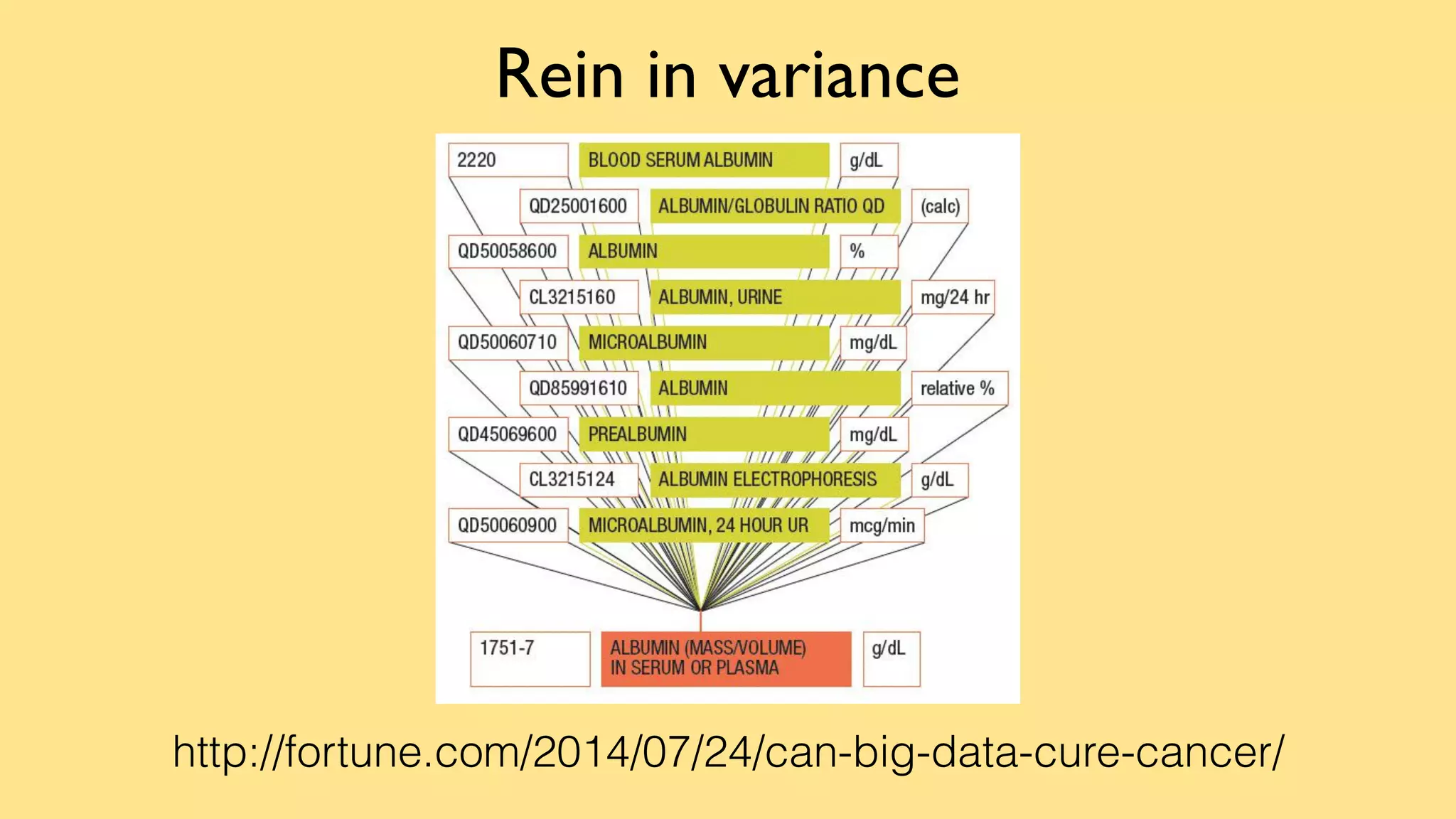



















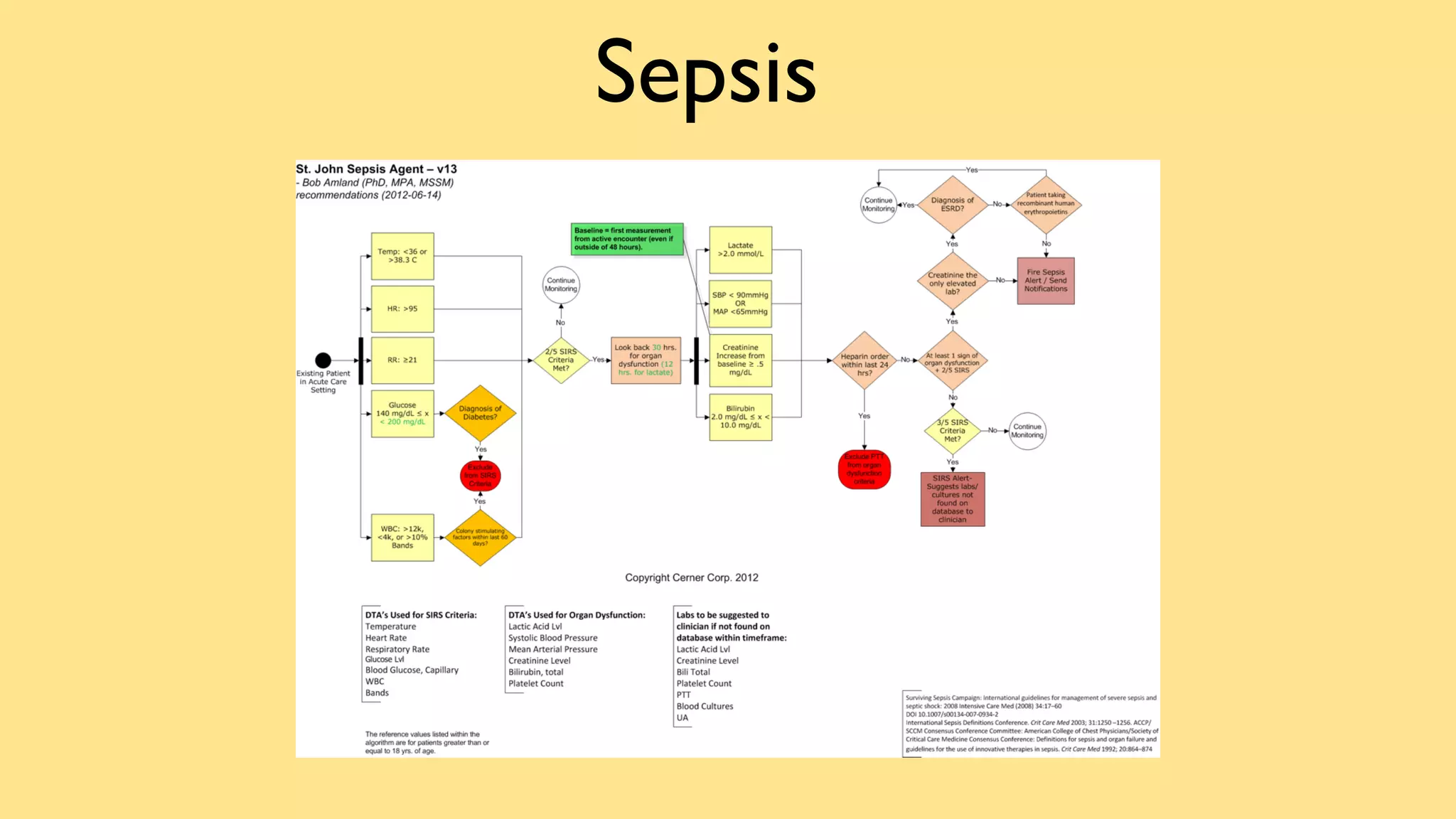







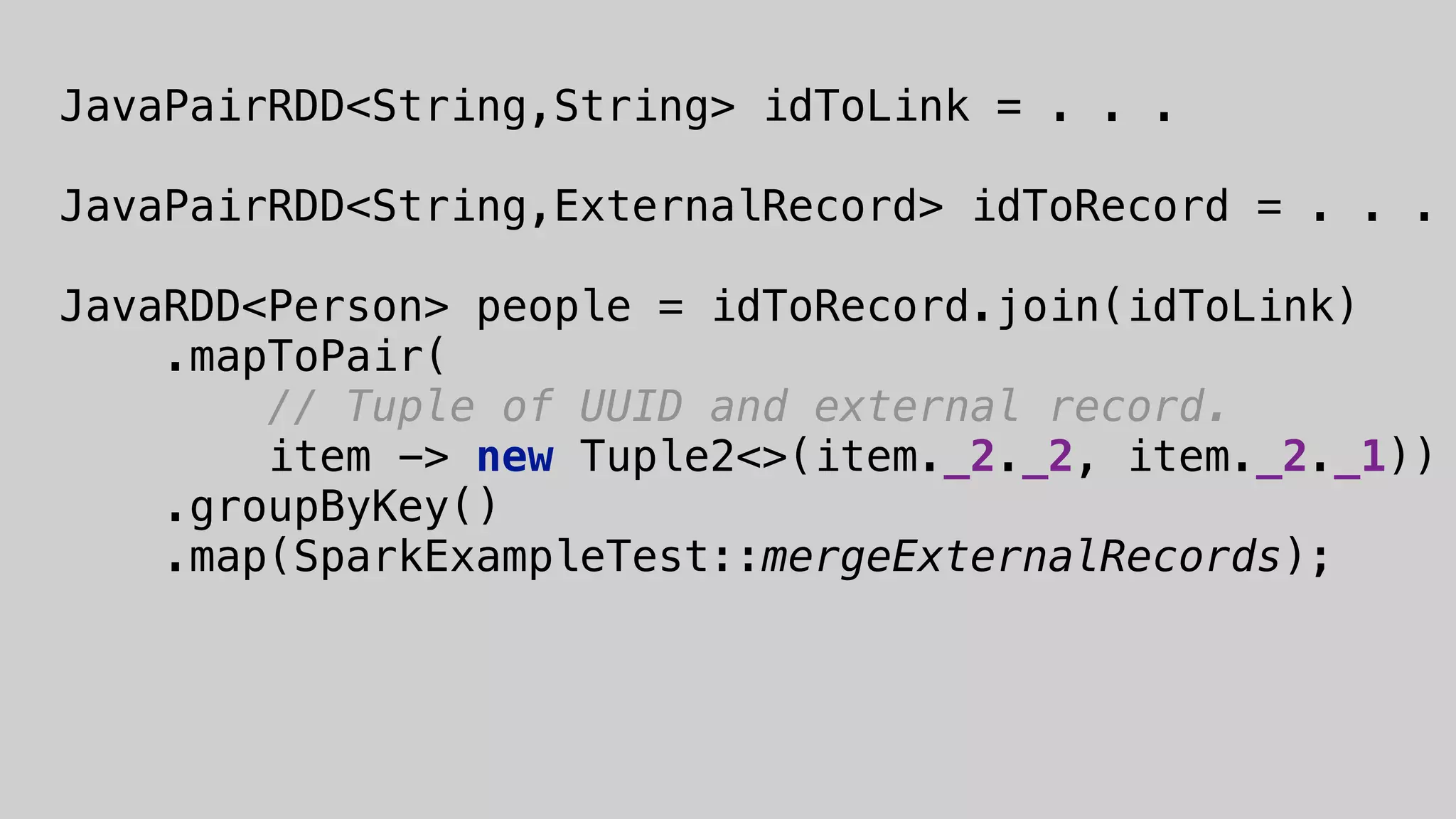
