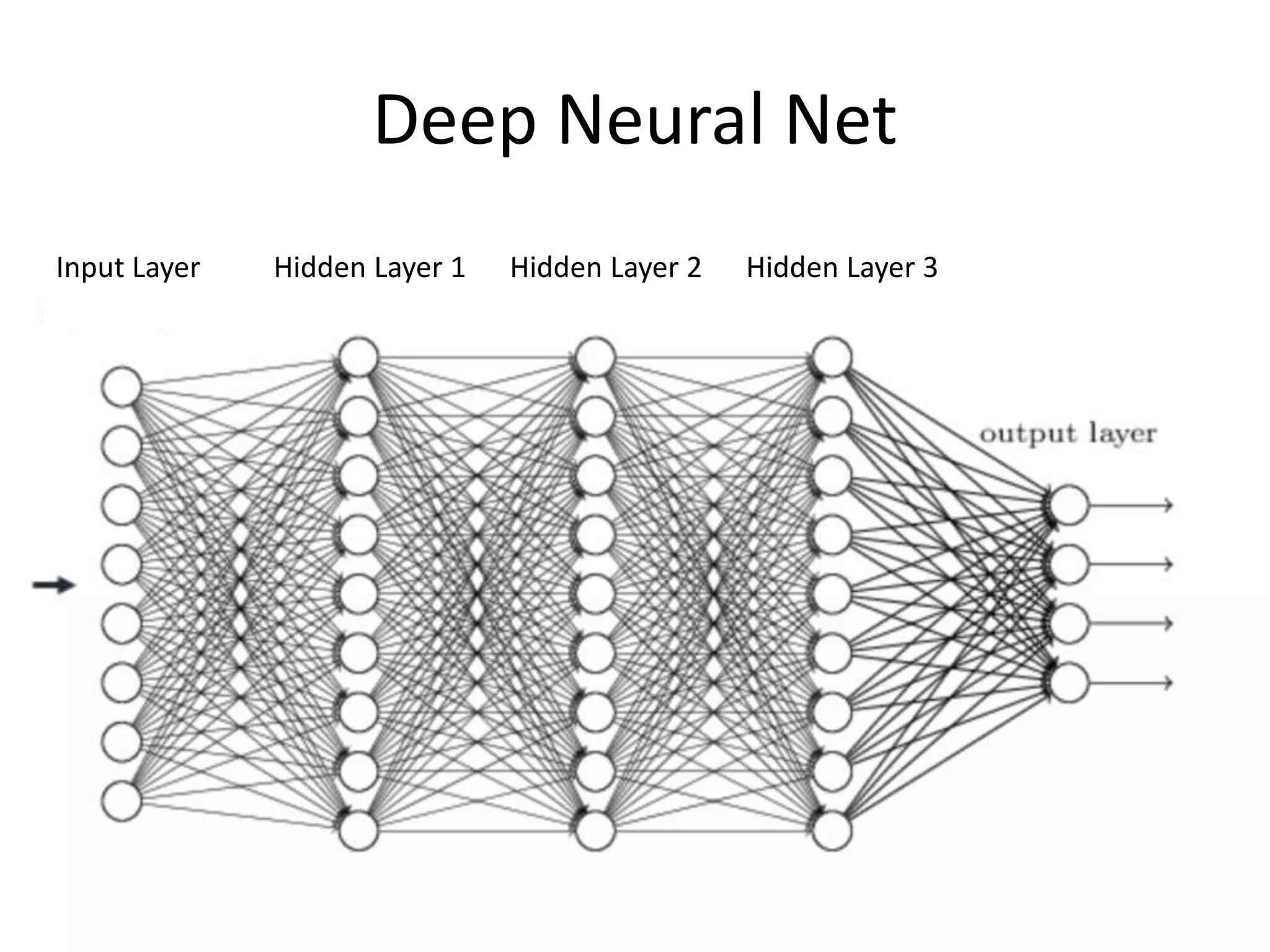
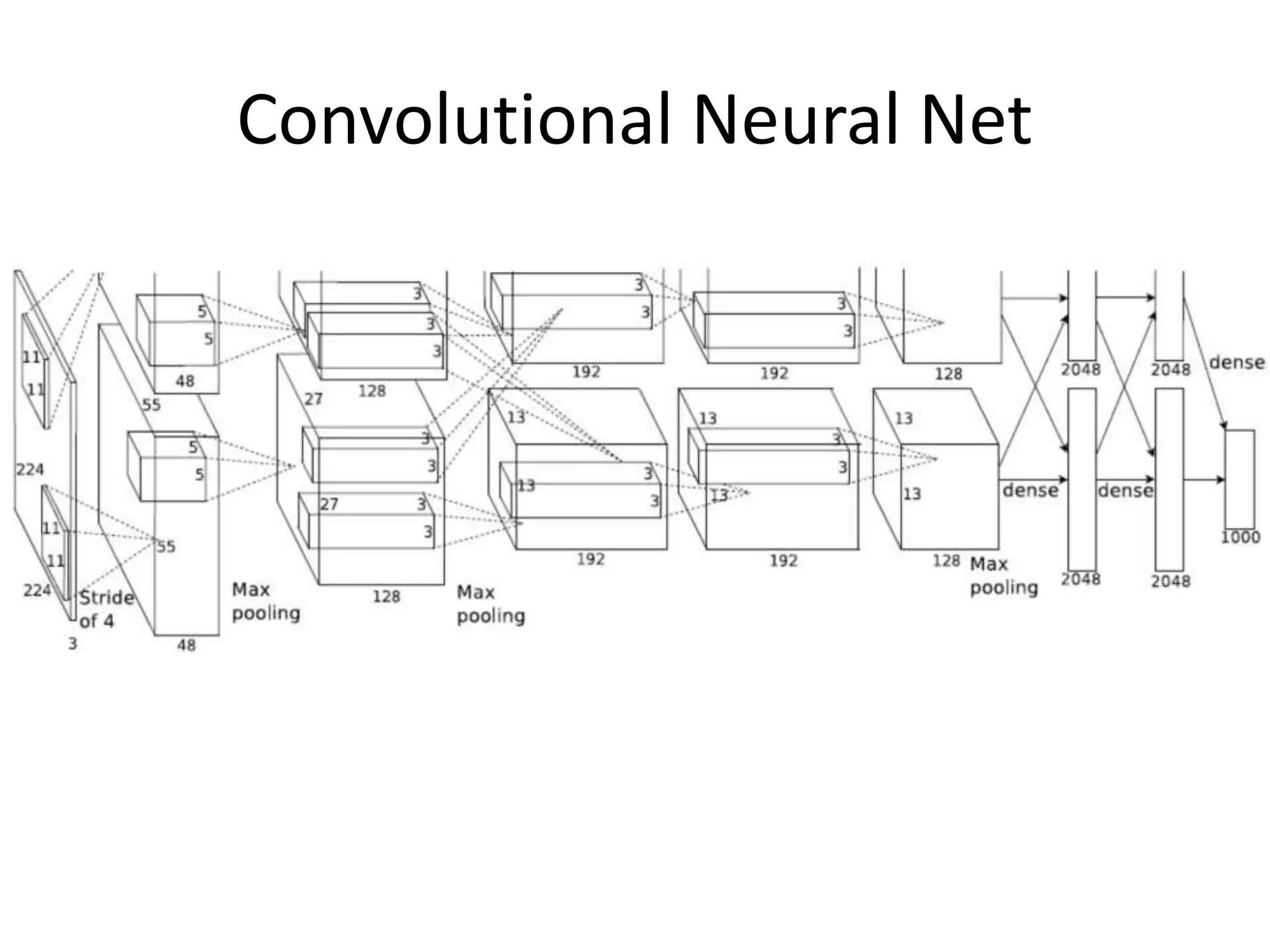
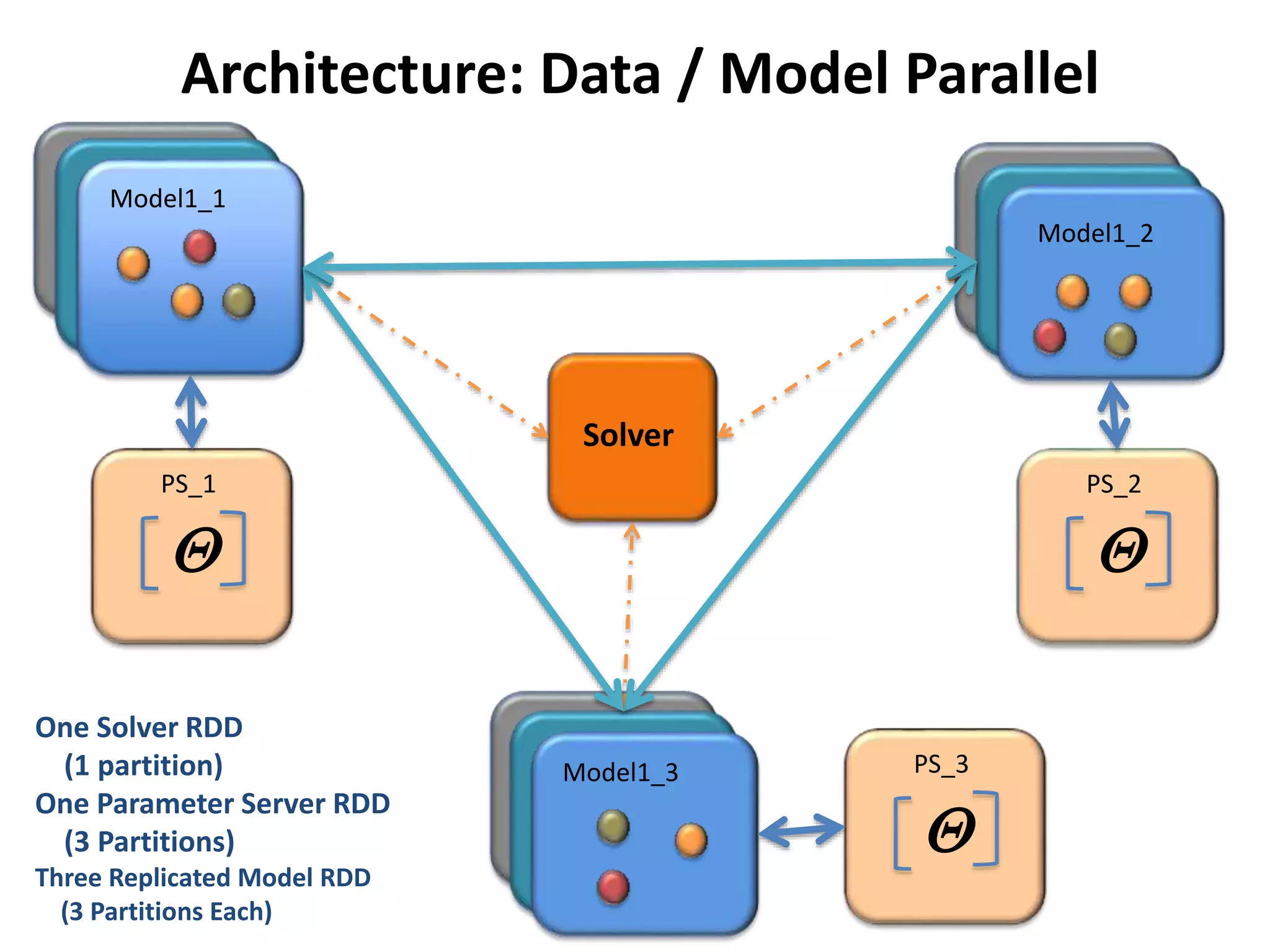
