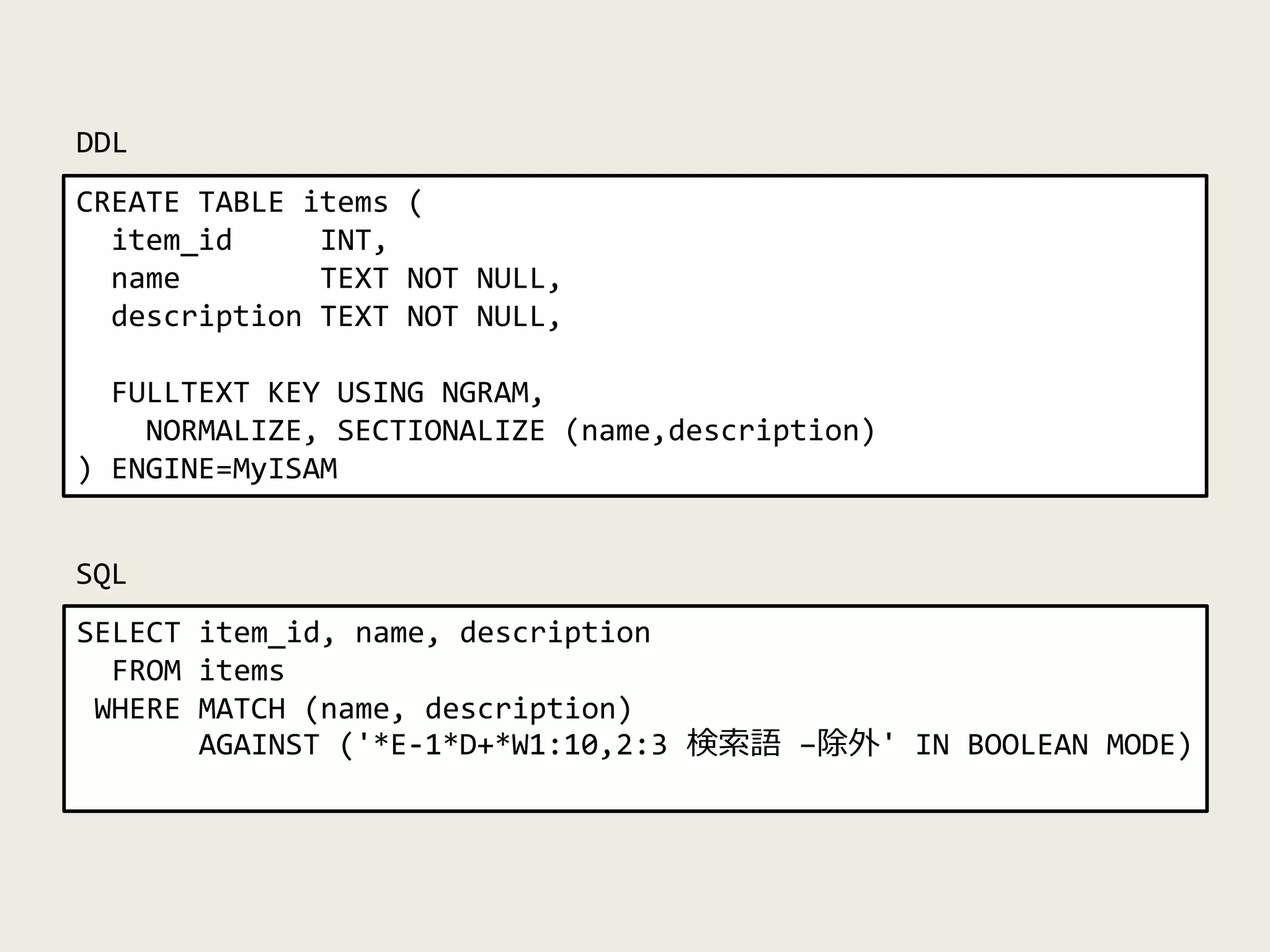
CREATE TABLE items(
item_id INT,
name TEXT NOT NULL,
description TEXT NOT NULL,
FULLTEXT KEY USING NGRAM,
NORMALIZE, SECTIONALIZE (name,description)
) ENGINE=MyISAM
SELECT item_id, name, description
FROM items
WHERE MATCH (name, description)
AGAINST ('*E-1*D+*W1:10,2:3 検索語 –除外' IN BOOLEAN MODE)
DDL
SQL



















![複数フィールドへの対応
• 例:「世界」 と 「花」 を含む name検索
• description フィールドも対象に
• match が使えないので bool query を駆使
↓ ↓ ↓
{"match" : {"name": "世界 花"}}
{"multi_match" :
{"query": "世界 花", "fields": ["name", "description"]}
}](https://image.slidesharecdn.com/tritonntoespub-190610032846/75/Tritonn-Elasticsearch-22-2048.jpg)
![bool query
{
"bool": {
"must": [
{
"bool": {
"should": [
{"match_phrase": {"name": {"世界"}}},
{"match_phrase": {"description": {"世界"}}},
]
}
},
{
"bool": {
"should": [
{"match_phrase": {"name": {"花"}}},
{"match_phrase": {"description": {"花"}}},
]
}
},
]
}
}](https://image.slidesharecdn.com/tritonntoespub-190610032846/75/Tritonn-Elasticsearch-23-2048.jpg)
![検索ワードの解析
• "(世界一 OR 日本一) 地雷職人 –yoku"
– Trironn では、そのまま渡せば意図通り
– 簡易パーサを作って対応
{"bool": {"must": [
{"bool": {"must": [
{"bool": {"should": [
{"match_phrase": {"name": {"query": "世界一"}}},
{"match_phrase": {"description": {"query": "世界一"}}
]}},
{"bool": {"should": [
{"match_phrase": {"name": {"query": "日本一"}}},
{"match_phrase": {"description": {"query": "日本一"}}}
]}}
]}},
{"bool": {"should": [
{"match_phrase": {"name": {"query": "地雷"}}},
{"match_phrase": {"description": {"query": "地雷"}}}
]}},
{"bool": {"must_not": [
{"bool": {"should": [
{"match_phrase": {"name": {"query": "yoku"}}},
