Recommended
PDF
PDF
PDF
R language definition3.1_3.2
ODP
PDF
Tokyor60 r data_science_part1
PPTX
Tritonn から Elasticsearch への移行話
PDF
3時間濃縮CakePHP2.1 in PHPカンファレンス北海道2012
PDF
PDF
PPTX
PDF
PDF
ビギナーだから使いたいO/Rマッパー ~Tengを使った開発~
PDF
PDF
PDF
PPTX
Python for Data Analysis: Chapter 2
ODP
PDF
Ruby初級者向けレッスン 53回 ─── Array と Hash
PDF
PDF
PHP と MySQL でカジュアルに MapReduce する
KEY
PDF
PDF
PHP と MySQL でカジュアルに MapReduce する (Short Version)
PPTX
PPTX
PDF
R入門(dplyrでデータ加工)-TokyoR42
PDF
PDF
PDF
PDF
RとStanでクラウドセットアップ時間を分析してみたら #TokyoR
More Related Content
PDF
PDF
PDF
R language definition3.1_3.2
ODP
PDF
Tokyor60 r data_science_part1
PPTX
Tritonn から Elasticsearch への移行話
PDF
3時間濃縮CakePHP2.1 in PHPカンファレンス北海道2012
PDF
What's hot
PDF
PPTX
PDF
PDF
ビギナーだから使いたいO/Rマッパー ~Tengを使った開発~
PDF
PDF
PDF
PPTX
Python for Data Analysis: Chapter 2
ODP
PDF
Ruby初級者向けレッスン 53回 ─── Array と Hash
PDF
PDF
PHP と MySQL でカジュアルに MapReduce する
KEY
PDF
PDF
PHP と MySQL でカジュアルに MapReduce する (Short Version)
Viewers also liked
PPTX
PPTX
PDF
R入門(dplyrでデータ加工)-TokyoR42
PDF
PDF
PDF
PDF
RとStanでクラウドセットアップ時間を分析してみたら #TokyoR
PDF
PPT
PDF
PDF
20140625 rでのデータ分析(仮) for_tokyor
PDF
PDF
Rで学ぶ 傾向スコア解析入門 - 無作為割り当てが出来ない時の因果効果推定 -
PDF
PPTX
PDF
PDF
PPTX
PDF
PPTX
Similar to 20170923 excelユーザーのためのr入門
PPTX
PDF
PDF
PDF
[データマイニング+WEB勉強会][R勉強会] はじめてでもわかる 統計解析・データマイニング R言語入門
PDF
PDF
PDF
第8回 大規模データを用いたデータフレーム操作実習(2)
PDF
PPT
12-11-30 Kashiwa.R #5 初めてのR Rを始める前に知っておきたい10のこと
PDF
PPTX
PDF
PPTX
PDF
PDF
PDF
PDF
PDF
PDF
PDF
More from Takashi Kitano
PDF
{tidygraph}と{ggraph}による モダンなネットワーク分析(未公開ver)
PDF
{tidygraph}と{ggraph}によるモダンなネットワーク分析