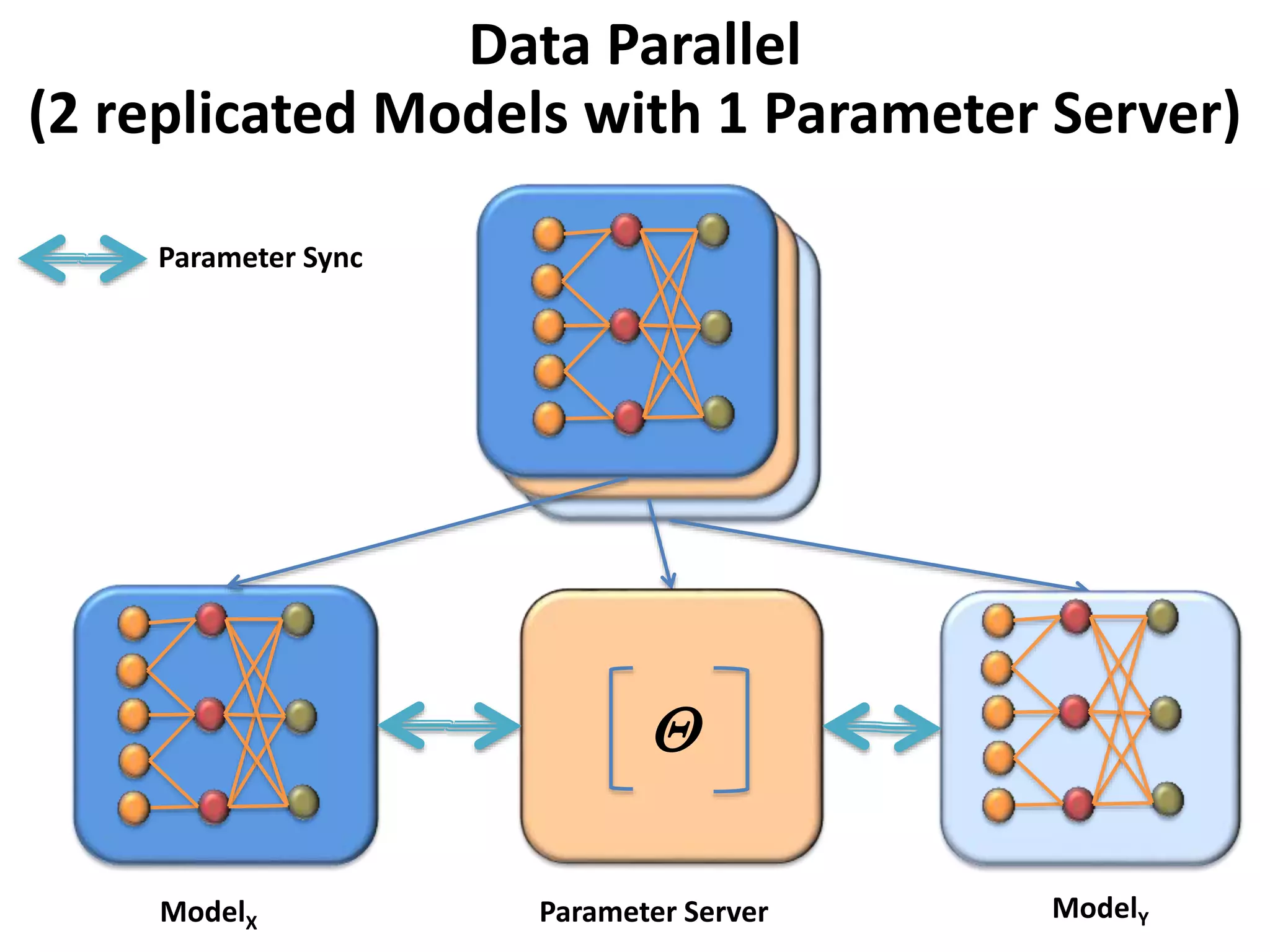
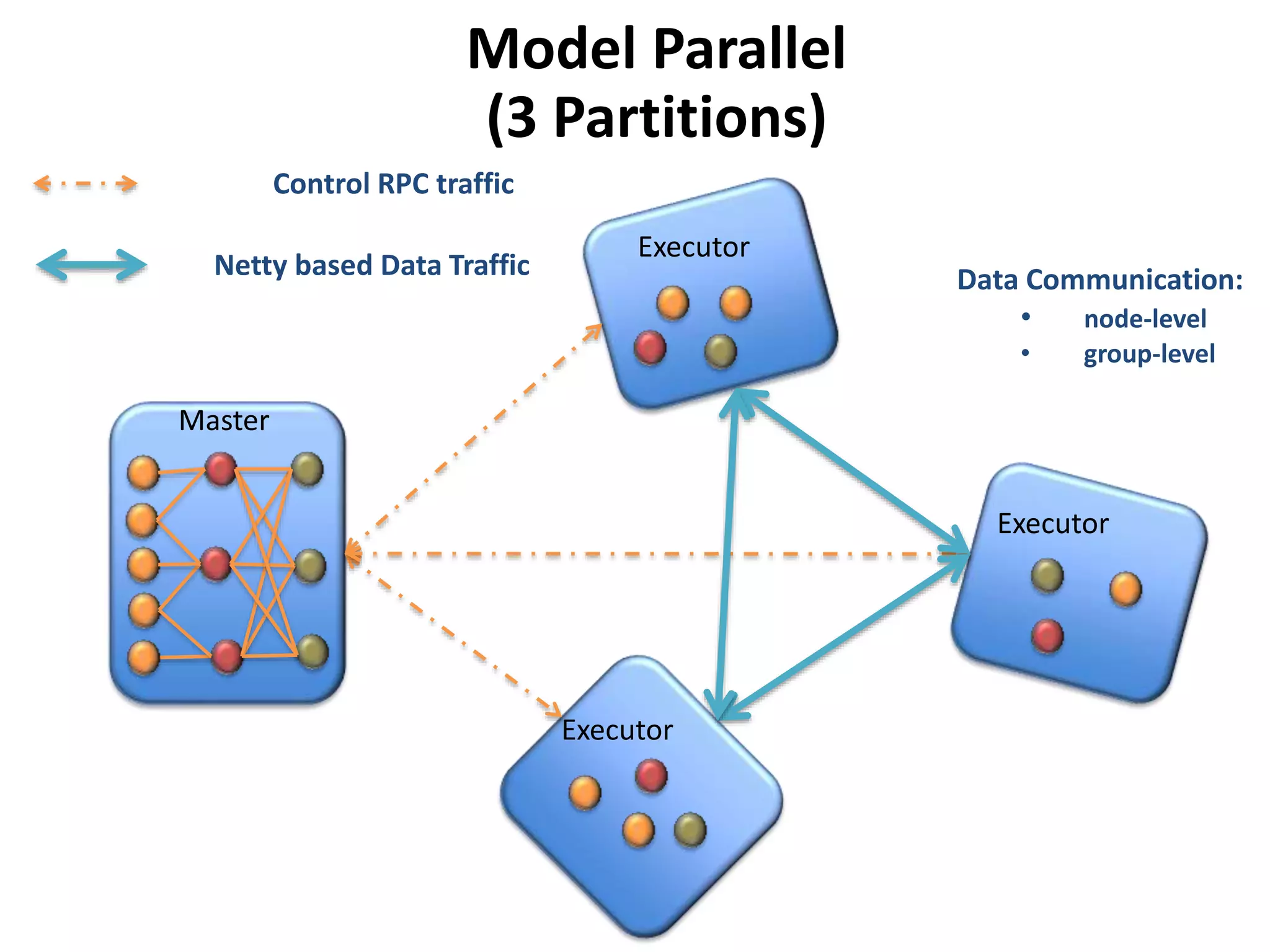