{"match_phrase": {"description": {"query": "yoku"}}}
]}}
]}}
]}}](https://image.slidesharecdn.com/tritonntoespub-190610032846/75/Tritonn-Elasticsearch-24-2048.jpg)

![スペースや # が除外されない
{"type": "stop", "stopwords_path": "stopwords.txt"}
{
"type": "stop",
"stopwords": [
"t", " ", "!", """, "#", "$", "%", "&", "'", "(", ")", "*", "+", ",", "-", ".", "/",
"0", "1", "2", "3", "4", "5", "6", "7", "8", "9", ":", ";", "<", "=", ">", "?", "@",
"A", "B", "C", "D", "E", "F", "G", "H", "I", "J", "K", "L", "M", "N", "O", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z",
"[", "", "]", "^", "_", "`",
"a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z",
"{", "|", "}", "~", " ",
"ぁ", "あ", "ぃ", "い", "ぅ", "う", "ぇ", "え", "ぉ", "お", "か", "が", "き", "ぎ", "く", "ぐ", "け", "げ", "こ", "ご",
"さ", "ざ", "し", "じ", "す", "ず", "せ", "ぜ", "そ", "ぞ", "た", "だ", "ち", "ぢ", "っ", "つ", "づ", "て", "で", "と", "ど",
"な", "に", "ぬ", "ね", "の", "は", "ば", "ぱ", "ひ", "び", "ぴ", "ふ", "ぶ", "ぷ", "へ", "べ", "ぺ", "ほ", "ぼ", "ぽ",
"ま", "み", "む", "め", "も", "ゃ", "や", "ゅ", "ゆ", "ょ", "よ", "ら", "り", "る", "れ", "ろ", "ゎ", "わ", "を", "ん",
"ゔ", "ゕ", "ゖ", " ゙", " ゚", "゛", "゜",
"ァ", "ア", "ィ", "イ", "ゥ", "ウ", "ェ", "エ", "ォ", "オ", "カ", "ガ", "キ", "ギ", "ク", "グ", "ケ", "ゲ", "コ", "ゴ",
"サ", "ザ", "シ", "ジ", "ス", "ズ", "セ", "ゼ", "ソ", "ゾ", "タ", "ダ", "チ", "ヂ", "ッ", "ツ", "ヅ", "テ", "デ", "ト", "ド",
"ナ", "ニ", "ヌ", "ネ", "ノ", "ハ", "バ", "パ", "ヒ", "ビ", "ピ", "フ", "ブ", "プ", "ヘ", "ベ", "ペ", "ホ", "ボ", "ポ",
"マ", "ミ", "ム", "メ", "モ", "ャ", "ヤ", "ュ", "ユ", "ョ", "ヨ", "ラ", "リ", "ル", "レ", "ロ", "ヮ", "ワ", "ヲ", "ン", "ヴ",
"ヵ", "ヶ", "ー", "、", "。", "「", "」", "『", "』", "【", "】", "〔", "〕", "〖", "〗", "〘", "〙", "〚", "〛", "〜", "!", "?"