PDF
好みの日本酒を呑みたい! 〜さけのわデータで探す自分好みの酒〜
PDF
{tidytext}と{RMeCab}によるモダンな日本語テキスト分析
PDF
{shiny}と{leaflet}による地図アプリ開発Tips
PDF
PDF
PDF
PDF
PDF
20160311 基礎からのベイズ統計学輪読会第6章 公開ver
PDF
PDF
Google's r style guideのすゝめ
PDF
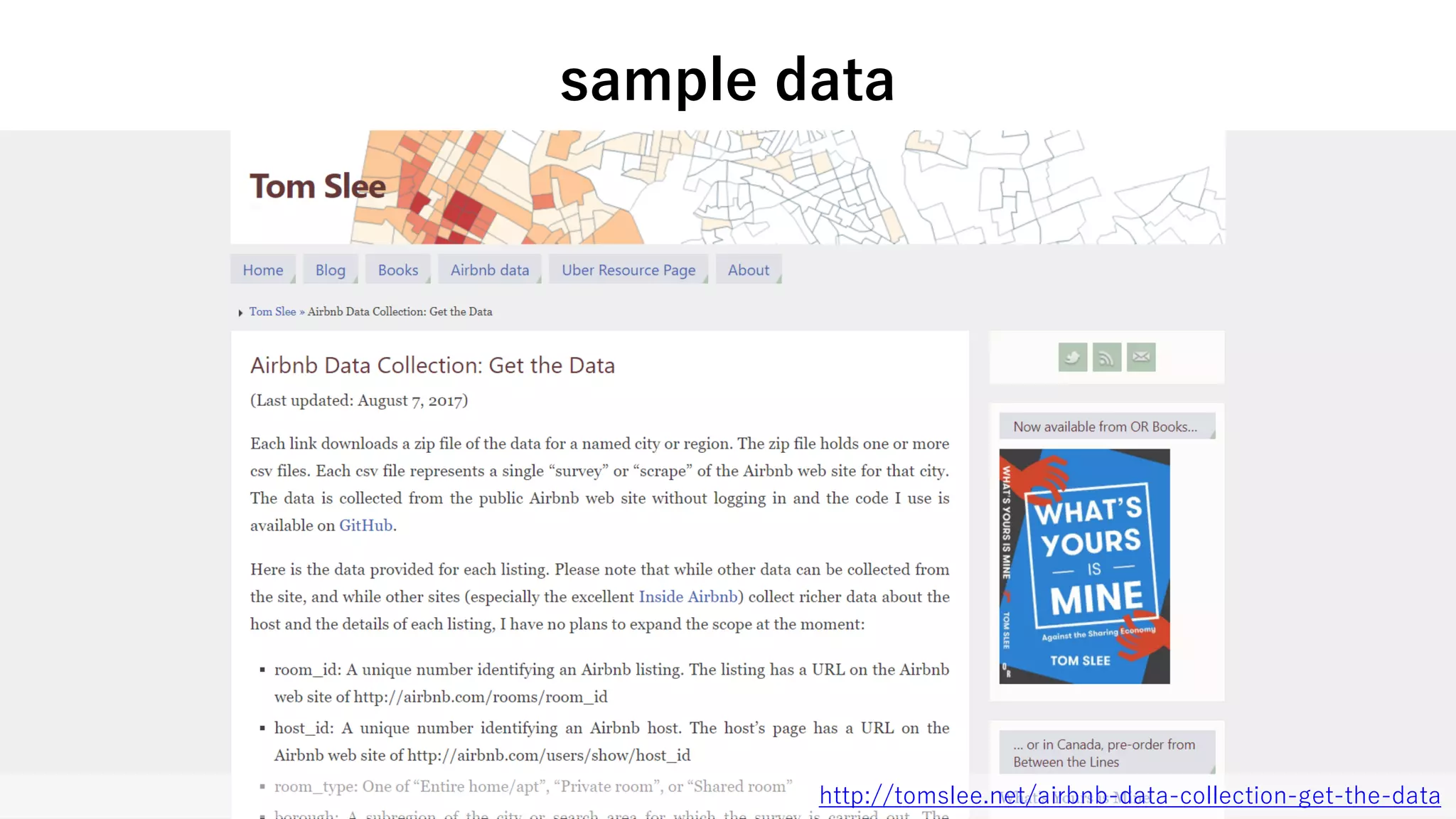
20170923 excelユーザーのためのr入門 1. 2. 3. 4. 5. 6. > sheet1 <- data.frame(
+ name = c("Access",
+ "Excel",
+ "Powerpoint",
+ "Word"),
+ price = rep(15984, 4),
+ stringsAsFactors = FALSE
+ )
data.frame() にc() で値を列挙
data.frameの作成
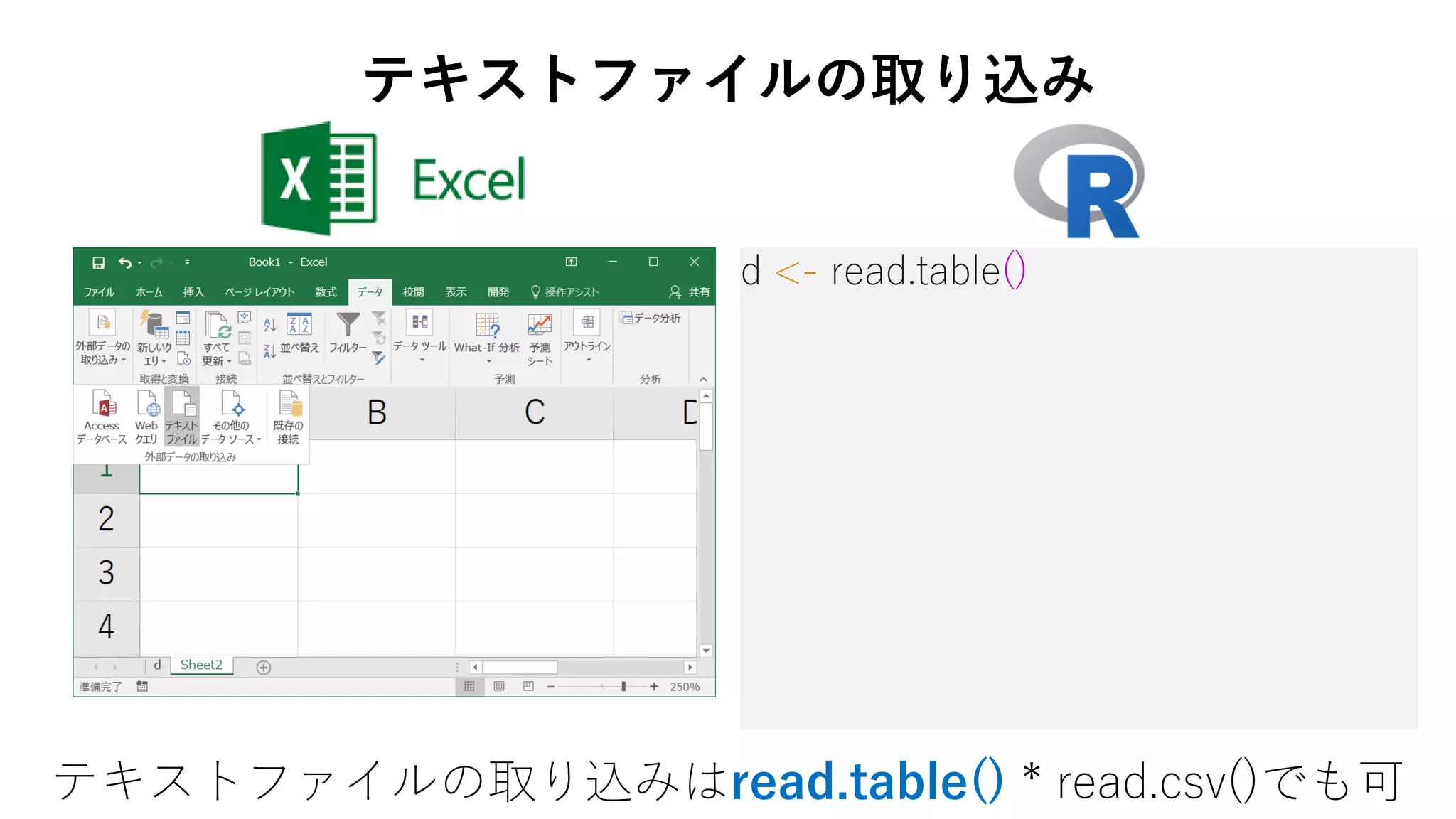
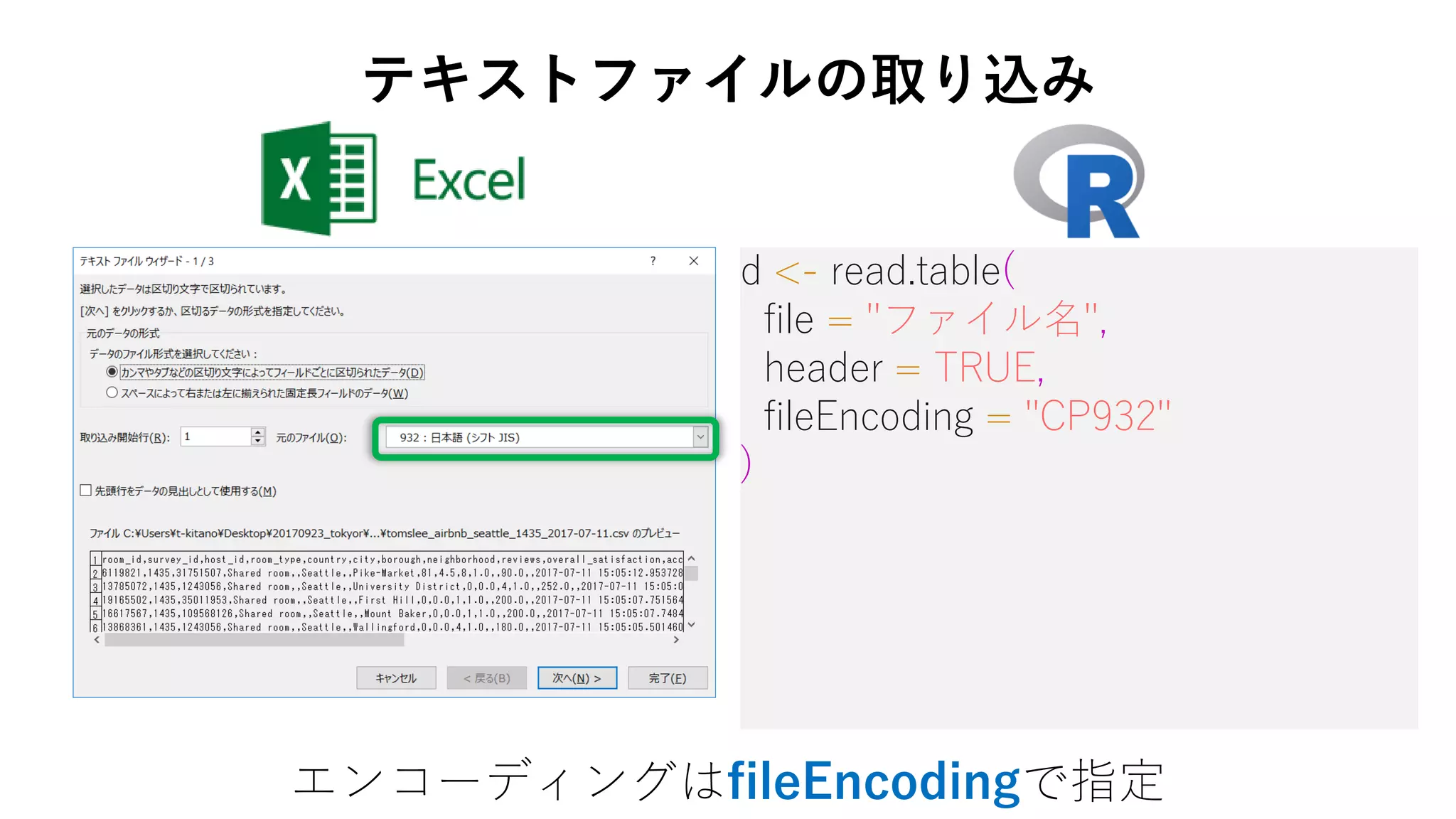
7. 8. 9. 10. d <- read.table(
file = "ファイル名",
header = TRUE,
fileEncoding = "CP932"
)
エンコーディングはfileEncodingで指定
テキストファイルの取り込み
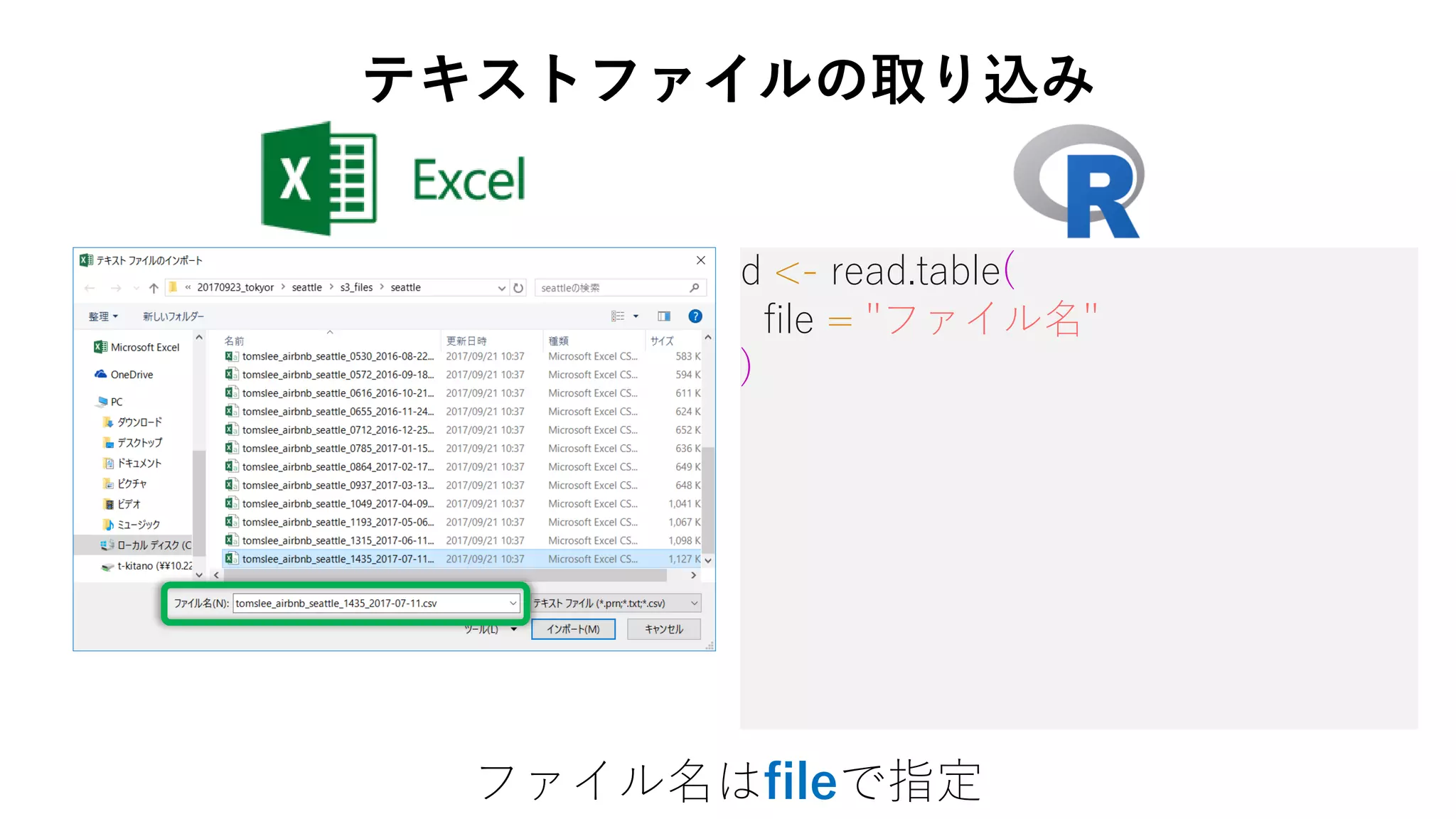
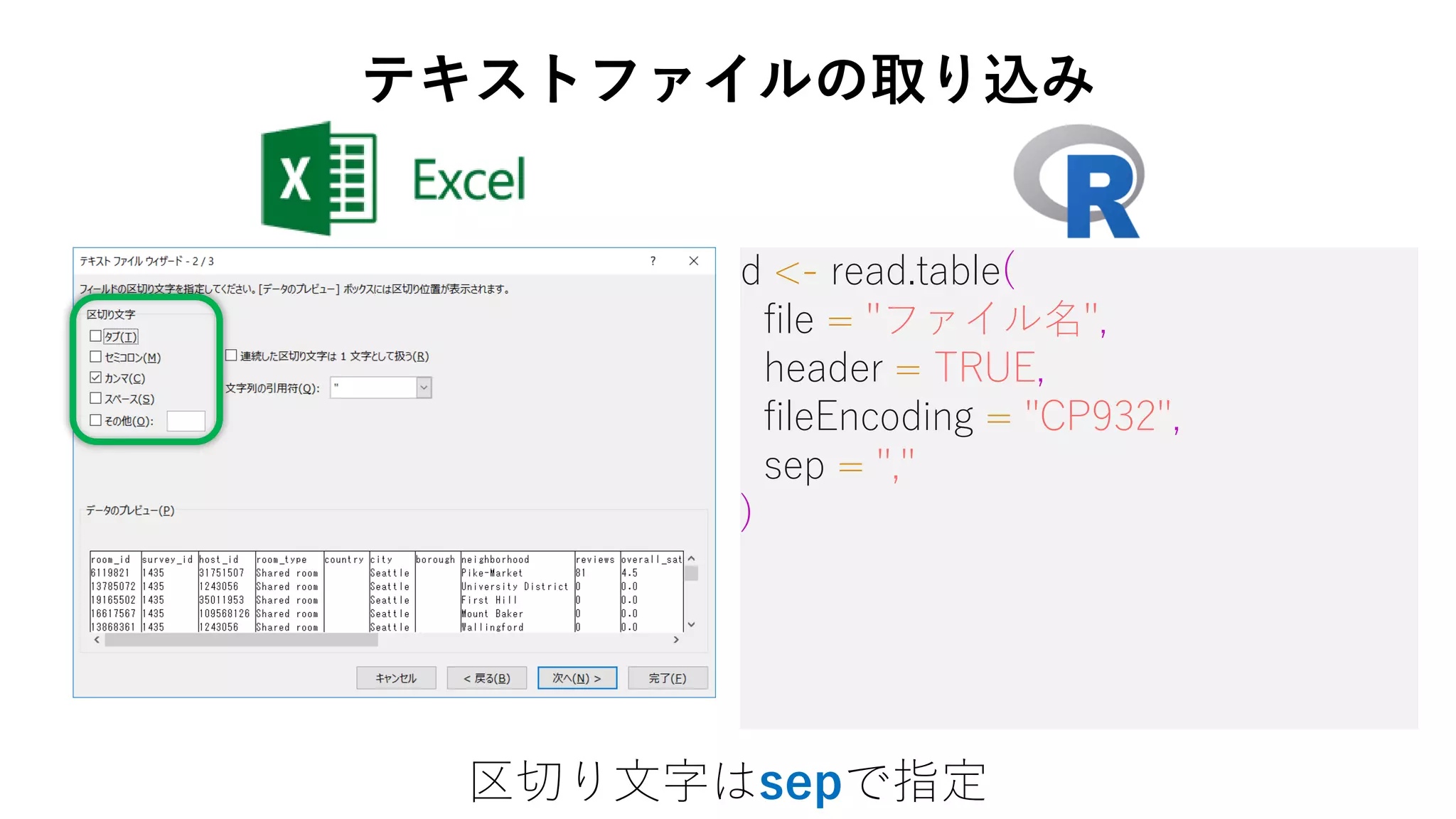
11. d <- read.table(
file = "ファイル名",
header = TRUE,
fileEncoding = "CP932",
sep = ","
)
区切り文字はsepで指定
テキストファイルの取り込み
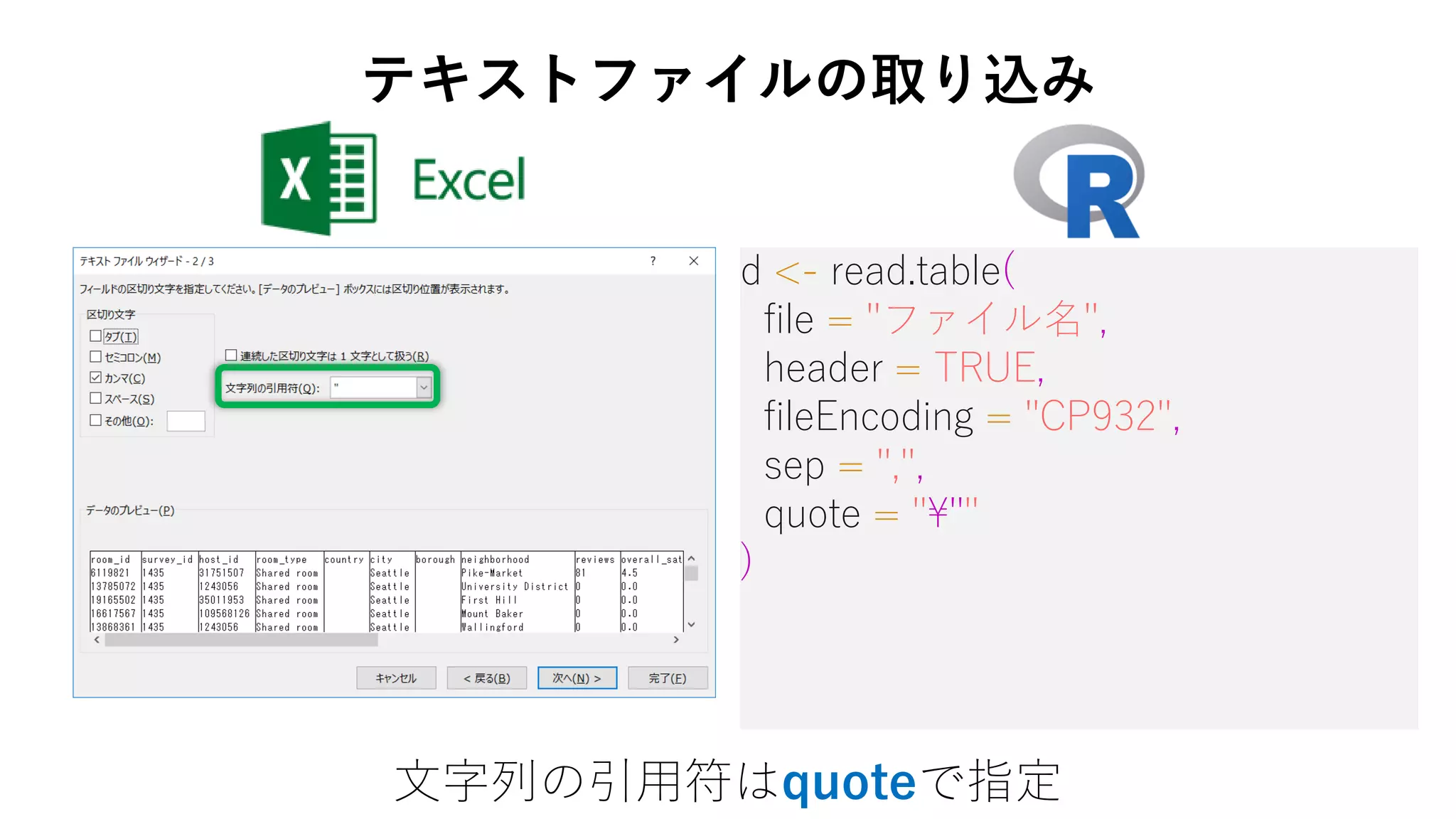
12. d <- read.table(
file = "ファイル名",
header = TRUE,
fileEncoding = "CP932",
sep = ",",
quote = "¥""
)
文字列の引用符はquoteで指定
テキストファイルの取り込み
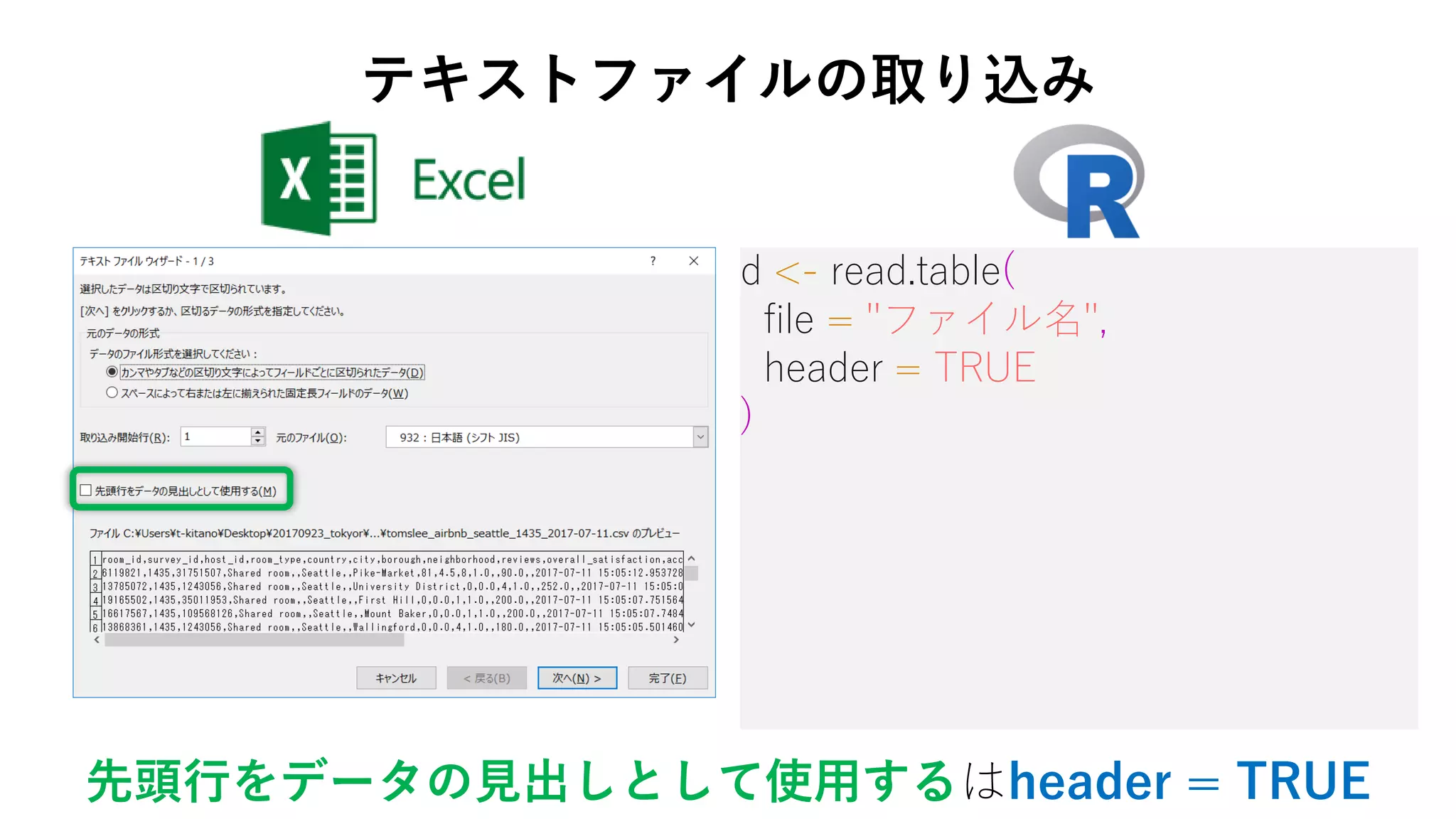
13. d <- read.table(
file = "ファイル名",
header = TRUE,
fileEncoding = "CP932",
sep = ",",
quote = "¥""
)
データ形式は自動で判別される
テキストファイルの取り込み
14. d <- read.table(
file = "ファイル名",
header = TRUE,
fileEncoding = "CP932",
sep = ",",
quote = "¥"",
stringsAsFactors = FALSE
)
文字列はFactor型となるのでstringsAsFactor = FALSEを推奨
テキストファイルの取り込み
15. d <- read.table(
file = "ファイル名",
header = TRUE,
fileEncoding = "CP932",
sep = ",",
quote = "¥"" ,
colClasses = c("integer", "integer", ...)