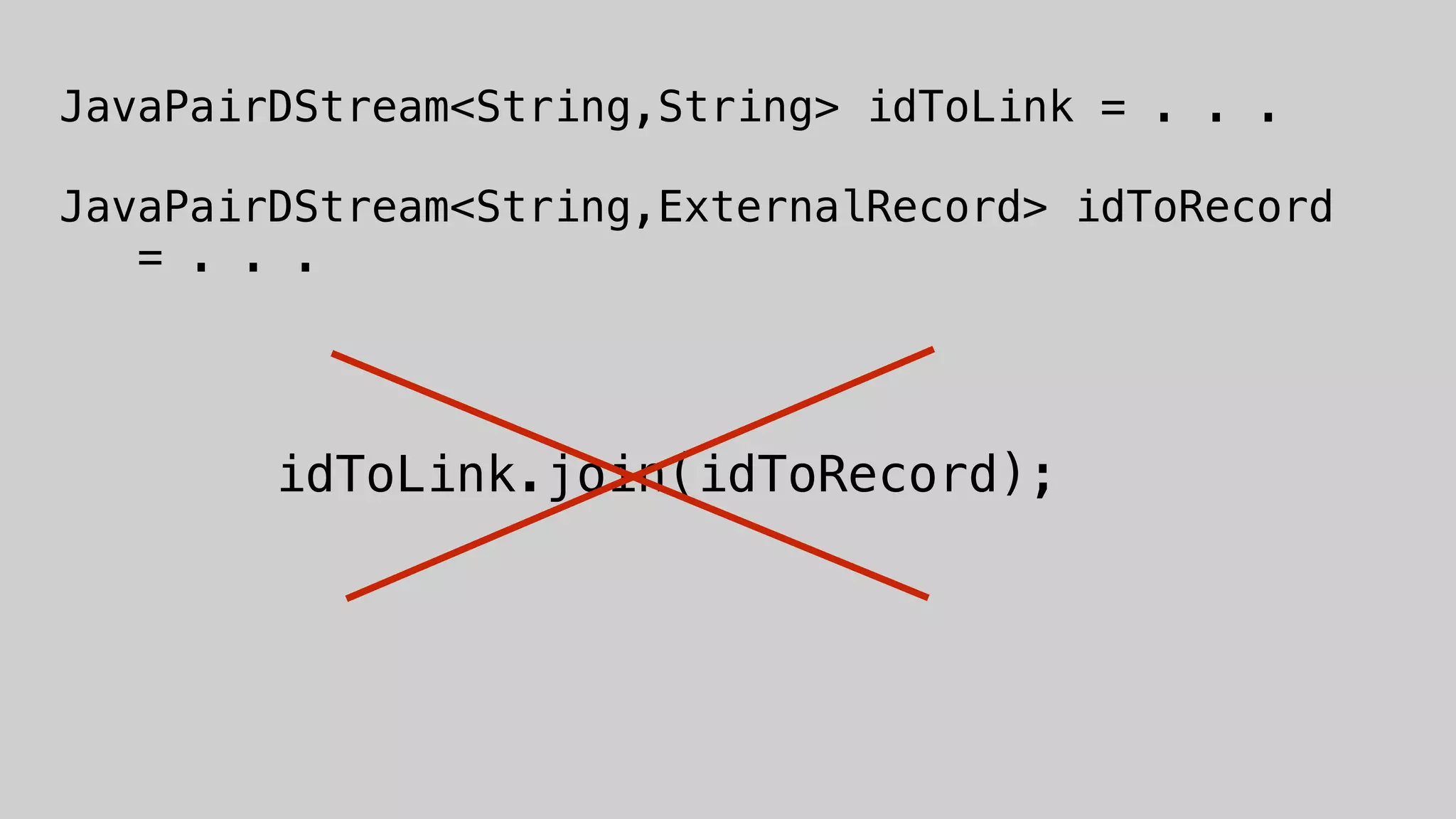

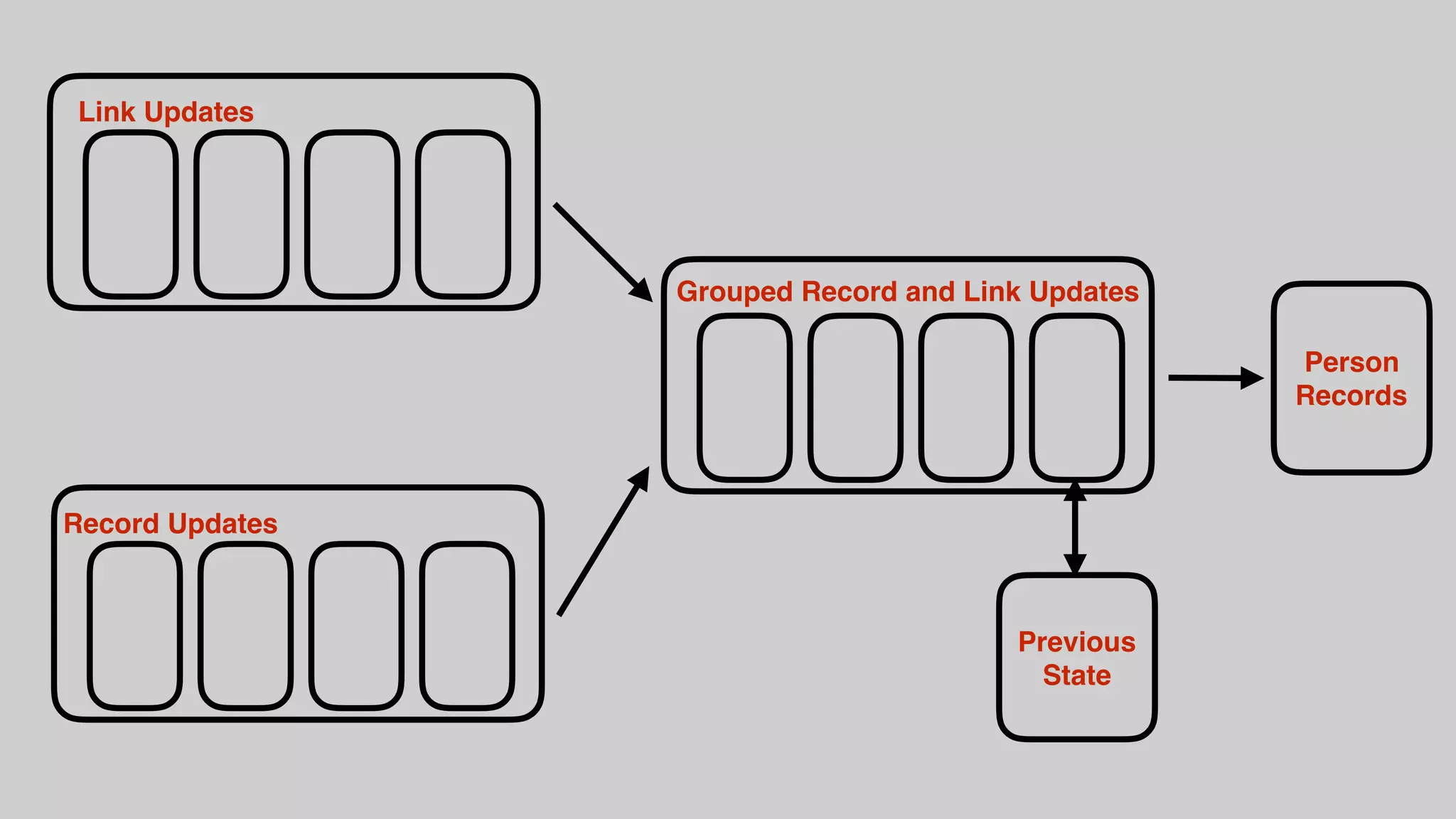
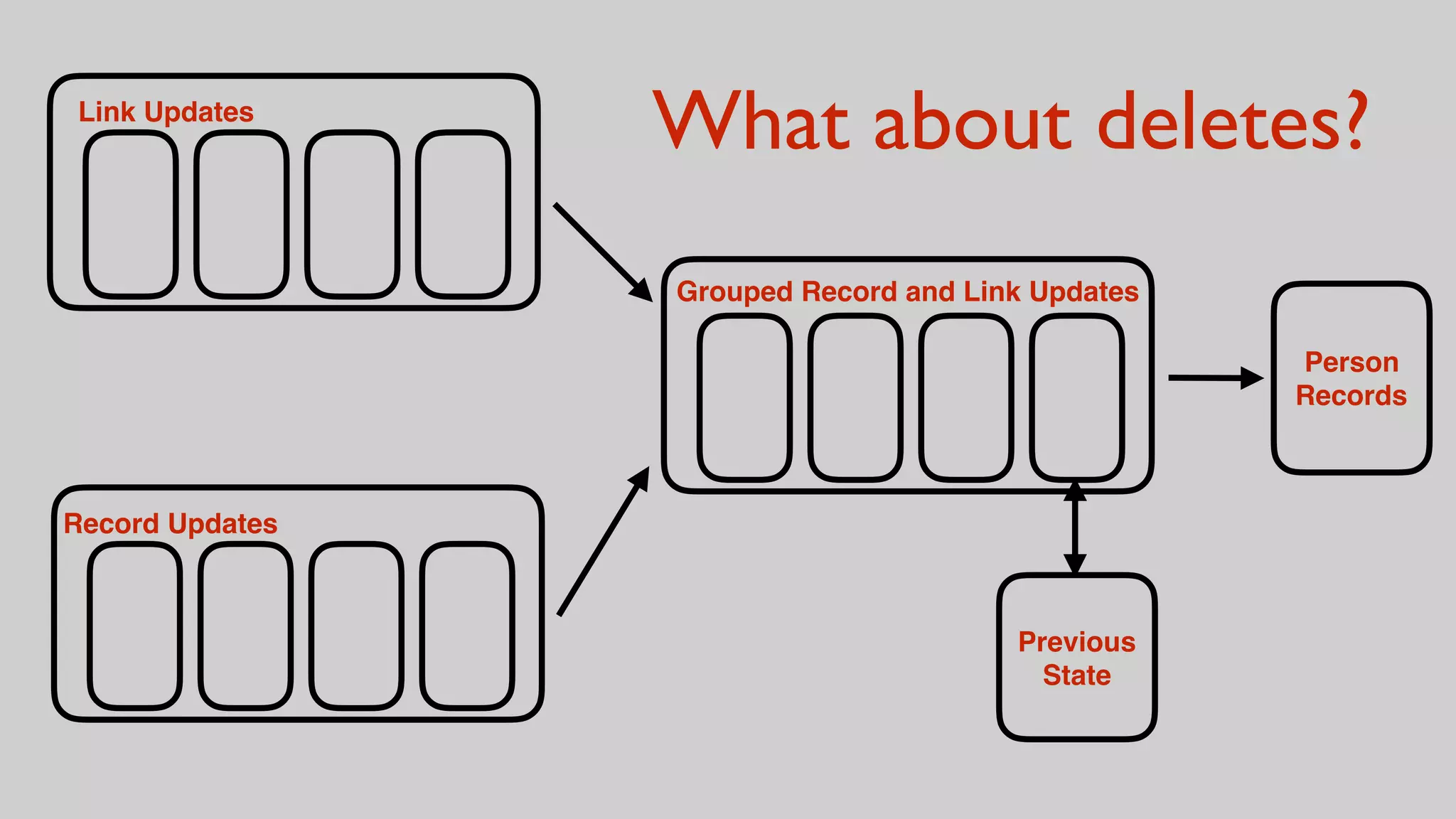