]
}
行単位で除外ワードを記述したファイルで stopword を指定
ファイルを読み込む処理で、# はコメント扱いの上、
スペース除去をしているため、 無視されていた
直接列挙することで対応](https://image.slidesharecdn.com/tritonntoespub-190610032846/75/Tritonn-Elasticsearch-26-2048.jpg)


![item_id plan provide
1 A 2019/06/01
1 B 2019/07/01
2 A 2019/06/07
nested field
item_id ...
10 ...
20 ...
items table
item_provisions table
{
"item_id": 10,
"item_provisions" : [
{
"plan": "A",
"provide": "2019-06-01"
},
{
"plan": "B",
"provide": "2019-07-01"
}
]
},
{
"item_id": 20,
"item_provisions" : [
{
"plan": "A",
"provide": "2019-06-07"
}
]
}
items index
1
0…n](https://image.slidesharecdn.com/tritonntoespub-190610032846/75/Tritonn-Elasticsearch-29-2048.jpg)
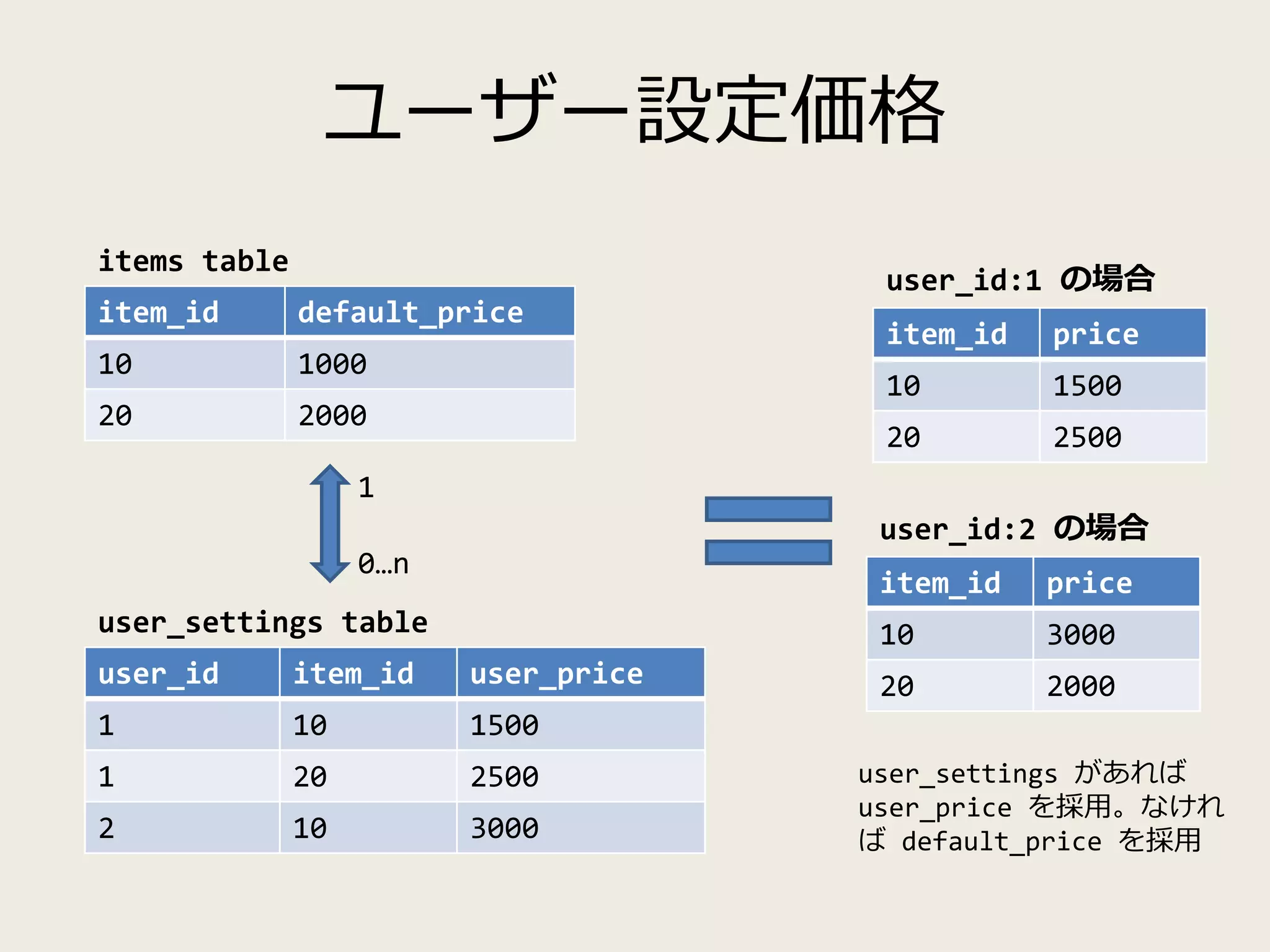

![user_id item_id user_price
1 10 1500
1 20 2500
2 10 3000
非正規化+展開
item_id default_price
10 1000
20 2000
items table
user_settings table
1
0…n
{
"item_id": 10,
"user_settings" : [
{
"user_id": 1,
"price": "1500"
},
{
"user_id": 2,
"price": "3000"
},
]
},
{
"item_id": 20,
"user_settings" : [
{
"user_id": 1,
"price": "2500"
},
{
"user_id": 2,
"price": "2000"
},
]
}
items index](https://image.slidesharecdn.com/tritonntoespub-190610032846/75/Tritonn-Elasticsearch-32-2048.jpg)

![user_id item_id user_price
1 10 1500
1 20 2500
2 10 3000
DB のデータを
そのまま非正規化
item_id default_price
10 1000