)
明示的にデータ形式を指定する場合はcolClassesで指定
テキストファイルの取り込み
16. • 数値
• 日付
• 時刻
• 文字列
• TRUE(), FALSE()
⇒numeric, integer
⇒Date
⇒POSIXct, POSIXlt, POSIXt
⇒character
⇒logical
データ形式の対応は上記の通り
Excelのデータ形式とRのデータ型
17. 18. 19. 20. > d[2:3, ]
room_id survey_id host_id ...
2 13785072 1435 1243056 ...
3 19165502 1435 35011953 ...
列番号を省略するとすべての列が返される
複数行の参照
21. > d[, 2:3]
survey_id host_id
1 1435 31751507
2 1435 1243056
3 1435 35011953
4 1435 109568126
…
行番号を省略するとすべての列が返される
複数列の参照
22. > d[, c("survey_id", "host_id")]
survey_id host_id
1 1435 31751507
2 1435 1243056
3 1435 35011953
4 1435 109568126
…
列名をベクトルで与えてもOK
複数列の参照
23. > d$price[2] + 10
[1] 262
> d$price[2] - 10
[1] 242
> d$price[2] * 10
[1] 2520
> d$price[2] / 10
[1] 25.2
四則演算は同じ
四則演算
24. 25. 26. > # デフォルトの底はe
> log(d$price[2])
[1] 5.529429 >
> log(d$price[2], 10)
[1] 2.401401
> log(d$price[2], 2)
[1] 7.97728
Excelのlog()の底のデフォルトは10, Rのlog()は自然数e
対数
27. 28. 29. 30. 31. 32. > # sepで連結時の文字を指定
> paste(d$room_type[2], d$city[2],
+ sep="-")
[1] "Shared room-Seattle"
> # paste0()はpaste(..., sep="")と同じ
> paste0(d$room_type[2], d$city[2])
[1] "Shared roomSeattle"
文字列の連結はpaste(), paste0()
文字列の連結
33. 34. > # 文字列の長さを取得
> n <- nchar(d$room_type[2])
> substr(d$room_type[2], n-4+1, n)
[1] "room"
Excelのright()は少し工夫が必要
文字列の一部取り出し
35. > # stringr::str_subは負数で
> # 末尾からの位置を指定できる
> library(stringr)
> str_sub(d$room_type[2], -4)
[1] "room"
Excelのright()はstringr::str_sub()が便利
文字列の一部取り出し
36. 37. > d$room_type[1]
[1] "Shared room"
> tolower(d$room_type[1])
[1] "shared room"
> toupper(d$room_type[1])
[1] "SHARED ROOM"
Excelのlower(), upper()はRのtolower(), toupper ()
大文字, 小文字の変換
38. > d$subtotal <- d$reviews * d$price
> d$subtotal
[1] 7290 0 0 0 0 0 0 0 0 0 4470 0 …
[16] 0 0 0 0 100 0 0 765 252 567 …
[31] 525 0 0 79 138 219 1152 248 …
[46] 2625 2015 1950 0 0 0 144 0 48…
[61] 225 405 49 0 48 200 0 360 …
…
Rでは同じ長さのベクトルの演算は、各要素ごとの演算となる
ベクトル演算
39. > d[order(d$price),
+ c("room_id", "price")]
room_id price
110 18852442 10
4370 13726014 10
4371 4825073 10