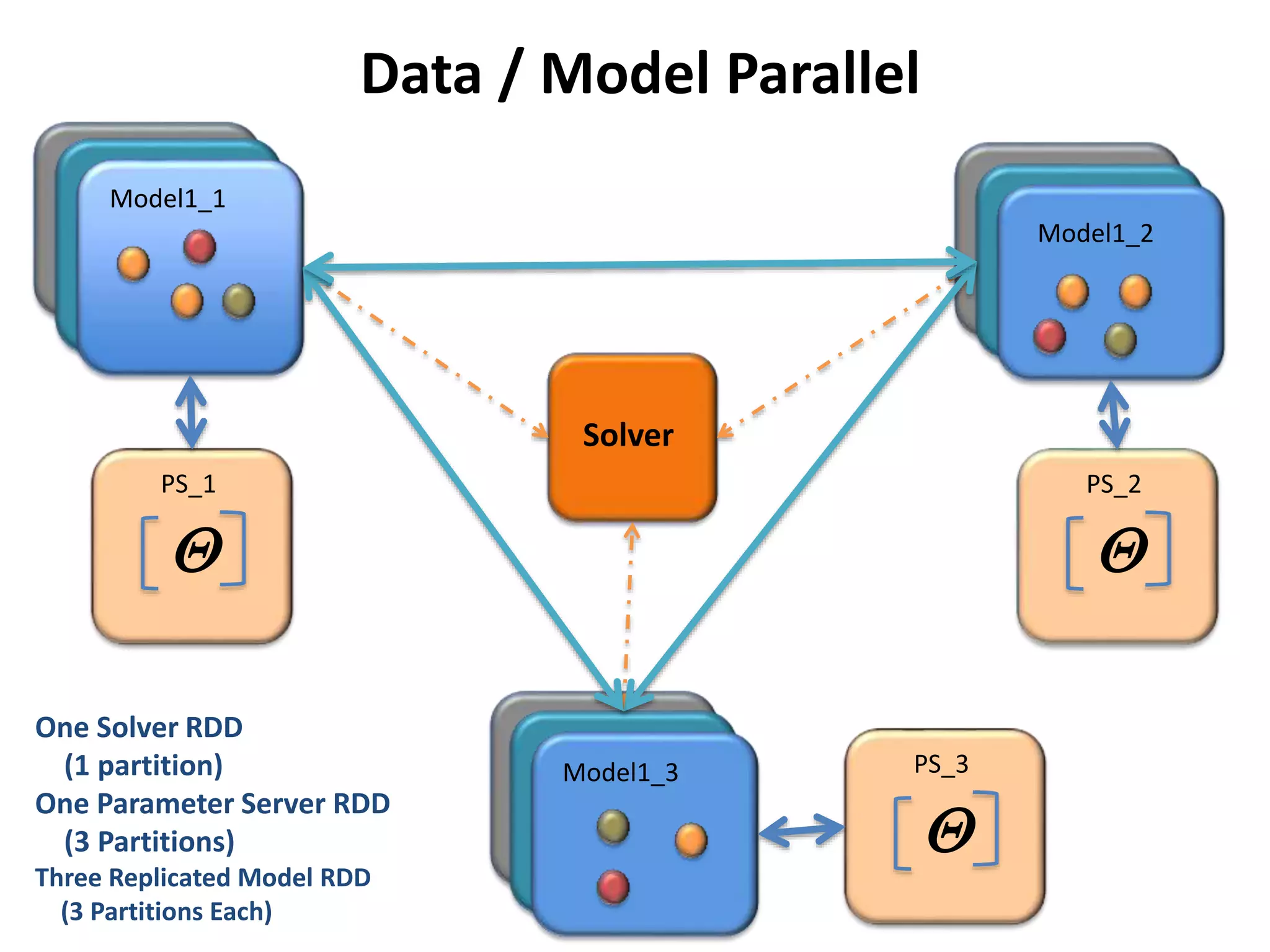
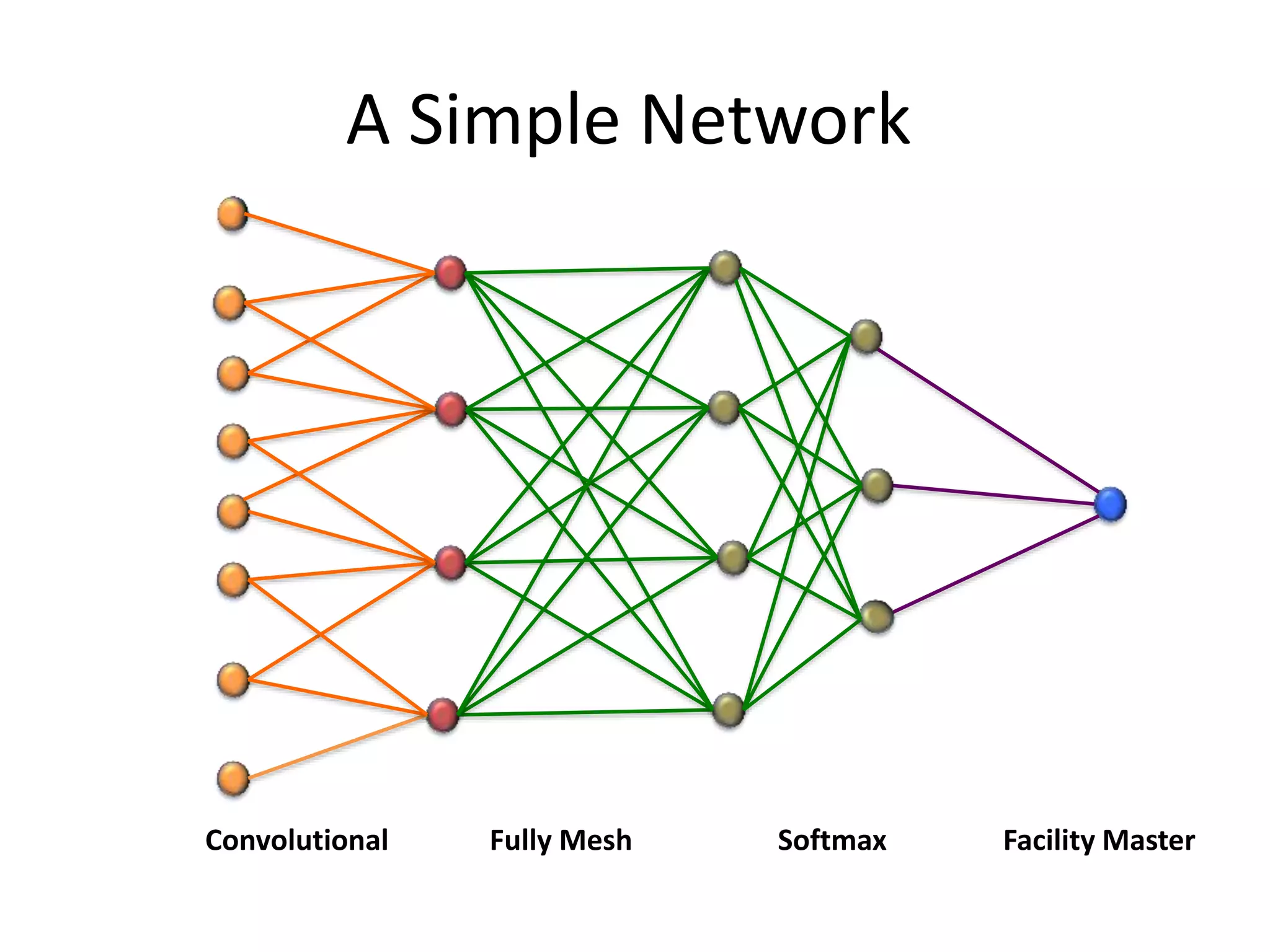
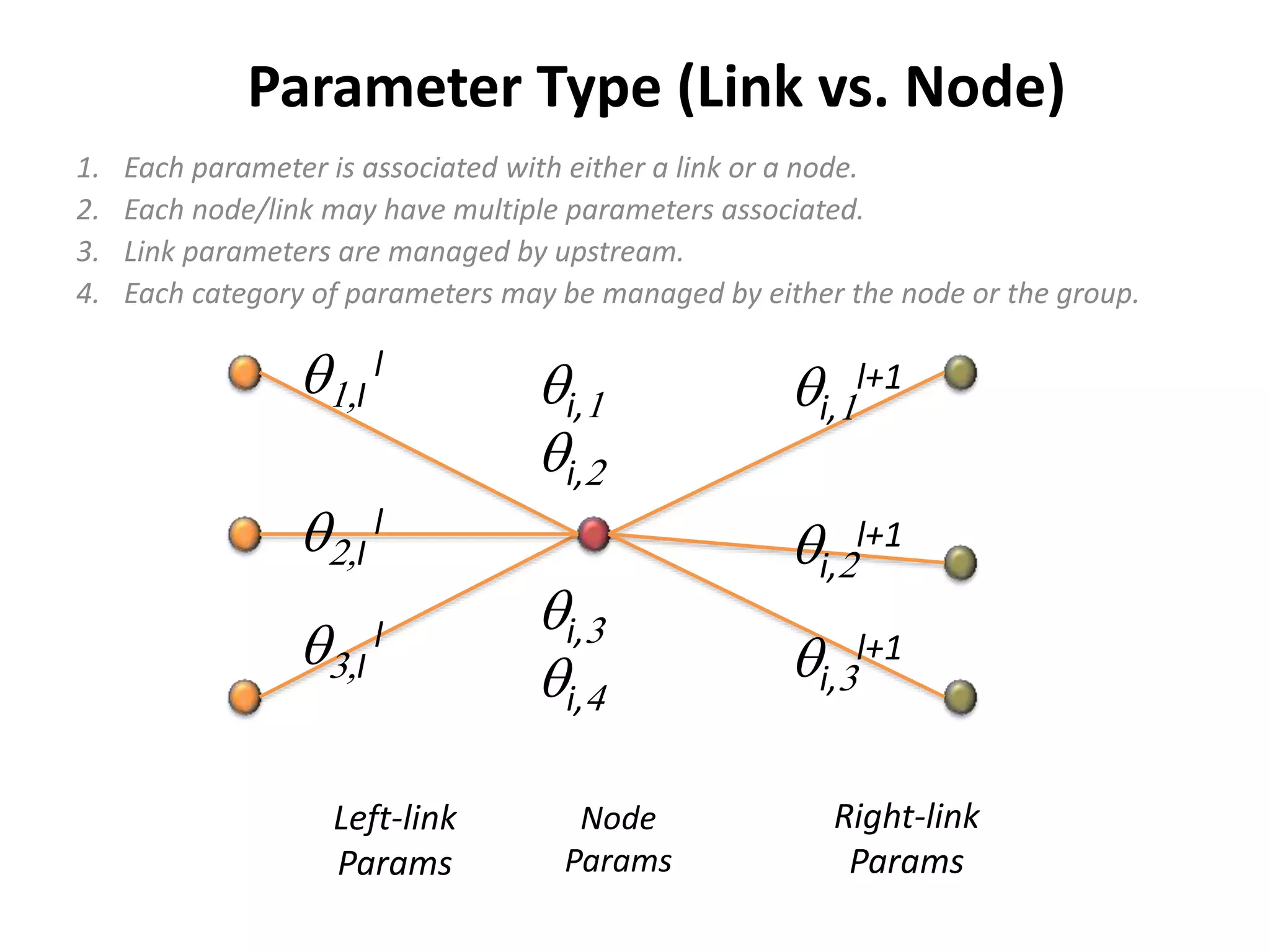