20 2000
items table
user_settings table
1
0…n
{
"item_id": 10,
"default_price": 1000,
"user_settings" : [
{
"user_id": 1,
"price": "1500"
},
{
"user_id": 2,
"price": "3000"
}
]
},
{
"item_id": 20,
"default_price": 2000,
"user_settings" : [
{
"user_id": 1,
"price": "2500"
}
/* user_id:2 は含めない */
]
}
items index](https://image.slidesharecdn.com/tritonntoespub-190610032846/75/Tritonn-Elasticsearch-34-2048.jpg)


![{
“function_score”: {
“query”: {
“function_score”: {
“query”: {
“bool”: {
"filter": [
{"match_all": {}}
],
“should”: [
{
“nested”: {
“path”: “user_settings",
"query": {
"function_score": {
"query": {
"term": {
"user_settings.user_id":{"value": 2, "boost": 0}
}
},
"field_value_factor" : {
"field":"user_settings.user_price", "missing": 0
},
"boost_mode": "replace"
}
}
}
}
]
}
},
"script_score": {
"script": {
"source": "0 < _score ? _score : doc['default_price'].value"
}
},
"boost_mode": "replace",
"min_score": 2000
}},
"boost_mode": "replace",
"weight": 1
}
}
1.全体を対象にして
2. user_id:2 の
user_settings があれば
3.user_price を _score に置き換える
(なければ0)
4. _score が 0 の場合は default_price を
_score に置き換え (_score が price になる)
5. _score (price) が 2000 以上のみに絞り込む
6. 重みづけを 1に戻すことで、金額がスコアに影響するのを抑制](https://image.slidesharecdn.com/tritonntoespub-190610032846/75/Tritonn-Elasticsearch-37-2048.jpg)