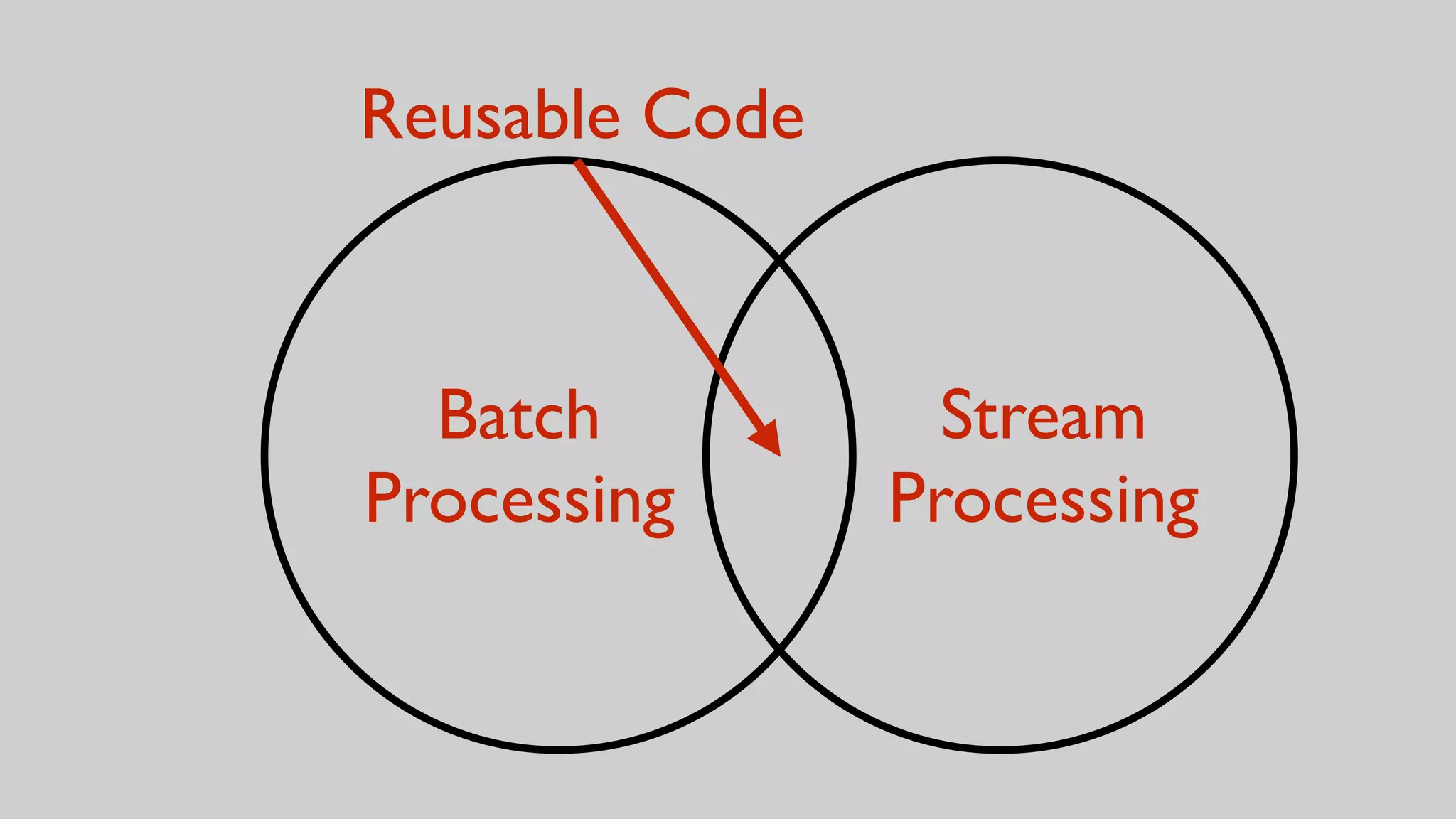






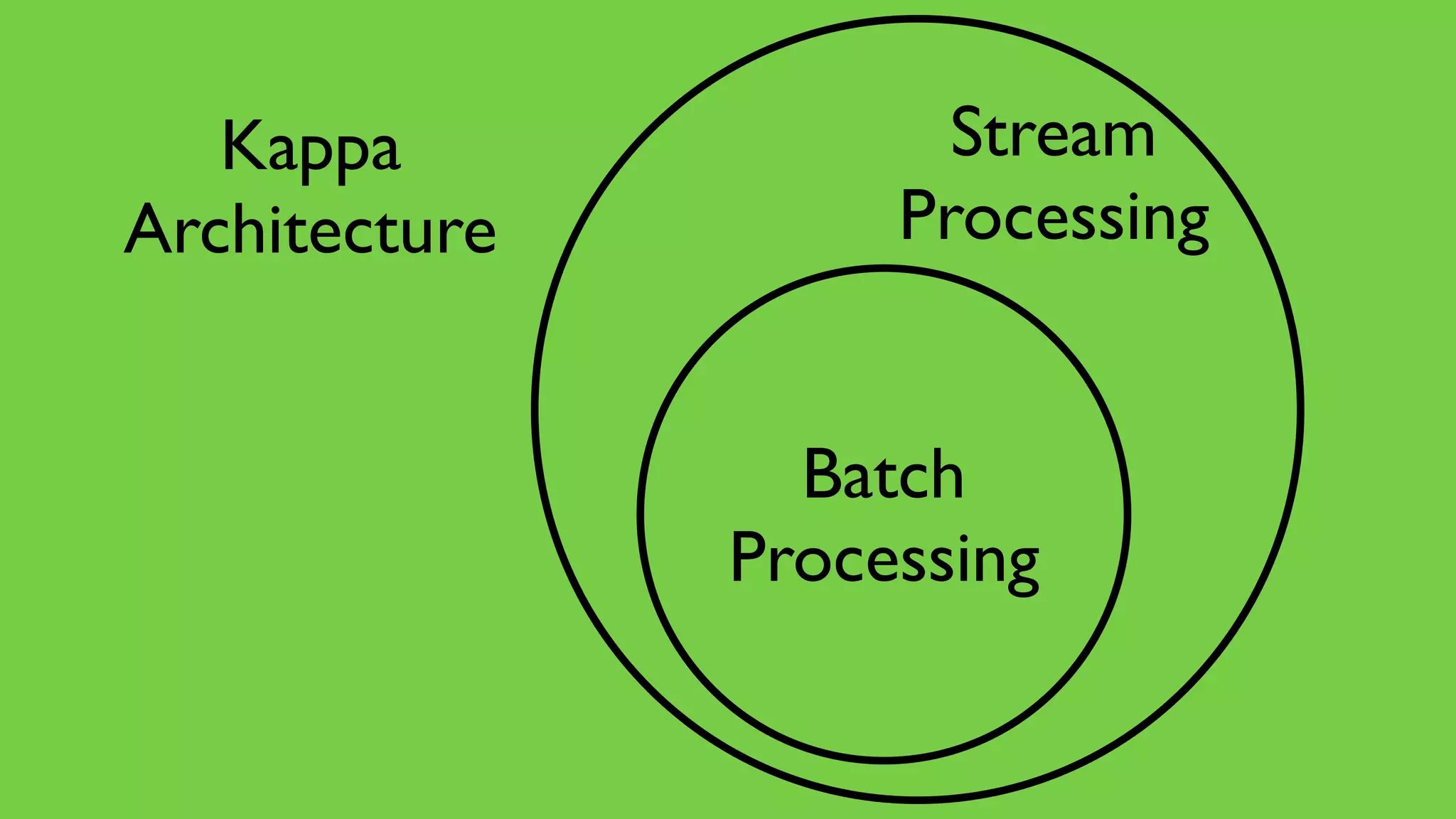
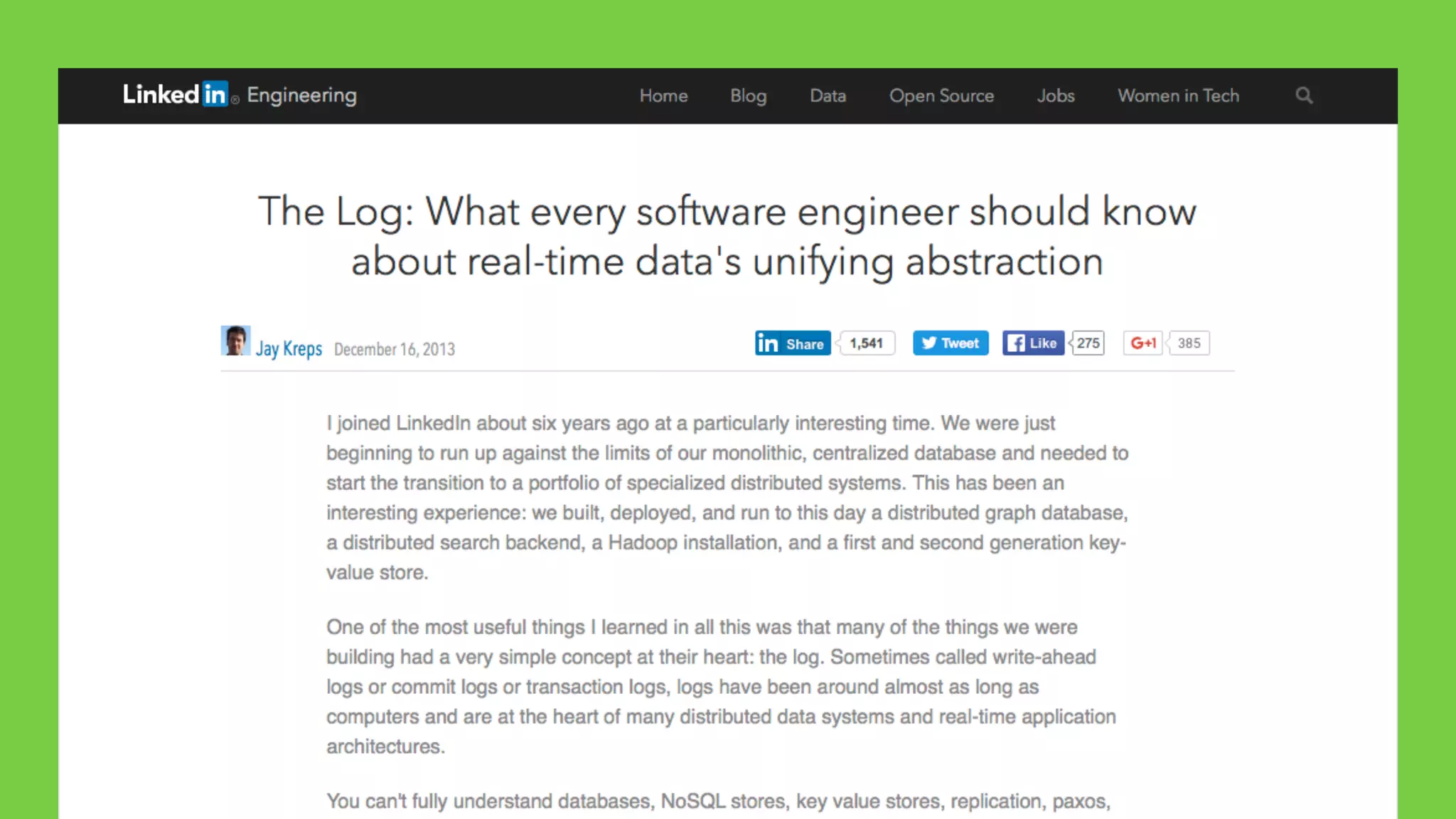