135 13560642 14
6302 6015931 19
order () で並べ替えの順番を取得して行に指定
並べ替え
40. > d[order(d$price,
+ decreasing = TRUE),
+ c("room_id", "price")]
room_id price
194 5240694 10000
193 153967 9300
195 16816051 1395
197 16740073 1200
降順はdescreasing = TRUE
並べ替え
41. > subset(d,
+ room_type == "Private room")
room_id host_id room_type ...
15647498 60642090 Private room ...
15906510 103181101 Private room ...
5978216 31036041 Private room ... ...
subset() で条件に合致するレコードを取得
フィルター
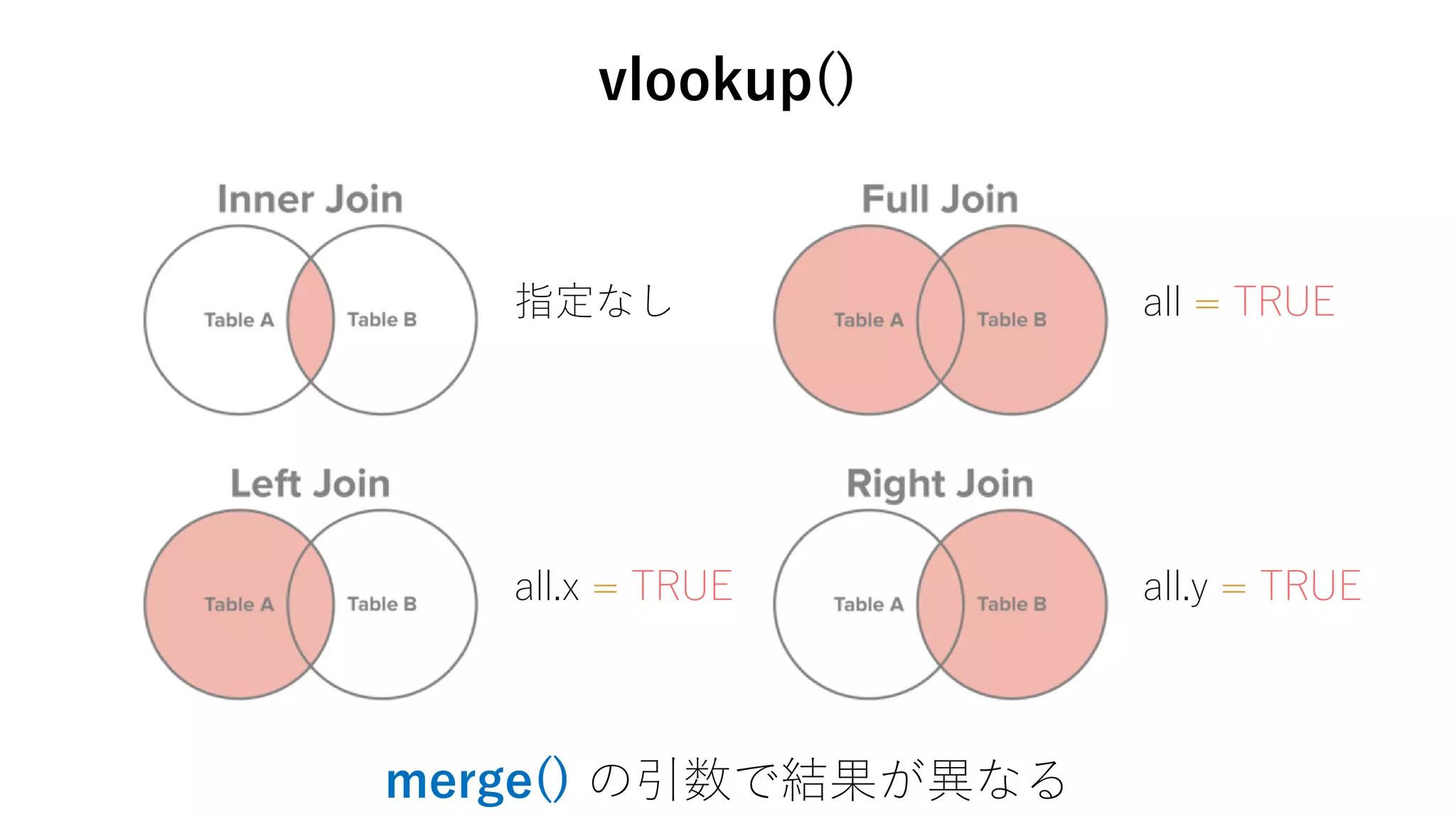
42. > merge(
+ d[, c("room_id", "city", "country")],
+ m, by="city", all.x = TRUE)
city room_id country.x country.y
1 Seattle 6119821 NA USA
2 Seattle 13785072 NA USA
3 Seattle 19165502 NA USA
…
merge() で複数のdata.frameをJOINすることが可能
vlookup()
43. 44. > write.table(d,
+ file = "file_name.txt",
+ quote = FALSE,
+ na = "",
+ sep = "¥t",
+ row.names = FALSE,
+ fileEncoding = "UTF8")
テキストファイルへの出力はwrite.table()
テキストファイルへの出力
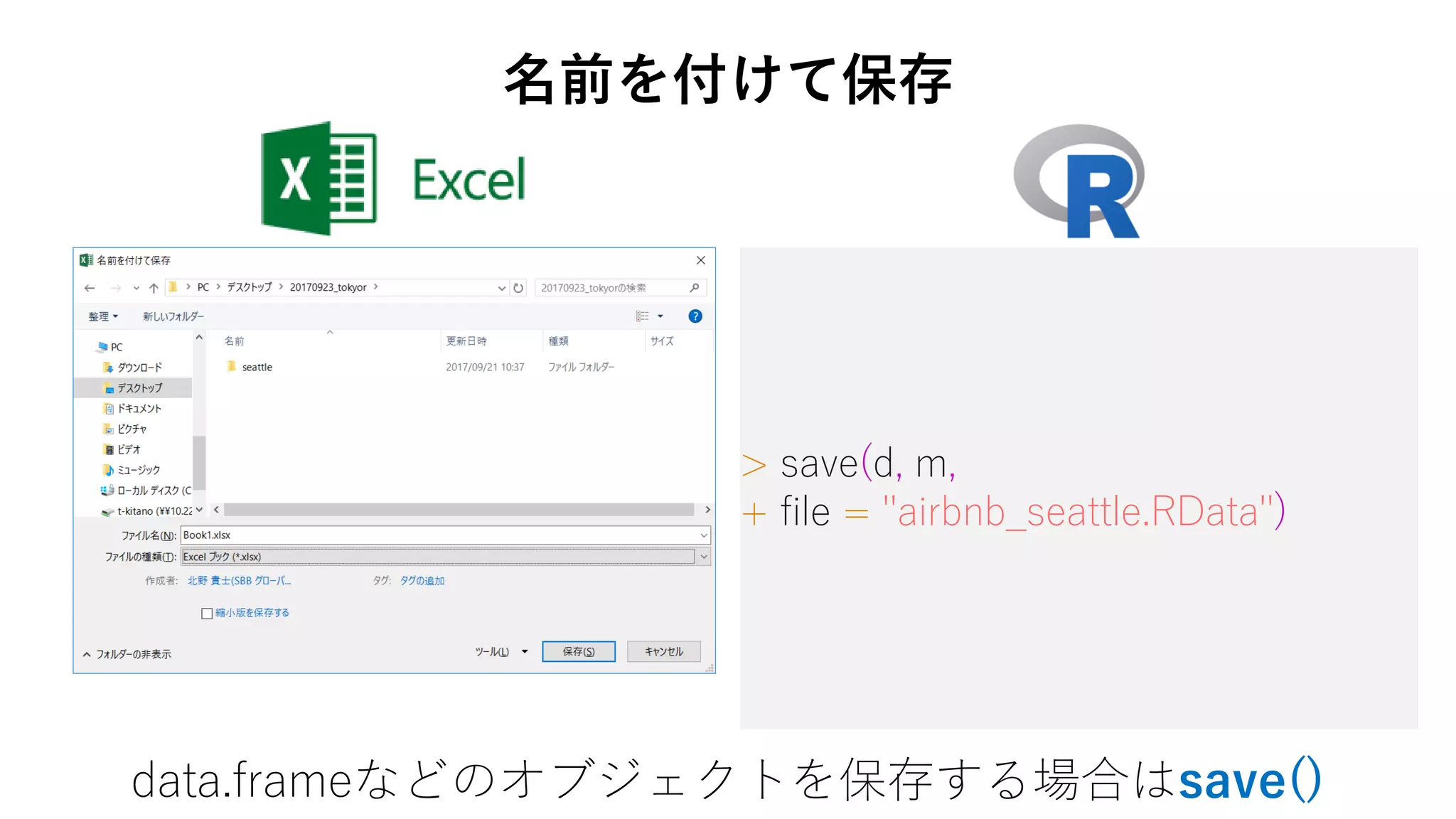
45. > save(d, m,
+ file = "airbnb_seattle.RData")
data.frameなどのオブジェクトを保存する場合はsave()
名前を付けて保存
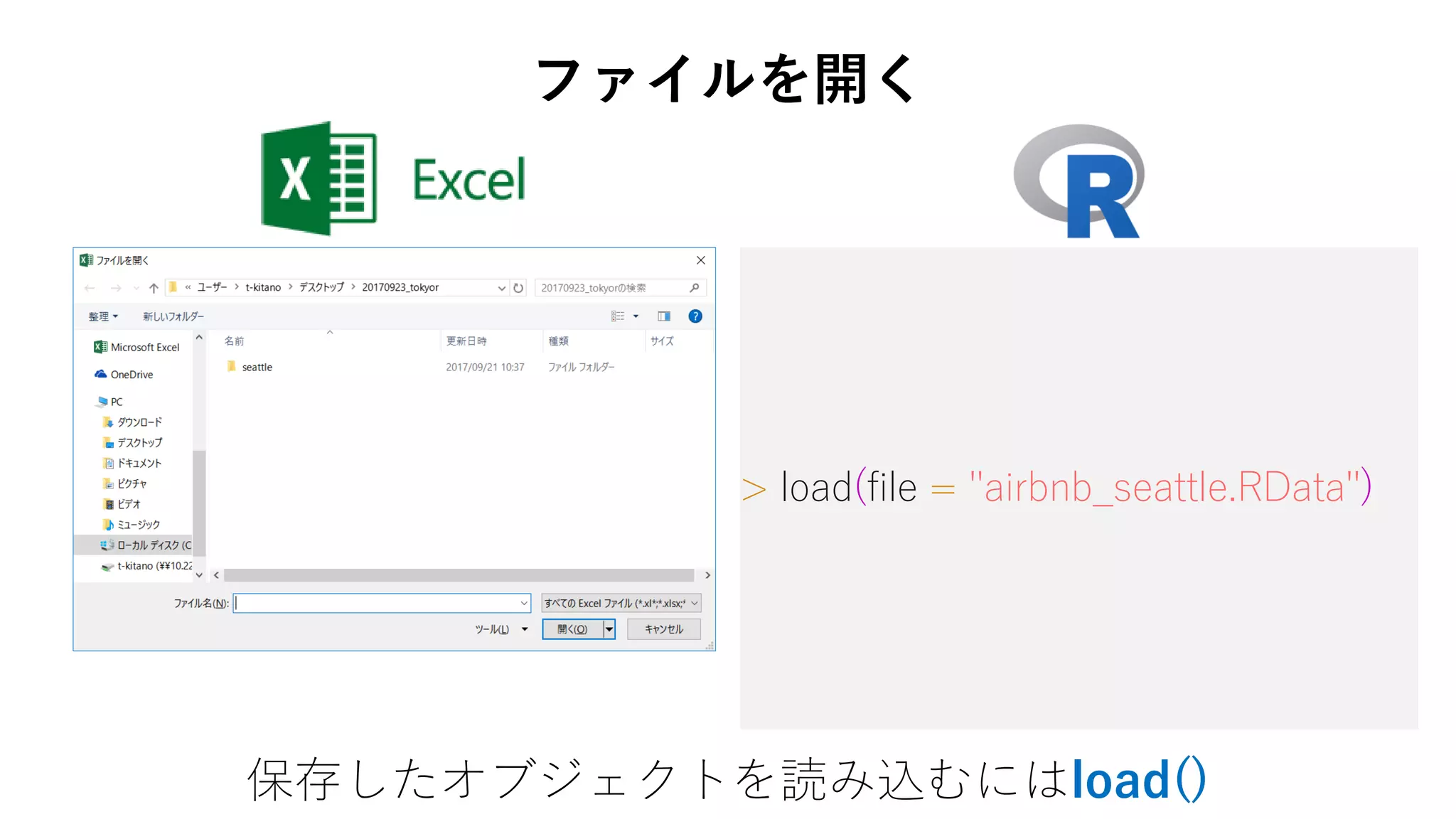
46. > load(file = "airbnb_seattle.RData")
保存したオブジェクトを読み込むにはload()
ファイルを開く
47. • quotient
• mod
• ln
• log10
• log(x, 底)
• sqrt
⇒%/%
⇒%%
⇒log(x)
⇒log(x, 10)
⇒log(x, 底)
⇒sqrt
データハンドリングまとめ
48. • if
• and
• or
• not
• 並べ替え
• フィルター
• vlookup
⇒ifelse
⇒&
⇒|
⇒not
⇒order
⇒subset
⇒merge
データハンドリングまとめ
49. • &, concatenate
• left
• mid
• right
• substitute
• lower
• upper
⇒paste, paste0, stringr::str_c
⇒substr, stringr::str_sub
⇒substr, stringr::str_sub
⇒substr, stringr::str_sub
⇒gsub, stringr::str_replace_all
⇒tolower
⇒toupper
データハンドリングまとめ
50. 51. 52. > sum(d$price)
[1] 913518
> mean(d$price)
[1] 142.7595
> var(d$price)
[1] 38718.49
> sd(d$price)
[1] 196.7701
average()はmean() , stdev()はsd()
合計, 平均, 分散, 標準偏差
53. > max(d$price)
[1] 10000
> min(d$price)
[1] 10
> median(d$price)
[1] 110
> # mode()はデータ型を返す
> mode(d$price)
[1] "numeric"
Rには最頻値を返す関数はない
最大値, 最小値, 中央値, 最頻値
54. > range(d$price)
[1] 10 10000
