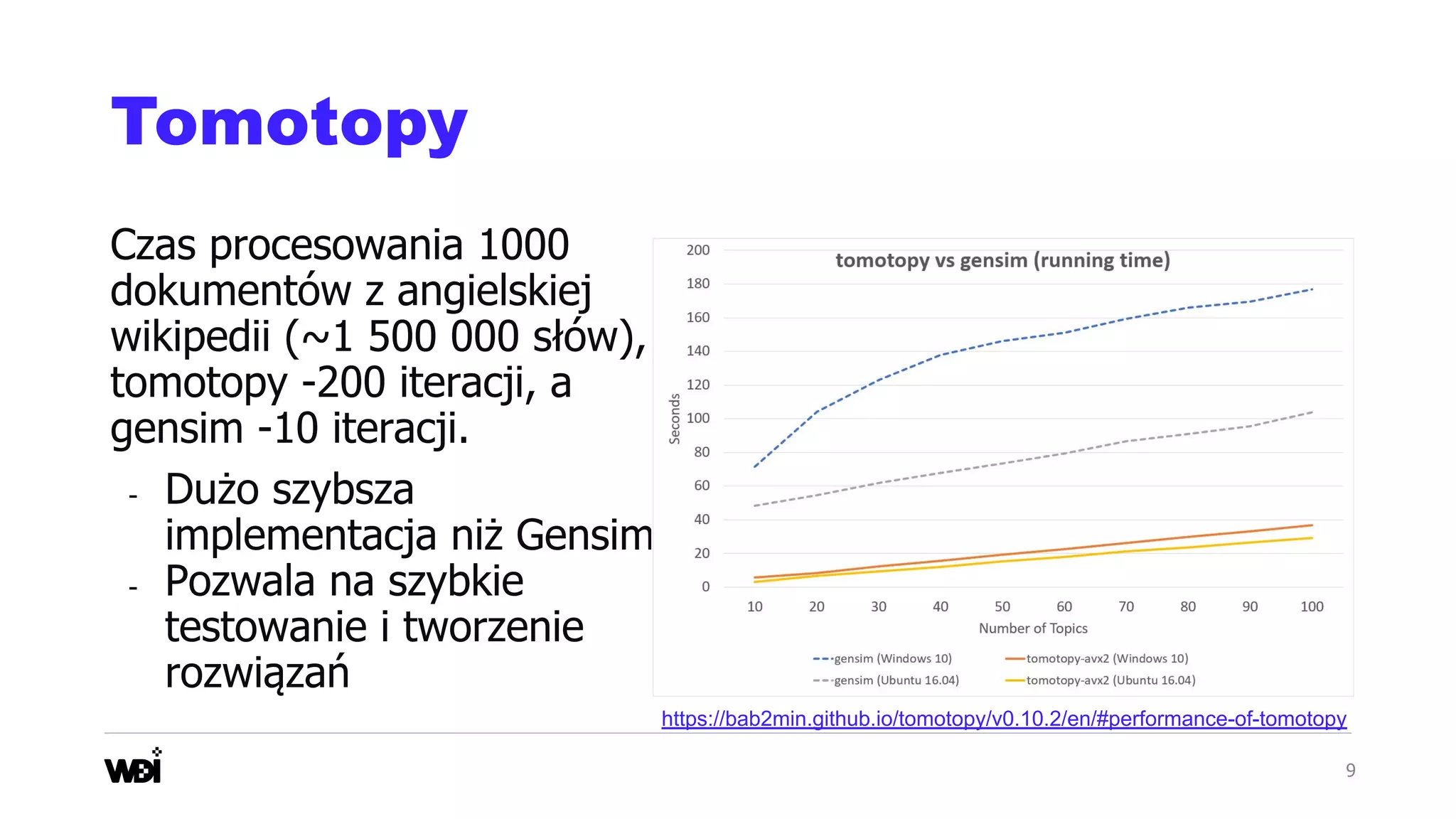
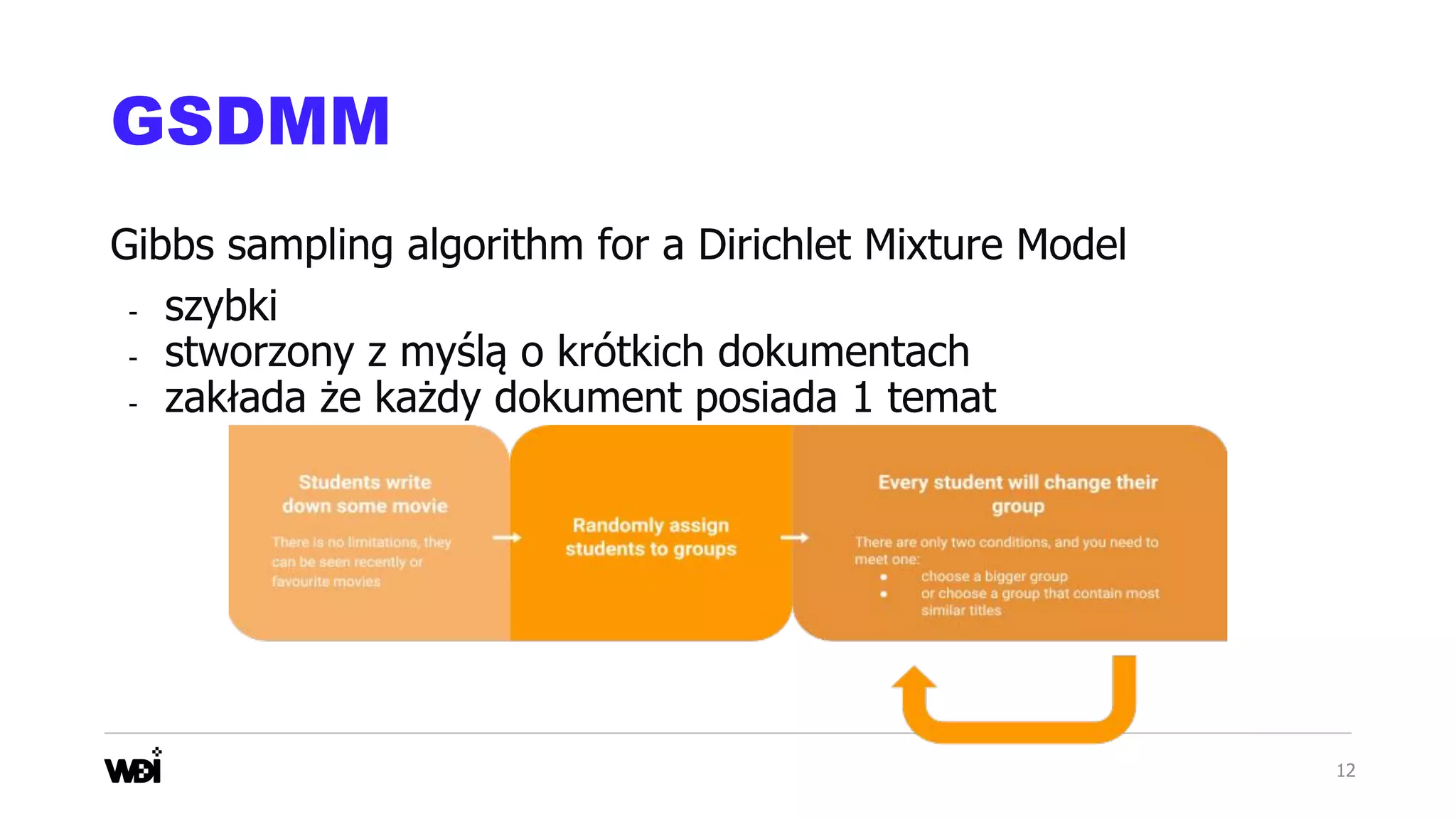
Download as PDF, PPTX