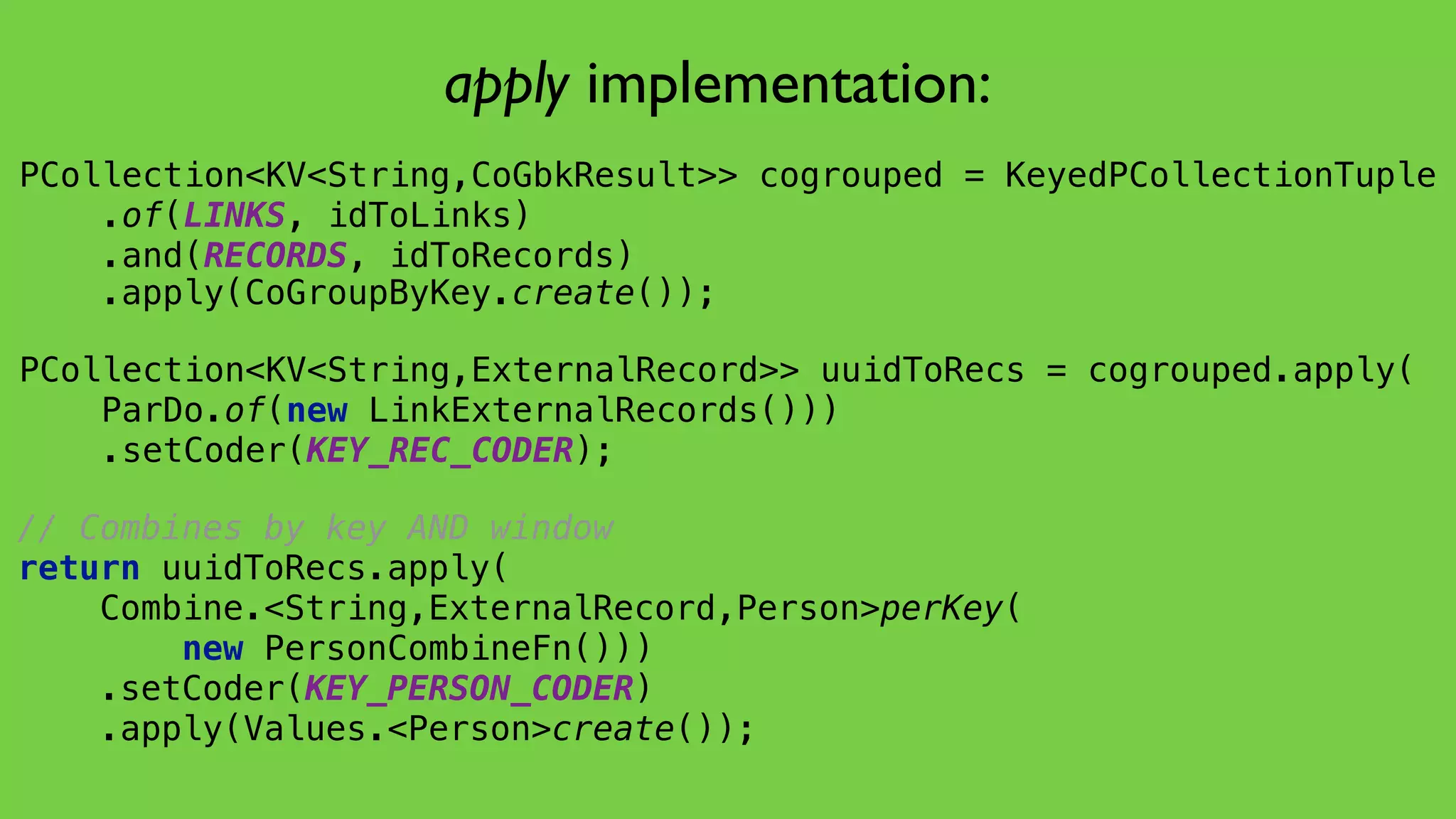


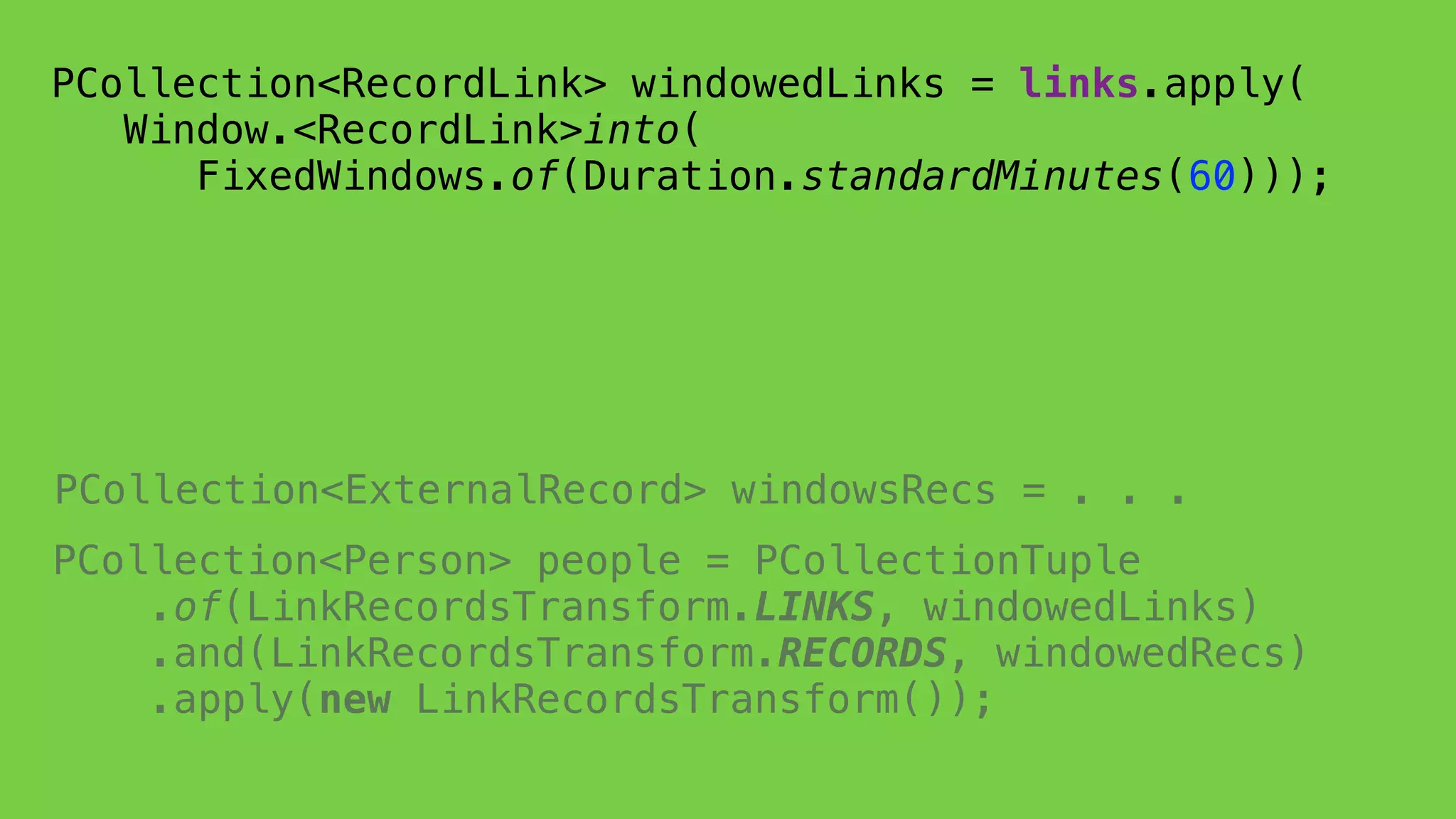

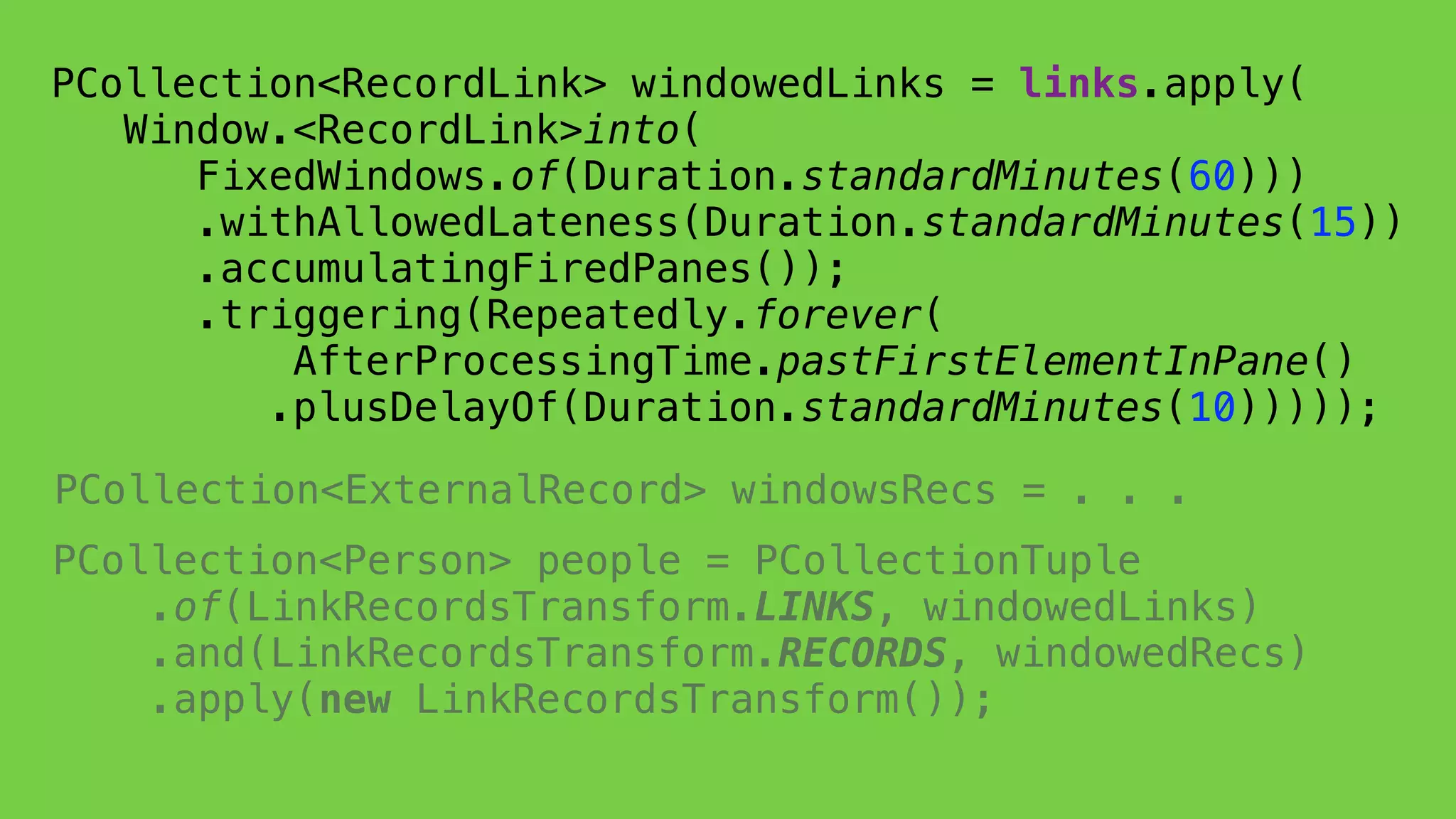












This document discusses the complexities of healthcare data integration, highlighting challenges such as inconsistent coding standards and incomplete datasets. It emphasizes the necessity of using data processing frameworks to normalize and link records for better healthcare analytics. The discussion also includes strategies for streamlining data management and processing, suggesting a unified approach to handle both batch and stream data effectively.















