> range(d$price)[1]
[1] 10
> range(d$price)[2]
[1] 10000
範囲(最大値と最小値の差)
Rのrange()は最大値と最小値がベクトルで返る
55. > quantile(d$price)
0% 25% 50% 75% 100%
10 79 110 172 10000
> quantile(d$price)[2]
25%
79
> quantile(d$price)[4]
75%
172
四分位数
Rのquantile()は四分位数がベクトルで返る
56. 57. 58. • max
• min
• quartile
• percentile
⇒max
⇒min
⇒quantile
⇒quantile
集約関数まとめ
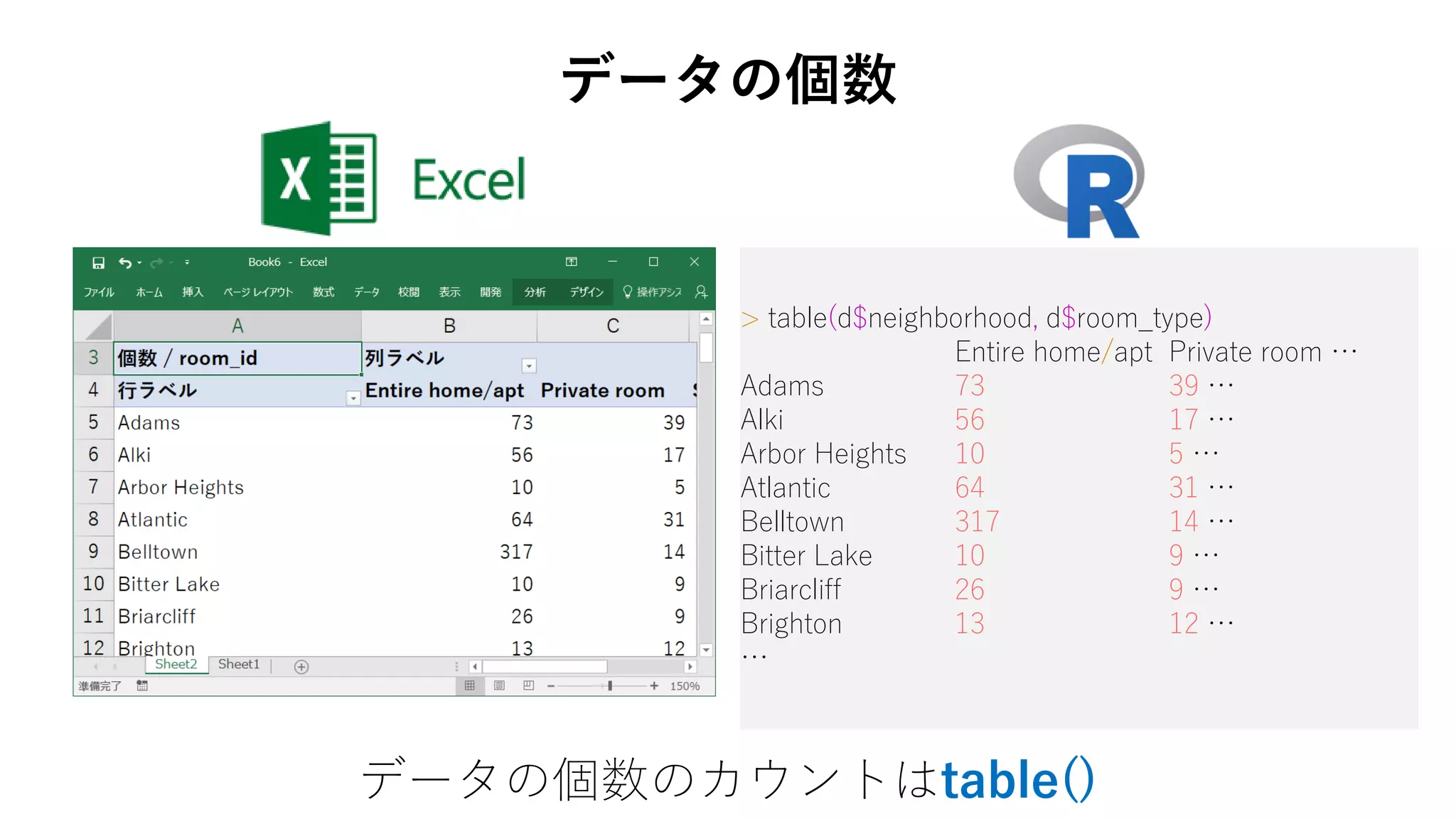
59. 60. 61. 62. 63. 65. 66. 67. > table(d$neighborhood, d$room_type)
Entire home/apt Private room …
Adams 73 39 …
Alki 56 17 …
Arbor Heights 10 5 …
Atlantic 64 31 …
Belltown 317 14 …
Bitter Lake 10 9 …
Briarcliff 26 9 …
Brighton 13 12 …
…
データの個数
データの個数のカウントはtable()
68. > tapply(d$reviews,
+ list(d$neighborhood, d$room_type), + sum)
Entire home/apt Private room …
Adams 2793 1468 …
Alki 1697 555 …
Arbor Heights 196 122 …
Atlantic 1983 1618 …
Belltown 11029 133 …
Bitter Lake 293 109 …
Briarcliff 337 125 …
Brighton 706 334 …
Broadview 523 379 …
合計, 平均, 最大, 最小
合計や平均, 最大, 最小はtapply()の引数に集約関数を指定
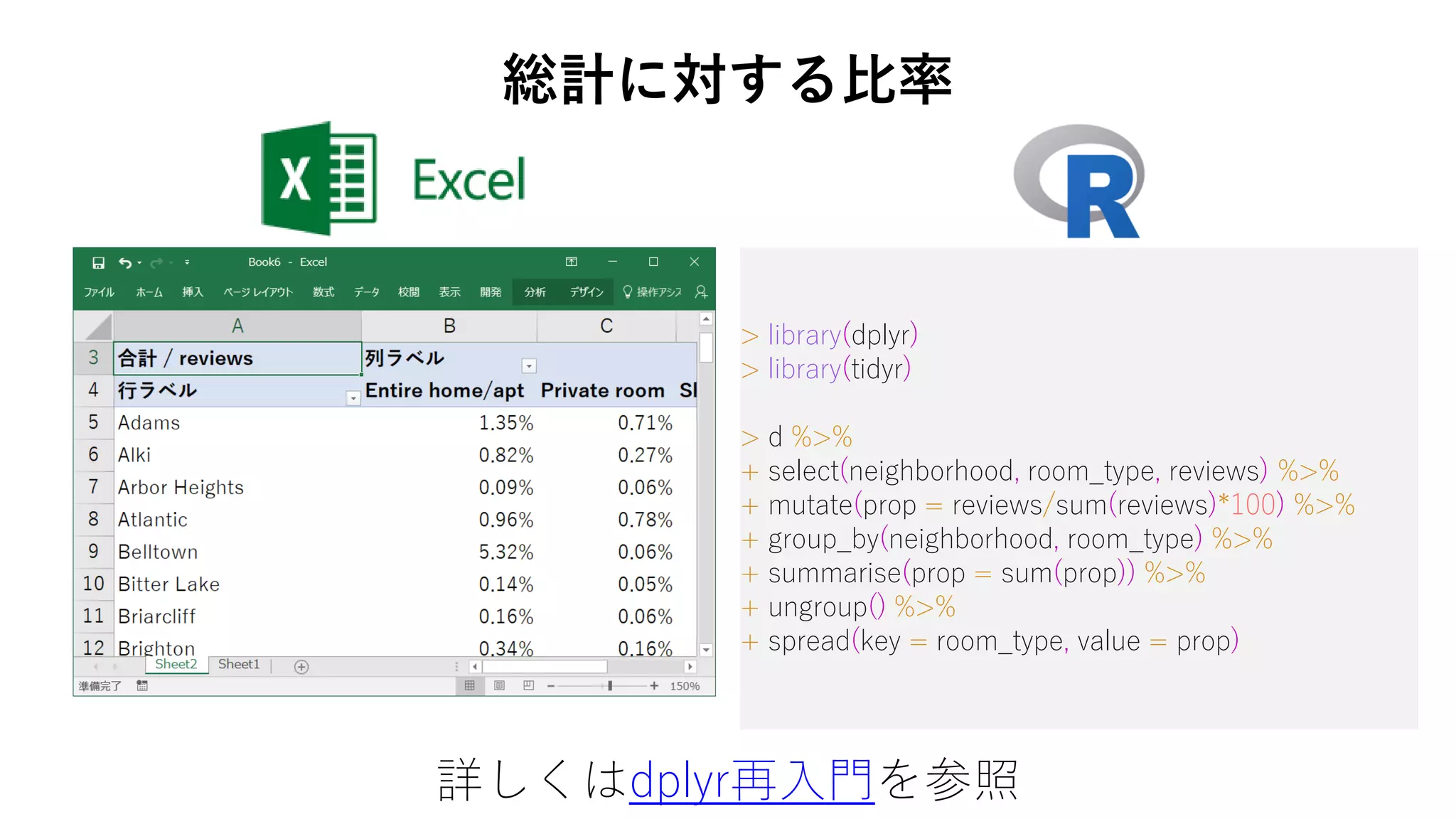
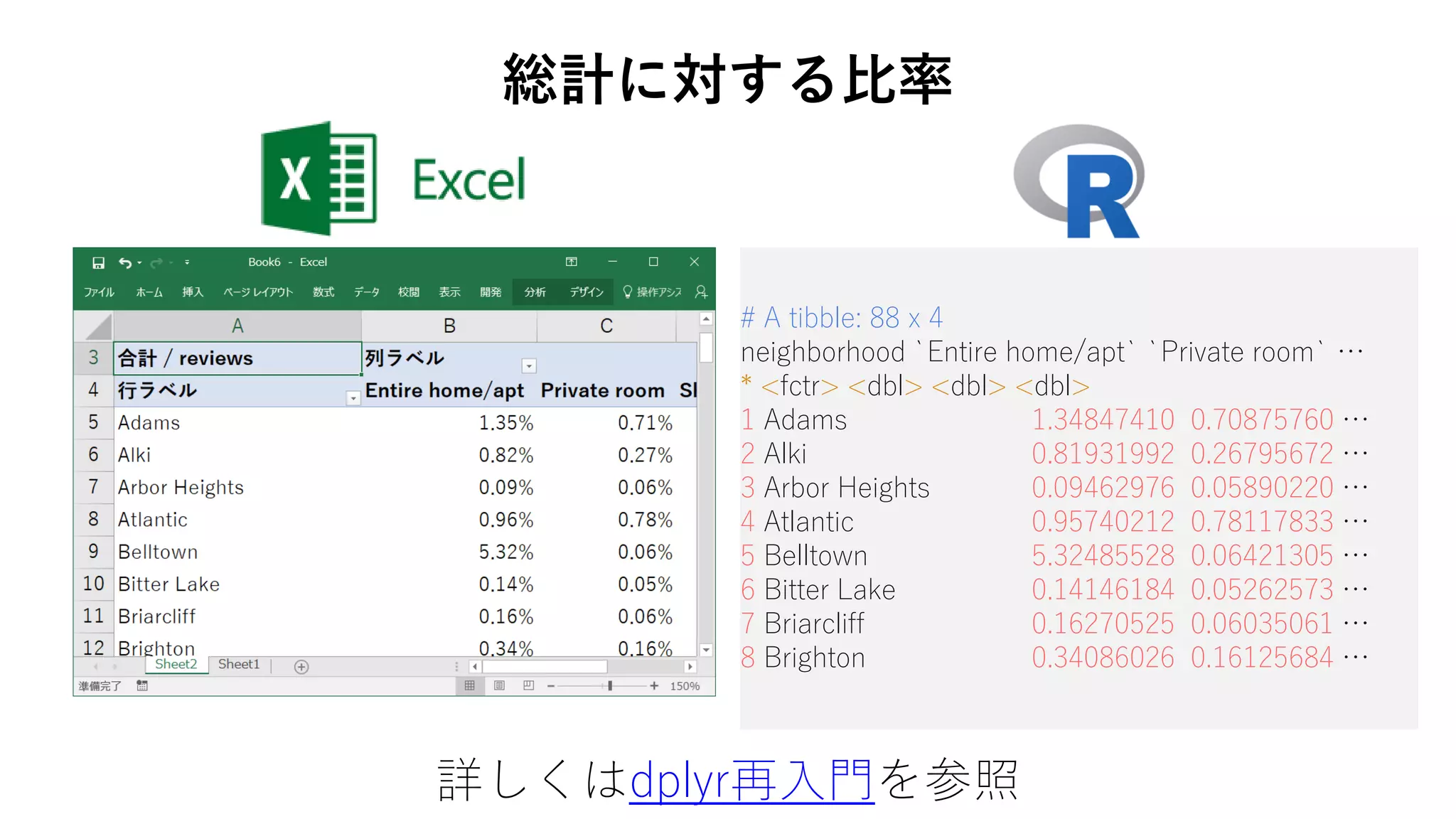
69. 70. > library(dplyr)
> library(tidyr)
> d %>%
+ select(neighborhood, room_type, reviews) %>%
+ mutate(prop = reviews/sum(reviews)*100) %>%
+ group_by(neighborhood, room_type) %>%
+ summarise(prop = sum(prop)) %>%
+ ungroup() %>%
+ spread(key = room_type, value = prop)
総計に対する比率
詳しくはdplyr再入門を参照
71. # A tibble: 88 x 4
neighborhood `Entire home/apt` `Private room` …
* <fctr> <dbl> <dbl> <dbl>
1 Adams 1.34847410 0.70875760 …
2 Alki 0.81931992 0.26795672 …
3 Arbor Heights 0.09462976 0.05890220 …
4 Atlantic 0.95740212 0.78117833 …
5 Belltown 5.32485528 0.06421305 …
6 Bitter Lake 0.14146184 0.05262573 …
7 Briarcliff 0.16270525 0.06035061 …
8 Brighton 0.34086026 0.16125684 …
総計に対する比率
詳しくはdplyr再入門を参照
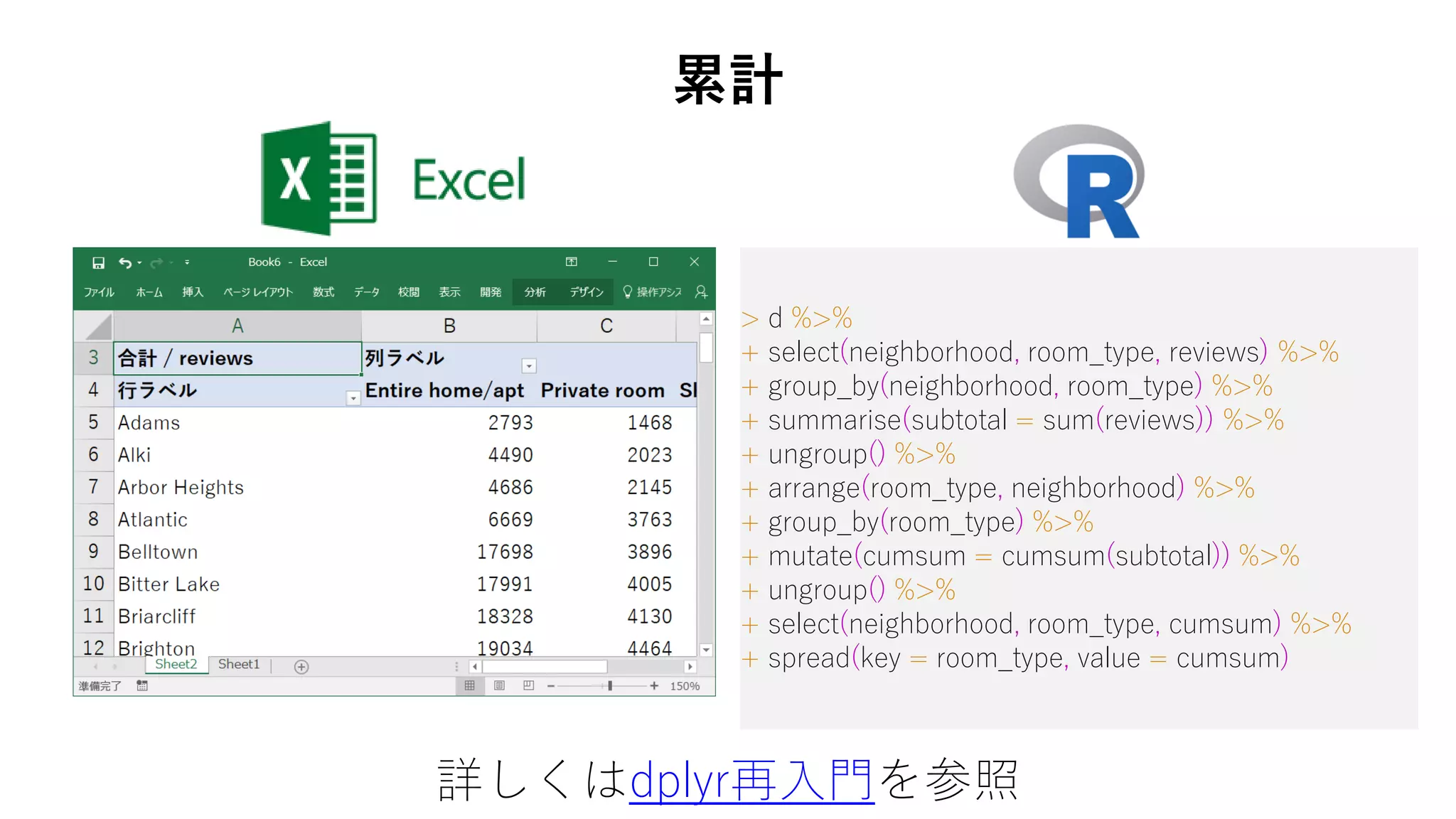
72. > d %>%
+ select(neighborhood, room_type, reviews) %>%
+ group_by(neighborhood, room_type) %>%
+ summarise(subtotal = sum(reviews)) %>%
+ ungroup() %>%
+ arrange(room_type, neighborhood) %>%
