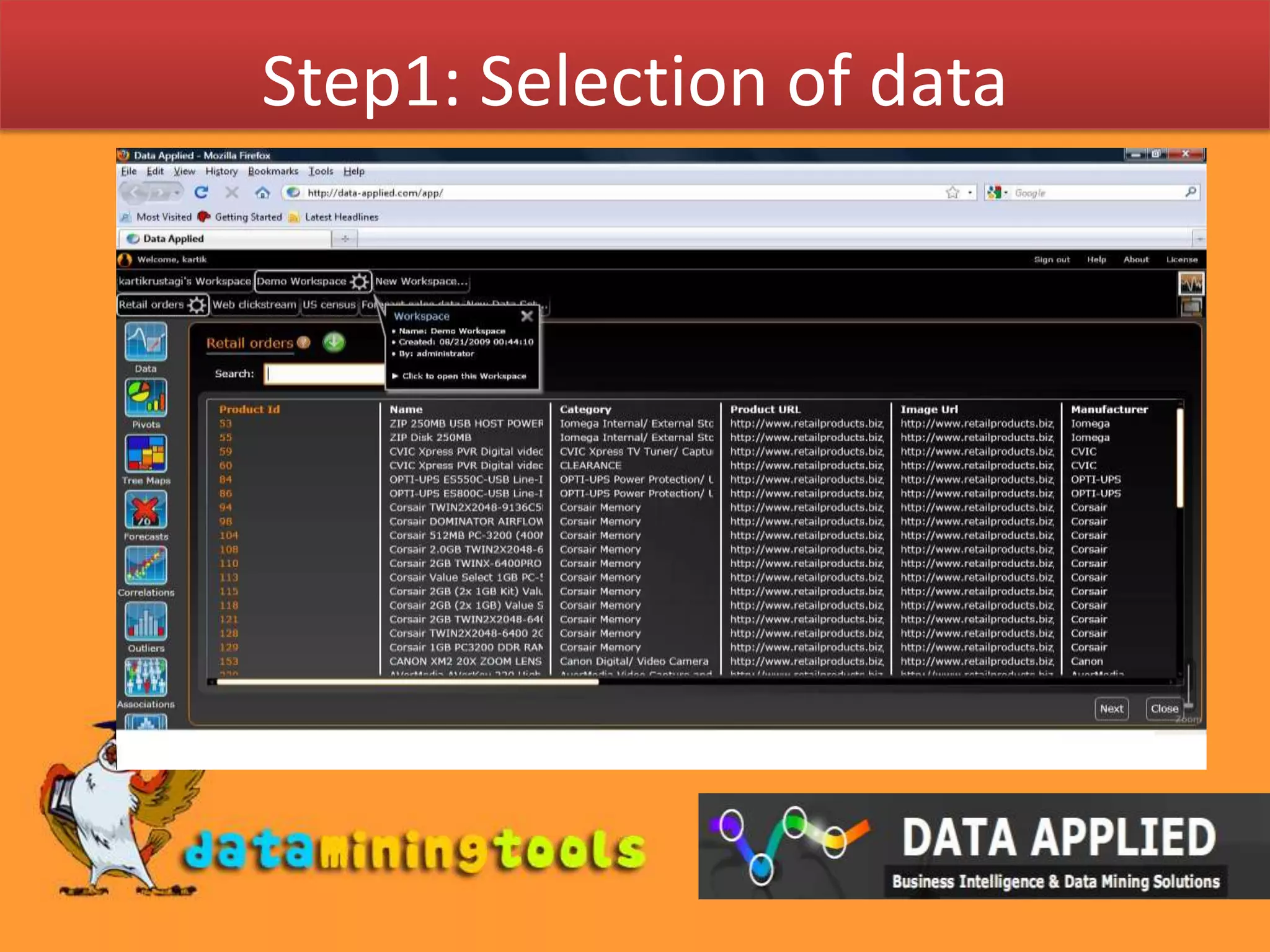
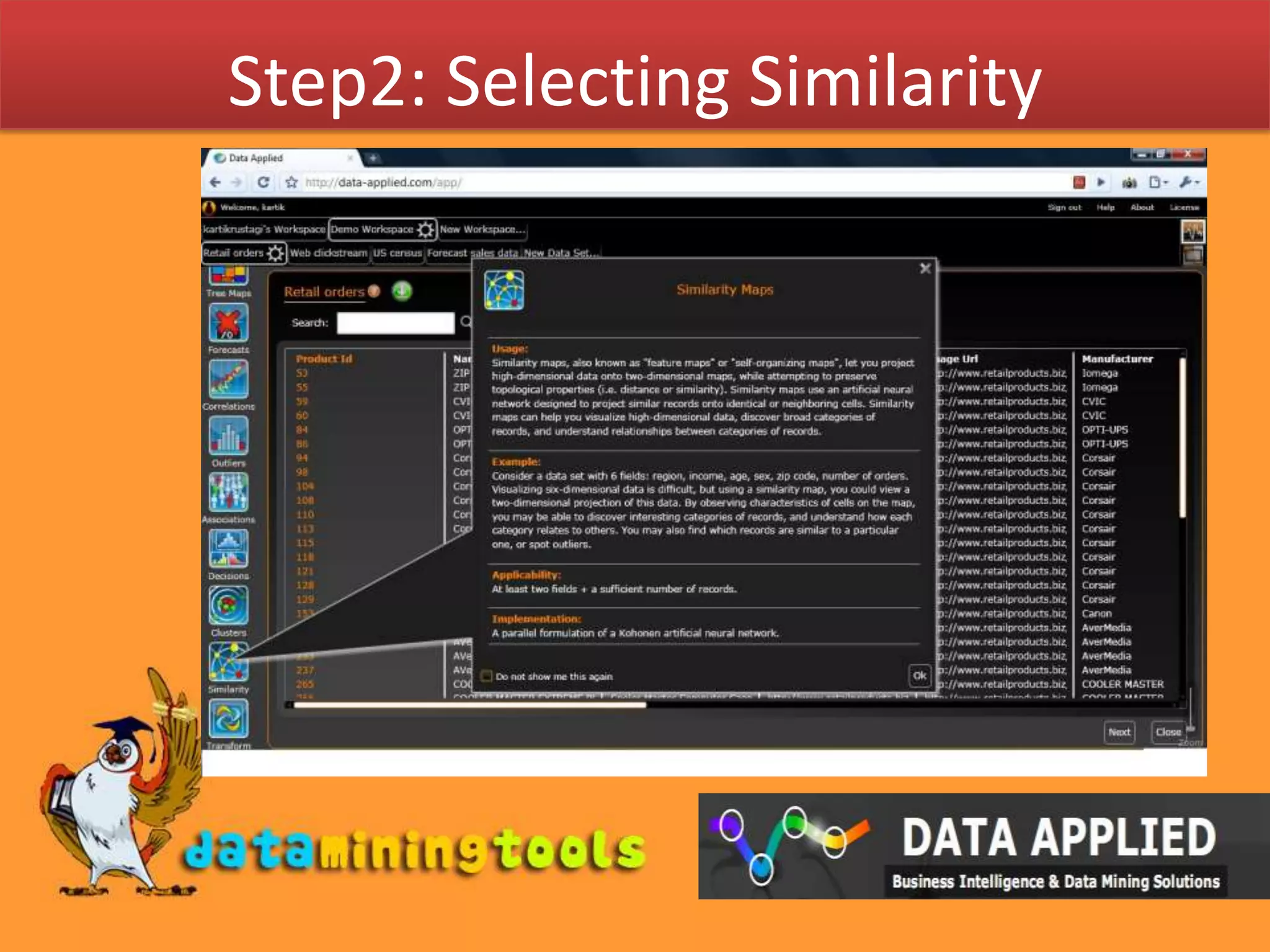
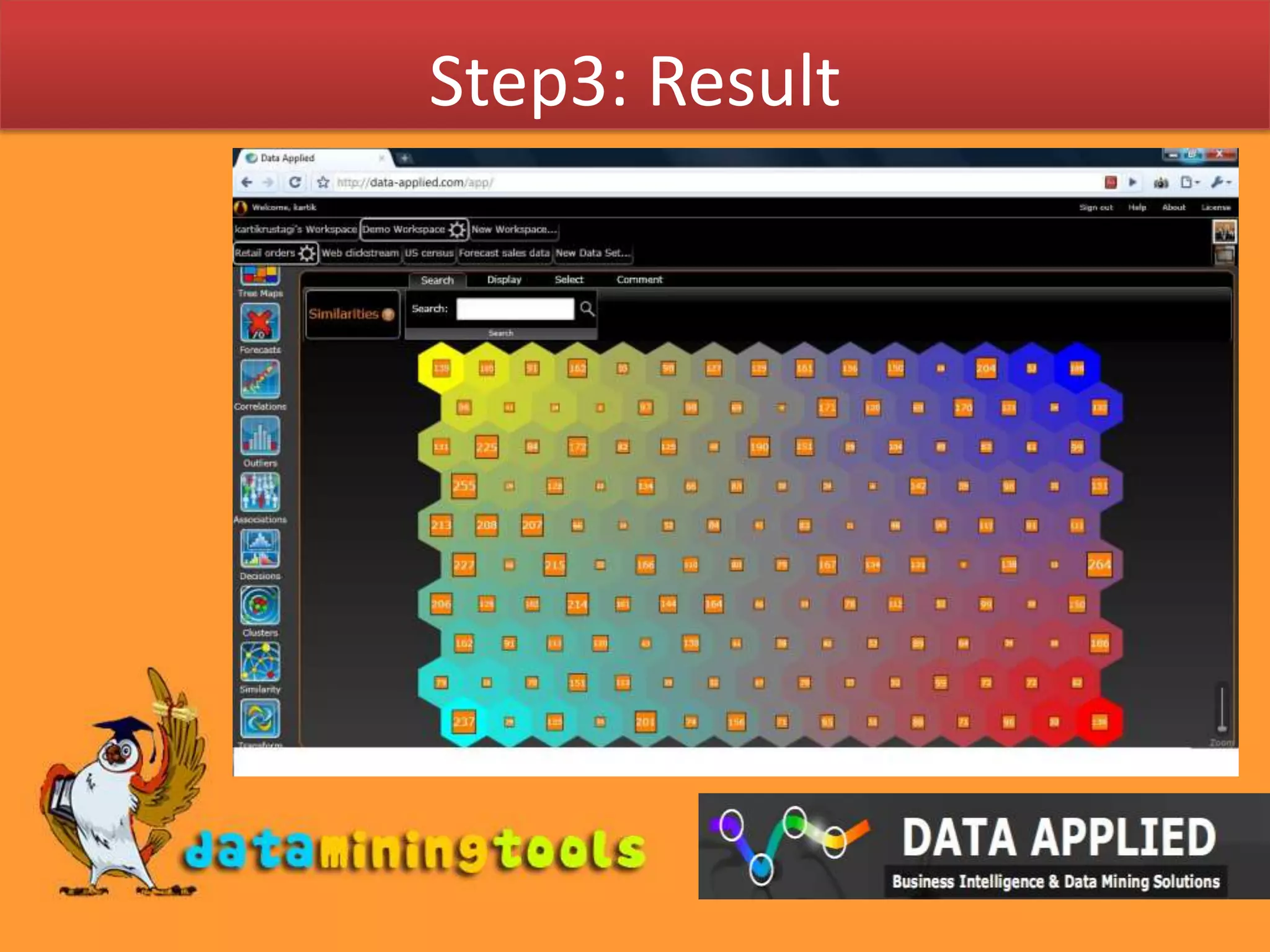


This document summarizes how a Kohonen network can be used to visualize high-dimensional data in a lower dimensional space while preserving topological similarities. It explains that a Kohonen network consists of input nodes equal to the data dimension and a grid of classification nodes with weight vectors. The learning algorithm initializes node weights, selects a random input vector, finds the best matching unit, adjusts the weights of neighboring nodes based on their distance from the BMU, and repeats for multiple iterations to map similar data points close together on the grid. It then briefly describes how Data-Applied's web interface can be used to select data and perform similarity analysis using a Kohonen network.