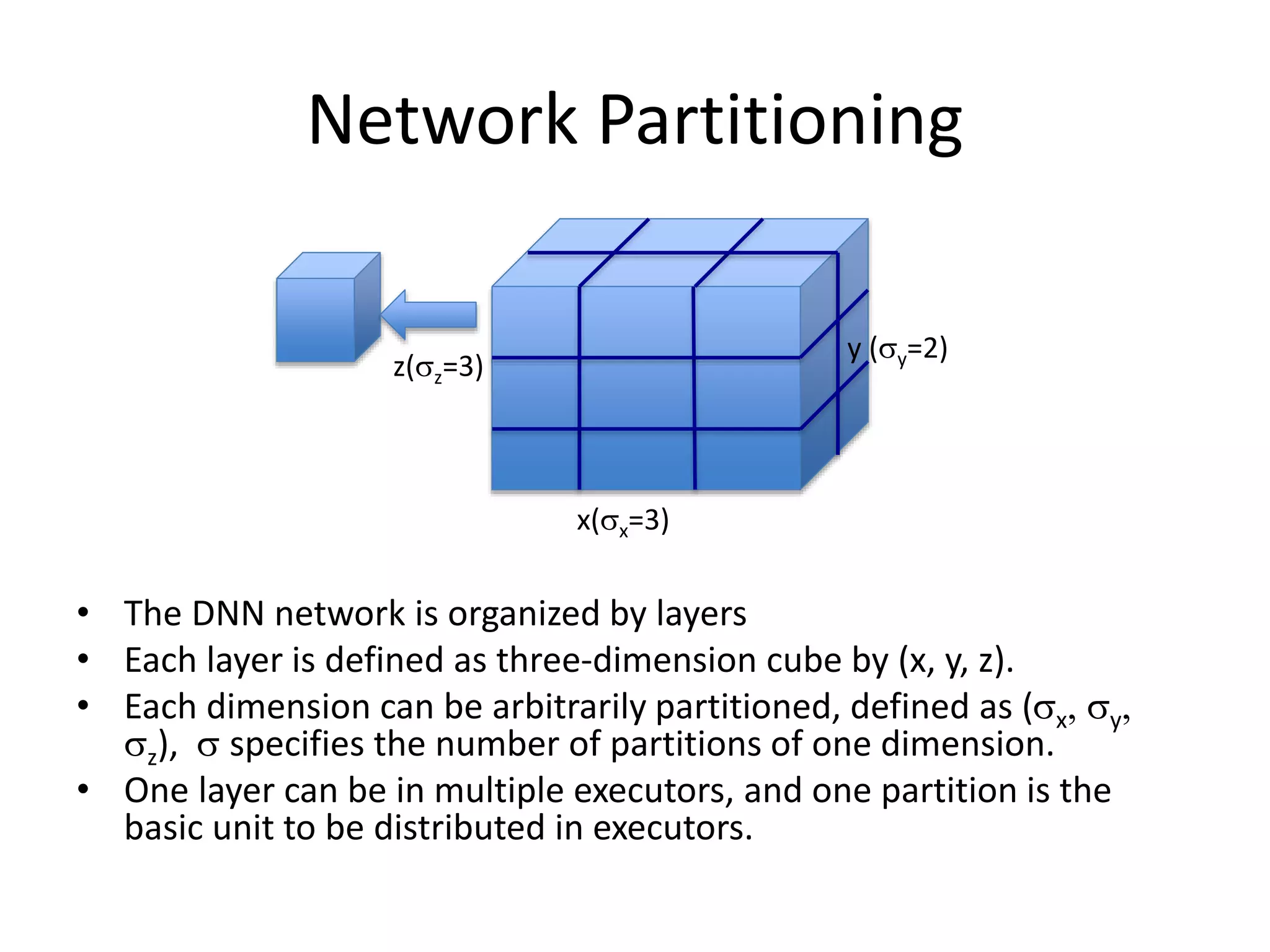
The document outlines a deep neural network (DNN) framework based on Apache Spark, emphasizing its components like solvers, parameter servers, and training methodologies (async and sync). It details the flexibility and scalability of the system, enabling data and model parallelism, along with network structure organization and various computational optimizations. Additionally, it discusses the memory and communication overheads involved in training processes, as well as the extensibility of its architecture through adaptors.