+ group_by(room_type) %>%
+ mutate(cumsum = cumsum(subtotal)) %>%
+ ungroup() %>%
+ select(neighborhood, room_type, cumsum) %>%
+ spread(key = room_type, value = cumsum)
累計
詳しくはdplyr再入門を参照
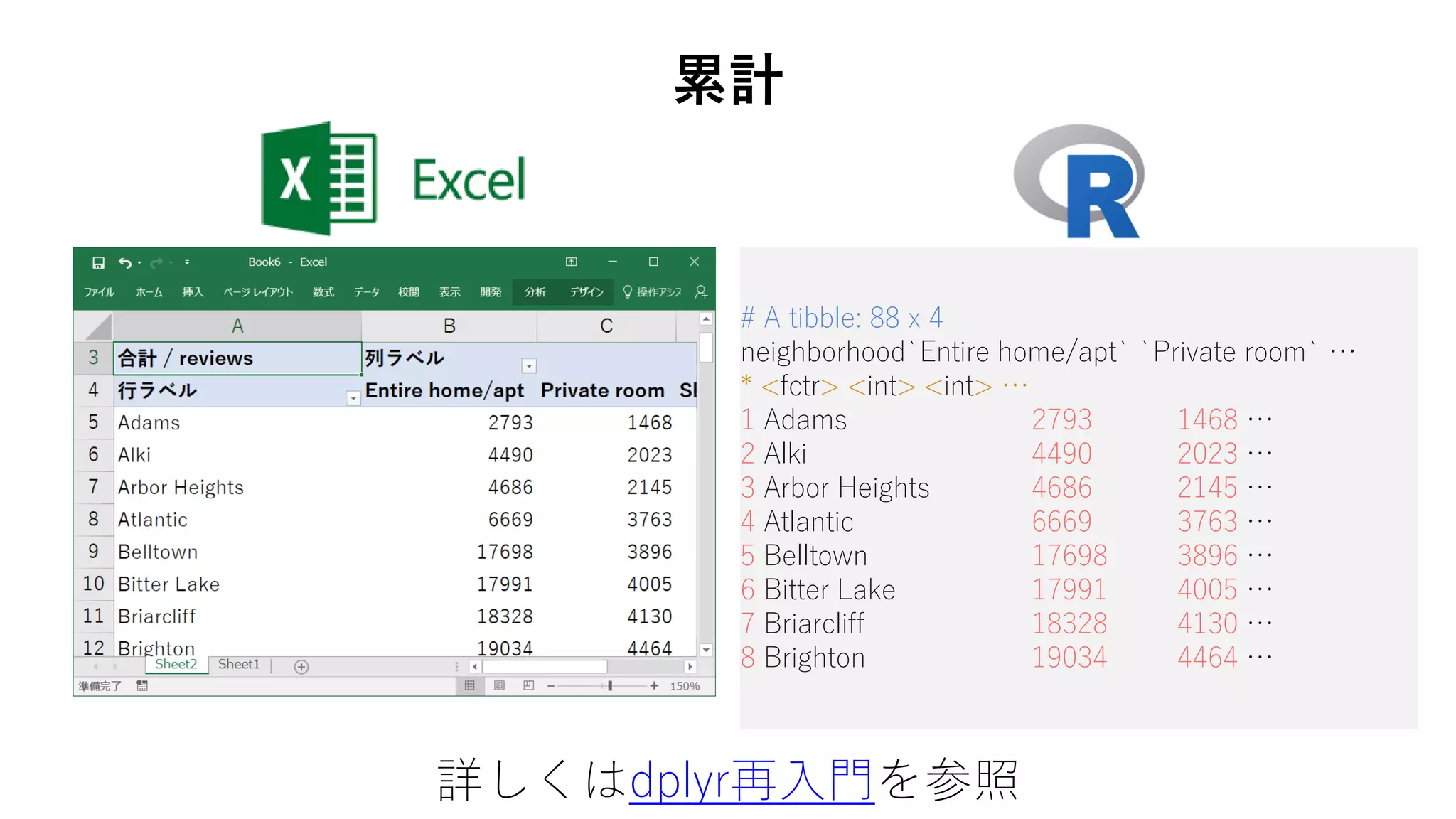
73. # A tibble: 88 x 4
neighborhood`Entire home/apt` `Private room` …
* <fctr> <int> <int> …
1 Adams 2793 1468 …
2 Alki 4490 2023 …
3 Arbor Heights 4686 2145 …
4 Atlantic 6669 3763 …
5 Belltown 17698 3896 …
6 Bitter Lake 17991 4005 …
7 Briarcliff 18328 4130 …
8 Brighton 19034 4464 …
累計
詳しくはdplyr再入門を参照
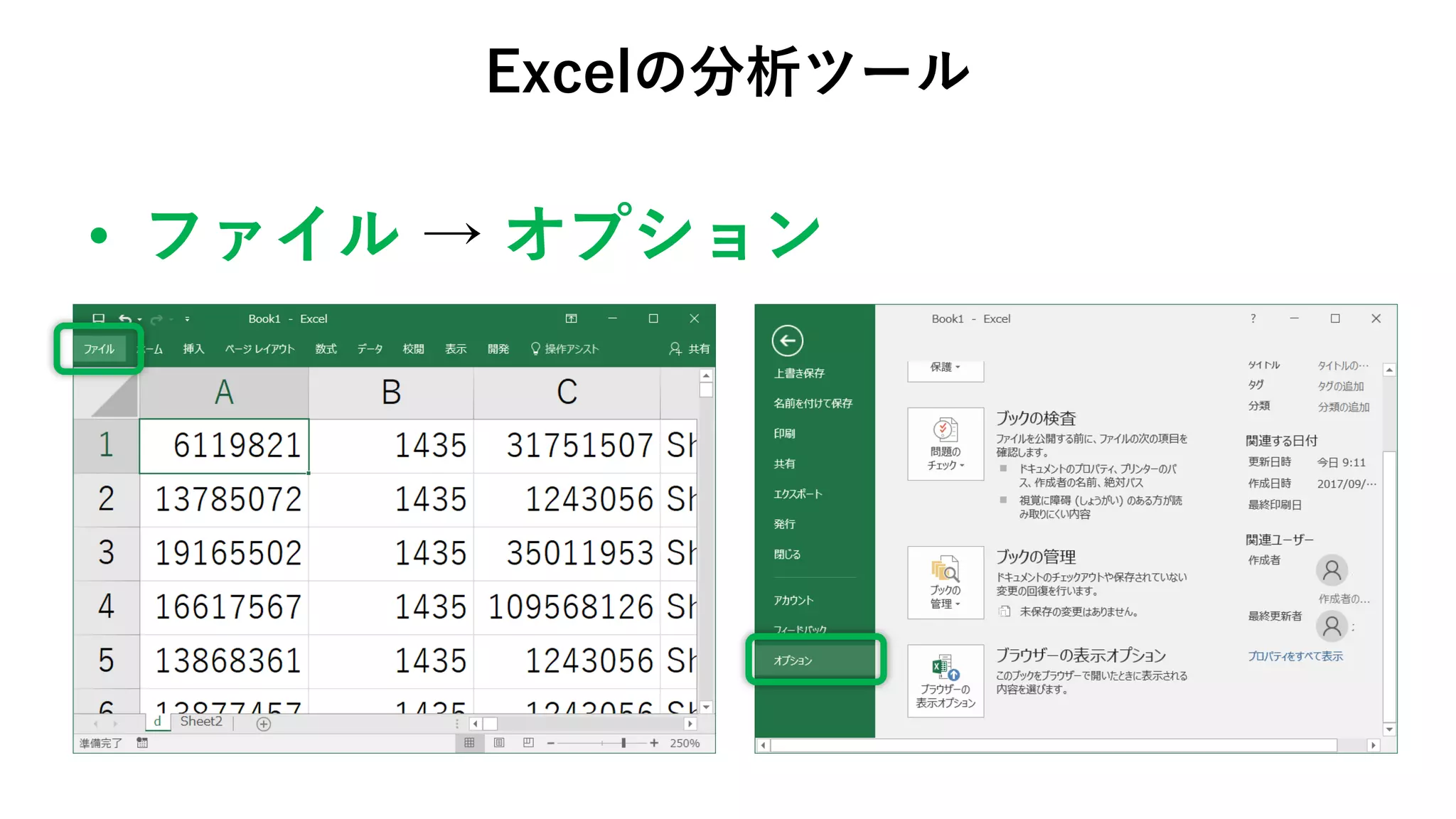
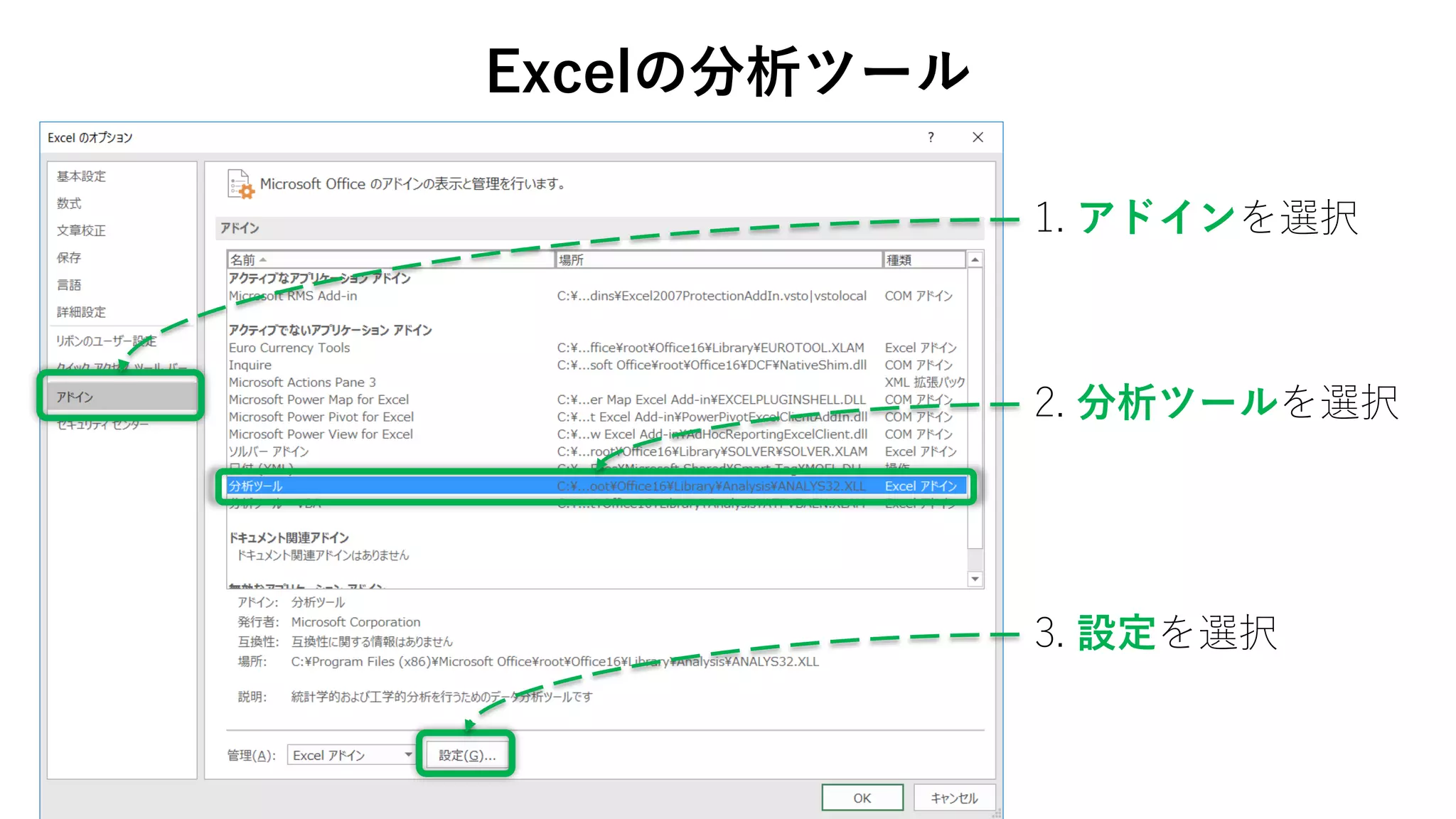
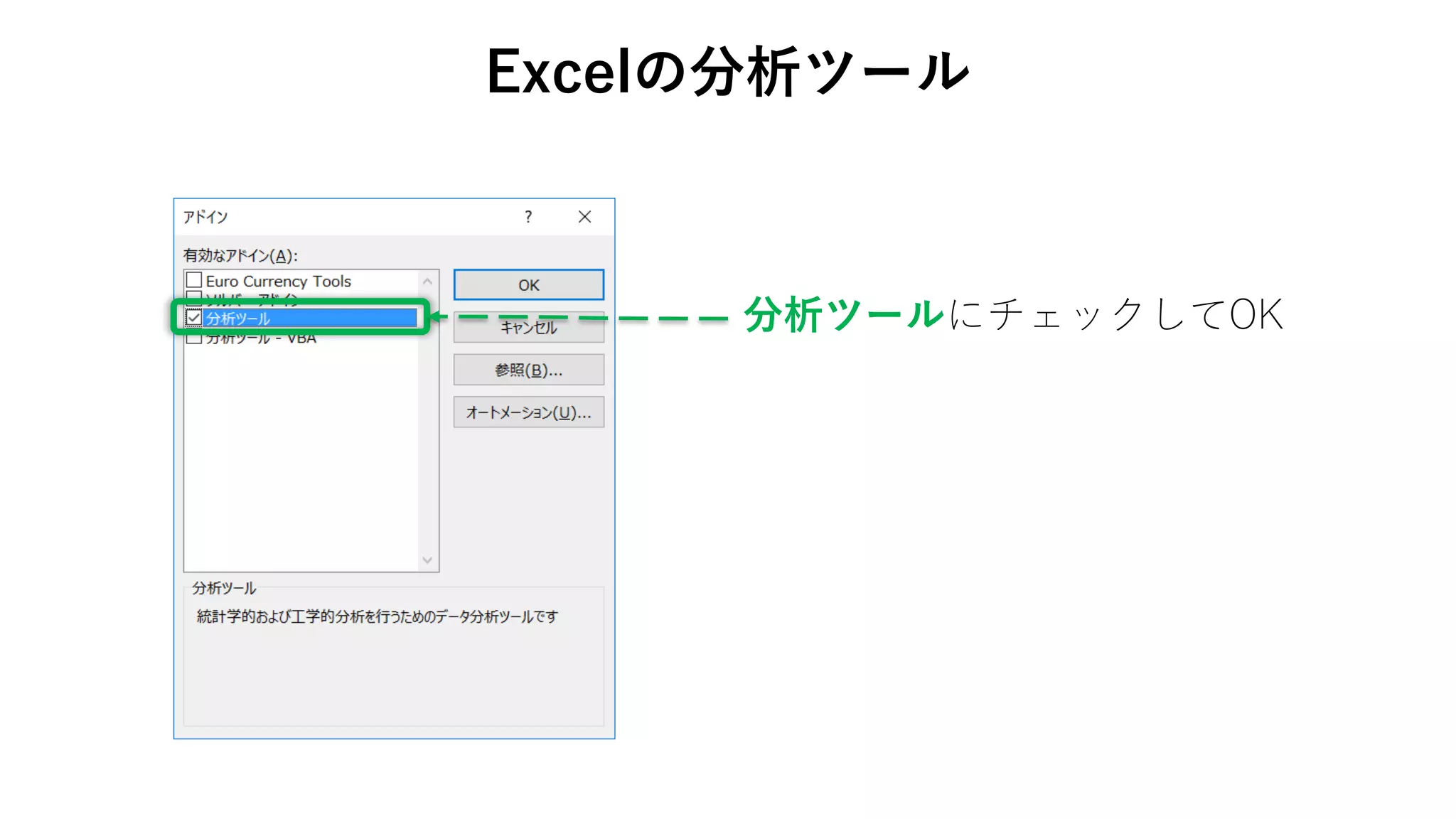
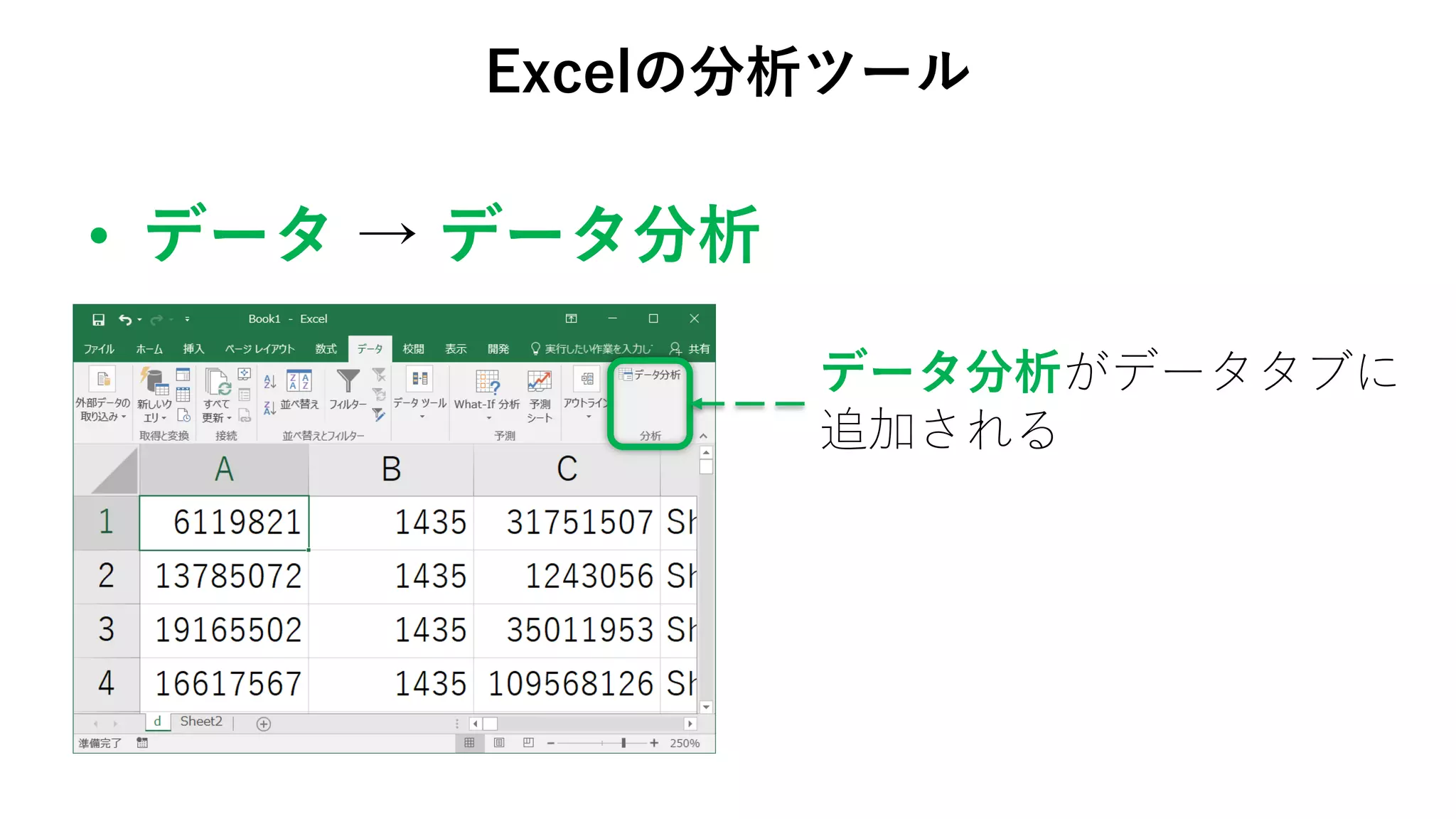
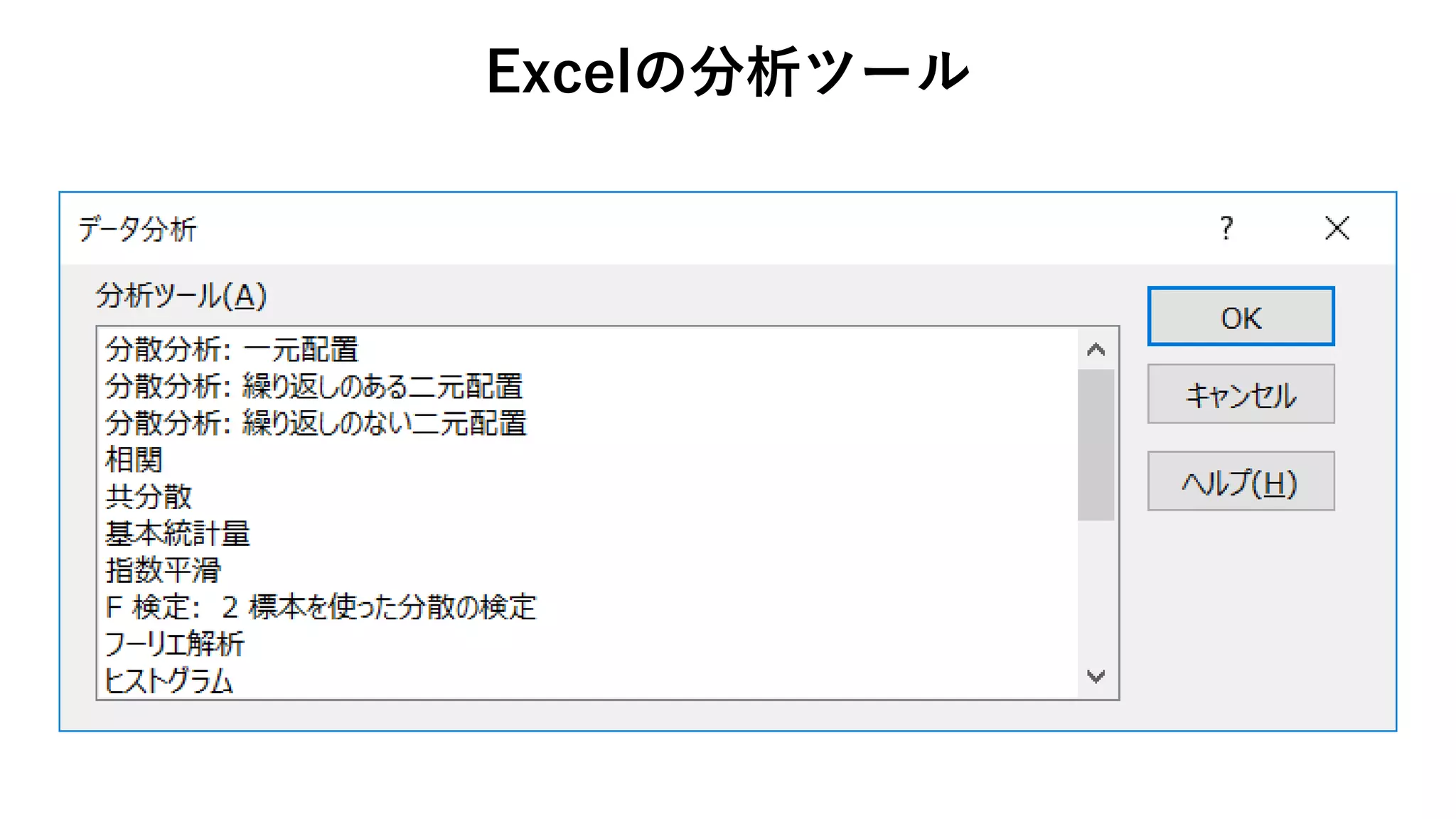
74. 75. 76. 77. 78. • データ → データ分析
Excelの分析ツール
データ分析がデータタブに
追加される
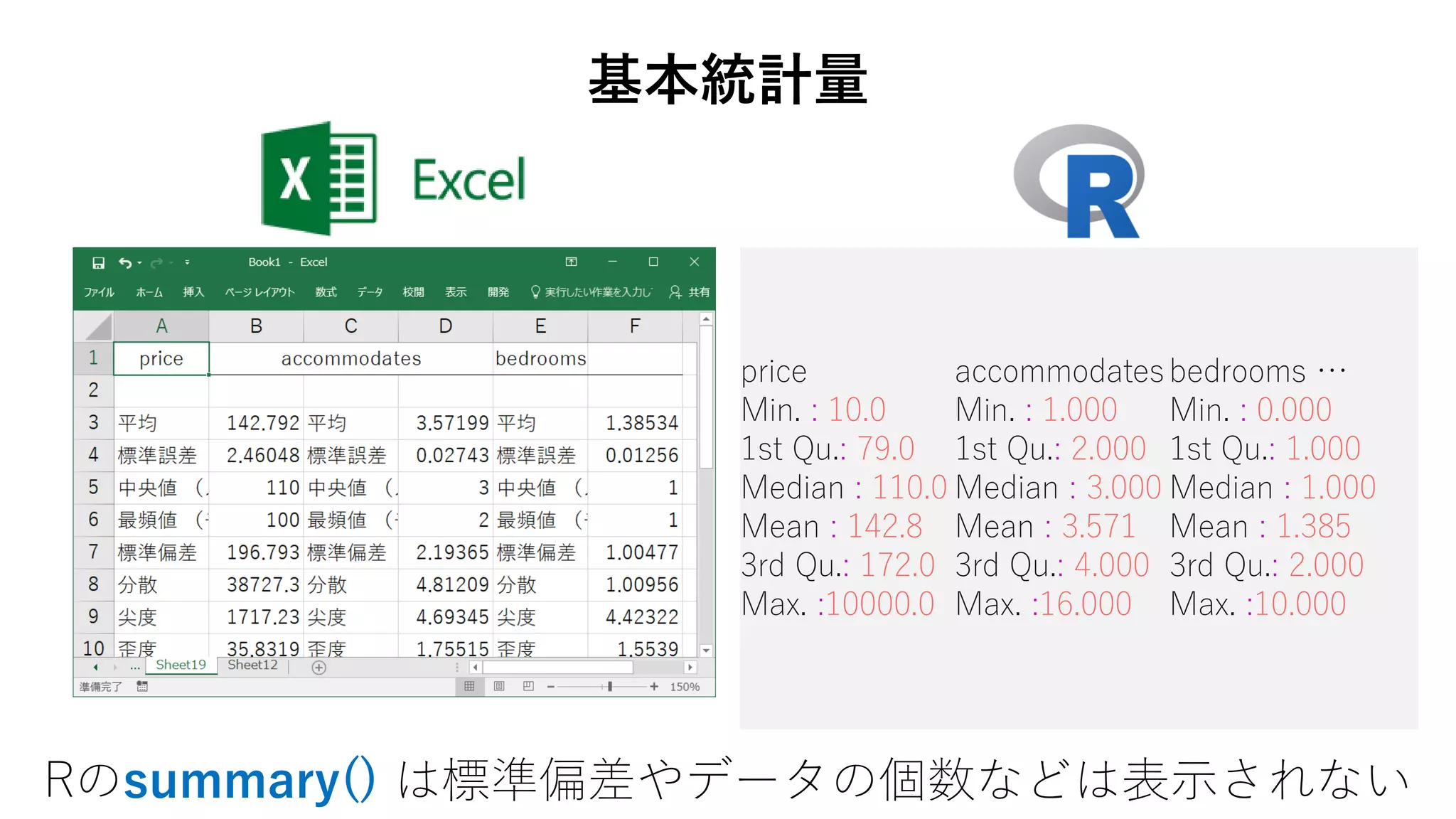
79. 80. 81. 82. price accommodatesbedrooms …
Min. : 10.0 Min. : 1.000 Min. : 0.000
1st Qu.: 79.0 1st Qu.: 2.000 1st Qu.: 1.000
Median : 110.0 Median : 3.000 Median : 1.000
Mean : 142.8 Mean : 3.571 Mean : 1.385
3rd Qu.: 172.0 3rd Qu.: 4.000 3rd Qu.: 2.000
Max. :10000.0 Max. :16.000 Max. :10.000
基本統計量
Rのsummary() は標準偏差やデータの個数などは表示されない
83. > summary(d[, c("room_type", "country")])
room_type country
Entire home/apt: 4526 Mode:logical
Private room : 1727 NA's:6399
Shared room : 146
基本統計量
Rのsummary()は因子型の場合に水準毎のデータ数を返す
84. > summary(d[, c("room_type", "country")])
room_type country
Entire home/apt: 4526 Mode:logical
Private room : 1727 NA's:6399
Shared room : 146
基本統計量
Rのsummary()は欠損の数を表示
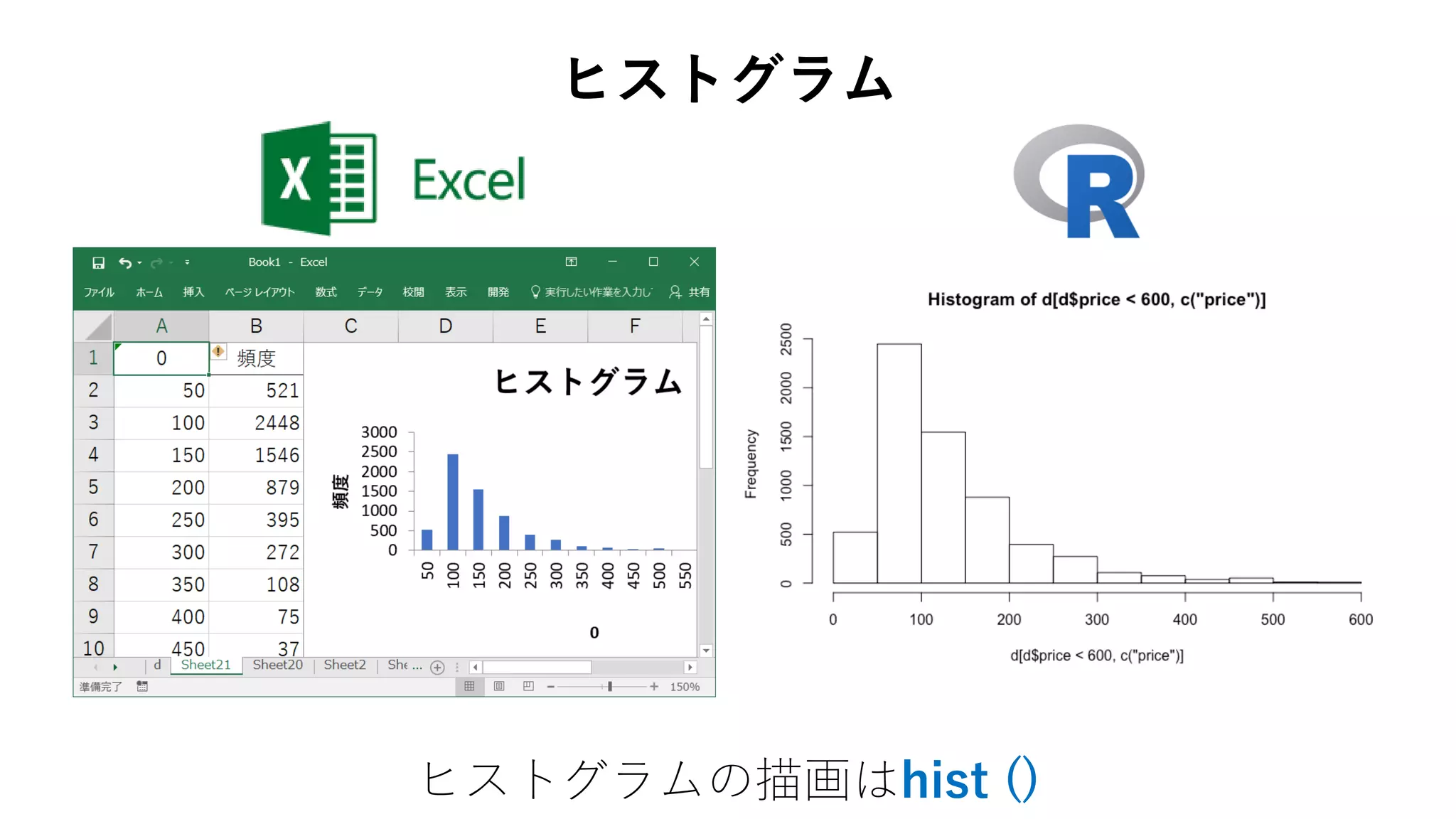
85. 86. 87. > h <- hist(d[d$price < 600,
+ c("price")])
> h$counts
[1] 521 2448 1546 879 395 272 108
75 37 52 11 9
ヒストグラム
頻度の取得はhist () のオブジェクトに保存しcountsを参照
88. > b <- seq(from = 0, to = 600, by = 100)
> hist(d[d$price < 600, c("price")],
+ breaks = b)
ヒストグラム
区間配列の変更するにはhist () の引数breaksを指定
89. 90. > cor(d[d$price < 9000,
+ c("price",
+ "accommodates",
+ "bedrooms",
+ "reviews")])
相関
相関係数行列の算出はcor()