![11
Dane z social media
- Bardzo krótkie wypowiedzi (dokumenty)
- Założenie, że dokument jest mieszanką kilku tematów często
nie jest spełniony
- zawierają emotki.
- Analizowane zbiory często są bardzo duże
[‘placek’, ‘ser’, ‘lubić’, ‘przepyszny’]
[akurat, dziś, pozdrawiać, najcieplej, życzyć,
dobry, popołudnie]](https://image.slidesharecdn.com/wdi21dominikasagan-210517115235/75/Topic-modeling-nie-tylko-LDA-w-Gensim-11-2048.jpg)






Jaki algorytm jest najczęściej wykorzystywany do Topic Modelingu? LDA! A jaka jest najpopularniejsza implementacja LDA? Oczywiście ta zawarta w pakiecie Gensim. LDA zaimplementowane w pakiecie Gensim jest niezaprzeczalnie dobrym wyborem startowym. Niestety nie umożliwia szybkiego testowania i poprawiania modelu wykorzystując duże zbiory danych, nie będzie też dobrym wyborem przy pracy z krótkimi tekstami z social media. W swojej prezentacji przedstawię topic modeling z nowej strony, skupiając się na metodzie GSDMM, stworzonej specjalnie pod analizę krótkich tekstów. Przedstawię również alternatywną implementację w języku Python algorytmów topic modelingu, w tym również LDA, umożliwiającą uzyskanie zadowalających wyników nawet przy bardzo krótkich deadline’ach. Prezentacja z Warszawskich Dni Informatyki 2021









![Prawdziwe oblicze tekstu, czyli jak rozmawiamy w sieci [WDI 2019]](https://cdn.slidesharecdn.com/ss_thumbnails/wdi2019-prawdziweobliczetekstuczylijakrozmawiamywsieci-210517103955-thumbnail.jpg?width=640&height=640&fit=bounds)







![Jakimi wartościami kieruje się Twoja grupa docelowa? [Listonic Case Study]](https://cdn.slidesharecdn.com/ss_thumbnails/20170824listoniccasestudysotrender-170830112038-thumbnail.jpg?width=640&height=640&fit=bounds)