91. price accommodates bedrooms
price 1.0000000 0.65552315 0.6131361
accommodates 0.6555231 1.00000000 0.7817959
bedrooms 0.6131361 0.78179593 1.0000000
reviews -0.1697077 -0.08256885 -0.1515890
相関
92. 93. 94. 回帰分析
回帰(かいき、英: regression)とは、統計学において、Y
が連続値の時にデータに Y = f(X) というモデル(「定量的な
関係の構造[1]」)を当てはめる事。別の言い方では、連続尺
度の従属変数(目的変数)Y と独立変数(説明変数)X の
間にモデルを当てはめること。X が1次元ならば単回帰、X
が2次元以上ならば重回帰と言う。Y が離散の場合は分類
と言う。
回帰分析(かいきぶんせき、英: regression analysis)とは、
回帰により分析する事。
回帰で使われる、最も基本的なモデルは Y = AX + B とい
う形式の線形回帰である。
https://ja.wikipedia.org/wiki/回帰分析
95. 96. > lm.mdl <- lm(
+ price~accommodates+bedrooms,
+ data = d[d$price < 9000, ])
回帰分析
シンプルな回帰分析はlm()
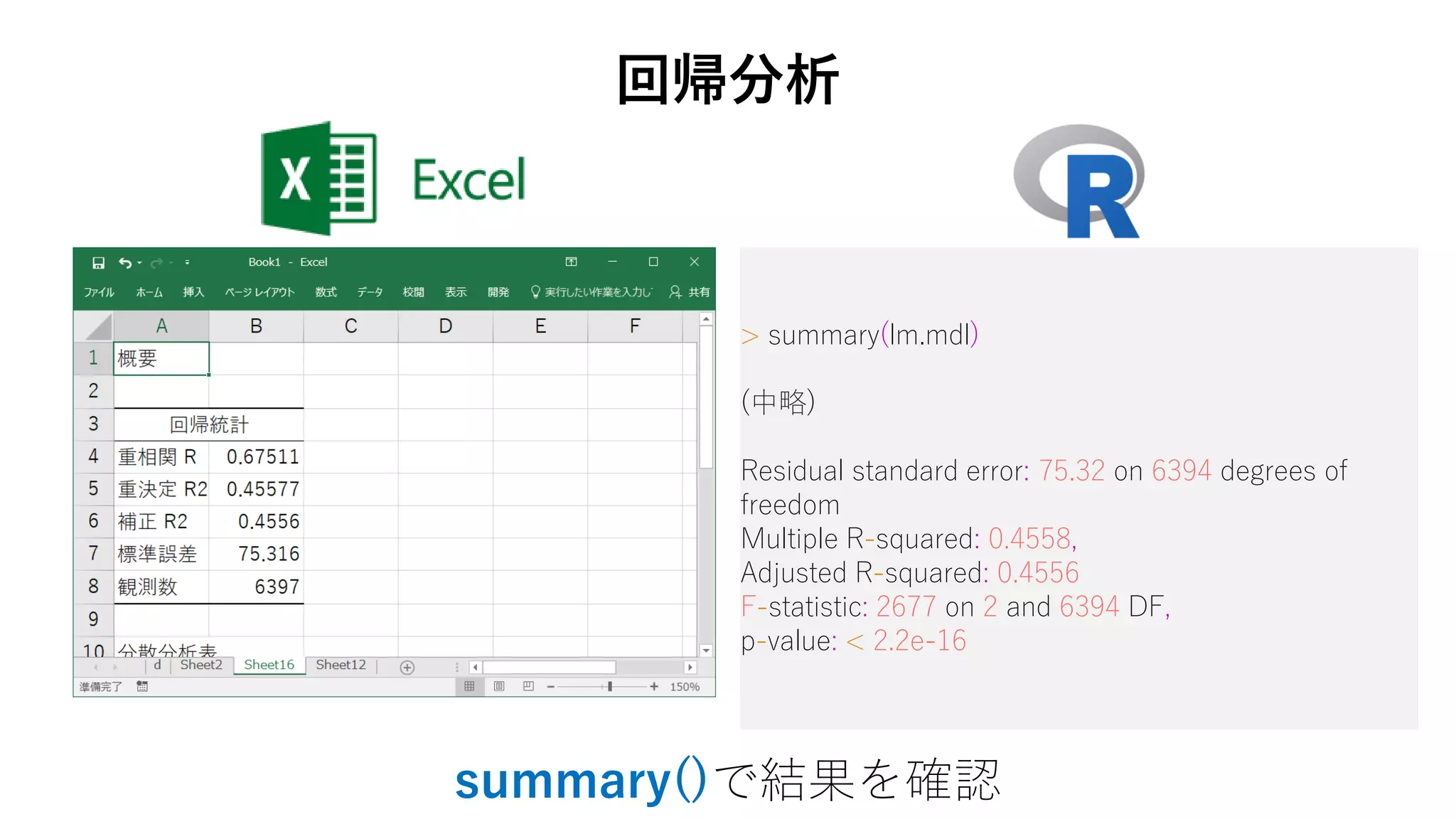
97. > summary(lm.mdl)
(中略)
Residual standard error: 75.32 on 6394 degrees of
freedom
Multiple R-squared: 0.4558,
Adjusted R-squared: 0.4556
F-statistic: 2677 on 2 and 6394 DF,
p-value: < 2.2e-16
回帰分析
summary()で結果を確認
98. > summary(lm.mdl)
(中略)
Coefficients: Estimate Std. Error t value Pr(>|t|)
(Intercept) 27.9864 1.8074 15.48 <2e-16 ***
accommodates 21.1150 0.6895 30.62 <2e-16 ***
bedrooms 26.3005 1.5032 17.50 <2e-16 ***
回帰分析
price = 27.9864 + 21.1150 ×accommodates + 26.3005 × bedrooms
99. > lm.mdl <- lm(price~accommodates+bedrooms+room_type, data = d[d$price < 9000, ])
> summary(lm.mdl)
(中略)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 53.0719 2.2779 23.299 < 2e-16 ***
accommodates 15.0748 0.7576 19.898 < 2e-16 ***
bedrooms 32.3503 1.5096 21.430 < 2e-16 ***
room_typePrivate room -39.9984 2.3746 -16.844 < 2e-16 ***
room_typeShared room -48.4926 6.3565 -7.629 2.71e-14 ***
回帰分析
Rでは因子型の変数も使用可能
100. > lm.mdl <- lm(price~accommodates+bedrooms+room_type, data = d[d$price < 9000, ])
> summary(lm.mdl)
(中略)
Residual standard error: 73.6 on 6392 degrees of freedom
Multiple R-squared: 0.4805, Adjusted R-squared: 0.4802
F-statistic: 1478 on 4 and 6392 DF, p-value: < 2.2e-16
回帰分析
補正R2も少し改善(0.4556 → 0.4802)
101. 102. まとめ
• 基本統計量 : データの要約
• ヒストグラム : データの分布を確認
• 相関 : 項目間の関係性を確認
• 回帰分析 : ある項目の予測式を作成
R でもっと簡単に
103.










![> d[1, c("room_id")]
[1] 6119821
シート名!列名行番号 変数名[行番号, c(列名)]
データの参照](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-17-2048.jpg)
![> d$room_id[1]
[1] 6119821
変数名$列名[行番号]
データの参照
シート名!列名行番号](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-18-2048.jpg)
![> d[1, 1]
[1] 6119821
変数名 [行番号, 列番号]
データの参照
シート名!列名行番号](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-19-2048.jpg)
![> d[2:3, ]
room_id survey_id host_id ...
2 13785072 1435 1243056 ...
3 19165502 1435 35011953 ...
列番号を省略するとすべての列が返される
複数行の参照](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-20-2048.jpg)
![> d[, 2:3]
survey_id host_id
1 1435 31751507
2 1435 1243056
3 1435 35011953
4 1435 109568126
…
行番号を省略するとすべての列が返される
複数列の参照](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-21-2048.jpg)
![> d[, c("survey_id", "host_id")]
survey_id host_id
1 1435 31751507
2 1435 1243056
3 1435 35011953
4 1435 109568126
…
列名をベクトルで与えてもOK
複数列の参照](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-22-2048.jpg)
![> d$price[2] + 10
[1] 262
> d$price[2] - 10
[1] 242
> d$price[2] * 10
[1] 2520
> d$price[2] / 10
[1] 25.2
四則演算は同じ
四則演算](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-23-2048.jpg)
![> d$price[2] %/% 10
[1] 25
> d$price[2] %% 10
[1] 2
整数商は%/%, 余りは%%
剰余](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-24-2048.jpg)
![> d$price[2]
[1] 252
> d$price[2]^2
[1] 63504
> sqrt(d$price[2])
[1] 15.87451
累乗、平方根は同じ
累乗, 平方根](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-25-2048.jpg)
![> # デフォルトの底はe
> log(d$price[2])
[1] 5.529429 >
> log(d$price[2], 10)
[1] 2.401401
> log(d$price[2], 2)
[1] 7.97728
Excelのlog()の底のデフォルトは10, Rのlog()は自然数e
対数](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-26-2048.jpg)
![> d$overall_satisfaction[1]
[1] 4.5
> ifelse(d$overall_satisfaction[1] > 3,
+ "pos", "neg")
[1] "pos"
Excelのif()はRのifelse()
条件分岐](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-27-2048.jpg)
![> d$overall_satisfaction[1]
[1] 4.5
> d$price[1]
[1] 90
> d$overall_satisfaction[1] > 3 &
+ d$price[1] == 90
[1] TRUE
Excelのand()は&
条件分岐](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-28-2048.jpg)
![> d$overall_satisfaction[1]
[1] 4.5
> d$price[1]
[1] 90
> d$overall_satisfaction[1] < 3 |
+ d$price[1] > 100
[1] FALSE
Excelのor()は|
条件分岐](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-29-2048.jpg)
![> d$overall_satisfaction[1]
[1] 4.5
> d$overall_satisfaction[1] > 3
[1] TRUE
> !(d$overall_satisfaction[1] > 3)
[1] FALSE
Excelのnot()は!
条件分岐](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-30-2048.jpg)
![> is.na(d$country[1])
[1] TRUE
欠損値の確認はis.na ()
欠損値の確認](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-31-2048.jpg)
![> # sepで連結時の文字を指定
> paste(d$room_type[2], d$city[2],
+ sep="-")
[1] "Shared room-Seattle"
> # paste0()はpaste(..., sep="")と同じ
> paste0(d$room_type[2], d$city[2])
[1] "Shared roomSeattle"
文字列の連結はpaste(), paste0()
文字列の連結](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-32-2048.jpg)
![> substr(d$room_type[2], 1, 5)
[1] "Share"
> # 4文字目から6文字目
> substr(d$room_type[2], 4, 6)
[1] "red"
文字列の一部取り出しはsubstr()
文字列の一部取り出し](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-33-2048.jpg)
![> # 文字列の長さを取得
> n <- nchar(d$room_type[2])
> substr(d$room_type[2], n-4+1, n)
[1] "room"
Excelのright()は少し工夫が必要
文字列の一部取り出し](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-34-2048.jpg)
![> # stringr::str_subは負数で
> # 末尾からの位置を指定できる
> library(stringr)
> str_sub(d$room_type[2], -4)
[1] "room"
Excelのright()はstringr::str_sub()が便利
文字列の一部取り出し](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-35-2048.jpg)
![> d$neighborhood[1]
[1] "Pike-Market"
> gsub(d$neighborhood[1],
+ "Pike-Market",
+ "1st Starbucks")
[1] "1st Starbucks"
Excelのsubstitute()はRのgsub()
文字列の置換](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-36-2048.jpg)
![> d$room_type[1]
[1] "Shared room"
> tolower(d$room_type[1])
[1] "shared room"
> toupper(d$room_type[1])
[1] "SHARED ROOM"
Excelのlower(), upper()はRのtolower(), toupper ()
大文字, 小文字の変換](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-37-2048.jpg)
![> d$subtotal <- d$reviews * d$price
> d$subtotal
[1] 7290 0 0 0 0 0 0 0 0 0 4470 0 …
[16] 0 0 0 0 100 0 0 765 252 567 …
[31] 525 0 0 79 138 219 1152 248 …
[46] 2625 2015 1950 0 0 0 144 0 48…
[61] 225 405 49 0 48 200 0 360 …
…
Rでは同じ長さのベクトルの演算は、各要素ごとの演算となる
ベクトル演算](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-38-2048.jpg)
![> d[order(d$price),
+ c("room_id", "price")]
room_id price
110 18852442 10
4370 13726014 10
4371 4825073 10
135 13560642 14
6302 6015931 19
order () で並べ替えの順番を取得して行に指定
並べ替え](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-39-2048.jpg)
![> d[order(d$price,
+ decreasing = TRUE),
+ c("room_id", "price")]
room_id price
194 5240694 10000
193 153967 9300
195 16816051 1395
197 16740073 1200
降順はdescreasing = TRUE
並べ替え](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-40-2048.jpg)

![> merge(
+ d[, c("room_id", "city", "country")],
+ m, by="city", all.x = TRUE)
city room_id country.x country.y
1 Seattle 6119821 NA USA
2 Seattle 13785072 NA USA
3 Seattle 19165502 NA USA
…
merge() で複数のdata.frameをJOINすることが可能
vlookup()](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-42-2048.jpg)






![> sum(d$price)
[1] 913518
> mean(d$price)
[1] 142.7595
> var(d$price)
[1] 38718.49
> sd(d$price)
[1] 196.7701
average()はmean() , stdev()はsd()
合計, 平均, 分散, 標準偏差](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-52-2048.jpg)
![> max(d$price)
[1] 10000
> min(d$price)
[1] 10
> median(d$price)
[1] 110
> # mode()はデータ型を返す
> mode(d$price)
[1] "numeric"
Rには最頻値を返す関数はない
最大値, 最小値, 中央値, 最頻値](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-53-2048.jpg)
![> range(d$price)
[1] 10 10000
> range(d$price)[1]
[1] 10
> range(d$price)[2]
[1] 10000
範囲(最大値と最小値の差)
Rのrange()は最大値と最小値がベクトルで返る](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-54-2048.jpg)
![> quantile(d$price)
0% 25% 50% 75% 100%
10 79 110 172 10000
> quantile(d$price)[2]
25%
79
> quantile(d$price)[4]
75%
172
四分位数
Rのquantile()は四分位数がベクトルで返る](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-55-2048.jpg)















![> summary(d[, c("price",
+ "accommodates",
+ "bedrooms")])
基本統計量
基本統計量の算出はsummary()](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-81-2048.jpg)
![> summary(d[, c("room_type", "country")])
room_type country
Entire home/apt: 4526 Mode:logical
Private room : 1727 NA's:6399
Shared room : 146
基本統計量
Rのsummary()は因子型の場合に水準毎のデータ数を返す](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-83-2048.jpg)
![> summary(d[, c("room_type", "country")])
room_type country
Entire home/apt: 4526 Mode:logical
Private room : 1727 NA's:6399
Shared room : 146
基本統計量
Rのsummary()は欠損の数を表示](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-84-2048.jpg)
![> hist(d[d$price < 600, c("price")])
ヒストグラム
ヒストグラムの描画はhist ()](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-85-2048.jpg)
![> h <- hist(d[d$price < 600,
+ c("price")])
> h$counts
[1] 521 2448 1546 879 395 272 108
75 37 52 11 9
ヒストグラム
頻度の取得はhist () のオブジェクトに保存しcountsを参照](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-87-2048.jpg)
![> b <- seq(from = 0, to = 600, by = 100)
> hist(d[d$price < 600, c("price")],
+ breaks = b)
ヒストグラム
区間配列の変更するにはhist () の引数breaksを指定](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-88-2048.jpg)
![相関
相関係数(そうかんけいすう、英: correlation coefficient)
は、2つの確率変数の間にある線形な関係の強弱を測る指
標である[1]。相関係数は無次元量で、−1以上1以下の実数
に値をとる。相関係数が正のとき確率変数には正の相関が、
負のとき確率変数には負の相関があるという。また相関係
数が0のとき確率変数は無相関であるという[2][3] 。
https://ja.wikipedia.org/wiki/相関係数](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-89-2048.jpg)
![> cor(d[d$price < 9000,
+ c("price",
+ "accommodates",
+ "bedrooms",
+ "reviews")])
相関
相関係数行列の算出はcor()](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-90-2048.jpg)


![回帰分析
回帰(かいき、英: regression)とは、統計学において、Y
が連続値の時にデータに Y = f(X) というモデル(「定量的な
関係の構造[1]」)を当てはめる事。別の言い方では、連続尺
度の従属変数(目的変数)Y と独立変数(説明変数)X の
間にモデルを当てはめること。X が1次元ならば単回帰、X
が2次元以上ならば重回帰と言う。Y が離散の場合は分類
と言う。
回帰分析(かいきぶんせき、英: regression analysis)とは、
回帰により分析する事。
回帰で使われる、最も基本的なモデルは Y = AX + B とい
う形式の線形回帰である。
https://ja.wikipedia.org/wiki/回帰分析](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-94-2048.jpg)

![> lm.mdl <- lm(
+ price~accommodates+bedrooms,
+ data = d[d$price < 9000, ])
回帰分析
シンプルな回帰分析はlm()](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-96-2048.jpg)

![> lm.mdl <- lm(price~accommodates+bedrooms+room_type, data = d[d$price < 9000, ])
> summary(lm.mdl)
(中略)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 53.0719 2.2779 23.299 < 2e-16 ***
accommodates 15.0748 0.7576 19.898 < 2e-16 ***
bedrooms 32.3503 1.5096 21.430 < 2e-16 ***
room_typePrivate room -39.9984 2.3746 -16.844 < 2e-16 ***
room_typeShared room -48.4926 6.3565 -7.629 2.71e-14 ***
回帰分析
Rでは因子型の変数も使用可能](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-99-2048.jpg)
![> lm.mdl <- lm(price~accommodates+bedrooms+room_type, data = d[d$price < 9000, ])
> summary(lm.mdl)
(中略)
Residual standard error: 73.6 on 6392 degrees of freedom
Multiple R-squared: 0.4805, Adjusted R-squared: 0.4802
F-statistic: 1478 on 4 and 6392 DF, p-value: < 2.2e-16
回帰分析
補正R2も少し改善(0.4556 → 0.4802)](https://image.slidesharecdn.com/20170923excelr-170923081217/75/20170923-excel-r-100-2048.jpg)












![[機械学習]文章のクラス分類](https://cdn.slidesharecdn.com/ss_thumbnails/ss-160218112331-thumbnail.jpg?width=640&height=640&fit=bounds)




































![[データマイニング+WEB勉強会][R勉強会] はじめてでもわかる 統計解析・データマイニング R言語入門](https://cdn.slidesharecdn.com/ss_thumbnails/rlecturehamada100213-100216161757-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




























